«Потомок» AlphaGo самостоятельно научился играть в шахматы, сеги и го

DeepMind создает поистине удивительные алгоритмы, которые способны на то, чего не могли достичь машинные системы ранее. В частности, нейросеть AlphaGo смогла обыграть в го лучших игроков мира. По мнению специалистов, сейчас возможности системы возросли настолько, что нет даже смысла пытаться ее победить — результат предопределен.
Тем не менее, компания не останавливается на достигнутом, а продолжает работу. Благодаря исследованиям ее сотрудников на свет появилась улучшенная версия AlphaGo, которая получила название AlphaZero. Как и указано в заголовке, система сама смогла научиться играть сразу в три логических игры — шахматы, сеги и го.
Отличием новой версии от всех предыдущих стало то, что система практически всему научилась сама. Она начала с нуля и быстро научилась отлично играть во все три игры. Никто AlphaZero не помогал — система до всего «дошла сама».
Шахматы были включены в комплект, скорее, по традиции — ничего сложно в том, чтобы научить компьютер играть в шахматы, нет. Впервые компьютерную систему привлекли к игре в 1950-х годах. Затем, уже в 60-х, была создана программа Mac Hack IV, которая стала обыгрывать соперников-людей. С течением времени шахматные программы постепенно совершенствовались, а в 1997 году корпорация IBM разработала «шахматный компьютер» Deep Blue, который сумел обыграть гроссмейстера и чемпиона мира Гарри Каспарова.
Как сам он указывает, в настоящее время многие приложения на смартфоне играют в шахматы лучше, чем Deep Blue. Достигнув совершенства в создании систем, которые умеют играть в шахматы, разработчики стали создавать новые варианты компьютерных соперников человека — в частности, удалось научить компьютер играть в го. Ранее эта игра с тысячелетней историей считалась одной из самых недоступных для «понимания» компьютера. Но времена изменились. Как уже говорилось выше, AlphaGo достигла настолько высокого уровня мастерства по игре в го, что человек и рядом не стоял.
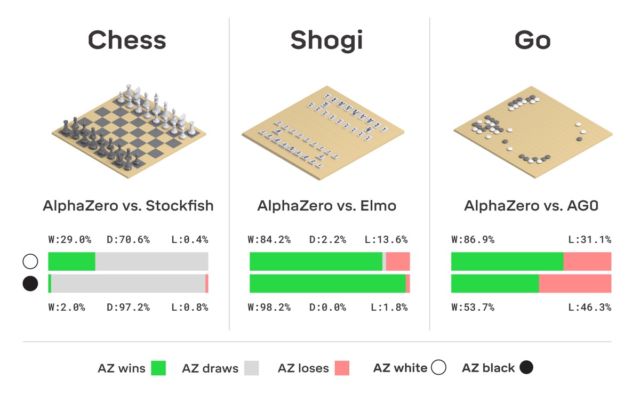
Кстати, в этом году AlphaGo получила обновление, благодаря которому теперь нейросеть может обучаться различным стратегиям игры в го без участия человека. Играя с собой снова и снова, AlphaGo совершенствуется. Именно такую систему обучения использует «потомок» AlphaGo — нейросеть AlphaZero. Всего за три дня она достигла в го такого уровня мастерства, что обыгрывает оригинальную версию AlphaGо с результатом 100 к 0. Единственное, что получает система изначально — правила игры.
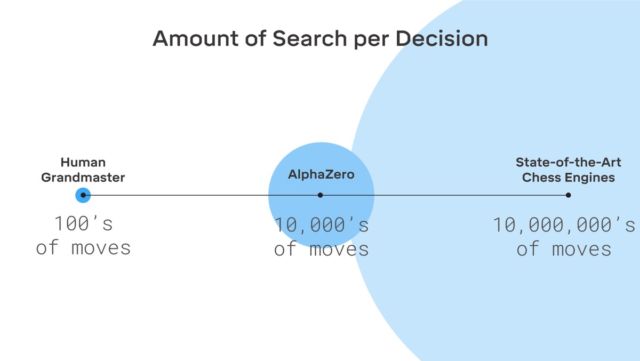
Никакой фантастики здесь нет, DeepMind использует широко известную систему машинного обучения с подкреплением. Компьютер стремится выиграть, поскольку за каждую победу получает награду (очки). Причем AlphaZero проигрывает миллионы комбинаций в процессе обучения. На просчет следующего хода и оценку вероятности победы AlphaZero тратит всего 0,4 секунды. Что касается AlphaGo оригинальной версии, то нейросеть состояла из двух элементов, двух нейросетей — одна определяла следующий возможный ход, а вторая просчитывала вероятности.
Для достижения уровня мастера в Go AlphaZero нужно «прокрутить» около 4,5 млн игр при игре с собой. А вот AlphaGo на это требовалось 30 млн игр.
Стоит отметить, что AlphaZero создали специально для игры в го. Компания не забыла об этом. Но кроме го, система способна обучаться и двум другим играм, о которых упоминалось выше. Система используется та же — машинное обучение с подкреплением. Стоит отметить, что AlphaZero работает лишь с задачами, у которых есть определенное количество вариантов решения. Также системе нужна модель окружающей среды (виртуальной).
Интересно, что тот же Каспаров считает, что человек может многое получить от систем вроде AlphaGo — научиться у них можно многому.
В настоящее время перед разработчиками стоит задача обучить компьютер играть в покер лучше, чем кто-либо из людей, а также создать систему, способную побить в честном бою любого киберспортсмена. В любом случае понятно, что нейросети и AI способны на многое.
