Как мы отказоустойчивый кластер запускали

Ошибки и сложности, с которыми мы столкнулись, запуская собственный кластер на базе VMmanager Cloud + Ceph.
Предыстория
К нам в FirstVDS приходят разные люди. Кому-то достаточно хостинга на базе CMS, кому-то виртуального сервера. Но иногда человек просит производительный сервер с повышенной надежностью, при этом его не сильно волнует стоимость услуги.
Мы уверены в наших обычных VDS, но решили создать отдельную услугу, которая за более высокую цену обеспечивала бы гарантированную отказоустойчивость, подкрепленную SLA. Задача решается созданием кластера повышенной надежности, однако, у нас были сомнения в сетевых технологиях. Как-то собрали кластер на гигабитной сети — для себя, чтобы попробовать. Ничего не вышло — сеть тормозила, кластер работал очень медленно, использовать его для практических задач было невозможно.
Сложилось впечатление, что распределённые системы уступают в скорости классическим решениям. Мы знали о технологии InfiniBand, но не были готовы тестировать на себе — оборудование-то дорогое. Сам коммутатор стоит порядка 5000$, сетевая карта 780$, и ещё кабель 100$. Итого, подключение одного сервера в сеть IB обходится в 1300$. Задумка получила продолжение благодаря удачному стечению обстоятельств.
В мае 2014 года наш директор Алексей Чекушкин в очередной раз отправился на конференцию Хостобзор. Это такая закрытая тусовка, где встречаются представители хостингов и делятся опытом. На конференции Алексей прослушал доклад об опыте использования InfiniBand, а затем побеседовал с докладчиком лично. Оказалось, что IB отлично справляется со своими задачами — сеть действительно работает на скорости 56 Гбит/сек, а сетевые задержки такие низкие, что незаметны на фоне дисковых задержек. Т.е. не важно — установлен ли диск локально, или компьютер обращается к нему по сети. Именно это и требовалось для создания распределённого кластера.
В августе 2014 купили необходимое оборудование и приступили к сборке.
Первая версия кластера
Хостинг FirstVDS уже 13 лет сотрудничает с компанией ISPsystem. Используем BILLmanager в качестве биллинговой платформы, на клиентские серверы устанавливаем ISPmanager как панель управления, для управления виртуальными машинами используем VMmanager. За годы сотрудничества с ISPsystem накопили большой опыт работы с продуктами, и ни разу не усомнились в профессионализме разработчиков. Поэтому решили использовать VMmanager Cloud для построения кластера. Тем более, что в спецификациях заявлена поддержка Ceph — именно его мы хотели использовать для хранения данных.
Стэк технологий для построения кластера высокой доступности получился таким:
- VMmanager Cloud — запуск виртуальных машин «в облаке»
- Ceph — сетевое распределённое хранилище данных
- InfiniBand — сеть, связь между машинами кластера
VMmanager Cloud фактически поддерживал Ceph, но мы были первыми, кто попробовал в деле. По мере реализации проекта возникли идеи по улучшению продукта — ISPsystem шли навстречу и дорабатывали VMmanager Cloud «на лету».
Специально для кластера купили:
- Машины Xeon 2630. Такие же машины используются для нашего обычного хостинга виртуальных серверов.
- Коммутатор InfiniBand SX6005 — модель на 12 портов, мы рассчитали, что такой будет достаточно
- Карты для подключения компьютеров к сети HCA Mellanox InfiniBand
- Кабели DAC — для соединения составляющих в сеть
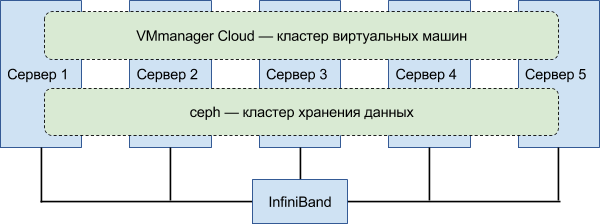
Хостинг высокой доступности состоит из двух кластеров — кластера хранения и вычислительного.
Вычислительный кластер работает под управлением VMmanager Cloud и отвечает за запуск клиентских виртуальных серверов на физических машинах кластера. Конфигурации всех виртуальных машин VMmanager хранит в базе данных, реплика базы хранится на каждой ноде вычислительного кластера. Поэтому, при выходе из строя любой из них, клиентский виртуальный сервер просто перезапускается на другой — происходит перебалансировка.
Кластер хранения работает под управлением Ceph и отвечает за хранение информации. Количество реплик одного блока данных (default pool size) установили равное 3 — все данные хранятся в трёх копиях. Если отключается диск или целая нода и одна из копий теряется, Ceph создает рабочую копию файлов из двух оставшихся. Кроме этого, в таких случаях система создает недостающие копии файлов на имеющемся дисковом пространстве — этот процесс также называется перебалансировкой.
Дублирование оборудования и избыточное хранение данных и обеспечивают повышенную отказоустойчивость.
Первая версия состояла из 5 серверов, объединенных в сеть с помощью IB. Ceph не поддерживал протокол IB на тот момент, поэтому использовали IPoIB. Ceph — многосоставное ПО. Мы используем две части: монитор кластера (ceph-mon) и демон хранилища (ceph-osd).
Для хранения на каждый сервер устанавливали 2 диска по 2 Тб и один SSD на 400 Гб для кэширования. Такая концепция — кэширование чтения-записи на быстрых носителях — поддерживается Ceph. Мы решили ею воспользоваться, чтобы не повышать цену для конечного пользователя из-за SSD-накопителей.
В первой версии обе задачи — вычисления и хранения — были запущены на одних и тех же нодах.
Сначала запустили на кластере синтетические тесты: создали VDS-болванки, смотрели, как система будет работать под нагрузкой. Для проверки связности кластера отключали диски и отдельные ноды — смотрели, как кластер будет перераспределять нагрузку и записанные данные.
После тестов стали запускать на кластере обычные клиентские VDS. Так мы увидели, как кластер ведёт себя в «боевом» режиме.
Система работала, но производительность была ниже ожидаемой. Скорость передачи данных по IB всего 20 Гбит/сек вместо заявленных 56 Гбит/сек. Грешили на InfiniBand, но позже выяснили, что дело было в другом. Медленно работала вся система: данные с виртуальных серверов не успевали записываться и вставали в очередь. Одни процессы ждали, пока другие процессы дождутся записи на диск, чтобы освободить процессор. Всё это наваливалось как снежный ком, увеличивая расходы на выполнение обслуживающих операций.
Кластер справлялся с задачами — при выходе из строя дисков или нод целиком, он продолжал функционировать. Однако, каждая перебалансировка превращала ситуацию в критическую. При добавлении нового диска сглаживали пик нагрузки, используя веса. Вес отвечает за степень использования конкретного физического носителя. Устанавливаем новый диск, ставим вес 0 — диск не используется. После этого увеличиваем вес постепенно, и перебалансировка происходит маленькими порциями. Если же диск выходит из строя, то веса не срабатывают: ~1 Тб реплик надо «размазать» по оставшимся дискам сразу, и Ceph надолго уходит в режим записи данных, загружая диски «пустой» работой.
Во время технических работ пользователи замечали, что сайты тормозят. Старались решать проблемы с железом как можно быстрее, чтобы сохранять качество сервиса на должном уровне.
Экспериментировали с конфигурацией: добавляли ноды, диски, оперативную память. Каждую конфигурацию проверяли сначала на синтетических тестах, потом открывали настоящие виртуалки новых клиентов. При увеличении количества VDS кластер начинал работать нестабильно, и мы переносили клиентские машины на обычные ноды. Поскольку такие переносы были плановыми и проходили в штатном режиме, то они не доставляли никаких неудобств клиентам.
После нескольких итераций стало ясно, что ситуация кардинально не меняется. Приняли решение перенести клиентов на обычные ноды и расформировать кластер.
Вторая версия кластера
Первая версия кластера не оправдала ожиданий. Клиенты сталкивались с дисковыми тормозами, а мы уделяли слишком много времени технической поддержке кластера. Решили взять перерыв, но совсем от идеи — запустить собственный сервис высокой доступности — не отказались. Да и коммутатор IB без дела лежит.
В первой версии одни и те же ноды отвечали и за хранение данных, и за работу виртуальных машин. Поломка одного физического сервера слишком сильно нагружала систему, так как одновременно запускалась и перебалансировка по нодам виртуальных машин, и создание недостающих реплик данных. Для разделения нагрузки применили классическую архитектуру:
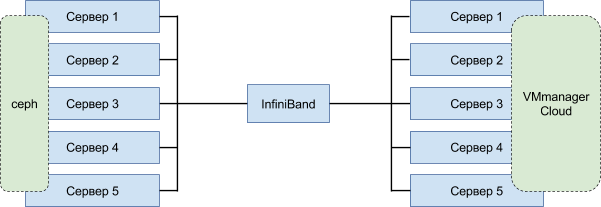
Организовали два раздельных кластера: один для хранения данных, другой для запуска виртуальных машин.
Чтобы опробовать новую архитектуру и избавиться от прежних недостатков, собрали тестовый стенд. И тут выяснилось интересное — специально купленные для сборки первой версии серверы оказались «палёными». Системная шина всех серверов работала медленно. В результате, все устройства, связанные с северным и южным мостами — карты IB, подключенные по PCI-E, диски, память — также работали медленно. Это объясняло большую часть проблем, с которыми мы столкнулись. В качестве пробы взяли несколько свободных нод, на которых обычно запускаем клиентские VDS. По тех. характеристикам они почти ничем не отличались. Собрали и запустили кластер на этих машинах, стали прогонять тесты. Всё летает! И даже сеть IB выдает заявленные 56 Гбит/сек.
Перед запуском в работу мы реорганизовали дисковое хранилище: купили новые серверы на базе Xeon 2630 с большим количеством дисковых корзин — на вырост. Обзавелись внешним контроллером жестких дисков для более эффективной работы дисковой подсистемы. В итоге, на каждой машине кластера хранения трудились 6 дисков: 4 HDD по 4–8 Тб + 2 SSD по 500 Гб.
В итоге вся сборка состояла из 12 машин: 3 в кластере хранилища и 9 в вычислительном кластере. После обкатки тестового стенда в сентябре 2015 запустили кластер как отдельную услугу — отказоустойчивый виртуальный сервер.
Около 5-ти месяцев система замечательно работала, радуя нас и клиентов. Так было, пока количество клиентов не достигло критического значения. Вместительные диски по 4–8 Тб всё-таки вылезли нам боком. При заполнении диска уже наполовину, он превращался в бутылочное горлышко — большое количество файлов, принадлежащих разным VDS, располагались на одном физическом носителе, и ему приходилось обслуживать большое количество клиентов. При выходе его из строя перебалансировка тоже проходила тяжело — надо перераспределить большой объём информации. SSD-кэш в таких условиях плохо справлялся со своими обязанностями. Рано или поздно диск кэша переполнялся и давал сигнал — с этого момента я ничего не кэширую, а только записываю сохраненную информацию на медленный HDD-диск. HDD-диск испытывает в это время двойную нагрузку — обрабатывает прямые обращения, которые поступают минуя кэш, и записывает сохраненные в кэше данные. Хранилище хорошо работало, пока дело не доходило до изменения дисковой конфигурации. Выпадение диска или добавление нового сильно замедляло общую пропускную способность хранилища.
Третья версия кластера
Беда не приходит одна. 18 февраля 2016 мы столкнулись с критическим багом Ceph: в процессе скидывания кэша на диск происходила некорректная запись блока данных. Это приводило к отключению процессов ceph-osd всех дисков, где хранились реплики злосчастного блока. Система сразу лишалась трёх дисков, а значит и всех файлов, размещенных на них. Запускался процесс перебалансировки, но не мог завершиться до конца — ведь из системы пропадали все три копии как минимум одного блока данных (и соответствующего файла), с которого началась проблема. Консистентность хранилища была под угрозой. Мы вручную удаляли ошибочные блоки, перезапускали процессы ceph-osd, но это помогало ненадолго. Ошибочная запись повторялась, балансировка начиналась снова, и хранилище рушилось.
Напряженный поиск в интернете дал результат — закрытая бага в последнем на тот момент релизе Ceph Hammer. Наше хранилище запущено на предыдущей версии — Firefly. К счастью, в Ceph действует система бэкпортов: фиксы критических багов добавляются в предыдущие версии, чтобы сохранить совместимость при миграции.
Предупредили клиентов о недоступности серверов и приступили к обновлению. Переключились на другой репозиторий, в который залит фикс баги, выполнили yum update, перезапустили процессы Ceph — не помогло. Ошибка повторяется. Локализовали источник проблемы — запись из кэша в основное хранилище — и отключили кэширование полностью. Клиентские серверы заработали, но каждая перебалансировка превращалась в ад. Диски не справлялись с обслуживанием системной балансировки и клиентского чтения-записи.
Решили проблему кардинально — отказались от SSD-кэша и поставили SSD-накопители в качестве основных. Тут помогли ноды с большим количеством дисковых корзин, предусмотрительно купленные для кластера хранения. Заменяли постепенно: сначала добавили по четыре SSD в оставшиеся пустые корзины на каждом сервере, а после балансировки данных, стали по одному заменять старые HDD-диски на SSD. Делали по схеме: удаление диска, установка диска, балансировка данных, удаление, установка, балансировка и так далее по кругу, пока в нодах не остались только SSD. Заменяли на горячую, поскольку потеря одного накопителя никак не сказывается на работоспособности кластера хранения.
Использовали промышленные накопители Samsung 810 размером 1 Тб. Не стали использовать SSD большего размера, чтобы не провоцировать ситуацию «узкого горлышка», когда на одном физическом носителе располагается много данных, и, следовательно на него приходится большое количество обращений.
Таким образом, постепенно мы заменили все накопители на SSD. И наступило счастье — кластер стал работать как часы. Пиковые нагрузок при возникновении проблем с железом прекратились, перебалансировка происходит незаметно для клиентов. Позже всё-таки пришлось уплотнить хранилище и заменить диски на 2-терабайтные Samsung 863. Замена никак не отразилась на работе кластера хранения.
В такой конфигурации наш отказоустойчивый кластер работает и по сей день. А имя ему — Атлант:)
Технические показатели кластера
Сравнение виртуальной машины в кластере (ceph) с виртуальной машиной на обычной ноде с SSD-накопителями (ssd).
Запись: ceph: bw=393.181 KB/s, iops=3071
ssd: bw=70.371 KB/s, iops=549
Чтение: ceph: bw=242.129 KB/s, iops=1891
ssd: bw=94.626 KB/s, iops=739
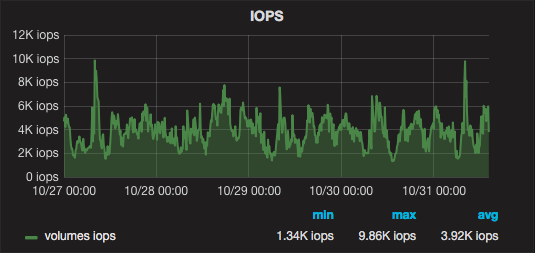
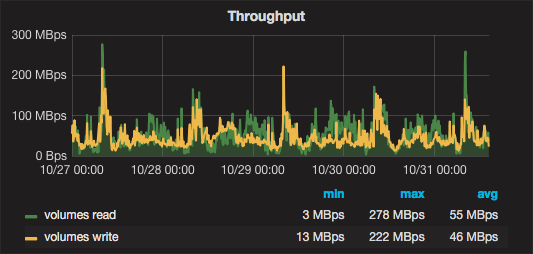
Несколько дней работы кластера в графиках:
Перспективы развития
Сейчас IB-коммутатор задублирован обычным гигабитным Ethernet-коммутатором. Это необходимо для того, чтобы кластер не потерял связность при выходе основного коммутатора из строя. На подхвате стоит резервный IB-коммутатор, но переключать на него узлы кластера придется в случае неполадки вручную. После сбоя система продолжит работать с деградацией производительности на 5–10 минут. Это время необходимо для физического переключения на резервный IB-коммутатор.
Планируем полностью задублировать IB-коммутатор, чтобы при выхода из строя основного второй мгновенно взял всю нагрузку на себя. Это не так просто, как кажется — необходимо в каждый сервер установить вторую HCA-карту. Не на всех нодах есть дополнительный PCI-E, поэтому некоторые придется заменять целиком. Можно поставить одну двухпортовую карту, но такое решение не спасает от выхода из строя самой карты.
Также планируем развивать кластер в ширину — ноды рано или поздно заполнятся, а для подключения новых нод портов почти не осталось. Необходимо добавить ещё один IB-коммутатор и соединять с имеющимся последовательно.
Заключение
Мы использовали для создания кластера повышенной надежности VMmanager Cloud и Ceph. Вот наши рекомендации, если вы решите использовать эти же технологии:
- Используйте LTS-выпуски Ceph. Не рассчитывайте, что будете накатывать новую версию с каждым релизом. Обновление — потенциально опасная операция для хранилища. Переход на новую версию повлечёт изменения в конфигах, и не факт, что хранилище заработает после обновления. Отслеживайте багфиксы — они бэктрекаются из новых версий в старые.
- Используйте быстрые SSD-накопители в качестве основных. Не нужно использовать диски большого объема. Лучше поставить 2 диска по 1 Тб чем 1 на 2 Тб. Подход с кэшированием не оправдывает себя. Придется сильно заморочиться как с настройками, так и с последующей поддержкой.
- Для хранилища используйте ноды с большим количеством дисковых корзин. Либо будьте готовы подключать дополнительные ноды по мере разрастания кластера.
