Как дискомфорт помогает нам совершенствовать процесс разработки

Я тимлид и моя задача — обеспечить продуктивную работу команды. Это непросто, поскольку готового рецепта успеха не существует. Конечно, есть признанные методологии: Agile, Lean, Value Stream Mapping. Они дают общие ориентиры и ценности, что уже неплохо, но это лишь ориентиры. А с конкретными решениями, будь добр, вертись сам. На то ты и тимлид.
В статье я расскажу, как мы с командой постепенно сформировали и теперь регулярно уточняем подход к эффективной работе. Ключевой момент в том, что выбранные инструменты действительно приняты всей командой и прижились в работе. Это даёт надежду на то, что подход полезный.
Немного контекста
В True Engineering мы занимаемся enterprise-разработкой. Делаем огромный, многолетний продукт, в котором участвует множество команд. Конкретно наша команда — это семь человек: четыре разработчика, один тим-тех-лид (пишет код и много), один QA, один PM. Продукту, над которым работает команда, два года. Техническое состояние — усилиями всей команды — близко к образцовому.
Дискомфорт как инструмент диагностики
Для поиска и осознания проблем в команде мы используем довольно простой инструмент — дискомфорт участников.
Речь, конечно, не про ситуации, когда одному человеку кондиционер дует, а другому жарко. Я говорю о сбоях в нормальном потоке работы.
Например, релиз прошёл криво, хотя каждый по отдельности выполнил свою работу хорошо. Или стабилизация идёт уже две недели и команда надрывается, хотя мы сами делали оценки и нам никто не мешал сделать хорошо. Или бизнес получил не то, что ожидал.
Как действовать в подобной ситуации:
- Остановить панику и осознать, почему прямо сейчас мы испытываем дискомфорт.
- Докопаться до исходной причины. Например, используя технику «Пять почему» или просто здравый смысл.
- Решить, как лечить проблему. Ориентиры для выбора подходящего решения мы обсудим в конце статьи. Здесь же отмечу принципиально важный момент: мы используем дискомфорт для диагностики проблем, но это не значит, что ориентиром для выбора решений является достижение комфорта. Помните про основную причину существования вас как команды — ценность для бизнеса. Никому не нужна счастливая команда, которая не приносит результат.
- Спустя время провести ретроспективу. Если принятое решение не помогло — возвращаемся к пункту 1 с новым пониманием. Если помогло — автоматизируем либо вносим в список принципов для будущих новичков. Никакой контроль уже не нужен, участники сами примут подход в работу, если он действительно хорош.
Описанный алгоритм несложный, но и конкретики маловато. Далее я опишу принципы, выведённые нами с использованием такого подхода. Чтобы статья не превратилась в мемуары, я буду описывать только полученный результат, а не всю историю от осознания боли до её устранения.
Принципы, на которых мы строим процесс
1. Мы постоянно создаём и укорачиваем петли обратной связи
На обратной связи построено всё взаимодействие человека с внешним миром, без неё невозможно проверить корректность выполненного действия. Представьте, какой была бы наша жизнь, не чувствуй мы боли, прыгая с четырёхметровой высоты или хватая раскалённый чайник.
В разработке примером хорошей, короткой петли обратной связи может служить code completion — он сообщает нам о правильности действия прямо в момент набора кода.
Теперь пример отсутствия петли обратной связи: мы знаем о проблеме у пользователей, но не можем её воспроизвести, у нас нет логов, нет возможности быстро выкатить исправление и мы вообще не знаем, какая версия сейчас на проде. Врагу не пожелаешь.
Каждое действие в процессе разработки может и должно давать обратную связь: build, lint, прошедшие автотесты, проведённое тестирование, тестовая сессия с бизнесом, успешный deploy, мониторинг prod— всё это способы обнаружить ошибки и скорректировать свои дальнейшие действия.
Также стоит заметить, что стоимость ошибки растёт по мере продвижения вперёд. Если мы выпустили на production баг, который портит данные, то задача не только его исправить, но и восстановить данные (если это вообще возможно). Стоимость позднего устранения подобной ошибки очень высока, не говоря уже о последствиях для бизнеса.
Поэтому наличие большого количества быстрых и информативных петель обратной связи жизненно необходимо.
Ниже те петли, которые мы сознательно поддерживаем и при возможности укорачиваем. Полагаю, большинство вам известны. Но они у вас действительно есть и работают?
- Возможность запустить и подебажить проект локально.
- Разработка в соответствии с принципом Fail Fast.
- Быстрый, информативный CI-билд.
- Постоянный code review и работа с кодом через pull requests.
- Наличие автотестов. Тесты быстрые, стабильные, сообщения об ошибках информативные.
- Автоматический деплой, потому что ручной будет выполняться реже.
- Частые релизы вместо накопления и выпуска версии спустя недели после завершения задач.
- Информативные логи, мониторинг, инструменты диагностики. Доступ к ним у всей команды.
- Возможность фильтрации и графическая визуализация логов.
- Постоянный мониторинг технических и функциональных показателей системы как часть повседневной работы.
- Эмпирическое изучение системы — Google Analytics, анализ накопленных в системе данных.
- Хранение истории изменения данных вместо конечного состояния, если это применимо.
- Плотная, совместная работа Dev, Ops, QA, бизнеса вместо «перекидывания через забор» результатов предыдущего этапа.
- Проведение регулярных ретроспектив как внутри команды, так и с бизнесом.
- Регулярный фидбек от бизнеса. Ещё лучше фидбек от конечного пользователя.
- Возможность понаблюдать за работой пользователей «в полях».
- Возможность понаблюдать за пользователем, который видит вашу систему впервые.
В общем, обратная связь должна сама лезть на глаза. Как, например, сломанный билд.
Что примечательно, иногда для радикального улучшения достаточно совсем небольшого изменения.
Например, вы пишете логи в ELK. Они структурируются, анализируются, общедоступны — всё хорошо. Но часто ли разработчик заглядывает туда при отладке? Скорее всего, нет.
Если сообщения уровня warning и выше выводить прямо в IDE, то появляется шанс заметить, например, просевшее время выполнения запросов. Даже если это не связано с текущей задачей. Появляется шанс заметить проблему раньше, и стоимость её устранения будет ниже.
2. Любая деятельность оставляет общедоступные артефакты
Артефакты должны быть именно общедоступные. И полезные.
Благодаря этому принципу мы минимизируем bus factor, обеспечиваем единое понимание ситуации, работаем (и факапим) осознанно, постоянно делая выводы.
Некоторые практики очевидны и общеприняты: информативные сообщения коммитов, связь коммитов с задачами, описание How To Test, Definition of Done.
Есть и менее очевидные моменты:
- Нельзя «просто облажаться», провал должен быть осознан. Если разбор вскрывает плохо продуманные требования, то артефактом станут всеми осознанные уточнения. Если проблема в архитектуре системы, артефактом станет описанный технический долг с понятным сроком взятия в работу.
- Количество знаний в почте, мессенджерах, головах должно быть минимально. Все уточнения отражаются в базе знаний или в трекере задач. Так, когда тестировщик принимает задачу, для него не будут новостью изменившиеся требования. Когда бизнес принимает результат, все понимают, что должны получить. Такое состояние превращает работу в непрерывный поток. Обеспечить его (выяснять детали, обновлять базу знаний и описание задач) — задача каждого участника процесса.
- Результаты тестирования не просто «я проверил, всё ок», а общедоступный список пройденных тест-кейсов, который составлен и обсуждён ещё до тестирования, а не во время или после. Список может быть изучен и дополнен каждым участником процесса.
3. Мы уважаем право друг друга на сосредоточенную работу
Важность работы в потоке и последствия от прерывания, полагаю, уже общеизвестны. Поэтому не буду подробно останавливаться на проблеме, а сразу перейду к нашим практикам.
- Работа в наушниках только поощряется.
- Рабочее общение асинхронное. Не отвлекай коллегу мелким вопросом, задай его в трекере задач (смотри раздел про общедоступные артефакты).
- Иногда происходят вещи, прерывающие нормальный режим работы: авария на проде, непонятные требования по уже взятой в работу задаче. Сигналом может служить шумная дискуссия в кабинете, в которой участвуют три и более человек. Если подобная ситуация не разрешается за несколько минут, я назначаю одного ответственного за прояснение деталей. Остальные возвращаются к нормальной работе, пока ответственный не принесет информацию для дальнейшего анализа.
4. Мы избегаем многозадачности
Потому что многозадачность не работает. Она лишь выматывает, распыляет внимание и откладывает получение результата.
Какие практики помогают:
- Ограничение Work In Progress.
- Сосредоточенность на потоке ценности, а не ресурсах. Например, первый разработчик может сделать задачу за день, а второй за три. Но первый освободится только через неделю. Значит, задачу берёт в работу второй. Мы потратим больше времени на реализацию, но мы быстрее доставим результат (три дня вместо недели и одного дня) и перейдём к следующей задаче. При этом мы не пытаемся «впихнуть невпихуемое» первому разработчику и не отвлекаемся на работу, «повисшую» в его ожидании.
- Если в одну задачу вовлечены несколько людей и работа закончена на 90%, то цель номер один для команды — сделать всё, чтобы закончить последние 10%. Только после этого двигаемся дальше.
5. Мы принимаем архитектурные решения настолько поздно, насколько возможно
Это не наше ноу-хау, а один из базовых принципов бережливого производства.
Принятое и реализованное решение ограничивает возможность дальнейших изменений. И если решение принято в условиях неполной информации (а это почти всегда так), то шансы принять неверное решение существенно выше.
Если непринятие решения не блокирует работу и не ведёт к экспоненциальному росту технического долга, его стоит отложить, оставив систему готовой к любому решению в будущем, когда у нас появится больше информации.
Это основа разработки — мы не строим «большие» архитектуры перед началом проекта. Взамен мы делаем безопасным процесс рефакторинга (смотри раздел про петли обратной связи) и превращаем его в естественную часть процесса.
Аналогично, мы не пытаемся угадать будущие требования к системе или построить универсальное решение. Возможность безопасно рефакторить более универсальна, поскольку даёт возможность внести любые изменения в будущем.
6. Код находится в рабочем состоянии в каждый момент времени
Разумеется, это состояние недостижимо в абсолюте, система будет периодически ломаться после внесения изменений. Но это не значит, что к этой характеристике не нужно стремиться.
Когда поломка — это нештатная ситуация, а не норма жизни, то её причины легко найти. Обычно это последний коммит. Следовательно, понятен ответственный, понятны действия по устранению, понятно, когда мы вернёмся в стабильное состояние.
Получаемая уверенность в работе системы даёт ценную возможность сделать релиз в любой момент времени.
Вторая ценность — мы более уверенно даём обещания о сроках готовности. Если делить работу на две фазы: «разработка» и «стабилизация», то конкретное обещание дать трудно, поскольку «стабилизация» это работа с проблемами, которых мы ещё не знаем. Значит, не можем точно их оценить.
Если же стабилизация идёт неразрывно с разработкой и для этого есть все необходимые инструменты, то ситуация более предсказуема.
Как мы поддерживаем постоянную работоспособность:
- Очевидное: code review, автотесты, feature flags.
- Любые изменения тут же разворачиваются на тестовую среду. Если сломалось, то починить «попозже» не получится — работа QA заблокирована.
- Тестирование непрерывным потоком сразу после завершения задач, пока разработчик помнит задачу и код и быстро внесёт исправления.
- Не делаем работу частями. Если для реализации нужны два человека, то они работают в паре, в одной ветке, заливают код в основную ветку, когда он полностью готов и покрыт тестами.
- Автоматизация поставки и неизменяемые артефакты поставки, которые не нужно «допиливать» вручную.
- Каждый член команды знает инструменты диагностики, умеет с ними работать, умеет делать релизы.
7. Мы команда, а не группа разработчиков
Что означает «команда»:
- Весь код проходит review хотя бы одним человеком. Если обнаруживается серьёзная проблема, то поощряется сесть вместе и заняться парным программированием. Поделиться книгой, статьёй, развёрнутым пояснением вместо трансляции личного мнения — бесценно.
- Вместо разработки по кускам с последующей болезненной интеграцией результата мы плотно работаем в парах, когда это нужно.
- Мы не превращаем ревьюера в инструмент для проверки опечаток, приносим на ревью чистые, маленькие, pull request.
- Мы не кидаем задачи «через забор», а аккуратно сдаём работу QA, проверяя happy path самостоятельно. Помогаем QA понять, что и как можно протестировать, помогаем в прохождении пограничных сценариев (например, искусственно сломать систему).
- QA, в свою очередь, изучает внутреннее устройство системы, знает, как собрать все нужные детали (логи, состояние данных) и завести предельно информативный баг.
8. Мы рубим хвосты
Чтобы максимально эффективно и сосредоточенно делать текущую работу, мы устраняем «долги», связанные с уже сделанной работой:
- Задачи максимально быстро доводятся до прода. Только после этого мы считаем их сделанными.
- Мы непрерывно устраняем технический долг, чтобы он не разрастался до большой стоимости исправления (недели) и не блокировал работу, руша планы поставки бизнес-функциональности.
- Мы не заводим задачи, которые сделаем «когда-нибудь», а задачи-долгожители удаляем. Бизнес обязательно придёт за задачей, когда (если) время её делать действительно наступит. И на всякий случай в таск трекере можно восстановить удалённую задачу. Но нам эта функция ни разу не пригодилась.
- Долгоживущие ветки, закомментированный код, To-do-шки — всё это мертвый код, место которого в корзине.
- Нестабильные тесты сразу исправляем либо удаляем и заменяем более низкоуровневыми.
- Отслеживаем «ползучие» задачи.
Последний пункт стоит отдельного пояснения.
«Ползучими» я называю задачи с изначально небольшими трудозатратами, но висящие в In Progress по несколько дней или недель.
Почему так может быть:
- Задача изначально плохо проработана, уже потребовала множества уточнений, уточнения противоречивы или неполны. Значит, прекращаем тратить время впустую, останавливаем работу над задачей и возвращаемся к постановке.
- Задача в состоянии ожидания результата от кого-либо. Например, сервис от другой команды или уточнения от бизнеса. Держим такие задачи на карандаше и не даём им пойти на самотёк.
Соблюдать этот пункт трудно. Прежде всего, «ползучесть» нужно осознать. Затем нужно принять волевое решение и сделать шаг назад, к детализации. Это трудно сделать разработчику, поскольку время уже потрачено. И конечно, такое решение встретит сопротивление бизнеса. Но практика показывает, что это снижает шансы выдать результат, которому не будут рады ни команда, ни бизнес, ни пользователи.
В поиске подобных задач помогает график cycle time. Он показывает время от момента взятия в работу до завершения. Если задача «выбивается из толпы», то это кандидат для пристального изучения.
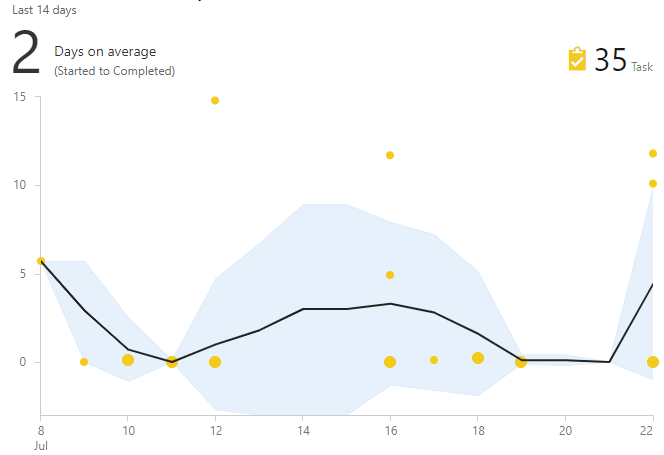
Как выбирать полезные решения
К сожалению, у меня нет готового рецепта «как надо». Эффективность команды — это эвристическая задача, а значит, она не имеет гарантированных способов решения.
Но некоторый чек-лист всё же есть. Вот он:
- Я писал об этом в начале статьи и повторюсь здесь: то, что мы используем дискомфорт для диагностики проблем, не означает, что мы стремимся к комфорту при принятии решений. Помните о главной цели — повышение ценности для бизнеса.
- При анализе проблем помните, что все участники имеют благие намерения. Если в основе ваших размышлений лежит параноидальное убеждение, что кто-то вам умышленно вредит, то принять хорошее решение очень трудно.
- Не пытайтесь всё сломать и отстроить заново. Двигайтесь маленькими шагами, внося изменения постепенно. Дождитесь, пока сделанные изменения принесут результат, и только потом внедряйте новые.
- Если понятного решения нет — двигайтесь маленькими шажками, постоянно оценивая результат и пробуя различные варианты. Понятная петля обратной связи и постоянная рефлексия — неисчерпаемый инструмент развития для вас и команды.
- Куйте железо пока горячо. Не откладывайте анализ до ретроспективы — команда уже забудет, что происходило. Лучше прийти на ретроспективу с уже осознанной проблемой и готовыми вариантами решений, которые остаётся взвесить с командой и выбрать лучшее.
- Решение должно приниматься всей командой. Никакое насаждение «сверху» не сработает, а попытки контроля — лишь иллюзия.
- Не насаждайте людям задачи, нетипичные для их повседневной деятельности. Вы столкнётесь с тысячей правдоподобных объяснений, почему обещанное не сделано, но результат не получите.
- Эффект от решения должен быть осязаемым. Вам редко удастся сформулировать решение по характеристикам SMART, но какой-то осознанный способ оценки результата должен существовать. Хотя бы по признаку «теперь так происходит реже».
- Попробуйте регулярно записывать, от чего сейчас болит сильнее всего. Если спустя полгода вы перечитываете записи с улыбкой, думая «вот же жесть была», то вы на правильном пути.
Заключение
В заключение давайте обсудим слабые стороны подхода.
Прежде всего, такой подход работает на поиск локальных оптимизаций, с ним не построить стратегию развития продукта и всей компании. Конечно, осознание проблем лучше, чем бессознательно херачить и гореть на работе, но это лишь первый шажок.
Также прошу вас, не берите готовый список принципов, возьмите инструмент, которым он создан. Вот почему:
Наш список неполон. В нём только то, что мы уже внедрили в повседневную работу.
В команде не приживутся принципы, важность которых она не осознала сама, через боль от их отсутствия. Вместо рабочих идей вы получите жупел, который какое-то время все будут носить по офису, а потом положат пылиться в угол.
Наш список специфичен. Например, если технический долг на проекте игнорировался пяток лет и сопоставим с госдолгом США, то получить пользу от принципа постоянного истребления техдолга будет очень непросто. Стоит честно признать: долг такого размера никогда не будет отдан. И сосредоточиться на решениях, которые действительно помогут сделать ситуацию лучше.
А как вы совершенствуете процесс? И какие принципы уже приняли в своей работе?
