Как брутить кириллические хеши в хешкате?
Вступление
Зачастую на пентест-проектах по внешке или внутрянке нам удается захватить хеши паролей. Это могут быть как соленые MD5, SHA* хеши в вебе, так и NTLMv2/NTLM хеши во внутрянке.
Конечно, успех дальнейшего продвижения напрямую зависит от успеха в атаке на перебор паролей (перебор по словарю или полный перебор по маске). Атаку на подбор паролей обычно называют брутфорс или брут от английского выражения «brute force» или же грубая сила. В последствии мы также будем придерживаться общепринятой терминологии.
И все бы ничего, пароли в латинице отлично перебираются как полным перебором по маске всех символов с инкрементом, так и по заранее сгенерированным региональным и отраслевым словарям с дополнительными правилами и без, но как быть с полным перебором кириллических символов?
Казалось бы, вполне себе логичная задача. Наши клиенты находятся в России и пароли могут состоять как из кириллических символов, например, «пароль123!», «Администрация2022», «Йй123456», так и из транслитерации русских слов в английскую раскладку, к примеру, «dkflbckfd — владислав», «vjqgjxnjdsqzobr — мой почтовый ящик» или даже наоборот из английский слов и словосочетаний в кириллическую раскладку — «щзукфешщт_сцфдд — operation_cwall». Поэтому нужно иметь как англоязычные словари, так и сконвертированные в кириллическую раскладку.
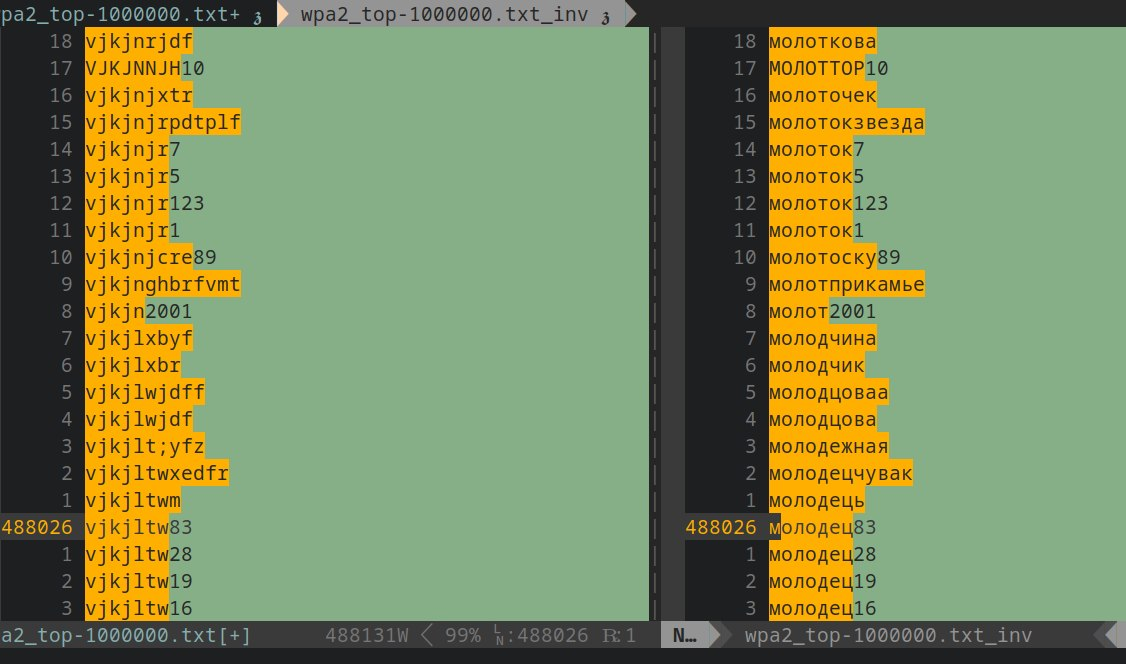 Слева исходный словарь для брута wpa2. Справа инвертированный на кириллическую раскладку
Слева исходный словарь для брута wpa2. Справа инвертированный на кириллическую раскладку
Об инстурментарии
В своей работе для брута мы используем hashcat, в качестве пилотного проекта ввели hashtopolis для составления очередей задач по перебору. Hashcat полезен для нас, так как процесс перебора может быть распределен на N-видеокарт с CUDA ядрами. Hashcat имеет широкую поддержку различных режимом атак (от перебора по словарю и маске до гибридных атак), так и поддержку множества типов хешей.
Проблема #1. Генерация кириллических чарсетов
Ну, подумали мы, в hashcat уже есть встроенные списки символов для перебора всех символов по маске:
?l = abcdefghijklmnopqrstuvwxyz
?u = ABCDEFGHIJKLMNOPQRSTUVWXYZ
?d = 0123456789
?h = 0123456789abcdef
?H = 0123456789ABCDEF
?s = «space»!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
?a = ?l?u?d?s
?b = 0x00 - 0xffДолжно же быть что-то готовое и для кириллицы. На момент начала ресерча мы уже знали о возможности составления кастомных комбинаций символов (чарсетов).
Несколько раундов гугления привели нас к первой отправной точке, а именно параметр — — hex-charset, который позволяет указывать символы в шестнадцатеричном виде. К слову, на просторах форумов hashcat несколько раз возникал один и тот вопрос, а именно как же брутить кириллические и нелатинские символы.
В одной из статей форуме hashcat пользователь Toetje предложил свой атаки на SHA1 от кириллических символов:
hashcat -m 100 -a 3 -w 3 -O hashfile.txt --hex-charset
-1 d0d1
-2 b0b1b2b3b4b5b6b7b8b9babbbcbdbebf808182838485868788898a8b8c8d8e8f
-3 909192939495969798999a9b9c9d9e9fa0a1a2a3a4a5a6a7a8a9aaabacadaeaf
?1?3?1?2?1?2?1?2?1?2?1?2Первым вопросом стало. «Черт возьми. А что это за хексы вообще?». Всё просто. Hashcat по-умолчанию работает с UTF-8 кодировкой. Кастомные чарсеты 1,2,3 являются шестнадцатеричным (хексы) отображением кириллических символов. Это можно увидеть, используя интерактивный питонячий интерпретатор:
ru_chars = 'АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдеёжзийклмнопрстуфхцчшщъыьэюя'
ru_chars.encode('UTF-8').hex() 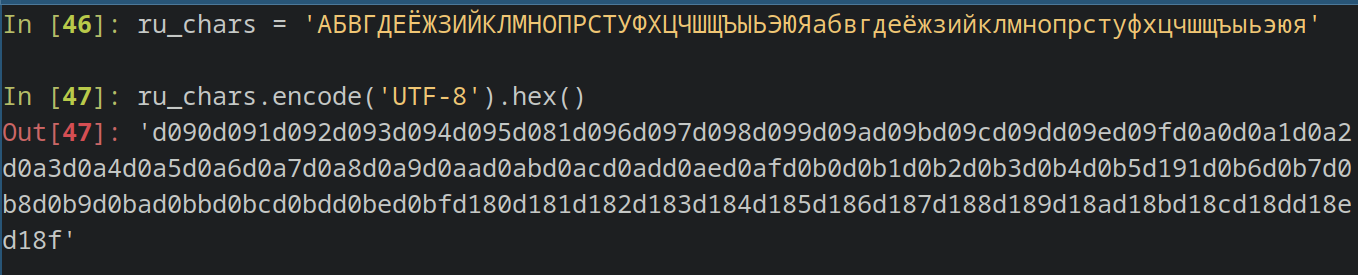 Перекодируем кириллицу в UTF-8
Перекодируем кириллицу в UTF-8
Но всё равно пока не очень понятно почему хексы кириллических символов находятся именно в таком порядке.
Вторая значимая для понимания статья открыла глаза на оптимизацию перебора кириллических символов.
Кодировки. Нужно больше кодировок
Каждый кириллический символ состоит из двух байт. К примеру, в UTF-8 кириллическая «А» кодируется как «D090», кириллическая «Б» кодируется как «D091». Занимательно. Если перекодировать все кириллические символы то получается следующее:
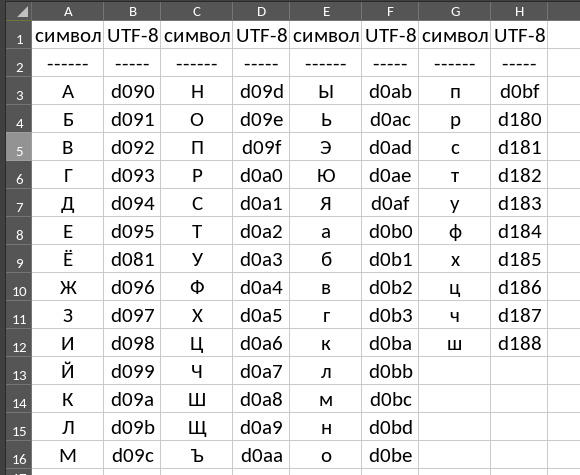 Таблица кириллицы в UTF-8
Таблица кириллицы в UTF-8
Первый байт кириллического символа — это либо «D0», либо «D1». Именно поэтому, если указать в чарсете 1 значения D0D1, а в чарсете 2 все остальные уникальные байты, то мы сможем совершить перебор всех кириллических символов. Важная деталь: так как байтов два, то для перебора одного кириллического символа в hashcat нужно указывать последовательность . Для двух символов необходимо указать соответственно.
В итоге получится что-то похожее на:
 сбрученный MD5 хеш от слова «нет»
сбрученный MD5 хеш от слова «нет»
Здесь мы для примера сгенерировали md5 хеш от кириллической строки «нет» и сбрутили этот хеш, используя созданный ранее чарсет.
Но наш брутфорс не является оптимизированным. Будут попадаться несуществующие варианты, например, шестнадцатеричная строка «D192».
Конечно, можно сделать так:
 Байтовая оптимизация перебора
Байтовая оптимизация перебора
Выделяем первые байты в отдельные чарсеты. Но тут возникает проблема. Мы не можем сделать так: ?5?1?2?1?4, так как максимальное число кастомных чарсетов равно четырем. На момент написания статьи мы не знаем как решить эту проблему.
Отлично! Теперь мы умеет брутить кириллические MD5 хеши.
Проблема #2. NTLM хеши
Разобрались с MD5 хешами — команда внешних пентестеров радуется. Внутрянщики пока не довольны — приведенный выше метод совершенно неработает для NTLM хешей.
Свежий Github Issue дал понимание о проведении атак на кириллические NTLM хеши. Для начала немного теории.
NTLM-хеш представляет из себя несоленый MD4 хеш. Поэтому для его перебора необходимо использовать режим -m 900 (raw md4) для кириллицы и или -m 1000 для латиницы.
NTLM-хеш формируется как MD4(UTF-16-LE (password)), то есть пароль кодируется в UTF16 Little Endian, а далее от полученный строки берется md4 hash.
Что же это значит? Значит именно то, что нам нужно проделать те же самые операции с кириллическими символами, но в кодировке UTF-16. Опять же используем python:
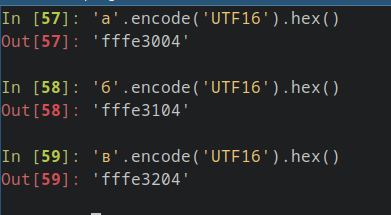
Также можем сделать обратное преобразование, срезав первые 2 байта:
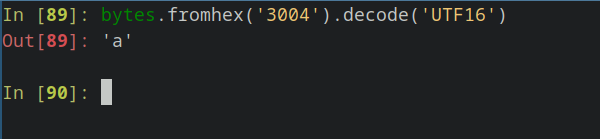
К сведению читателей, кодировка UTF-16 состоит из целых 8 байт.
В UTF-16 кириллическая «А» кодируется как »1004», кириллическая «Б» кодируется как »11004». Если перекодировать все кириллические символы то получается следующее:
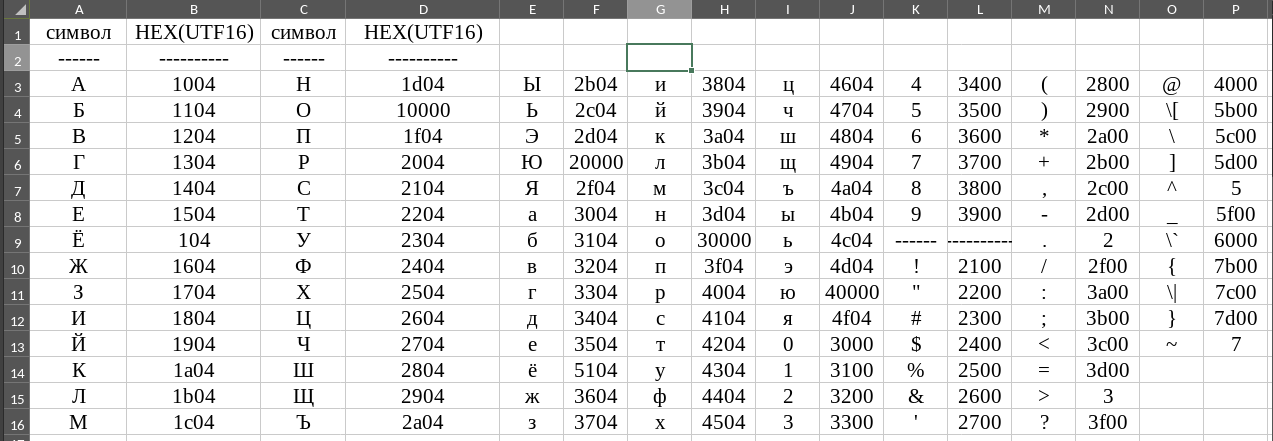 Таблица символов UTF16
Таблица символов UTF16
С учетом всего вышесказанного можем сформировать следующую команду хешката для перебора кириллических NTLM-хешей
# Перебор NTLM([<кир. символ> + цифры + "!@$**]{1})
# !!! Неоптимизированный алгоритм. Будут перебираться несуществующие символы, например 1004
time hashcat -O --hex-charset -m900 -a3 ../ntlm_allhashes.txt
-1 3031323334353637383910111213141501161718191a1b1c1d1e1f202122232425262728292a2b2c2d2e2f30313233343551363738393a3b3c3d3e3f404142434445464748494a4b4c4d4e4f2140242a
-2 0400 ?1?2Вот такие пароли получилось сбрутить по маске из 6 символов:
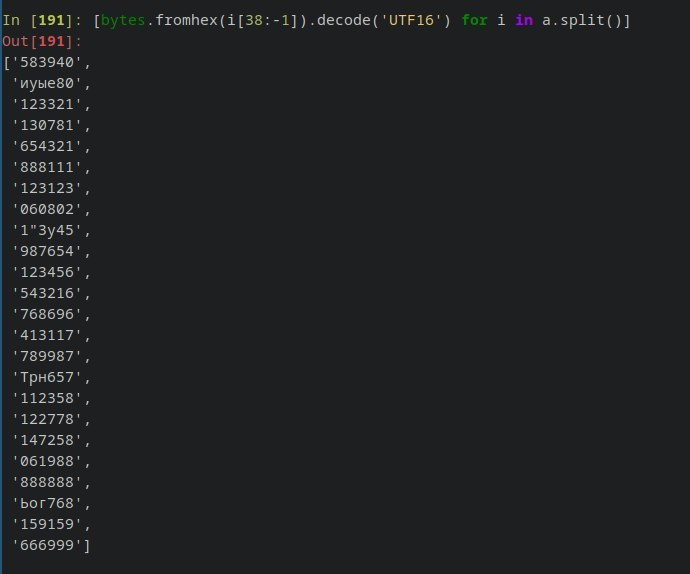 Новые сбрученные пароли
Новые сбрученные пароли
Заключение
Несколько дней ресерча позволили научиться проводить атаки полного перебора на кириллические хеши, что в дальнейшем поможет в сборе статистики, формировании новых закономерностей и новым успехам при внутренних и внешких пентестах.
В качестве инструмента для перегона паролей из разных раскладок (ru <-> en) предлагаем наш небольшой форк инстурмента crwg.
Существует множество тактик, техник, лайфхаков и просто хороших советов как правильно брутить пароли. За годы своей практики мы наработали свою базу знаний по проведению брутфорс атак. Закономерности в паролях прослеживаются от региона к региону, от компании к компании. Подробнее об этом в будущих статьях : P
