Как нативно визуализировать голос в iOS
Представьте, что у вас в приложении есть чат. В один прекрасный день на встрече отдела product manager приносит весть, что пора бы в чат добавить поддержку голосовых сообщений. «Да легко!» — проносится в голове: быстренько создадим новую ячейку, нарисуем в ней плеер, напишем бизнес-логику и готово. Но вдруг оказывается, что заказчик хочет плеер «как в Telegram» — с поддержкой отрисовки аудиоволны. Да ещё и динамически — в процессе записи.

Внедрять лишние сторонние зависимости в нашем проекте не особо-то и приветствуется (они требуют поддержки), и прекрасный день ставится уже не таким ярким. Почесывая затылок, отправляемся гуглить решение проблем нативным способом, но утопаем в куче абстракций, которые может быть довольно трудно понять, — особенно начинающему разработчику.
Я — Илья Черкасов, iOS-разработчик компании Surf. В статье расскажу, как нативными средствами визуализировать аудиоволну для голосовых сообщений. Объясню простым языком физические термины, с которыми можно столкнуться при поиске решения. Представлю на суд читателю свой тестовый проект.
Статья состоит из двух логических частей:
Погружение в физический уровень: как голос превращается в поток битов. Если вы это знаете, переходите сразу ко второй части.
Обзор программного уровня: откуда полученные биты можно взять и как их можно визуализировать.
Эта статья — об основах, которые необходимы для написания тестового приложения для отображения аудиоволны. Детально рассматривать работу с API в ней не будем.
Тестовое приложение >>
Решение задачи по отображению аудиоволны также описано в статье от Apple. Она изобилует не совсем простыми математическими абстракциями. Тем не менее, рекомендую с ней ознакомиться.
Статья Visualizing sound as an audio spectrogram >>
В тестовом приложении я основательно переработал проект, который прикреплён к статье от Apple. Мой проект содержит только необходимые инструменты для визуализации.
Звук на физическом уровене
Чтобы решить задачу по динамической отрисовке аудиоволны в приложении, необходимо освоить базовые абстракции. Но без привязки к физике это будет достаточно трудно сделать. Всё же микрофон — это не мысленная абстракция, а реальное устройство.Начнём издалека.
Какому человеку мы обязаны появлением такого устройства, как микрофон? Ещё в школьные годы репетитор по физике представил мне его следующим образом:
«Был такой учёный — Миша Фарадей. И он был скуп. Захотел Миша однажды поставить такой опыт: в одну руку взял катушку, на которую была намотана медная проволока, в другую — магнит. Поместил магнит внутрь катушки, и в добрых традициях советского Винни-Пуха стал наблюдать, как магнит в катушку «входит и выходит».
 Архивные записи опыта Фарадея (в цвете)
Архивные записи опыта Фарадея (в цвете)
В соседней комнате стоял прибор, с помощью которого Фарадей пытался определить, происходит ли что-то в катушке: например, не течёт ли по ней электрический ток.
Катушка и прибор были соединены проводами. Миша поиграет в ослика Иа с катушкой и магнитом в первой комнате — бежит во вторую, проверяет, не колыхнулась ли стрелка у прибора. Так и бегал он безуспешно из одной комнаты в другую 10 лет.
Только после того, как решился Миша заплатить подручному, дело сдвинулось с мёртвой точки. Фарадей проводил манипуляции с катушкой и магнитом в первой комнате, и лаборант наблюдал в этот момент за прибором в соседней комнате. И — о, чудо: помощник увидел, что стрелка на приборе начинала колебаться то в одну, то в другую сторону».
Впоследствии Фарадей выяснил, что причиной этого был электрический ток. А явление возникновения такого тока в катушке назвали явлением электромагнитной индукции. И оно как раз лежит в основе современного микрофона.
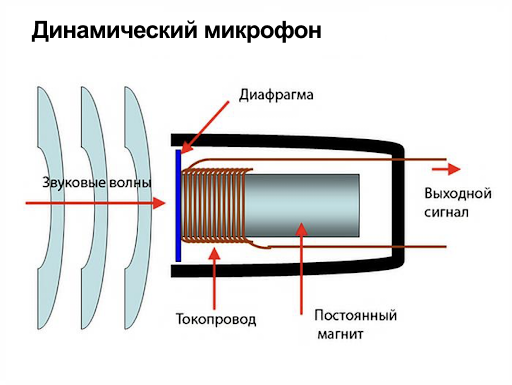 Типичная схема микрофона
Типичная схема микрофона
Методом «пристального вглядывания» заключим, что принципиально ничего не изменилось. На месте катушка и магнит, провода для передачи сигнала. Но теперь в роли Фарадея как раз выступаем мы:, а точнее, звуковые волны, которые порождаются голосовыми связками.
Небольшое отличие от опыта в том, что теперь катушка двигается относительно магнита. Но с точки зрения физики это совершенно не важно. Другими словами, голос воздействует на мембрану, мембрана толкает катушку, и за счет её движения в цепи возникает электрический ток, который поступает по проводам дальше.
Дальше — это куда? Кто превращает электрический ток в нули и единицы, которые можно обрабатывать на программном уровне? Такую магию выполняет волшебная «чёрная» коробка посередине, которая называется аналого-цифровой преобразователь (или просто АЦП). Давайте же заглянем внутрь этой черной коробки.
 Магическая коробка под названием АЦП
Магическая коробка под названием АЦП
Провода от микрофона заходят внутрь чёрной коробки. Из контекста статьи несложно догадаться, что она олицетворяет собой комнату, в которой сидит лаборант, нанятый Фарадеем. За хорошую работу лаборанту подняли ставку, и теперь он не только смотрит на то, как стрелочка покачивается из стороны в сторону. Сейчас в его обязанности входит:
Снимать показания с прибора: фиксировать, на какую величину отклоняется стрелка.
Преобразовывать показания в двоичный код.
Передавать двоичный код дальше.
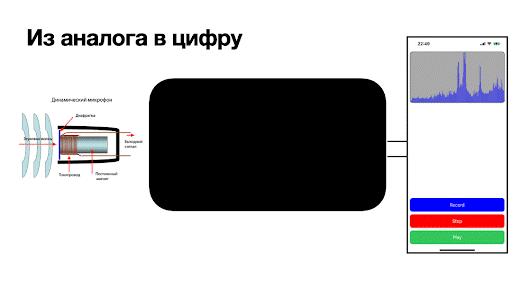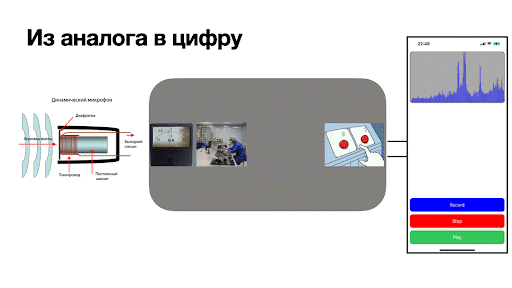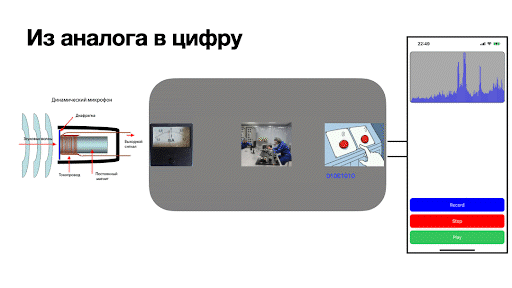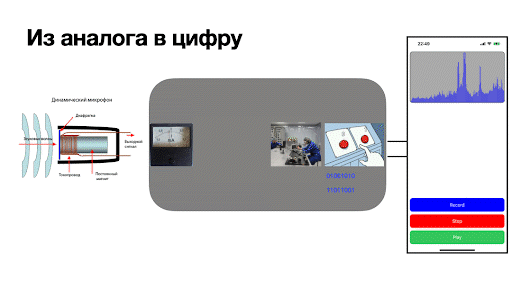
Казалось бы: что сложного в таком списке обязанностей? Но как только микрофон включается, начинаются трудности: стрелка прибора колеблется непрерывно, с микрофона всегда поступают данные. Говоря формально, получаемый уровень сигнала — величина непрерывная! И как же такой сигнал представить в двоичном коде?
Первое, что понимает лаборант: он не может всё время наблюдать за прибором. Решает действовать так:
Взглянуть на прибор.
Увидеть, на какой отметке находится стрелка.
Добежать до пульта передачи данных в другой конце комнаты и отправить 0 и 1 дальше по схемам.
Чем больше данных лаборант передаёт через пульт за единицу времени, тем качественнее он работает и тем лучше будет само качество записи. Говоря на более формальном языке, этапы работы лаборанта сводятся к процессам:
Дискретизации сигнала — снятия данных с прибора в определённые моменты времени. В нашем случае это происходит 44 100 раз в секунду. Вот так быстро должен работать лаборант. Быстрота работы лаборанта называется частотой дискретизации.
Квантования сигнала — замера уровня сигнала на амперметре.
Кодирования сигнала — перевода уровня сигнала в двоичный код (то есть работа с пультом передачи данных).
Качество прибора, с которого лаборант снимает значения, напрямую влияет на качество звука. Если прибор сделан «на коленке» и показывает значения, например, только от 0 до 10 без промежуточных вариантов, качество записи будет соответствующим: получим слишком грубые данные.
Поэтому чем точнее прибор и чем больше его шкала содержит промежуточных значений, тем точнее можно описать сигнал, приходящий с микрофона. На формальном языке количество промежуточных значений назовём «количеством уровней квантования сигнала».
Лаборант у нас нас неглупый, и решил немного оптимизировать свой рабочий процесс. Он сообразил, что так часто бегать он прибора к пульту передачи информации не очень-то и практично. Лучше подождать и некоторое время поснимать с прибора информацию. Теперь он бежит в другой конец комнаты не с одним значением, а, например, с тремя.
Дальше — больше: можно накопить сразу и 100 значений. Лаборант догадался буферизировать значения: накапливать данные и отдавать их получателю (в нашем случае — приложению) одномоментно.
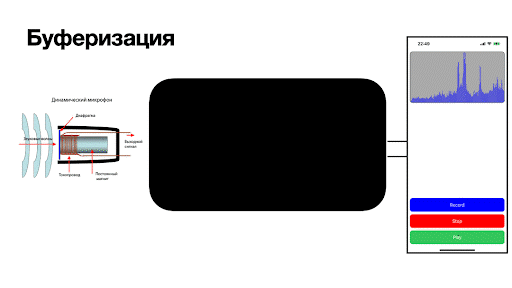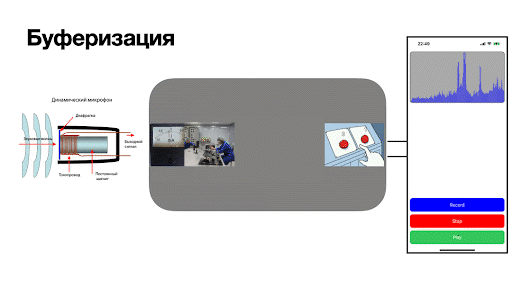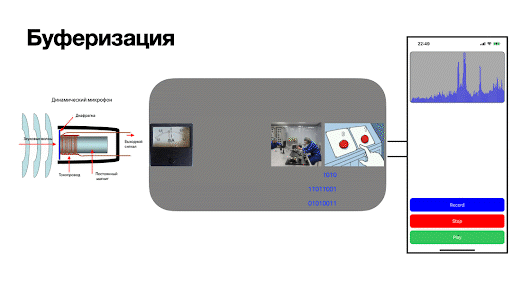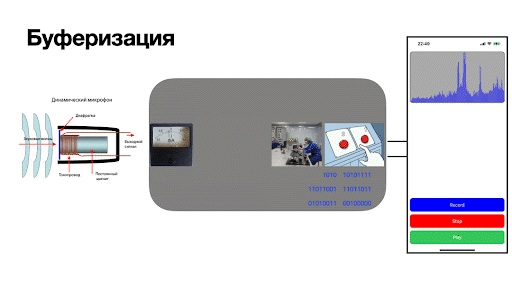
Как получить и использовать буферизированные данные в приложении
Вспомним о наших задачах:
Записать сигнал с микрофона как аудиофайл, который можно было бы отправить как голосовое сообщение.
Получить массив необработанных звуковых данных, который потом наглядно отобразить на экране.
Исходя из этих задач, можно спроектировать приложение так:
Сначала запросим доступ к микрофону — иначе изготавливать аудиобуферы будет не из чего.
Добавим функцию, через которую будем получать аудиобуферы.
Сконфигурируем сущность
writer, которая будет записывать аудиофайл в память устройства из получаемых буферов.Создадим сущность
DatasetProvider, которая будет подготавливать необработанные звуковые данные к репрезентируемым — назовём ихdataset. Пункт опциональный, пригодится для разгрузки логики.В конце добавим некоторое представление, которое будет отрисовывать
datasetкак звуковую волну
Реализуем все пункты нативными средствами, и для первых трёх будем использовать AVFoundation. Фреймворк поможет получить доступ к микрофону, предоставит функцию для получения буферов и writer, который запишет аудиофайл.
Опишем каждый пункт детальнее.
Открытие аудиосессии
Начнём с инициализации сессии захвата звука.
private let captureSession = AVCaptureSession()Необходимо создать экземпляр вспомогательного класса, который позволит выводить эти аудиоданные и получить к ним доступ.
private let audioOutput = AVCaptureAudioDataOutput()В конфигурацию сессии входит настройка звукового ВХОДА (микрофона) и ВЫХОДА (только что созданного audioOutput). Приложение должно иметь доступ к микрофону.
guard
let microphone = AVCaptureDevice.default(
.builtInMicrophone,
for: .audio,
position: .unspecified
),
let microphoneInput = try? AVCaptureDeviceInput(device: microphone) else {
return
}
if captureSession.canAddInput(microphoneInput) {
captureSession.addInput(microphoneInput)
}
if captureSession.canAddOutput(audioOutput) {
captureSession.addOutput(audioOutput)
} else {
print("Can't add `audioOutput`.")
return
}Конфигурация writer
Фреймворк поставляет уже готовую сущность для записи аудиофайла из буферов.
private var writer: AVAssetWriter?Я объявил writer опциональным свойством. В теории попытка создать инстанс может закочниться неудачей, инициализатор AVAssetWriter способен выкинуть ошибку.
Конфигурируем настройки вывода.
let outputSettings: [String : Any] = [
AVFormatIDKey: UInt(kAudioFormatLinearPCM),
AVSampleRateKey: 44100,
AVNumberOfChannelsKey: 2,
AVLinearPCMBitDepthKey: 16,
AVLinearPCMIsNonInterleaved: false,
AVLinearPCMIsFloatKey: false,
AVLinearPCMIsBigEndianKey: false
]Ключ
AVFormatIDKeyопределяет формат записываемого файла: в данном случае его значение означает, что сжимать данные я не собираюсь, аудио будет записано в максимальном качестве, без потерь.AVSampleRateKeyопределяет частоту дискретизации сигнала.AVNumberOfChannelsKeyопределяет количество каналов в записи. В нашем случае их два — это стерео. Если бы канал был один — это монофонический режим.AVLinearPCMBitDepthKeyотвечает за количество уровней квантования сигнала. Выражается в битах. Больше битов — больше уровней квантования. Нам будет достаточно 16 бит.AVLinearPCMIsBigEndianKeyуказывает на порядок байтов в записи. В данном случае он будет обратным (little — endian). Попробуйте поменять значение ключа на true, и приложение упадет с ошибкой «WAVE files cannot contain big-endian LPCM».
Ключи
AVLinearPCMIsNonInterleavedиAVLinearPCMIsFloatKey, на мой взгляд, сильно уведут повествование в сторону, но я оставляю ссылки, где можно будет чуть подробнее прочитать про их смысл.https://stackoverflow.com/questions/17879933/whats-the-interleaved-audio
https://stackoverflow.com/questions/32128206/what-does-interleaved-stereo-pcm-linear-int16-big-endian-audio-look-like
https://rmmedia.ru/threads/62680/
https://audiocoding.ru/articles/2008–05–22-wav-file-structure/
Как и в предыдущем случае, понадобится вспомогательный класс writerInput. В тестовом проекте он выполняет роль «накопителя» буферов.
private lazy var writerInput = AVAssetWriterInput(
mediaType: AVMediaType.audio,
outputSettings: outputSettings
)Вишенкой на торте служит инициализация writer через do-catch блок.
do {
writer = try AVAssetWriter(outputURL: fileURL,fileType: .wav)
writer?.add(writerInput!)
self.writer?.startWriting()
self.writer?.startSession(atSourceTime: .zero)
} catch let error {
print(error)
}Функция, которая будет поставлять буферы
Вызываем у audioOutput функцию setSampleBufferDelegate, назначаем делегатом класс, в котором конфигурировали сущности сверху. Вторым аргументом передаём заранее инициализированную очередь, в которой будет происходить захват данных.
audioOutput.setSampleBufferDelegate(
self,
queue: captureQueue
)Подписываемся под протокол AVCaptureAudioDataOutputSampleBufferDelegate. Реализуем метод captureOutput из этого протокола:
func captureOutput(_ output: AVCaptureOutput,
didOutput sampleBuffer: CMSampleBuffer,
from connection: AVCaptureConnection) И — ура, среди списка аргументов видим заветный didOutput sampleBuffer —CMSampleBuffer.
Запись файла осуществить достаточно просто: достаточно вызвать у writerInput функцию append и передать в неё sampleBuffer. writerInput преобразовывает буферы в аудиофайл, никаких дополнительных манипуляций делать не нужно.
Теперь задача состоит в получении данных для визуализации аудиодорожки. Помогать в этом будет функция CMSampleBufferGetAudioBufferListWithRetainedBlockBuffer с внушительным списком аргументов. Разбирать все аргументы функции в данной статье не будем.
var audioBufferList = AudioBufferList()
var blockBuffer: CMBlockBuffer?
CMSampleBufferGetAudioBufferListWithRetainedBlockBuffer(
sampleBuffer,
bufferListSizeNeededOut: nil,
bufferListOut: &audioBufferList,
bufferListSize: MemoryLayout.stride(ofValue: audioBufferList),
blockBufferAllocator: nil,
blockBufferMemoryAllocator: nil,
flags: kCMSampleBufferFlag_AudioBufferList_Assure16ByteAlignment,
blockBufferOut: &blockBuffer
)Исходя из нейминга, функция отдаёт некоторую сущность AudioBufferList. Исходя из документации, AudioBufferList — структура, которая предоставляет следующие свойства для взаимодействия с ней:
Сразу же бросается в глаза нестыковка: нейминг и тип значения не соответствуют друг другу. При обращении к этому свойству мы ожидаем получить массив [AudioBuffer], и по итогу возвращается кортеж с одним AudioBuffer. Почему так? Swift оборачивает оборачивает сишный код в свои абстракции.
Как можно вспомнить, в Си массивы можно задать уже только с каким-то заранее известным размером: динамически увеличивать количество элементов не выйдет. Поэтому инициализатор сишной структуры, содержащий массив из n-го количества элементов, в Swift превращается в инициализатор, содержащий кортеж с таким же количеством одинаковых элементов. Иными словами, если в Си структура выглядит как:
typedef struct {
char testVar[3];
} TestTuplesStruct;То в Swift она будет представлена как:
TestTuplesStruct(testVar: (CChar, CChar, CChar))Подробнее можно прочитать об этом в статье Swift imports fixed-size C arrays as tuples.
Однако AudioBufferList может содержать в себе больше, чем один буфер. Покопавшись поглубже, можно найти расширение:
extension AudioBufferList {
/// - Returns: the size in bytes of an `AudioBufferList` that can hold up to
/// `maximumBuffers` `AudioBuffer`s.
public static func sizeInBytes(maximumBuffers: Int) -> Int
/// Allocate an `AudioBufferList` with a capacity for the specified number of
/// `AudioBuffer`s.
///
/// The `count` property of the new `AudioBufferList` is initialized to
/// `maximumBuffers`.
///
/// The memory should be freed with `free()`.
public static func allocate(maximumBuffers: Int) -> UnsafeMutableAudioBufferListPointer
}С помощью статической функции allocate можем выделить себе память под нужное количество AudioBuffer и обращаться к ним как элементам массива.
Пример на Stackoverflow >>
Вернемся к приложению. В AudioBufferList записался AudioBuffer. Извлекаем его обращением к свойству mBuffers. AudioBuffer в свою очередь имеет свойство mData, которое отдает указатель на начало raw-аудио данных. Превращаем его в типизированный указатель. Учтём, что заданное количество уровней квантования в AVLinearPCMBitDepthKey равно Int16.
guard let data = audioBufferList.mBuffers.mData else {
return
}
let actualSampleCount = CMSampleBufferGetNumSamples(sampleBuffer)
let ptr = data.bindMemory(to: Int16.self, capacity: actualSampleCount)Осталось обернуть указатель в UnsafeBufferPointer, который подписан под протокол Sequence. А это значит, что можно использовать UnsafeBufferPointer для инициализации массива. Такие данные уже можно передавать на дальнейшую обработку.
В моём тестовом приложении это класс RecordViewController. Я подписал его под протокол RawAudioDataReceiverDelegate, который содержит функцию rawAudioDataOutput(_ raw: [Int16]). Используя контроллер как делегат, я передаю через эту функцию массив с необработанным данными:
let buf = UnsafeBufferPointer(start: ptr, count: actualSampleCount)
rawAudioDataReceiverDelegate?.rawAudioDataOutput(Array(buf))Слой для подготовки данных для отображения
Я завел отдельную сущность datasetProvider для накопления полученных массивов. При вызове функции append и передачи ему массива происходит следующее: вычисляется среднее арифметическое всех значений, которые мы передали в массиве. Оно записывается в хранимое свойство dataset внутри провайдера.
Примерная реализация этого слоя находится в репозитории. Но это далеко не единственный способ обработать данные — всё зависит от вашей фантазии. Получить обработанные данные можно вызовом функции provide() у datasetProvider.
func rawAudioDataOutput(_ raw: [Int16]) {
DispatchQueue.main.async { [weak self] in
self?.datasetProvider.append(raw)
self?.waveForm.displayFromDataset(self?.datasetProvider.provide() ?? [])
}
}Отрисовка звуковой волны
Для визуализации обработанных данных я использовал стандартные средства UIView. Помним, что на вход поступает массив средних значений. Естественной репрезентацией таких значений могут быть столбики разной высоты.
import UIKit
final class WaveFormView: UIView {
// MARK: - Nested types
struct Constants {
let widthRatio: CGFloat = 0.5
}
// MARK: - Private properties
private let constants = Constants()
private var colomnsRect = [CGRect]()
private var pathBuffer = UIBezierPath()
// MARK: - Initialization
override init(frame: CGRect) {
super.init(frame: frame)
reflectAndFlip()
}
required init?(coder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
// MARK: - UIView lifecycle
override func draw(_ rect: CGRect) {
pathBuffer.removeAllPoints()
colomnsRect.forEach { pathBuffer.append(UIBezierPath(rect: $0)) }
UIColor.blue.setFill()
pathBuffer.fill()
}
}
// MARK: - WaveFormDisplayable
extension WaveFormView: WaveFormDisplayable {
func displayFromDataset(_ dataset: Dataset) {
colomnsRect = calculateColomnRect(from: dataset)
setNeedsDisplay()
}
}
// MARK: - Private functions
private extension WaveFormView {
func reflectAndFlip() {
transform = CGAffineTransform(scaleX: 1, y: -1)
}
func calculateColomnRect(from dataset: Dataset) -> [CGRect] {
guard
let max = dataset.max(),
max > 0 else {
return []
} //Выбираем максимальное значение среди данных для масштабирования
var colomnsRect = [CGRect]() //сюда будем записывать результаты вычисления размеров и origin наших столбцов
let distanceBetweenOriginsOnX = frame.width / CGFloat(dataset.count) //Вычисляем расстояние между origin двух соседних столбцов
let heightRatio = frame.height / max
dataset.forEach {
// Высоту получаем путём умножения соответствующего значения из dataset на коэффициент масштабирования
let height = $0 * heightRatio
let previousColomnOrigin = colomnsRect.last?.origin ?? .zero
let size = CGSize(
//Ширину столбца получаем как расстояние между origin двух соседних столбцов, умноженное на коэффициент, который меньше единицы.
//Чем больше коэффициент, тем жирнее будут столбцы.
width: distanceBetweenOriginsOnX * constants.widthRatio,
height: height
)
colomnsRect.append(
CGRect(
//Origin текущего столба получаем сдвигом origin предыдущего на его ширину
origin: previousColomnOrigin.moveBy(x: distanceBetweenOriginsOnX),
size: size
)
)
}
return colomnsRect
}
}Если вкратце, я:
Выбирал максимальное значение среди данных для масштабирования, рассчитывал коэффициенты масштабирования.
Ширину столбца получал как расстояние между origin двух соседних столбцов, умноженное на коэффициент, который меньше единицы.
Высоту получал путём умножения соответствующего значения из dataset на коэффициент масштабирования.
Для отрисовки использовал функцию draw, в которую поместил кривую Безье.
Для воспроизведения записанного файла использую обычный AVAudioPlayer. Предлагаю читателю попробовать приложение на реальном устройстве (не на симуляторе!).
 Тестовое приложение: https://github.com/ilya-r-cherkasov/WaveForm
Тестовое приложение: https://github.com/ilya-r-cherkasov/WaveForm
Для тех, кто хочет покопаться в теме детальнее, собрал все материалы, которыми пользовался.
