Как не превратить корпоративный GitHub в склад старого опенсорса
Всем привет, меня зовут Таня Хомякова, я Java-разработчик в Lamoda Tech. Моя команда отвечает за автоматизацию и поддержку процессов на двух складах Lamoda. Обычно наш код не покидает пределов внутренних репозиториев, так как это исключительно внутренняя разработка, но бывают и исключения.
В статье я расскажу, зачем мы выкладываем код в открытый доступ и как у нас выстроена работа с опенсорс-проектами. Статья будет полезна всем, кто хочет заниматься опенсорсом в компании и пока не знает, с чего начать и как организовать процесс.

Все опенсорс-проекты Lamoda Tech можно разделить на два типа. Первый — инициативы для сообщества: например, Gonkey для тестирования микросервисов или библиотека для интеграции с облачными кассами «АТОЛ». Второй — это b2b-направление: инструменты для партнеров, которые помогают взаимодействовать с нашим API.
Проекты для сообщества какое-то время существовали на уровне самоорганизации: они работали и поддерживались, пока были люди, которые горят идеей. Когда эти люди уходили, проект постепенно умирал. Из-за этого в нашем корпоративном Github скопилось много устаревших инструментов, в которых стоит очередь из пулл-реквестов и просрочены обновления безопасности.
Возник закономерный вопрос, что с этим делать. Собрали требования, обсудили — и теперь у нас есть описанные правила публикации проектов в корпоративном GitHub, которые помогают не наступать на те же грабли. Возможно, они помогут наладить процесс не только нам: расскажу обо всем на примере своего проекта Data Matrix Validator.
Как я начала выкладывать свой код
В Lamoda Tech я занимаюсь автоматизацией складских процессов, в том числе связанных с кодами маркировки — Data Matrix. С 1 июля 2019 года в России действует закон об обязательной маркировке на определенные группы товаров (табак, шубы, обувь, лекарства). Это правило не прошло мимо Lamoda: мы начали проверять маркировку поставщиков и возвращать им товар, если находили ошибки. О том, что такое Data Matrix и для чего он нужен, есть подробная статья моего коллеги «Data Matrix или как правильно маркировать обувь».
У нас постепенно накопилась большая база знаний в области маркировки товаров, которой можно было поделиться с сообществом и развивать ее дальше совместными силами. Мы разработали программу валидации DataMatrix-кодов, чтобы выявлять неизбежно возникающие при работе с данными ошибки. Например, в код может закрасться лишний GS-разделитель, неправильно экранированная кавычка. Кроме того, форматы для разных товарных групп отличаются между собой, что тоже может стать предметом путаницы.
Идея нашей программы довольно проста: пользователь загружает список кодов маркировки в текстовом формате, проверяет на соответствие правилам валидации определенной товарной группы и выгружает результат. Эта программа может быть полезна не только партнерам Lamoda, но и всем, кто сталкивается с кодами маркировки.
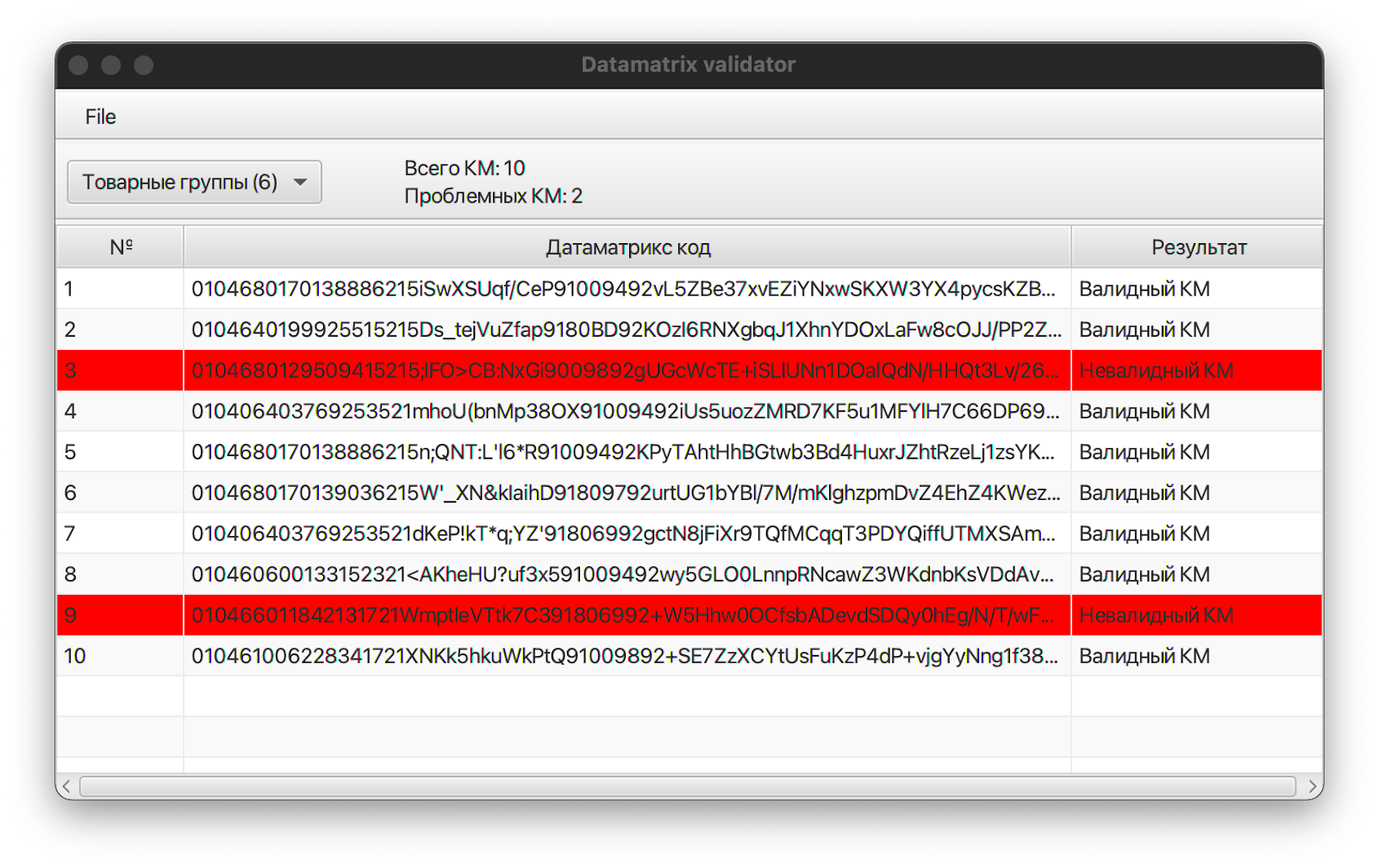
Интерфейс Data Matrix Validator
Поэтому вместе с коллегами мы решили, что GUI и библиотеку валидации стоит выложить в открытый доступ. А вот как это сделать?
Как устроен опенсорс-процесс в Lamoda Tech
Пошаговое руководство лежит в нашей корпоративной базе знаний.
1 шаг. Обсуждение на уровне команды
Прежде чем выкладывать проект в публичный репозиторий, нужно пообщаться со всеми заинтересованными лицами. На первом этапе — это команда и ее руководители.
Находим ответы на вопросы:
Инструменты вроде Data Matrix Validator обычно легко находят свою аудиторию. Работа с государственными требованиями и системами — сложный процесс, который связан с чтением многостраничной документации. У разработчиков часто не хватает на это времени, и они ищут решение проблемы в опенсорсе.
В нашей компании 20% времени команды отводится на техдолг. Работу над опенсорс-проектами мы включаем в это время.
Ответственность за проект обычно берет вся команда, и важно договориться с коллегами, кто и как часто будет проверять актуальность и вносить доработки в проект.
2 шаг. Оформление кодовой базы
Стороннему разработчику, ничего не знающему о вашей внутренней кухне, должно быть легко ориентироваться в проекте. Прежде чем наработки станут достоянием общественности, нужно провести ревью кода и оформить документацию.
Чек-лист для опенсорс-проектов, который есть у нас:
Файл .gitignore должен быть настроен правильно (пример).
Файл LICENSE с описанием лицензии. У себя мы используем MIT (пример).
README.md является лицом проекта. Он должен быть грамотно оформлен и как минимум включать:
назначение библиотеки (проекта, инструмента, фреймворка);
системные требования (версия языка, требования к ресурсам, системные зависимости, нужные расширения);
шаги по установке, сборке, запуску;
примеры использования или ссылки на документацию.
3 шаг. Согласование
Сначала с отделом безопасности. Для этого мы создаем задачу, в которой описываем детально все подробности выкладываемого проекта. В опенсорс не должен попасть код, который раскрывает нашу внутреннюю организацию.
После того, как мы получили согласие службы безопасности, переходим к System Design Review-комитету, который проходит раз в две недели. На нем собираются системные архитекторы и лиды разных направлений разработки для обсуждения изменений, вносимых в архитектуру.
Они проверяют готовность опенсорс-проекта, убеждаются, что он не требует доработок. Также на встрече решают, будет ли востребован инструмент снаружи компании и стоит ли вкладываться в его поддержку. На первом шаге мы уже обсудили этот вопрос с командой, и для встречи подготовили ответы на все вопросы. Комитет их одобрил, и проект отправился в релиз.
4 шаг. Релиз
В разных компаниях это происходит по-своему. Для нас было важно не просто публиковать проект, а привязывать его к ответственной команде. Так можно планировать доработки или исправления в соответствии с квотой на техдолг, чтобы у нас точно было время на поддержку проекта.

5 шаг. Поддержка
Это бесконечный итерационный процесс:
Проверять наличие запросов и своевременно отвечать на них.
Поддерживать код в актуальном состоянии.
Ставить задачи на внесение изменений и включать их в бэклог. Как правило, команда создает задачу в Jira со ссылкой на issue в GitHub, и таким образом учитывает потраченное время.
Что дальше
Data Matrix Validator уже опубликован и мы активно начинаем рассказывать о нем сообществу. Для меня это первый опыт с опенсорсом и приятный бонус к основной работе — проект, который принесет пользу не только нашей компании, но и широкому кругу пользователей.
А еще нам предстоит долгая и кропотливая работа по ревизии старых проектов на GitHub и их обновлению. Пожелайте удачи:)
