Как обрабатывать ошибки на JVM быстрее
Существуют различные способы обработки ошибок в языках программирования:
- стандартные для многих языков исключения (Java, Scala и прочий JVM, python и многие другие)
- коды статуса или флаги (Go, bash)
- различные алгебраические структуры данных, значениями которых могут быть как успешные результаты так и описания ошибок (Scala, haskell и другие функциональные языки)
Исключения используются очень широко, с другой стороны о них часто говорят, что они медленные. Но и противники функционального подхода часто апеллируют к производительности.
Последнее время я работаю со Scala, где в равной мере я могу использовать как исключения так и различные типы данных для обработки ошибок, поэтому интересно какой из подходов будет удобнее и быстрее.
Сразу отбросим использование кодов и флагов, так как этот подход не принят в JVM языках и по моему мнению слишком подвержен ошибкам (прошу прощения за каламбур). Поэтому будем сравнивать исключения и разные виды АТД. Кроме того АТД можно рассматривать как использование кодов ошибок в функциональном стиле.
UPDATE: к сравнению добавлены исключения без стек-трейсов
Конкурсанты
Для тех, кто не слишком знаком с АТД (ADT) — алгебраический тип состоит из нескольких возможных значений, каждое из которых может быть составным значением (структурой, записью).
Примером может служить тип Option[T] = Some(value: T) | None, который используется вместо null-ов: значением данного типа может быть либо Some(t) если значение есть, либо None если его нет.
Другим примером может быть Try[T] = Success(value: T) | Failure(exception: Throwable), который описывает результат вычисления, которое могло завершиться успешно либо с ошибкой.
Итак наши конкурсанты:
- Старые добрые исключения
- Исключения без стек-трейса, так как именно заполнение стек-трейса очень медленная операция
Try[T] = Success(value: T) | Failure(exception: Throwable)— те же исключения, но в функциональной оберткеEither[String, T] = Left(error: String) | Right(value: T)— тип, содержащий либо результат либо описание ошибкиValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String])— тип из библиотеки Cats, который в случае ошибки может содержать несколько сообщений о разных ошибках (там используется не совсемList, но это не важно)
NOTE по-сути сравниваются исключения со стек-трейсом, без и АТД, но выбрано несколько типов, так как в Scala нет единого подхода и интересно сравнить несколько.
Кроме исключений тут используются строки для описания ошибок, но с тем же успехом в реальной ситуации использовались бы различные классы (Either[Failure, T]).
Проблема
Для тестирование обработки ошибок возьмем проблему парсинга и валидации данных:
case class Person(name: String, age: Int, isMale: Boolean)
type Result[T] = Either[String, T]
trait PersonParser {
def parse(data: Map[String, String]): Result[Person]
}
т.е. имея сырые данные Map[String, String] нужно получить Person или ошибку если данные не валидны.
Throw
Решение в лоб с использованием исключений (тут и далее буду приводить только функцию person, с полным кодом ознакомится можно на github):
ThrowParser.scala
def person(data: Map[String, String]): Person = {
val name = string(data.getOrElse("name", null))
val age = integer(data.getOrElse("age", null))
val isMale = boolean(data.getOrElse("isMale", null))
require(name.nonEmpty, "name should not be empty")
require(age > 0, "age should be positive")
Person(name, age, isMale)
}
тут string, integer и boolean валидируют наличие и формат простых типов и производят преобразование.
В целом довольно просто и понятно.
ThrowNST (No Stack Trace)
Код такой же, как и в предыдущем случае, но используются исключения без стек-трейса где можно: ThrowNSTParser.scala
Try
Решение перехватывает исключения раньше и позволяет комбинировать результаты через for (не путать с циклами в других языках):
TryParser.scala
def person(data: Map[String, String]): Try[Person] = for {
name <- required(data.get("name"))
age <- required(data.get("age")) flatMap integer
isMale <- required(data.get("isMale")) flatMap boolean
_ <- require(name.nonEmpty, "name should not be empty")
_ <- require(age > 0, "age should be positive")
} yield Person(name, age, isMale)
немного более непривычно для неокрепшего глаза, но за счет использования for в целом очень похоже на версию с исключениями, кроме того валидация наличия поля и парсинг нужного типа происходят отдельно (flatMap тут можно читать как and then)
Either
Тут тип Either спрятан за алиасом Result так как тип ошибки фиксирован:
EitherParser.scala
def person(data: Map[String, String]): Result[Person] = for {
name <- required(data.get("name"))
age <- required(data.get("age")) flatMap integer
isMale <- required(data.get("isMale")) flatMap boolean
_ <- require(name.nonEmpty, "name should not be empty")
_ <- require(age > 0, "age should be positive")
} yield Person(name, age, isMale)
Поскольку стандартный Either как и Try формирует монаду в Scala то код вышел абсолютно такой же, отличие тут в том, что в качестве ошибки тут фигурирует строка и исключения используются минимально (только для обработки ошибки при парсинге числа)
Validated
Тут используется библиотека Cats для того чтобы получить в случае ошибки не первую произошедшую, но как можно больше (например если несколько полей были не валидными, то результат будет содержать ошибки парсинга всех этих полей)
ValidatedParser.scala
def person(data: Map[String, String]): Validated[Person] = {
val name: Validated[String] =
required(data.get("name"))
.ensure(one("name should not be empty"))(_.nonEmpty)
val age: Validated[Int] =
required(data.get("age"))
.andThen(integer)
.ensure(one("age should be positive"))(_ > 0)
val isMale: Validated[Boolean] =
required(data.get("isMale"))
.andThen(boolean)
(name, age, isMale).mapN(Person)
}
этот код уже менее похож на исходную версию с исключениями, но зато проверка дополнительных ограничений не оторвана от парсинга полей и мы все-таки получаем несколько ошибок вместо одной, это того стоит!
Тестирование
Для тестирование генерировался набор данных с различным процентом ошибок и парсился каждым из способов.
Результат на всех процентах ошибок: 
Более подробно на низком проценте ошибок (время тут другое так как использовалась большая выборка): 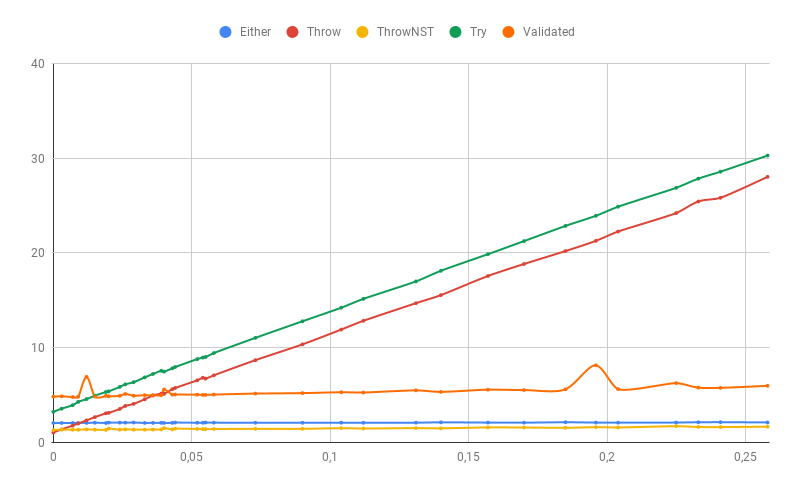
Если же какая-то часть ошибок все-же является исключением со стек-трейсом (в нашем случае ошибка парсинга числа будет исключением, которое мы не контролируем) то конечно производительность «быстрых» способов обработки ошибок будет значительно ухудшаться. Особенно страдает Validated, так как он собирает все ошибки и в результате получает медленное исключение больше других: 
Выводы
Как показал эксперимент исключения со стек-трейсами действительно очень медленные (на 100% ошибок разница между Throw и Either более чем в 50 раз!), а когда исключений практически нет использование АТД имеет свою цену. Однако использование исключений без стек-трейсов так же быстро (а при низком проценте ошибок быстрее) как и АДТ, однако если такие исключения выйдут за пределы той же валидации отследить их источник будет не легко.
Итого, если вероятность исключения более 1% то быстрее всего работают исключения без стек-трейсов, Validated или обычный Either почти так же быстры. При большом количестве ошибок Either может быть немного быстрее Validated только за счет семантики fail-fast.
Использование АТД для обработки ошибок дает еще одно преимущество перед исключениями: возможность ошибки зашита в сам тип и ее сложнее упустить, как и при использовании Option вместо null’ов.
