Как мы контролируем работу облаков с тысячами виртуальных машин и сотнями тысяч приложений
Как и многие другие вендоры ПО, 1С давно предлагает свои продукты в облачном варианте. Это, в первую очередь, наши облачные сервисы 1С: ГРМ (Готовое Рабочее Место) и 1cFresh. Предоставление облачных сервисов требует наличия соответствующей инфраструктуры — прежде всего серверов, на которых размещаются виртуальные машины с приложениями, и софта, управляющего физическими и виртуальными машинами.
Чем сложнее инфраструктура, тем выше вероятность возникновения ошибок. Своевременно исправлять ошибки (а ещё лучше — предсказывать их возникновение и своевременно реагировать) — одна из главных задач провайдера облачных сервисов. Для таких задач разрабатываются системы интеллектуального мониторинга, которые помогают в сопровождении больших облачных продуктов. И у нас такая система тоже есть, мы разработали её сами на Java. О ней мы и хотим рассказать.

Рабочее название системы — «Система интеллектуального RCA мониторинга». Разработка и обкатка системы потребовали около одного человеко-года.
Целью разработки было повышение качества работы предоставляемых сервисов. Для этого нужно:
Снизить количество поломок.
Уменьшить время реагирования и расследования инцидентов.
Поддерживать работоспособность на необходимом уровне.
Получать полную информацию о состоянии информационной системы.
В то же время мы хотели решить и бизнес-задачи:
Минимизировать рост расходов на поддержку при росте инфраструктуры.
Снизить зависимость от сторонних продуктов.
Прежде чем начать проектировать систему мониторинга — надо понять, а что, собственно, мы хотим мониторить. Для себя мы решили так. Объект мониторинга — это сущность системы, предоставляющая какую-либо функциональность, например, выполнение какой-либо функции или обеспечение работоспособности какого-то узла (скажем, сервера-хоста).
Наша система интеллектуального мониторинга (и, наверное, не только наша) — это набор сервисов, позволяющих получить полную картину обслуживаемой системы и своевременно получать оповещения о поломках. Для этого система должна:
Позволять добавлять и удалять объекты мониторинга.
Строить зависимости между объектами мониторинга.
Определять причину поломок для ускорения расследования инцидентов.
Собирать данные для предсказания инцидентов.
Своевременно информировать администраторов об ошибках.
Быть достаточно интеллектуальной, чтобы отличать критичные сбои от допустимых.
Чтобы понять, какая система нам нужна, мы посмотрели на основные решения, представленные на рынке систем управления производительностью приложений (Application Performance Management, APM) и операционной IT-аналитики (IT Operations Analytics, ITOA).
Хотим отметить, что информация в таблице ниже носит субъективный
характер — мы оценивали, как то или иное ПО подходит для решения именно наших
задач.

Проанализировав все плюсы и минусы существующих решений, мы выделили основную функциональность и спроектировали собственную систему. Её основой являются следующие механизмы:
Сервис регистрации объектов мониторинга.
Сервис поиска первопричины поломки (Root Cause Analysis, RCA).
Сервис регистрации источников телеметрии.
Сервис визуального отображения.
Система оповещений.
Рассмотрим каждый из них подробнее.
Сервис регистрации объектов мониторинга
Это разработанный нами сервис, позволяющий с помощью HTTP-запросов регистрировать объекты мониторинга и зависимости между ними. Поскольку зависимости сложные, мы представляем их в виде ориентированного графа и храним в графовой базе данных Neo4j.
Объекты мониторинга регистрируются в процессе развертывания компонентов и сервисов. Компоненты и сервисы (виртуальные хосты, сервера СУБД, кластеры серверов 1С и т.д.) разворачиваются с помощью скриптов, написанных на Python. В скриптах прописаны зависимости между объектами мониторинга, в процессе развертывания выполняется POST-запрос к сервису регистрации, а сервис регистрации сохраняет данные в графовой базе данных, при и этом также составляются графы зависимостей объектов мониторинга друг от друга.

Сервис RCA (Root Cause Analysis)
Сервис RCA — это один из самых интересных компонентов нашего решения. Он позволяет быстро найти причину ошибки в объекте мониторинга.
В процессе развертывания инфраструктуры у нас уже построен ориентированный граф зависимостей объектов мониторинга. Для примера рассмотрим такой граф для физического сервера-хоста.

В данном случае объект мониторинга — это работоспособность физического сервера-хоста. По графу видно, что работоспособность хоста зависит от доступности его диска, CPU и оперативной памяти, а их доступность зависит ещё от ряда метрик.
На картинке показана ситуация, когда использование оперативной памяти хоста превысило критическое (заданное нами) значение. Как следствие — объект мониторинга RAM стал нефункциональным, что привело к неработоспособности хоста. Регистрация в системе этих трех событий, а также информация о связях между объектами мониторинга (хранящаяся в графовой базе данных), позволит нам определить первопричину поломки.
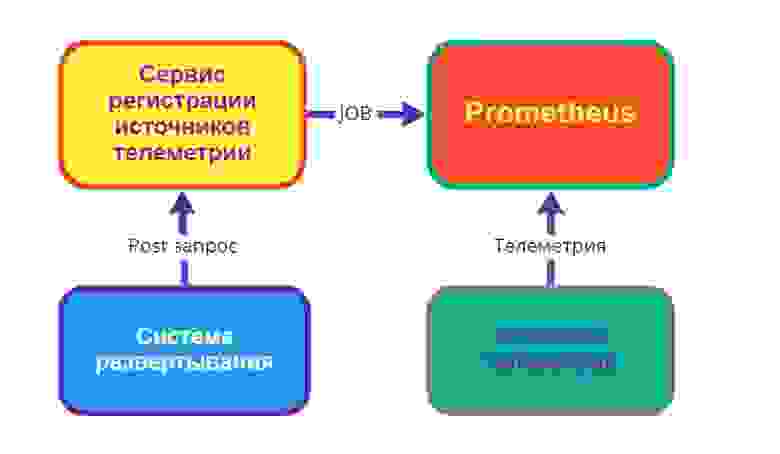
Сервис регистрации источников телеметрии
Здесь у нас появляется ещё одна сущность — источник телеметрии. Источник телеметрии — это объект, способный предоставить нам некоторую метрику (как правило цифровую). Источник телеметрии сам по себе может не быть объектом мониторинга, а диагностирование работоспособности объекта мониторинга может зависеть от метрик нескольких источников телеметрии. Так, работоспособность хоста зависит от совокупности метрик, которые предоставляют разные источники телеметрии:
Загруженность CPU в процентах.
Процент использования RAM.
Заполненность диска в процентах.
На схеме ниже изображен поток данных от источника телеметрии. В процессе развертывания или создания узла инфраструктуры отправляется POST-запрос с данными об источнике в сервис регистрации, который, в свою очередь, создает job для системы сбора и хранения телеметрии (например, для системы Prometheus — мы используем именно её, или для любой другой Time Series Database, TSDB).
Сервис визуального отображения
Для визуального отображения и удобства администрирования, а также наглядности обслуживаемой системы был разработан сервис визуального отображения (использующий для собственно визуализации графов библиотеку 3d-force-graph).

Здесь мы можем видеть узлы инфраструктуры. Красные вершины — это узлы инфраструктуры, в которых в данный момент обнаружены неполадки. Они образуют цепочку срабатывания алертов. Отсутствие алертов в соседних узлах означает, что остальные компоненты не затронуты. Значит — проблема локализована, и мы можем не беспокоиться об остальной части инфраструктуры и заниматься восстановлением только данных узлов системы.
Система оповещений
Система оповещений разработана таким образом, что может отправлять оповещения о поломках и восстановлении практически в любой мессенджер.
Так выглядит рабочая панель, в которой отображаются оповещения о поломках с указанием первопричины (RootCause) со статусом [FIRING].

А это сообщение о восстановлении функциональности:

В сообщении видно, что ошибки в работе одного кластера повлияли на другой.
Общая схема работы мониторинга:
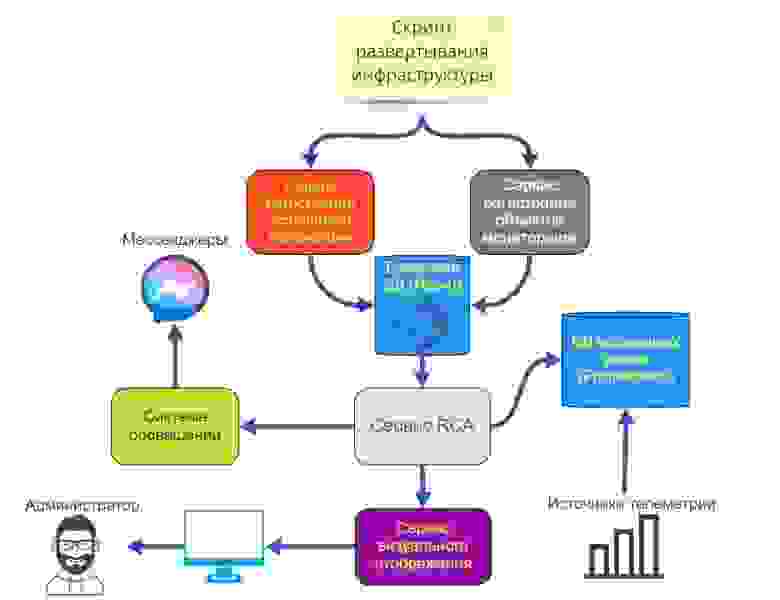
БД с телеметрией наполняется как с помощью непосредственной загрузки в нее метрик источниками телеметрии, так и периодическими запросами самого Prometheus к HTTP-интерфейсам источников телеметрии.
Результаты работы сервиса
В первые дни после внедрения системы мы диагностировали и исправили множество неполадок в инфраструктуре, которые было тяжело отследить без системы мониторинга. Раньше мы видели только последствия этих неполадок в виде периодической недоступности той или иной функциональности.
Спустя несколько месяцев эксплуатации количество запросов в техподдержку сократилось, несмотря на рост инфраструктуры, что наглядно показывает эффективность системы. Сотрудники техподдержки стали тратить меньше времени на расследование инцидентов, потому что им стали известны причины и ошибки стали локализованными.
Одним из первых сервисов, где была внедрена эта система мониторинга, был сервис 1С: ГРМ, т.к. он является ярким примером облачного сервиса, и его архитектура хорошо подходит для тестирования нашей системы.
Сейчас система успешно обслуживает различные облачные сервисы 1С.
