Как мы автоматизировали работу с Kafka: через тернии к Cruise Control
В 2022 годуискушённого хабрачитателя уже не удивить очередной статьёй о том, как готовить Kafka. На эту тему уже есть куча полезных материалов. Например: тут, тут, тут и тут. А вот информации об инструментах, входящих в экосистему Kafka, ещё не так много.
Когда у вас тысячи топиков и десятки брокеров в нескольких дата-центрах, то вручную балансировать реплики партиций ещё возможно. Но где-то на этом этапе работа по переносу реплик с одного брокера на другой становится рутиной. А при увеличении объёмов без автоматизации уже не обойтись. Поэтому мы задумались о том, какие инструменты могут в этом помочь.
Сегодня я поделюсь нашей историей запуска инструмента Kafka Cruise Control от LinkedIn. Наш путь по запуску на наших объёмах был тернист, и получился интересным, почти детективным рассказом. А если вы думаете, как автоматизировать рутинные операции по администрированию Kafka-кластеров, то, уверен, почерпнёте для себя что-то полезное.

Как у нас всё устроено
Привет, дорогой читатель, расскажу немного о нас. Меня зовут Юрий, я инженер инфраструктурных сервисов в Ozon.
Один из сервисов, с которыми работает наша команда, — это Apache Kafka. Вместе с командой платформенных сервисов мы решаем глобальную задачу по предоставлению Kafka as a service. В это понятие мы вкладываем идею того, что пользователю не нужно задумываться о масштабировании и отказоустойчивости — для него это само собой разумеющиеся возможности сервиса. Пользователь может ничего не знать о брокерах и количестве реплик, тонких настройках для каждого топика и других особенностях работы кластера Kafka. Вместо этого ему предлагается просто заказывать нужные сущности, выбирая из каталога шаблонов на портале, писать в топики любое количество сообщений любого объёма и вычитывать их с нужной скоростью.
Как и во многих других компаниях, в Ozon используется классическая трёхзвенная схема окружений:
Dev (малые нагрузки, малые объёмы, используется для разработки фич);
Stage (объёмы в разы больше, используется для разного рода тестов);
Prod (думаю, тут можно ничего не объяснять).
С чем мы имеем дело каждый день. Кластер Apache Kafka в Ozon — это:
инсталляция Apache Kafka 2.7.1 с ZooKeeper 3.6.3;
брокеры на железных серверах;
четыре больших кластера Kafka-брокеров, распределённые между тремя дата-центрами;
больше 70 брокеров;
больше 9400 топиков;
десятки тысяч партиций;
терабайты сообщений в Kafka.
 Типовое распределение нод одного кластера между тремя дата-центрами
Типовое распределение нод одного кластера между тремя дата-центрами
Как видно из схемы, в один кластер входит множество брокеров, расположенных в разных дата-центрах. И физически они также находятся на разных серверах. Нам важно, чтобы каждая партиция имела несколько реплик — за счёт этого мы распределяем нагрузку и гарантируем сохранение данных в случаях разных сбоев. При этом мы хотим распределить эту нагрузку равномерно:
с точки зрения использования дисков;
с точки зрения операций записи/чтения (а это нагрузка на сеть, процессор, память).
Процесс распределения реплик между брокерами мы и называем перебалансировкой. Перебалансировка кластера — достаточно трудоёмкая задача для инженера. Кроме того, это откровенно скучная и монотонная работа, если делать её постоянно. «А зачем вообще нужно что-то перебалансировывать?» — спросите вы. Ведь можно сразу создавать реплики партиций «правильно». Но в реальном мире всё не так радужно: серверы выходят из строя, появляются новые топики и партиции, а нагрузка на них меняется, не говоря уже о таких глобальных событиях, как переезд дата-центра или открытие нового.
Под спойлером я оставлю информацию о том, как можно выполнить простую балансировку кластера с помощью утилит из коробки Apache Kafka. Надеюсь, примеры пригодятся тем, у кого кластеры ещё не достигли критического размера.
Балансировка с помощью Kafka-tools
echo '{
"version": 1,
"topics": [' > kafka_topics.json
/opt/kafka/bin/kafka-topics.sh \
--bootstrap-server {{ KAFKA_BROKER_ADDRESS }}:{{ KAFKA_BROKER_PORT }} \
--list | awk '{print "{\042topic\042:\042"$1"\042},"}' >> kafka_topics.json
echo ' ]
}' >> kafka_topics.json Удаляем в конце последней строки с блоком topic символ »,» так как kafka-reassign-partitions.sh на вход принимает файлы в формате JSON.
/opt/kafka/bin/kafka-reassign-partitions.sh \
--bootstrap-server {{ KAFKA_BROKER_ADDRESS }}:{{ KAFKA_BROKER_PORT }} \
--topics-to-move-json-file kafka_topics.json \
--broker-list "1007,1008,1009" \
--generate > kafka_topics_reassignment.json В получившемся файле kafka_topics_reassignment.json в последней строке находится блок, который утилита рекомендует в качестве изменений для выполнения балансировки. Но как показала практика, эти рекомендации не всегда верны.
tail -n 1 kafka_topics_reassignment.json > kafka_topics_reassignment_proposal.json Убеждаемся, что файл заполнен в корректном формате.
/opt/kafka/bin/kafka-reassign-partitions.sh \
--bootstrap-server {{ KAFKA_BROKER_ADDRESS }}:{{ KAFKA_BROKER_PORT }} \
--reassignment-json-file kafka_topics_reassignment_proposal.json \
--verify Запускаем ребалансировку.
/opt/kafka/bin/kafka-reassign-partitions.sh \
--bootstrap-server {{ KAFKA_BROKER_ADDRESS }}:{{ KAFKA_BROKER_PORT }} \
--reassignment-json-file kafka_topics_reassignment_proposal.json \
--execute Выбор решения
Главная задача, которая перед нами стояла, — автоматическое восстановление фактора репликации, то есть поднятие отсутствующих реплик на других брокерах (например, в случае выхода из строя Kafka-брокера). Чем критичнее топик, тем больше реплик у него должно быть. У нас большинство топиков имеют три реплики при как минимум двух синхронизированных репликах. При штатном расширении кластера или его уменьшении ребалансировка также должна происходить автоматически.
Особое внимание мы уделяли вопросу контроля используемых ресурсов, в том числе полосе пропускания сети. То есть мы должны контролировать полосу пропускания, когда Cruise Control (или другое решение) выполняет ребалансировку партиций. Кроме того, нам важно иметь возможность контролировать и другие ресурсы: CPU, RAM, чтение с дисков и запись на них.
А ещё нам важно следить за тем, чтобы реплики оказывались в разных дата-центрах. Тогда при полном выходе из строя одного из них мы сможем продолжить использование Kafka без деградации.
С такими вводными мы приступили к подбору решения. После первого отсева у нас осталось пять вариантов, которые мы изучили более внимательно.
Из заголовка уже понятно, какой инструмент мы выбрали. Но давайте кратко пройдёмся, почему отказались от остальных.
Confluent Rebalancer
Одна из утилит, входящая в состав Confluent Hub (может быть использована и без его установки). Обладает богатой функциональностью, которая позволяет выполнить полную перебалансировку кластера с ограничением скорости репликации и количества единовременно перемещаемых партиций (задаётся для каждого брокера).
Что нам не подошло:
Kafka Assigner
Входит в набор утилит Kafka Tools от LinkedIn. Скрипты написаны на Python. Kafka Assigner позволяет генерировать предложения по балансировке кластера и реализовывать их. Есть возможность ограничивать количество перемещаемых за один раз партиций.
Почему не выбрали:
Orion
Разработка компании Pinterest, судя по документации, имеет множество подключаемых классов для выполнения манипуляций в Kafka, но всё ещё находится в стадии активной разработки, а значит, не готова к продуктовому использованию. Да и документация, на мой взгляд, слабая.
Что нам не подошло:
нет подтверждения готовности решения к использованию на продуктовых кластерах;
слабая документация, в которой не хватает подробностей при работе с Kafka.
Консольные утилиты
Утилиты, входящие в комплект поставки Apache Kafka, обладают обширной функциональностью для администрирования кластера, но не подходят для сложной автоматизации. У них нет веб-интерфейса, они не позволяют распределять нагрузку с учётом нескольких факторов. Если необходимо изменить условие или переместить партиции в другом порядке, потребуется ручное формирование JSON-файла администратором. Пример условия: распределение нагрузки с учетом rack.id и занимаемой дисковой ёмкости по всему кластеру.
Критерий | Cruise Control | Orion | Консольные утилиты | Kafka Assigner | Confluent Rebalancer |
Среда исполнения | Java | Java | Shell + Java | Python | Shell + Java |
Наличие API для внешней интеграции | + | + | — | — | ? |
Наличие UI для визуализации работы системы | + | + | — | — | + |
Работа с несколькими кластерами одновременно | + | + | + | + | + |
Отслеживание ресурсов Kafka-кластера (CPU, RAM, HDD, NET) | + | + | — | — | + |
Автоматическая поддержка описанных в конфиге показателей работоспособности кластера | + | + | — | — | — |
Добавление/удаление брокеров | + | + | + | + | + |
Генерация рекомендаций по балансировке партиций | + | + | — | + | + |
Перебалансировка партиций между брокерами | + | + | + | + | + |
Выведение брокеров на обслуживание | + | — | + | + | + |
Восстановление офлайн-партиции | + | — | + | — | — |
Увеличение/уменьшение фактора репликации для каждого топика | + | + | + | + | — |
Отслеживание аномалий в работе кластера | + | — | — | — | + |
Один из главных критериев для меня — наличие открытого исходного кода, поскольку это сейчас является гарантией стабильности внедрённого решения.
После фиксации основных требований и анализа решений мы выбрали Cruise Control. Confluent Rebalancer, входящий в Confluent Cloud, нам тоже показался очень интересным, но он доступен только с лицензией Enterprise, которую в России не приобрести. Да и закрытость кода делает его менее привлекательным для нас.
О Kafka Cruise Control
Историческая справка
LinkedIn, будучи разработчиком Kafka, активно используют её в своих проектах. С развитием компании увеличивались и количество кластеров Kafka, и объём перегоняемых через неё сообщений.
Инженеры LinkedIn приводят такие цифры по своим продуктовым кластерам на февраль 2019 года:
4,5 трлн сообщений в день;
около 2000 брокеров.
Сопровождение систем такого размера требует больших усилий и внимания со стороны инженеров. В LinkedIn активно используют утилиты, поставляемые из коробки с Kafka для выполнения рутинных задач, таких как выведение брокеров из эксплуатации и перемещение партиций. Однако более сложные операции, такие как полная перебалансировка кластера с учётом правильного распределения партиций, тогда занимали огромное количество времени и сил, связанных с ручными манипуляциями со стороны инженеров.
В 2017 году LinkedIn представила сообществу проект с открытым исходным кодом Kafka Cruise Control, который призван помочь в решении сложных эксплуатационных задач.
Архитектура
Глобально бэкенд-архитектуру Cruise Control можно разбить на несколько крупных компонентов:
REST API,
Executor,
Monitor,
Analyzer,
Anomaly Detector.
Для сбора информации о состоянии каждого брокера в кластере также используется внешний модуль, который импортируется в Apache Kafka (Metrics Reporter). Данный модуль компилируется в качестве JAR-файла и добавляется в директорию /libs каждого Kafka-брокера.
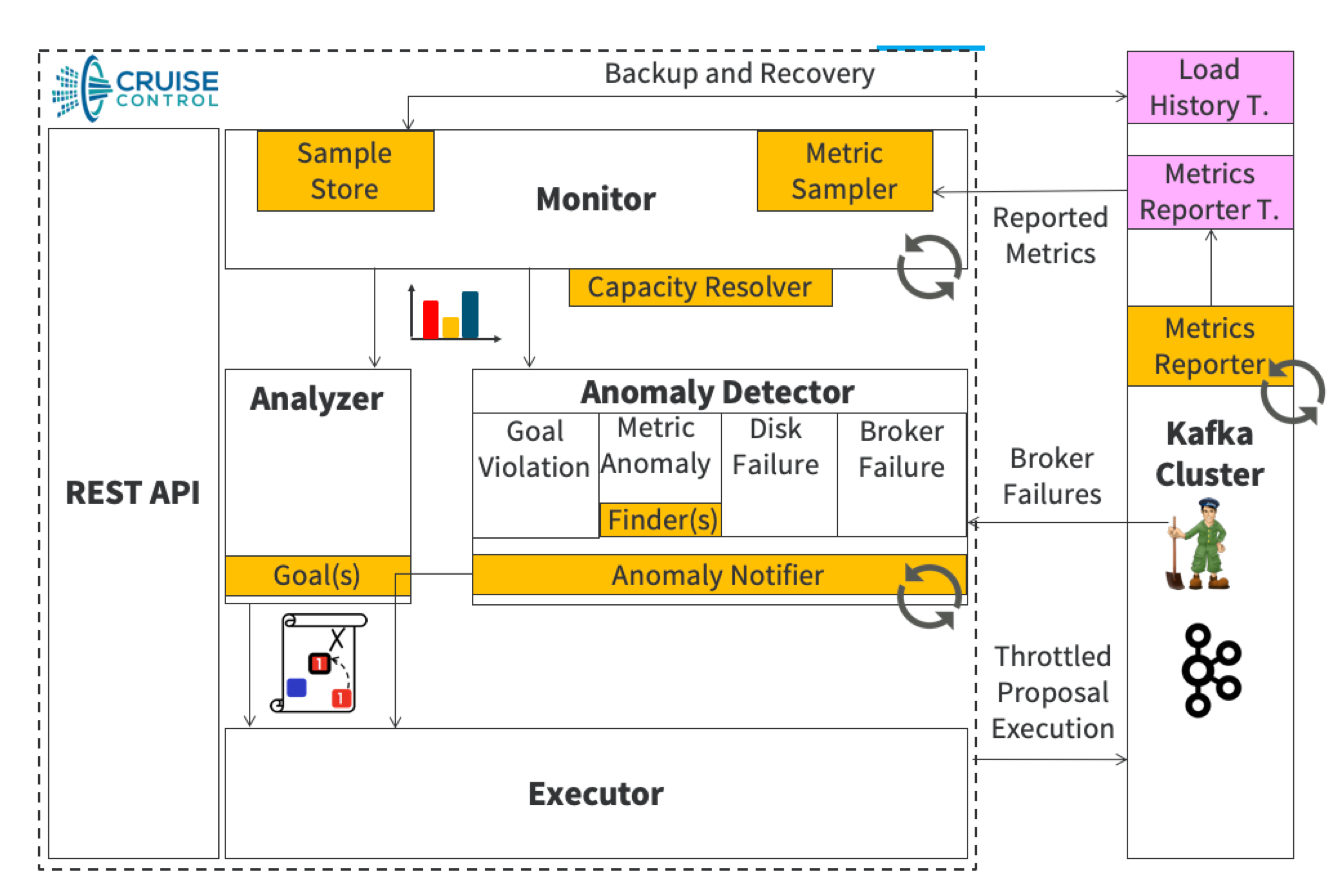 Материал взят из первоисточника https://github.com/linkedin/cruise-control/wiki/Overview
Материал взят из первоисточника https://github.com/linkedin/cruise-control/wiki/Overview
Первый запуск…
Как и во всех активно развивающихся компаниях, работающий инструмент нам был нужен ещё вчера. Требовалось запустить приложение как можно быстрее.
Для тестирования работоспособности был развёрнут тестовый кластер Kafka с ZooKeeper-ами и сгенерирована заливка тестовых данных. При первом запуске за основу мы взяли базовый конфиг.

Как это обычно бывает, уже в момент первого запуска мы ознакомились с README и собрали свою первую версию Kafka Cruise Control.
Старт на тестовом кластере прошёл успешно, без всяких ошибок.
Мы просто склонировали репозиторий, выдали команды из README для сборки приложения: ./gradlew jar copyDependantLibs
Указали в properties-файле адреса для подключения к нашим брокерам и ZooKeeper-ам.
После этого выполнили команду для запуска самого приложения: ./kafka-cruise-control-start.sh config/cruisecontrol.properties
И радостно наблюдали за приглашением консольной строки перейти в браузере по адресу: http://{{ IP_address }}:9090.

В момент перехода мы почувствовали первое недоумение: где же обещанный пользовательский веб-интерфейс, который мы хотели предоставлять коллегам для удобства выполнения базовых задач?
Как оказалось, основной проект Kafka Cruise Control не содержит никакого фронтенда в виде веб-интерфейса. Cruise Control реализует взаимодействие с пользователями через REST API, а веб-интерфейс разрабатывается в отдельном проекте.
Надо сказать, что функциональность веб-интерфейса на момент написания статьи не покрывала все методы, существующие в REST API, но её было достаточно, чтобы показать базовый примитив коллегам.
Для развёртывания веб-интерфейса знакомимся, как осуществляется интеграция веб-интерфейса в основное приложение, перезапускаем собранное «это» — и вуаля! «Cruise Control готов», — подумали мы…
Забегая вперёд, отмечу, что на момент тестов у нас были две основные ветки в репозитории разработчика:
Migrate_to_kafka_2_4(в документации указано, что используется с Apache Kafka 2.4);Migrate_to_kafka_2_5(для нашей версии Apache Kafka 2.7.1 нужно использовать релизную версию старше 2.5.36).
И, как оказалось позднее, в работе необходимой нам ветки Migrate_to_kafka_2_5 есть нюансы.
Начинаем тестировать ситуации, с которым мы столкнёмся в реальной жизни.
Кейс 1: Балансировка партиций с учётом настроенного rack.id
У нас rack.id используется для распределения брокеров между дата-центрами. Нам очень важно, чтобы топики имели отказоустойчивую конфигурацию, поэтому все они имеют такие настройки:
replication.factor = 3,min.insync.replicas = 2,
и мы стараемся держать копию каждой партиции в трёх разных дата-центрах.
Тестирование данного кейса прошло без всяких проблем. В кластере мы создали топики, налили в них тестовых сообщений и после этого запустили полную ребалансировку.
Состояние кластера до балансировки:

Состояние кластера после балансировки:

В момент тестирования мы столкнулись с первой особенностью, связанной с достижением целей (goals).
В Cruise Control целевые показатели, к которым внутренняя математика старается привести кластер, называются целями. Существуют две похожие цели, позволяющие достигнуть равномерного распределения партиций между дата-центрами с использованием параметра rack.id:
Но у них есть одно важное отличие. Если в вашем проекте возможна ситуация, при которой количество уникальных rack.id будет меньше, чем количество реплик (replication.factor), при использовании цели RackAwareGoal Cruise Control не позволит выполнить балансировку партиций. Вы получите следующую ошибку:
there are only 3 racks in the cluster, to skip the rack-awareness check, set skip_rack_awareness_check to true in the request.
Так как в качестве rack.id мы распределяем кластер между дата-центрами, мы закладываем риск потери целого дата-центра, что приведёт как раз к вышеописанной ситуации.
С помощью параметра rack.id мы логически распределяем копии партиций по кластеру таким образом, чтобы в каждом дата-центре при нормальных условиях находилась одна копия. Благодаря подобной конфигурации мы можем гарантированно пережить потерю целого дата-центра.
Мы выбрали для себя настройку RackAwareDistributionGoal. Она позволяет распределить партиции между двумя дата-центрами при невозможности их распределения между тремя.
Кейс 2: Достижение целей
Все расчёты предложений в Cruise Control строятся при активации подключаемых целей. Цели можно создавать самостоятельно, но мы пока остановились на использовании стандартного набора. В репозитории указано, что базовый набор целей, в комплекте с Cruise Control, имеют определённый приоритет.
Приведу выдержку из документации, в которой цели перечислены в порядке убывания приоритета:
RackAwareGoal — гарантирует, что все реплики каждой партиции назначаются с учетом rack.id, то есть в одной rack.id-зоне находится не более одной реплики каждой партиции;
RackAwareDistributionGoal — облегчённая версия предыдущей цели, которая позволяет размещать несколько реплик партиции в одной стойке;
ReplicaCapacityGoal — гарантирует, что максимальное количество реплик на брокера не превышает указанного предела; задаётся с помощью параметра
replica.count.balance.thresholdв cruisecontrol.properties;DiskCapacityGoal — гарантирует, что объём используемого дискового пространства каждым брокером меньше установленного порога; задаётся с помощью параметра
disk.capacity.thresholdв cruisecontrol.properties;NetworkInboundCapacityGoal — гарантирует, что объём используемой входящей сети каждым брокером меньше установленного порога; задаётся с помощью параметра
network.inbound.capacity.thresholdв cruisecontrol.properties;NetworkOutboundCapacityGoal — гарантирует, что объём используемой исходящей сети каждым брокером меньше установленного порога; задаётся с помощью параметра
network.outbound.capacity.thresholdв cruisecontrol.properties;CpuCapacityGoal — гарантирует, что загрузка CPU на каждом брокере меньше установленного порога; задаётся с помощью параметра
cpu.capacity.thresholdв cruisecontrol.properties;ReplicaDistributionGoal — постарается распределить реплики таким образом, чтобы все брокеры в кластере имели одинаковое количество реплик;
PotentialNwOutGoal — гарантирует, что потенциальная исходящая нагрузка на сеть (когда все реплики станут лидерами) на каждом брокере не превысит пропускную способность исходящей сети (для корректной работы необходимо описать характеристики сетевого соединения в файле capacity.json);
DiskUsageDistributionGoal — попытается сделать так, чтобы распределение дискового пространства между всеми брокерами было равномерным;
NetworkInboundUsageDistributionGoal — попытается сделать так, чтобы распределение входящего сетевого трафика между всеми брокерами было равномерным;
NetworkOutboundUsageDistributionGoal — попытается сделать так, чтобы распределение исходящего сетевого трафика между всеми брокерами было равномерным;
CpuUsageDistributionGoal — попытается сделать так, чтобы дисперсия утилизации CPU между всеми брокерами была равномерной;
LeaderReplicaDistributionGoal — попытается сделать так, чтобы распределение лидер-партиций по кластеру было равномерным;
LeaderBytesInDistributionGoal — попытается сделать так, чтобы входящий сетевой трафик на лидер-партиций в кластере был равномерным;
TopicReplicaDistributionGoal — попытается равномерно распределить реплики одного и того же топика по кластеру;
IntraBrokerDiskCapacityGoal — гарантирует, что загрузка дискового пространства каждого брокера меньше заданного порога; выбираем эту цель, если нам необходимо запустить только балансировку утилизации по дискам;
IntraBrokerDiskUsageDistributionGoal — попытается сделать так, чтобы использование дискового пространства всеми брокерами было равномерным; выбираем эту цель, если нам необходимо запустить только балансировку утилизации по дискам.
По умолчанию мы оставляем все цели активными. А когда возникает ситуация, требующая изменения набора целей, мы запускаем балансировку через веб-интерфейс, переопределяя стандартный набор.
 Запуск балансировки с изменённым набором целей
Запуск балансировки с изменённым набором целей
Для проверки того, какие цели будут достигнуты в рамках выбранных настроек, можно выбрать режим »Dry run» (так называемый холостой прогон). Cruise Control построит математическую модель, покажет нам результаты, но задания на исполнение передавать не будет.
На запрос в режиме »Dry run» мы получим от Cruise Control ответ в формате JSON. Нас будут интересовать в основном поля:
.summary.onDemandBalancednessScoreBefore— оценка в функциональных единицах того, насколько кластер имеет сбалансированную конфигурацию перед запуском процесса балансировки;.summary.onDemandBalancednessScoreAfter— оценка в функциональных единицах того, насколько кластер имеет сбалансированную конфигурацию после применения предлагаемых изменений: 100% — полностью сбалансированный, 0% — полностью разбалансированный;.goalSummary.goal— наименование выбранной цели;.goalSummary.status— статус, отражающий, сможет ли Cruise Control достигнуть поставленной цели; есть три типа статусов: FIXED, NO-ACTION, VIOLATED.
Ориентируясь на передаваемые параметры и полученный от Cruise Control статус, мы можем корректировать цели для достижения лучшей сбалансированности кластера. Иногда возникают ситуации, при которых выбранные цели блокируют достижение других, более приоритетных целей и Cruise Control не позволяет в обычных условиях достичь желаемого результата. Инженер, ориентируясь по метрикам Kafka-кластера, принимает решение, что в определённый момент необходимо, например, выровнять входящую сетевую нагрузку по лидер-партициям. Тогда мы корректируем набор целей, до тех пор, пока в статусе для нужной нам цели не появится заветное FIXED.
С оставшимися кейсами нам пришлось повозиться.
Кейс 3: В момент перемещения партиций необходимо устанавливать скоростное ограничение на перемещаемые партиции
Для установки ограничения скорости в Cruise Control есть две опции:
Чтобы исключить влияние на работу продуктового кластера в момент запуска перебалансировки через Cruise Control, мы проанализировали утилизацию сетевых интерфейсов на наших кластерах и приняли соглашение. Для наших сред мы устанавливаем ограничения с помощью default.replication.throttle (измеряется в байтах в секунду) в следующем распределении:
Dev = 12500000Bps (100Mbps),
Stage = 125000000Bps (1Gbps),
Prod = 250000000Bps (2Gbps).
При тестировании на ветке Migrate_to_kafka_2_5 ограничение работало корректно до тех пор, пока дело не дошло до четвёртого кейса с мёртвым брокером.
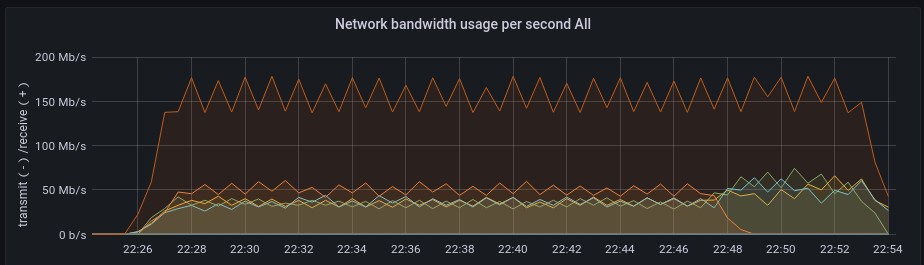 Пример перемещения партиций с одного брокера на остальные брокеры в кластере с заданным параметром replication_throttle = 20000000Bps
Пример перемещения партиций с одного брокера на остальные брокеры в кластере с заданным параметром replication_throttle = 20000000Bps
Кейс 4: Автоматическое перемещение партиций при наличии мёртвого брокера или недоступных logDirectory
Для более быстрого тестирования уменьшаем временные интервалы срабатывания триггера для лечения последствий от упавшего брокера (для боевого использования изменяем таймеры на подходящие временные интервалы). Для этого в файле cruisecontrol.properties меняем параметры:
self.healing.broker.failure.enabled=true,broker.failure.alert.threshold.ms=300000,broker.failure.self.healing.threshold.ms=600000,broker.failure.detection.interval.ms=300000(параметр появляется на migrate_to_kafka_2_5),kafka.broker.failure.detection.enable=true(параметр появляется на migrate_to_kafka_2_5).
Останавливаем один Kafka-брокер, имитируя его смерть. Дожидаемся истечения заданного времени и с грустью наблюдаем за тем, как функция падает с ошибкой. Самовосстановление и попытки выполнить удаление остановленного Kafka-брокера с помощью вызова ручки Remove Broker не сработали. Но каждый раз в логах мы наблюдали «говорящую» ошибку:
ERROR Executor got exception during execution (com.linkedin.kafka.cruisecontrol.executor.Executor)
java.util.concurrent.TimeoutException: null
at java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1886) ~[?:?]
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:2021) ~[?:?]
at org.apache.kafka.common.internals.KafkaFutureImpl.get(KafkaFutureImpl.java:180) ~[kafka-clients-3.1.0.jar:?]
at com.linkedin.kafka.cruisecontrol.executor.ReplicationThrottleHelper.getEntityConfigs(ReplicationThrottleHelper.java:203) На тот момент мы не углублялись в исходный код Cruise Control, и полученная ошибка TimeoutException: null не навела нас на правильный путь.
Как я упоминал выше, есть две ветки приложения:
Migrate_to_kafka_2_4,Migrate_to_kafka_2_5.
После поиска информации мы решили посмотреть, как обстоят дела с подобным кейсом на второй ветке. Переключились на ветку Migrate_to_kafka_2_4 и собрали приложение. Запустили его с теми же параметрами. Автоматическое удаление остановленного брокера не сработало, но при вызове ручки Remove Broker задания отрабатывали без ошибок.
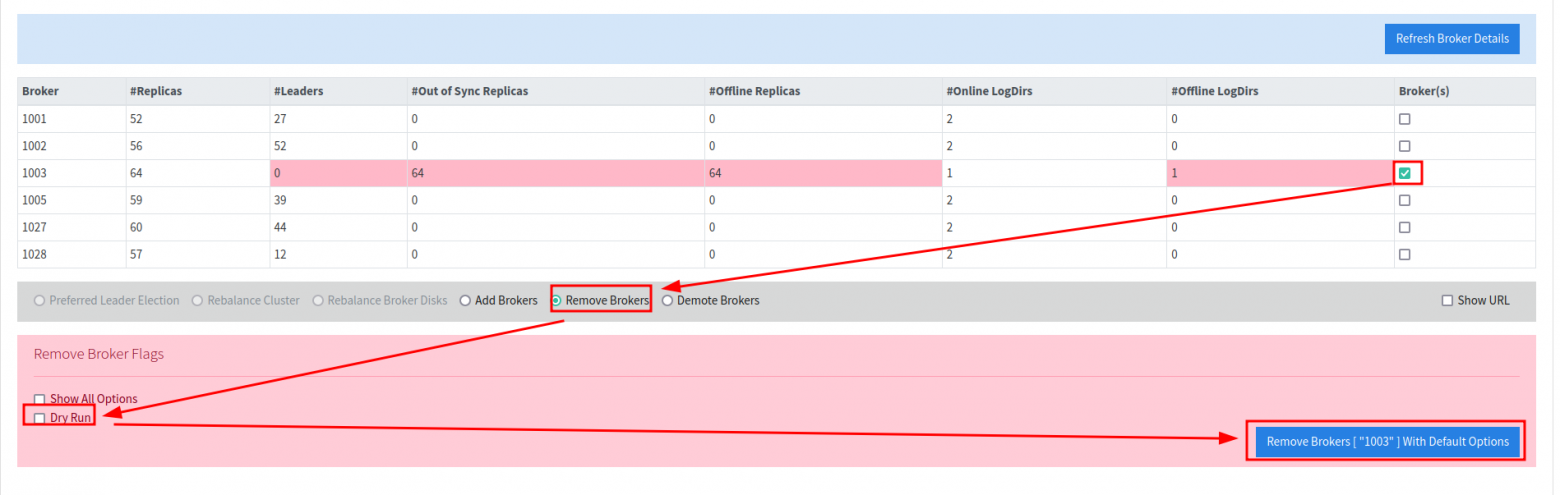 Запуск удаления брокера
Запуск удаления брокера  По окончании перемещения реплик брокер удалился из списка
По окончании перемещения реплик брокер удалился из списка
С недоумением начали исследовать, почему не работает удаление в более свежей версии на ветке Migrate_to_kafka_2_5. В ней при внесении изменений в метаданные топиков и партиций все запросы идут через Kafka API, а запрос на изменение метаданных отправляется от Kafka-брокера, который является контроллером в кластере.
На ветке Migrate_to_kafka_2_4 изменение метаданных кластера происходит с помощью прямого обращения Cruise Control к ZooKeeper-у. И в момент недоступности брокера у модуля Executor вызывается класс, отвечающий за установку ограничения скорости (ReplicationThrottleHelper). В случае падения брокера у этого класса не возникает никаких проблем с получением и изменением метаданных у ZooKeeper-а. Брокеры впоследствии вычитывают обновлённую информацию о топиках и выполняют необходимую работу по изменению расположения партиций в кластере.
Судя по всему, в версии Cruise Control из ветки Migrate_to_kafka_2_5 логика работы класса ReplicationThrottleHelper не менялась, но при этом модуль Executor и все классы были изменены на использование Kafka API. Таким образом, когда появляется мёртвый брокер, ReplicationThrottleHelperпытается получить от него метаданные и, конечно же, получает ошибку по тайм-ауту.
Начали изучать, как нам и рыбку съесть, и косточкой не подавиться.
Нужно сказать, что у нас Cruise Control был форкнут во внутренний репозиторий. Мы выяснили, на каком этапе ReplicationThrottleHelperвозникает ошибка, и попробовали сделать собственный патч. После нескольких попыток мы поняли, что нет времени ковыряться, а запускать приложение уже пора (был внутренний дедлайн). Тогда мы решили узнать, чем отличаются версии ReplicationThrottleHelper. На этом этапе мы и выяснили, что в предыдущей версии была реализация с использованием ZooKeeper-а, а все последующие версии уже используют Kafka API. Принимаем решение сделать в нашем форкнутом репозитории гибрид, откатить коммит, связанный с выпиливанием взаимодействия через ZooKeeper, а все остальные наработки оставить. Откатили коммит, пересобрали приложение — и о чудо! Теперь у нас работают и установка скоростного ограничения, и автоматическое переназначение партиций с мёртвого брокера.
Осознав проблему, завели разработчикам issue. Убедились ещё раз, что на тестовом кластере всё работает. Успех!
Первые полубоевые испытания
Stage-кластер представляет собой набор из шести брокеров:
2,3 ТБ информации;
3470 топиков;
16 500 партиций.
Так как для полной перебалансировки всего кластера, возможно, потребуется переместить большое количество партиций, мы заранее решили подкрутить параметр, отвечающий за параллельно перемещаемые партиции в рамках одного брокера.
В cruisecontrol.properties изменили num.concurrent.partition.movements.per.broker = 100 (было 10), запустили сборку — и контейнер не стартует. В логах увидели невнятную ошибку, что мы превысили какой-то лимит в 12 единиц. Ищем полные логи и находим при старте приложения «портянку» параметров, загружаемых по умолчанию. Единственный параметр, который имеет значение 12, — concurrency.adjuster.max.partition.movements.per.broker. Находим в репозитории информацию: этот параметр накладывает ограничение на максимальное количество одновременно перемещаемых между брокерами партиций. В этом же файле написано, что параметр должен находиться в диапазоне между num.concurrent.partition.movements.per.broker и max.num.cluster.movements. Удивляемся, что его сразу не было в cruisecontrol.properties…
Устанавливаем:
num.concurrent.partition.movements.per.broker = 100,concurrency.adjuster.max.partition.movements.per.broker = 500.
Запускаем полную перебалансировку кластера. Убедившись, что задания запустились и Cruise Control будет перемещать около 540 Гб данных, я решил спокойно сделать себе кружечку кофе.
 Статус модуля Executor в Cruise Control UI
Статус модуля Executor в Cruise Control UI
Вернувшись на рабочее место спустя 15 минут, я обнаружил, что работа завершена, начал удивлённо изучать результаты балансировки — и увидел, что она завершилась с ошибкой.
ERROR SASL authentication failed using login context 'Client' with exception: {} (org.apache.zookeeper.client.ZooKeeperSaslClient)
javax.security.sasl.SaslException: Error in authenticating with a Zookeeper Quorum member: the quorum member's saslToken is null.
at org.apache.zookeeper.client.ZooKeeperSaslClient.createSaslToken(ZooKeeperSaslClient.java:312) ~[zookeeper-3.5.9.jar:3.5.9]
at org.apache.zookeeper.client.ZooKeeperSaslClient.respondToServer(ZooKeeperSaslClient.java:275) [zookeeper-3.5.9.jar:3.5.9]
at org.apache.zookeeper.ClientCnxn$SendThread.readResponse(ClientCnxn.java:882) [zookeeper-3.5.9.jar:3.5.9]
at org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:103) [zookeeper-3.5.9.jar:3.5.9]
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:365) [zookeeper-3.5.9.jar:3.5.9]
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1223) [zookeeper-3.5.9.jar:3.5.9] Как можно заметить из ошибки, ZooKeeper-кластер у нас настроен на использование SASL-аутентификации для обеспечения безопасности. В момент возникновения ошибки Cruise Control не может пройти аутентификацию.
 Уровень невезения в данной ситуации стремится к бесконечности
Уровень невезения в данной ситуации стремится к бесконечности
Идём в логи ZooKeeper-а и видим там ошибки, связанные с частым перевыбором лидера.
По графикам в Grafana более пристально приглядываемся к ситуации и понимаем, что перевыбор действительно происходит часто, но не до такой степени, чтобы Cruise Control полностью останавливал выполнение задач на перебалансировку. Бонусом видим на графиках, что при запуске балансировки через Cruise Control количество запросов к кластеру ZooKeeper-а кратно увеличивается.
 Частота запросов к нодам ZooKeeper
Частота запросов к нодам ZooKeeper Время жизни кворума ZooKeeper
Время жизни кворума ZooKeeper
Ещё раз более детально изучаем логи Cruise Control, чтобы разобраться в причине происходящего. В голове мелькает мысль, что от таких переключений не должны падать таски на балансировку: сам ZooKeeper-кластер жив, и кластер Kafka при этом работает без проблем.
Замечаем следующую этапность:
Cruise Control последовательно выполняет модификацию метаданных у топиков, над которыми выполняется балансировка. В ZooKeeper в директории:
/config/topics/{{ topics_name }}.Возникает ошибка аутентификации. zookeeper.client гасит текущую сессию и закрывает socket с кластером.
Одномоментно пытается выполнить новое подключение, получает повторно ошибку
ERROR SASL authentication failed using login context 'Client' with exception: {} (org.apache.zookeeper.client.ZooKeeperSaslClient).zookeeper.client гасит новую сессию, закрывает socket с кластером и больше не пытается выполнить подключение.
Cruise Control останавливает задания на балансировку.
В голове мелькает мысль, что кластер ещё не успел определить нового лидера и повторное подключение необходимо делать чуть медленнее…
Замечаем в логах при второй попытке установить соединение с ZooKeeper-кластером не привлекающую внимания строку от zookeeper.client:
INFO zookeeper.request.timeout value is 0. feature enabled= (org.apache.zookeeper.ClientCnxn)
Очень интересный параметр zookeeper.request.timeout! Начинаем выяснять, за что он отвечает и какой тайм-аут устанавливает. Перерыли кучу информации, включая документацию, — и нигде не описан этот загадочный параметр. С надеждой заглянули в репозиторий Apache ZooKeeper, но и это не помогло.
«Ладно, — решили мы. — Просто выставим значение для теста». Но какое? В найденных обрывках информации этот параметр относят к величине, измеряемой в миллисекундах. За истину мы решили считать информацию в репозитории разработчика: раз там для тестов используют параметры, близкие к обозначению миллисекунд, то и мы попробуем.

Добрый друг, если у тебя есть развёрнутая информация о назначении этого параметра, пожалуйста, поделись.
Устанавливаем -Dzookeeper.request.timeout=2000 и запускаем повторно полную балансировку кластера.
Пока мы занимались поиском причин падения заданий в Cruise Control, нашли баг в ZooKeeper-е: оказывается, нельзя просто так изменить уровень логирования.
Мы ещё раз проверили все возможные метрики после выставления тайм-аута. Критичных отклоне
