Как хранить сеть дорог в БД для построения маршрута?
И так, формулировка задачи следующая: есть база данных, в ней хранится информация о дорогах, включая координаты, нужно реализовать построение маршрутов из начальной точки к конечной.
Построение маршрутов — задача распространенная, и, как для каждой распространённой задачи, для неё давно существуют реализации. Мне нравится GraphHopper. Да так нравится, что моя первая статья на Хабре была про то, как создать для него собственные правила построения графа дорог.
Аналог: pgRouting
Кроме того, для построения маршрута по дорогам из PostgreSQL, можете ознакомиться с pgRouting, на Хабре есть несколько статей по этой теме, вот хотя бы: «делаем маршрутизацию (роутинг) на OpenStreetMap». Но это альтернативный способ реализации, я его затрагивать не буду.
Эта статья будет про то, как использовать свой источник данных, и как этот источник данных редактировать так, чтобы GraphHopper вас понял.
Оглавление
Как это работает?
GraphHopper использует данные OSM для построения графа дорог, однако есть возможность для расширения. Если нам понадобится альтернативный от OSM источник, необходимо предоставить свою реализацию класса DataReader, который будет читать данные из нашего хранилища.
К счастью для нас, мы не первые кому такое решение понадобилось, Японская компания Georepublic, уже всё сделала. Репозиторий их проекта есть на GitHub: mbasa/graphhopper-reader-postgis. Используем его. Я сделал форк репозитория Tkachenko-Ivan/graphhopper-reader-postgis, он немного отличается от первоисточника, все примеры кода ниже, взяты из форка.
В качестве хранилища данных используется PostgreSQL, с расширением PostGIS. Давайте разберём как это работает, и с чем это едят. Пример PostgreSQL поможет нам понять принцип создания произвольных источников данных.
Судя по всему, японцы основывали свои наработки на версии 2.x, а потом, с выходом новых версий GraphHopper, их актуализировали. Однако я решил вернуться к корням, все ссылки, которые я буду приводить на репозиторий GraphHopper, будут на ветку 2.x.
GraphHopper написан на Java, поэтому, если планируете делать какие-то доработки, или просто использовать его библиотеки, создайте проект Java. Прежде чем приступить к написанию классов для использования произвольных источников данных, необходимо подключить к проекту основную библиотеку, классы которой мы и будем дополнять и расширять:
com.graphhopper
graphhopper-web
2.4
GraphHopperPostgis — фасад для работы с графом дорог
В качестве точки доступа к API маршрутизации, используется класс GraphHopper. Он является по сути фасадом для индексирования дорог и построения маршрутов. Как я уже говорил, в качестве источника используется OSM, и для работы с этим источником есть соответствующий класс GraphHopperOSM, — унаследованный от класса GraphHopper. На основе таких данных из OSM как, тип дороги, направление движения и максимальная скорость, он и строит граф дорог. Нас устраивает всё, кроме источника, поэтому мы можем не изобретать велосипед, а унаследовать класс GraphHopperOSM, и переопределить метод createReader:
public class GraphHopperPostgis extends GraphHopperOSM {
private final Map postgisParams = new HashMap<>();
...
@Override
protected DataReader createReader(GraphHopperStorage ghStorage) {
OSMPostgisReader reader = new OSMPostgisReader(ghStorage, postgisParams);
for (OSMPostgisReader.EdgeAddedListener l : edgeAddedListeners) {
reader.addListener(l);
}
return initDataReader(reader);
}
...
} Здесь же мы должны дополнить метод init, создав HashMap для хранения параметров подключения к источнику данных, в нашем случае PostgreSQL.
public class GraphHopperPostgis extends GraphHopperOSM {
...
private final Map postgisParams = new HashMap<>();
@Override
public GraphHopper init(GraphHopperConfig ghConfig) {
postgisParams.put("dbtype", "postgis");
postgisParams.put("host", ghConfig.getString("db.host", host));
postgisParams.put("port", ghConfig.getString("db.port", port));
...
return super.init(ghConfig);
}
...
} Эти параметры были нами использованы при создании объекта класса OSMPostgisReader.
PostGIS reader
Приступим к разбору классов, которые непосредственно будут выполнять чтение данных из источника: OSMPostgisReader, который наследует абстрактный PostgisReader, который, в свою очередь, реализует интерфейс DataReader:
 Диаграмма классов для чтения данных дорог (в пакетах показаны классы GraphHopper, вне пакетов — созданные «нами»)
Диаграмма классов для чтения данных дорог (в пакетах показаны классы GraphHopper, вне пакетов — созданные «нами»)
Нам нужно реализовать метод readGraph в PostgisReader:
public abstract class PostgisReader implements DataReader {
...
@Override
public void readGraph() {
graphStorage.create(1000);
processJunctions();
processRoads();
finishReading();
}
...
}Метод processJunctions — поиск перекрёстков
Самое интересное начинается с метода processJunctions(). Вначале создаётся подключение к БД в методе openPostGisStore:
protected DataStore openPostGisStore() {
...
DataStore ds = DataStoreFinder.getDataStore(this.postgisParams);
...
}Затем получаем список дорог — FeatureIterator, и обходим его:
void processJunctions() {
DataStore dataStore = null;
FeatureIterator roads = null;
try {
dataStore = openPostGisStore();
roads = getFeatureIterator(dataStore, roadsFile.getName());
...
while (roads.hasNext()) {
SimpleFeature road = roads.next();
...
}
}
...
} Метод getFeatureIterator реализован в классе PostgisReader.
Для соединения с БД и чтения геоданных, используется GeoTools, подключаем библиотеки:
org.geotools
gt-main
19.4
org.geotools.jdbc
gt-jdbc-postgis
19.4
Получаем объект соответствующий строке в БД:
SimpleFeature road = roads.next();Нам необходимо получить координаты геометрии дороги (массив точек), для этого используем метод getCoords(SimpleFeature feature):
public abstract class PostgisReader implements DataReader {
...
protected List getCoords(SimpleFeature feature) {
ArrayList ret = new ArrayList<>();
...
Object coords = feature.getDefaultGeometry();
...
if (coords instanceof LineString) {
ret.add(((LineString) coords).getCoordinates());
} else if (coords instanceof MultiLineString) {
MultiLineString mls = (MultiLineString) coords;
int n = mls.getNumGeometries();
for (int i = 0; i < n; i++) {
ret.add(mls.getGeometryN(i).getCoordinates());
}
}
return ret;
}
...
} И в цикле обрабатываем все точки линии. Все обработанные точки хранятся в специальном массиве (для карты дорог России понадобится сохранить порядка 60 миллионов объектов):
public class OSMPostgisReader extends PostgisReader implements TurnCostParser.ExternalInternalMap {
private GHObjectIntHashMap coordState = new GHObjectIntHashMap<>(10_000_000, 0.7f);
...
} Если точка попадает в него впервые, у неё статус COORD_STATE_UNKNOWN, а если она уже встречалась ранее, то у неё статус COORD_STATE_PILLAR, что означает, что это узловая точка, — она встречается в нескольких разных линия, а значит в этой точке можно повернуть на другую дорогу, ей присваивается некоторый порядковый номер, начиная с 1, по количеству найденных узлов (повторно узлы не обрабатываются, т.е. точка на перекрёстке семи дорог будет помечена как узловая один раз, и этого достаточно):
while (roads.hasNext()) {
...
for (Coordinate[] points : getCoords(road)) {
...
for (int i = 0; i < points.length; i++) {
Coordinate c = points[i];
...
int state = coordState.get(c);
if (state >= FIRST_NODE_ID) {
continue;
}
if (i == 0 || i == points.length - 1 || state == COORD_STATE_PILLAR) {
int nodeId = nextNodeId++;
coordState.put(c, nodeId);
saveTowerPosition(nodeId, c);
} else if (state == COORD_STATE_UNKNOWN) {
coordState.put(c, COORD_STATE_PILLAR);
}
...
}
}
}Иными словами в этом методе — мы получаем список перекрёстков.
Метод processRoads — создание рёбер графа дорог
Запускается после processJunctions, и начинается аналогично: с подключения к БД, получения списка дорог и обхода их в цикле, разложения геометрии дороги на координаты, и перебор этих координат.
Его задача создать рёбра графа дорог и вычислить их длину. Рёбрами графа дорог будут не сами дороги, а те их участки, которые зажаты между найденными ранее точками перекрёстков.
 Преобразование дорог в рёбра графа
Преобразование дорог в рёбра графа
Помимо перекрёстков существует множество других точек, из которых состоит линия, они позволяют вычислить её длину, поэтому все точки между перекрёстками, сохраняются в массиве pillars:
void processRoads() {
...
while (roads.hasNext()) {
...
for (Coordinate[] points : getCoords(road)) {
...
List pillars = new ArrayList<>();
for (Coordinate point : points) {
...
if (state >= FIRST_NODE_ID) {
// Получить расстояние и приблизитльный центр
...
double distance = getWayLength(startTowerPnt, pillars, point);
addEdge(fromTowerNodeId, toTowerNodeId, road, distance, estmCentre, pillarNodes);
...
} else {
pillars.add(point);
}
...
}
}
}
...
} А когда дойдём до перекрёстка (условие if (state >= FIRST_NODE_ID)), — вычисляется длина ребра:
protected double getWayLength(Coordinate start, List pillars, Coordinate end) {
double distance = 0;
Coordinate previous = start;
for (Coordinate point : pillars) {
distance += distCalc.calcDist(lat(previous), lng(previous), lat(point), lng(point));
previous = point;
}
distance += distCalc.calcDist(lat(previous), lng(previous), lat(end), lng(end));
...
return distance;
} Для найденного ребра затем создаётся объект класса ReaderWay, в который передаются параметры дороги:
private void addEdge(int fromTower, int toTower, SimpleFeature road, double distance,
GHPoint estmCentre, PointList pillarNodes) {
...
ReaderWay way = new ReaderWay(id);
way.setTag("estimated_distance", distance);
way.setTag("estimated_center", estmCentre);
...
// Тип дороги
Object type = road.getAttribute("fclass");
if (type != null) {
way.setTag("highway", type.toString());
}
// Максимальная скорость
Object maxSpeed = road.getAttribute("maxspeed");
if (maxSpeed != null && !maxSpeed.toString().trim().equals("0")) {
way.setTag("maxspeed", maxSpeed.toString());
}
...
}В конце настройки регистрируем созданную дорогу в encodingManager:
encodingManager.handleWayTags(way, acceptWay, tempRelFlags);
...
encodingManager.applyWayTags(way, edge);Здесь и обрабатываются свойства дороги для определения скорости и направления в ребре графа.
На всю Россию получилось примерно 14.5 миллионов рёбер.
Метод processRestrictions — запрет поворота
Он присутствует в реализации, и накладывает ограничение на проезд, например запрет поворота налево (см. OSMTurnRelation), однако не используется из-за отсутствия в скачанных мною данных, полей:
restriction— тип ограниченияrestriction_to— по отношению к какой дороге это ограничение накладывается.
Если хотите чтобы заработал, надо искать другой источник данных или задавать самостоятельно, (я скачал shape c geofabrik.de, но об этом ниже). И не забыть также изменить SQL представление (о представлении тоже ниже).
Результат
К счастью проходить всю процедуру построения графа дорог не придётся при каждом запуске приложения, после построения, граф будет благополучно сохранён в указанную директорию. При перезапуске, приложение обратится к этой директории и загрузит индекс из файлов.
На построение графа дорог всей России потребовалось примерно 10 ГБ оперативной памяти, поэтому не забывайте про -Xms.
Как это использовать?
В первую очередь читайте README автора, но свои пять копеек так же вставлю.
Подготовка данных
Для начала нам нужно где-то взять данные, удобно скачать shape c geofabrik, и загрузить файл gis_osm_roads_free_1.shp (название может немного отличаться) в свою БД, предварительно создав в ней таблицу для дорог (поля соответствуют тем, что представлены в shape файле):
CREATE TABLE public.gis_osm_roads (
osm_id varchar(10) NULL,
code int2 NULL,
fclass varchar(28) NULL,
"name" varchar(100) NULL,
ref varchar(100) NULL,
oneway varchar(1) NULL,
maxspeed int2 NULL,
layer float8 NULL,
bridge varchar(1) NULL,
tunnel varchar(1) NULL,
geom geometry(MULTILINESTRING, 4326) NULL,
CONSTRAINT gis_osm_roads_pkey PRIMARY KEY (osm_id)
);
CREATE INDEX gis_osm_roads_geom_idx ON public.gis_osm_roads USING gist (geom);В fclass содержится значение тега highway, можете выбрать только те типы дорог, которые вас интересуют, а лишние удалить чтобы не занимали место и не тратили время.
Скачанные геоданные имеют тип MULTILINESTRING, мне было удобнее работать с LINESTRING, поэтому я сначала гружу во временный слой gis_osm_roads, а потом осуществляю конвертацию с помощью ST_LineMerge в другой слой — gis_roads (gis_osm_roads можно после этого удалять):
INSERT INTO gis_roads (fclass,"name",oneway,maxspeed,bridge,tunnel,geom)
(SELECT fclass,"name",oneway,maxspeed,bridge,tunnel,ST_LineMerge(geom) FROM gis_osm_roads)Вы можете не конвертировать из MULTILINESTRING в LINESTRING, построитель графа и маршрутизатор умеют работать с обоими типами. Я произвожу конвертацию потому что, при добавлении новых данных в слой, мне удобнее работать с LINESTRING .
Таблица не обязательно должна однозначно соответствовать полям в скачанном файле, я добавил в неё несколько дополнительных полей, например дата загрузки date_load, и удалил то, что посчитал лишним, например ref. Ключ создал свой — gid (т.к. вставка данных предполагается не только за счёт импорта с OSM, но и из своих источников), osm_id по сути уже и не нужен. Вы можете аналогично создавать и удалять поля. Для построителя в первую очередь важны fclass, geom, maxspeed, oneway, на основе которых создадим представление:
CREATE OR REPLACE VIEW public.roads_view
AS SELECT gis_roads.gid AS osm_id,
gis_roads.maxspeed,
gis_roads.oneway,
gis_roads.fclass,
gis_roads.name,
gis_roads.geom
FROM gis_roads;Поля bridge и tunnel не нужны для прокладки маршрута, т.к. для GraphHopper важно наличие общей точки, а не тип, однако эти поля важны для поиска пересечений при вставке новых линий, — логично, мост или эстакада не должны иметь точек пересечения с дорогой над которой они проложены.
Я загрузил дороги Калининградской области — она занимает меньше места среди других shape файлов. Если не хочется мучаться с загрузкой, то контейнер с загруженными данными можно взять с Docker Hub: tkachenkoivan/road-data.
Итак, данные получены. Переходим к построению графа.
Индексирование и построение маршрута
Разобранный далее код, можно полностью увидеть на GitHub: пример построения маршрута.
Создаём объект, для индексирования и построения маршрута:
GraphHopper hopper = new GraphHopperPostgis().forServer();Выполняем настройку:
параметры подключения к БД,
указываем имя представления, в котором присутствуют данные —
roads_view,директорию, где будут храниться построенные индексы,
encoder.
Поскольку мы решили строить автомобильные маршруты, то указываем имя для класса CarFlagEncoder:
GraphHopperConfig graphHopperConfig = new GraphHopperConfig();
graphHopperConfig.putObject("db.host", host);
graphHopperConfig.putObject("db.port", port);
...
graphHopperConfig.putObject("datareader.file", "roads_view");
graphHopperConfig.putObject("graph.location", dir);
graphHopperConfig.putObject("graph.flag_encoders", "car");Используем параметры для индексирования графа дорог, или загрузки из файлов, если он уже был ранее проиндексирован:
hopper.init(graphHopperConfig);
hopper.importOrLoad();Вызывается метод init, класса GraphHopperPostgis.
Теперь можем построить маршрут, указывая в запросе точки, которые хотим посетить:
GHRequest request = new GHRequest();
for (int i = 0; i < points.size(); i++) {
request.addPoint(new GHPoint(points.get(i)[0], points.get(i)[1]));
}
request.setProfile("my_car");
GHResponse response = hopper.route(request);Маршрут построен!
Как обрабатывать появление новых данных?
Чтение из БД для маршрутизации мы подсмотрели у Georepublic, спасибо им, однако там ничего нет о появлении новых данных. В целом это не проблема, если в качестве источника используется OSM, можно:
раз в какой-то период, например месяц, брать новую выгрузку OSM;
удалять из своей БД все данные;
заменять их новой выгрузкой;
перестраивать граф дорог.
Давайте подумаем что делать, если нам такой сценарий не подходит, например по той причине, что у нас свой анонимный источник данных о дорогах.
Саму вставку данных разбирать не будем, оставим без ответа вопрос о том, как эти данные в таблицу попали: может их загрузили из shape-файла, может этот слой можно редактировать через GeoServer, может геометрии были созданы через SQL выражения… здесь пусть каждый извращается как умеет.
Разберём что делать с новыми данными после того как они оказались в слое — как сделать так, чтобы новые данные учитывались при построении маршрута. А учитываться они будут в том случае, если имеют общие точки с другими линиями, в местах пересечений. Иными словами: нам эти точки предстоит создать, если их там ещё нет.
Итоговый файл присутствует на GitHub Gist Tkachenko-Ivan/PostGisGeometry.java
Вначале подключите net.postgis:
net.postgis
postgis-jdbc
2.3.0
jar
Поиск пересечений
Создадим функцию поиска пересечений, воспользуемся ST_Intersection:
private List> findIntersect(List tempIds) {
if (tempIds.isEmpty()) {
return new ArrayList<>();
}
String ids = StringUtils.join(tempIds, ',');
String sql = String.format(
"""
SELECT
ST_Intersection(temps.geom, mains.geom) intersects,
temps.gid temps_id,
mains.gid mains_id,
temps.geom temps_way,
mains.geom mains_way
FROM
road_temp AS temps,
road_temp AS mains
WHERE temps.gid IN (%s)
AND temps.gid <> mains.gid
AND ST_Intersects(temps.geom, mains.geom) IS TRUE
""", ids);
return jdbcTemplate.queryForList(sql);
} В WHERE temps.gid IN (...) передаются идентификаторы добавленных линий, добавлены они сразу в основной слой, поэтому необходима проверка temps.gid <> mains.gid, чтобы не обрабатывать пересечения с самим собой. Чтобы исключить всякие мосты и тоннели, добавляйте подобные условия:
AND (mains.bridge IS null OR mains.bridge = 'F')Пересечения нашли с помощью SQL.
Обработка пересечений
Перебираем в цикле найденные пересечения:
List> intersects = findIntersect(tempIds);
for (Map intersect : intersects) {
// Идентификатор рассматриваемых линии
Long tempId = ((Number) intersect.get("temps_id")).longValue();
Long mainId = ((Number) intersect.get("mains_id")).longValue();
...
// Геометрия пересечения
PGgeometry pgGeom = (PGgeometry) intersect.get("intersects");
Geometry geom = pgGeom.getGeometry();
switch (geom.getTypeString()) {
...
}
}
Здесь всё зависит от того, какого типа геометрия пересечения, подробнее они будут разобраны ниже, в примерах. Но всё сводится к одной цели — иметь точки с одинаковыми координатами на месте пересечения.
Модификация линий
Найдя факт пересечения линий, все эти линии необходимо модифицировать создав в них точки на месте пересечения.
Линия представляет собой массив точек, какую точку вставить мы уже знает, — точку пересечения, осталось найти место в массиве куда вставлять.
Зная координаты точки пересечения, мы можем воспользоваться функцией ST_LineLocatePoint, которая возвращает значение с плавающей точкой от 0 до 1, представляющее местоположение точки на линии:
String sql = String.format("SELECT ST_LineLocatePoint(geom, ?) FROM %s WHERE gid = %d", layerName, lineId);
double part = jdbcTemplate.queryForObject(sql, Double.class, new PGgeometry(intersectPoint));Теперь нужно понять сколько точек в массиве располагается на этом участке, для этого воспользуемся ST_NumPoints:
int pointCount = 1;
if (part != 0) {
// Количество точек в этой части линии
sql = String.format("SELECT ST_NumPoints(ST_LineSubstring(geom, 0, %s)) FROM %s WHERE gid = %d", part + "", layerName, lineId);
pointCount = jdbcTemplate.queryForObject(sql, Integer.class);
}Теперь мы знает точку, после которой необходимо вставить найденную точку пересечения, при условии что координаты этих точек не совпадают, Для вставки воспользуемся функцией ST_AddPoint:
Point existPoint = tempWay.getPoints()[pointCount - 1];
if (existPoint.x != intersectPoint.x || existPoint.y != intersectPoint.y) {
// Если отсутствует, - то создать
sql = String.format("UPDATE %s SET geom = ST_AddPoint(geom, ?, %d) WHERE gid = %d", layerName, pointCount - 1, lineId);
jdbcTemplate.update(sql, new PGgeometry(intersectPoint));
}Здесь tempWay — это полученная из БД линия, чтобы ещё раз убедиться что координаты точки в указанной позиции не совпадают с добавляемой точкой пересечения.
Получение tempWay:
sql = String.format("SELECT geom FROM %s WHERE gid = %d", layerName, lineId);
LineString tempWay = (LineString) jdbcTemplate.queryForObject(sql, PGgeometry.class).getGeometry();Теперь рассмотрим несколько примеров.
Примеры
Данные, для моделируемых ситуаций я выложил в репозиторий GitHub Tkachenko-Ivan/shape-example-graphhopper, здесь они сохранены в shape-файлы, в README представлены схематичные иллюстрации содержимого, и дано текстовое представление данных. Текстовое представление можно использовать чтобы не грузить shape, а создать линии сразу в БД, с помощью ST_LineFromText, например:
INSERT INTO road_temp (gid,geom) VALUES (63,ST_LineFromText('LINESTRING (66.08940600324757 57.261858384708496, 66.09133689803114 57.26600914483714)',4326))Пересекающиеся линии
Сначала добавим две линии, которые пересекают одну из существующих линий, и пересекаются между собой. Точки, на местах пересечения не созданы — необходимо их создать. Например добавление 1 и 3 к линии 2.
 Пересекающиеся линии
Пересекающиеся линии
Мы должны обработать новые линии и создать точки на местах пересечений, при том, как на месте пересечений двух новых линий между собой, так и на месте пересечения с уже добавленной ранее линией.
Если линии пересекаются, то точки, на местах пересечений, должны быть добавлены в обе линии:
case "POINT" -> {
// Модифицируем временную линию
lineModificate(tempId, (Point) geom);
// Модифицируем постоянную линию
lineModificate(mainId, (Point) geom);
}Было:
LINESTRING (66.06819599931458 57.25031281486611, 66.07962892895415 57.24961189436822)
LINESTRING (66.07467465944366 57.24771511084118, 66.07660555422723 57.25186587096982)
LINESTRING (66.07091449591776 57.24793501267562, 66.07284539070133 57.252085772804264)Стало:
LINESTRING (66.06819599931458 57.25031281486611, 66.0719145752549 57.25008483951931, 66.0756699340296 57.249854609121236, 66.07962892895415 57.24961189436822)
LINESTRING (66.07467465944366 57.24771511084118, 66.0756699340296 57.249854609121236, 66.07660555422723 57.25186587096982)
LINESTRING (66.07091449591776 57.24793501267562, 66.0719145752549 57.25008483951931, 66.07284539070133 57.252085772804264)Можно запустить ещё раз обработку этих линий, для того чтобы убедиться что повторно точки пересечения не создаются, — у ранее созданных точек дубли не появляются.
Если передать линии 1 и 3, для обработки, то будет найдено как пересечение 1 с 3, так и 3 с 1, важно повторно линии не обрабатывать, поэтому для хранения факта обработки необходимо создать список, и проверять в нём факт обработки.
public void putIntersectionPoint(List tempIds, List deleteList) {
List map = new ArrayList<>();
// Поиск пересечений
List> intersects = findIntersect(tempIds);
for (Map intersect : intersects) {
...
if (map.contains(new Bidi(mainId, tempId))) {
// Это пересечение уже было обработано в другой комбинации
continue;
}
// Сохранить признак того что эта пара линий уже обработана
Bidi bidi = new Bidi(tempId, mainId);
if (!map.contains(bidi)) {
map.add(bidi);
}
...
}
} Соприкасающиеся линии
Отличие от предыдущего примера в том, что одна линия, своим концом примыкает к другой линии, но не пересекает её.
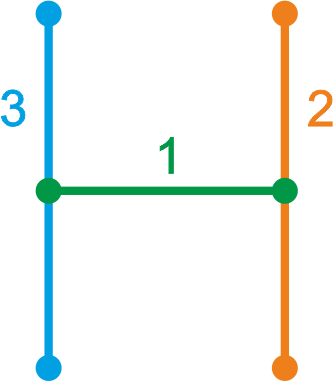 Соприкасающиеся линии
Соприкасающиеся линии
Необходимо убедиться что мы находим и корректно обрабатываем эту ситуацию: в одной из линий, создавать новую точку не надо, точка пересечения, ну или «примыкания», уже создана, осталось модифицировать вторую линию. Но это в идеале, практика несколько далека от идеала, из-за возможных допусков.
Ситуацию смоделировать легко, а вот написать обработчик наоборот — сложно. Основная сложность заключается в том, что примыкание может осуществляться с некоторой погрешностью, разумной конечно же. Если мы используем функцию ST_Intersects для определения статуса пересечения (пересеклась или нет), то допустимая погрешность 0.00001 (sic!). Это очень мало, невозможно гарантировать что все линии будут создаваться с таким допуском, поэтому первое что нужно сделать — перегрузить функцию ST_Intersects:
CREATE FUNCTION ST_Intersects(geography, geography, float8)
RETURNS boolean
AS 'SELECT $1 OPERATOR(&&) $2 AND _ST_Distance($1, $2, 0.0, false) < $3'
LANGUAGE 'sql' IMMUTABLE;Теперь мы можем находить факт пересечения с той погрешностью, с которой посчитаем необходимым.
ST_Intersection находит геометрию пересечения — точку пересечения, которую мы ожидаем найти, однако, из-за тех же допусков и погрешностей может возвращать пустую геометрию. В этом случае можно воспользоваться функцией ST_ClosestPoint, которая вернёт из первой геометрии самую ближайшую точку ко второй геометрии:
CASE
WHEN ST_IsEmpty(ST_Intersection(temps.geom, mains.geom))
THEN ST_ClosestPoint(temps.geom, mains.geom)
ELSE ST_Intersection(temps.geom, mains.geom)
END intersectsПонятно что «ближайшая» и «лежащая на линии» не совсем одно и то же, тем более что мы вводим некоторые допуски, поэтому, есть вероятность что будет две близко расположенные, но отличающиеся друг от друга, точки.
Кроме того, введение погрешности значительно замедляет работу SQL-запроса при поиске пересечений, если данных много, например все дороги России, — замедление становится чувствительным.
Соединяющиеся линии
Тут всё просто, линии примыкают друг к другу.
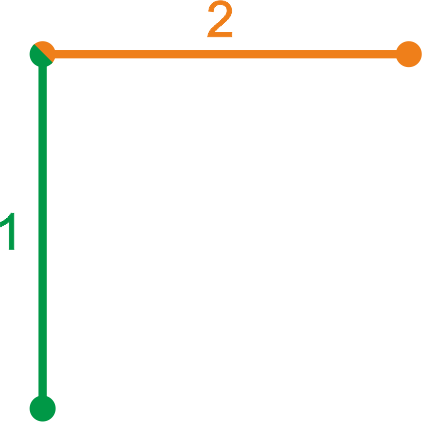 Соединяющиеся линии
Соединяющиеся линии
Если конечные точки линий совпадут, то линии останутся неизменными, если из-за погрешности точки не будут совпадать, то одна из линий будет модифицирована.
Многократное пересечение линий
Две линии пересекаются более чем один раз. Необходимо убедиться что все точки пересечения будут созданы.
 Многократно пересекающиеся линии
Многократно пересекающиеся линии
Особенность этого случая в том, что пересечением будет MULTIPOINT:
MULTIPOINT ((66.07382786284145 57.25453467704222), (66.07476362252248 57.25654623873221))Во всех предыдущих случаях был POINT.
Мы можем разложить MultiPoint на Point, и обработать все точки последовательно, независимо друг от друга:
case "MULTIPOINT" -> {
MultiPoint multiPoint = (MultiPoint) geom;
for (Point point : multiPoint.getPoints()) {
// Обработка как при обработке POINT
...
}
}Накладывающиеся линии
Здесь линии не просто пересекаются, но частично накладываются друг на друга. Тот участок, который повторяется в обеих линиях, он избыточен, хранить его не надо, и поэтому из одной из линий он должен быть удалён. В этом случае линия разбивается на части, и части сохраняются как новые линии.
 Накладывающиеся линии
Накладывающиеся линии
Если одна из линий существует давно, а вторая загружена и в процессе обработки, то логично старую линия не трогать, а новую разбить на участки. Если обе линии новые, то «жертвой» может стать любая из них.
Результатом пересечения в этом случае будет LINESTRING, или MULTILINESTRING (если линии совпали на разных участках), например:
LINESTRING (66.08938990291034 57.24927918041815, 66.0888363036685 57.24808912999145)Именно этот участок необходимо убрать. Воспользуемся ST_Difference и посмотрим что осталось от линии:
/**
* Сохраняем различия линий (в виде новых линий) имеющих повторяющиеся куски
*
* @param tempId идентификатор временной линии
* @param mainId идентификатор уже существующей линии
* @return список идентифкаторов созданных линий
*/
private List lineSpliter(long tempId, long mainId) {
List result = new ArrayList<>();
// Получаем разницу
String sql = String.format(
"""
SELECT diff FROM
(
SELECT ST_Difference(temps.geom, mains.geom) AS diff
FROM
%s AS temps,
%s AS mains
WHERE temps.gid = %d AND mains.gid = %d
) dif
WHERE ST_IsEmpty(diff) = false
""", layerName, layerName, tempId, mainId);
List> differences = jdbcTemplate.queryForList(sql);
for (Map difference : differences) {
PGgeometry pgGeom = (PGgeometry) difference.get("diff");
Geometry geom = pgGeom.getGeometry();
// Вставить в ту же самую таблицу
result.addAll(insertTempLines(geom, tempId));
}
return result;
} В нашем примере, от линии останется два отдельных куска, их надо вставить в слой:
public List insertTempLines(Geometry geom) {
List result = new ArrayList<>();
if (geom.numPoints() != 0) {
String sql = "INSERT INTO road_temp (geom, date_load) VALUES (?, current_date)";
KeyHolder keyHolder = new GeneratedKeyHolder();
MultiLineString multiLine = (org.postgis.MultiLineString) geom;
for (org.postgis.LineString line : multiLine.getLines()) {
jdbcTemplate.update(
(Connection connection) -> {
PreparedStatement ps = connection.prepareStatement(sql, new String[]{"gid"});
ps.setObject(1, new PGgeometry(line));
return ps;
},
keyHolder);
result.add(keyHolder.getKey().longValue());
}
}
return result;
} Изначальная линия после этого должна быть удалена, а две новые линии необходимо обработать так же, как если бы изначально вставляли их, а не удалённую линию, — рекурсия.
Это самая сложно воспроизводимая из ситуаций, всё дело, как всегда, в погрешности. Если при редактировании карты не включён режим «прилипания», или он сам рассчитал с некоторым допуском (например в QGIS он может работать с точностью до 0,00001 градуса) — идеального совпадения не будет, а значит участок не будет обнаружен. Конечно факт пересечения в виде точке будет найден, благодаря ST_ClosestPoint, но именно точки, а не линии. И это меньшее из зол. Можно попытаться нивелировать погрешность с помощью ST_Buffer, однако считаю это плохой идеей, т.к. ST_Buffer скажется даже на тех запросах, где результатом пересечения должна быть точка, — вместо неё будет линия длинной с размер буфера.
Полное наложение линий
Ситуация может быть типичной, например если один и тот же файл загружать дважды, например по ошибке.
 Полное наложение линий
Полное наложение линий
Необходимо убедиться что останется только одна линия: новая линия не будет создана, если в БД уже такая существует, а если дубль присутствует в самом файле загрузки, то будет выбрана и создана только одна из двух.
Воспользуемся методом ST_Difference, например таким образом:
SELECT ST_Difference(temps.geom, mains.geom) AS diff
FROM
road_temp AS temps,
road_temp AS mains
WHERE temps.gid = 1 AND mains.gid = 2Если линии полностью совпадают, то ответом будет LINESTRING EMPTY. Для удобства можем в запрос добавить ST_IsEmpty(diff), и условие проверяющее на пустоту.
Поглощение линий
Так же может возникнуть ситуация когда одна линия больше чем другая, но при этом полностью её поглощает. Если добавляется меньшая линия, — она должна быть удалена, если большая, — она должна быть рассечена повторяющейся частью.
Похоже на пример с «наложением линий».
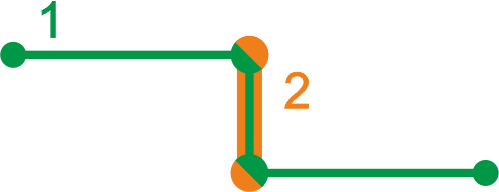 Поглощение линий
Поглощение линий
Важно обратить внимание на последовательность действий: когда линия разделяется на кусочки (путём удаления совпадающей с другими линиями части), происходит операция вставки этих линий, и их тоже надо обработать как добавленные линии и найти точки пересечения с уже существующими. Необходимо чтобы линия, из которой они получились не участвовала в запросе поиска пересечений, иначе изначальная линия их полностью поглотит. Исходную линию надо как-то исключить, или даже удалить — deleteFromTemp, и только потом выполнять поиск пересечений рекурсивно вызвав putIntersectionPoint.
case "MULTILINESTRING", "LINESTRING" -> {
// Если геометрией пересечения является линия значит временная линия будет поделена на несколько других
List newTempIds = lineSpliter(tempId, mainId);
// Удалить лишнюю линию
deleteList.add(tempId);
deleteFromTemp(Arrays.asList(tempId));
putIntersectionPoint(newTempIds, deleteList);
} private void deleteFromTemp(List deletesIds) {
if (!deletesIds.isEmpty()) {
String sql = String.format("DELETE FROM %s WHERE gid IN (%s)", layerName, StringUtils.join(deletesIds, ','));
jdbcTemplate.update(sql);
}
} Наложение + пересечение линий
Идея та же: одна из наложившихся линий будет удалена, вместо неё будет создано две новые линии. Однако помимо наложения, эта линия ещё и имеет точки пересечения с некоторыми линиями (например при добавлении линии 4, она частично совпадает с линией 3, линия 4 будет удалена, и вместо неё появятся две новые).
 Наложение и пересечение линий
Наложение и пересечение линий
Необходимо убедиться, что в местах пересечений будет создано только по одной точке в каждой линии, и удаление не приведёт к ошибкам, в случае, если в списке найденных пересечений, имеется факт пересечения с удалённой ранее линией. Поэтому можно сохранять список удалённых линий, и при обработке найденных пересечений, проверять не была ли эта линия удалена:
if (deleteList.contains(tempId) || deleteList.contains(mainId)) {
// Одна из этих линий была удалена на предыдущем шаге
// найденное пересечение уже не актуально
continue;
}Это был последний из рассматриваемых примеров.
Итог
Статья получилась объёмной, давайте ещё раз соберём всё вместе.
И так, мы разобрали решение от Georepublic, оригинал их репозитория есть на GitHub: mbasa/graphhopper-reader-postgis.
Я сделал форк их решения и немного подшаманил его: Tkachenko-Ivan/graphhopper-reader-postgis.
Данные в виде spahe файлов можно взять с geofabrik.
Для тех, кому данные не принципиальные и хочется перейти к экспериментам с построителем, я уже загрузил данные по Калининградской области и выложил в докер контейнере на Docker Hub: tkachenkoivan/road-data.
Затем разобрали как обрабатывать появление новых данных в таблице, получившийся код есть на GitHub Gist Tkachenko-Ivan/PostGisGeometry.java
Примеры загружаемых данных, на которых можно протестировать загрузку есть на GitHub: Tkachenko-Ivan/shape-example-graphhopper
Мы рассмотрели, как реализовать в GraphHopper чтение данных из источника отличного от OSM, на примере PostgreSQL, но точно такой же подход можно использовать для чего угодно, из чего можно получить список дорог и их координат.
Удачи!
