Как быстро получить много данных от Битрикс24 через REST API
Нередко при работе с Bitrix24 REST API возникает необходимость быстро получить содержимое определенных полей всех элементов какого-то списка (например, лидов). Традиционный способ для этого — обращение к серверу через метод *.list (например, crm.lead.list для лидов) с параметром select, перечисляющим список требуемых полей.
Однако в силу того, что информация сервером выдается постранично, существует несколько стратегий для того, чтобы получить весь список, и некоторые из них позволяют ускорять процесс на порядки по сравнению с последовательным запросом страниц.
Стратегии
Ниже мы описываем три стратегии, которые мы условно назвали «ID filter», «Start increment' и «List + get».
Первые две стратегии («ID filter» и «Start increment») предложены в официальной документации Битрикс24, но мы ниже предлагаем их «докрутить».
ID filter
Запросы отправляются к серверу последовательно с параметром "order": {"ID": "ASC"} (сортировка по возрастанию ID), и в каждом последующем запросе используются результаты предыдущего (фильтрация по ID, где ID > максимального ID в результатах предыдущего запроса).
При этом для ускорения используется параметр start = -1 для отключения затратной по времени операции расчета общего количества записей (поле total), которое по умолчанию возвращается в каждом ответе сервера при вызове методов вида *.list.
В потенциале для ускорения можно попытаться параллельно передвигаться по списку сущностей в два потока: с начала списка и с конца, продолжая получать страницы, пока ID в двух потоках не пересекутся. Такой способ, возможно, будет давать двукратное ускорение до тех пор, пока не будет исчерпан пул запросов к серверу и не потребуется включить throttling.
Start increment
Стратегия, при которой перебираются страницы путем увеличения параметра start, который является средством позиционирования курсора для получения следующей страницы.
Если перед нами стоит цель получить полный набор сущностей, то, в отличие от предыдущей стратегии, эта хорошо поддается ускорению (несмотря на то, что она требует использования параметра start, что замедляет работу сервера).
После того, как мы получили первую страницу и увидели в ней общее количество элементов (поле total), то дальнейшее ускорение запросов можно получить двумя нижеописанными способами.
Объединение запросов в батчи
Зная общее количество элементов, можно сразу создать запросы на все страницы и объединить их в батчи. (Битрикс поддерживает батчи в 50 запросов.) Использование батчей позволяет обойти ограничения на максимальную скорость запросов, так как один батч считается за один запрос при учете сервером количества получаемых запросов.
Параллельная отправка батчей к серверу
Примеры кода в официальной документации Битрикс24 REST API везде предлагают последовательную отправку запросов и описывают лишь ограничения на скорость отправки запросов. Но параллельная отправка запросов возможна и позволяет сильно ускорить обмен информацией с сервером.
Впрочем, таким образом достаточно просто перегрузить сервер, который даже при соблюдении скорости запросов начинает обрывать соединение и уходить в таймауты. Поэтому такой подход требует нахождения пределов нагрузки на сервер экспериментальным способом.
Именно такая стратегия сейчас заложена в метод get_all() в питоновской библиотеке fast_bitrix24 (пиарюсь — библиотеку написал я).
List + get
Составная стратегия, при которой при помощи стратегии «Start increment» от сервера получается сначала список всех ID по методу *.list (с указанием, что нужны только ID — 'select': ['ID']) , а потом через метод *.get получается содержимое всех полей для каждого ID. При этом в обоих шагах используются описанные выше способы ускорения «Объединение запросов в батчи» и «Параллельная отправка батчей».
Тест
Чтобы проверить эффективность этих стратегий, мы провели тест (код теста).
Тест запрашивает страницы лидов (метод crm.lead.list) через 3 вышеописанные стратегии (при этом стратегия «ID filter» реализована в один поток — с начала списка ID). Для каждой стратегии запрашиваются 1, 50, 100 и 200 страниц и замеряется время выполнения запроса.
Тест использует библиотеку fast_bitrix24 для автоматического контроля скорости запросов к серверу Битрикс24.
Тест проводим на 7-й версии REST API на списке в ~35000 лидов.
Результаты теста
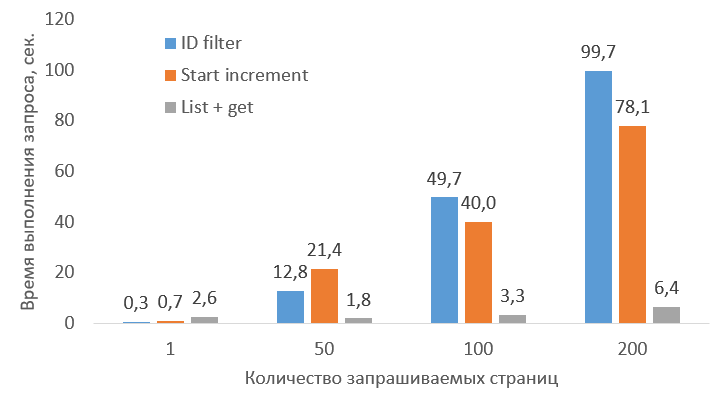
Getting 1 pages:
ID filter: 0.3 sec.
Start increment: 0.73 sec.
Getting ID list for the 'list+get' strategy, method crm.lead: 2.17 sec.
List + get: 2.61 sec.
Getting 50 pages:
ID filter: 12.8 sec.
Start increment: 21.39 sec.
List + get: 1.84 sec.
Getting 100 pages:
ID filter: 49.67 sec.
Start increment: 39.97 sec.
List + get: 3.28 sec.
Getting 200 pages:
ID filter: 99.67 sec.
Start increment: 78.05 sec.
List + get: 6.36 sec.Выводы
В целом, стратегии, использующие батчи и параллельные запросы («Start increment» и «List + get»), показали себя лучше.
Однако при этом, к моему удивлению, стратегия «List + get» оказалась на порядок продуктивнее остальных, даже несмотря на то, что в ней приходится пробегаться по всему списку два раза. (Возможно, эту статью увидят разработчики Битрикс24 и объяснят этот феномен?)
Я не уверен в существовании высокоуровневых библиотек для PHP, позволяющих пользователю реализовывать такие стратегии, не парясь упаковкой запросов в батчи и организацией параллельных запросов с контролем их скорости. Но если вы пишете на Python — милости прошу использовать fast_bitrix24, который позволяет выгружать данные из Битрикс24 со скоростью до тысяч элементов в секунду.
