Как я занял 13 место из 3500+ участников и стал Kaggle Competition Master
Привет Хабр! Меня зовут Олег Сидоршин, я стажер (с марта буду джуном) в Лаборатории машинного обучения Альфа-Банка. До перехода в коммерческую разработку для практики своих навыков я активно участвовал в Kaggle-соревнованиях.
Этот пост — ретроспектива о крупном соревновании по компьютерному зрению Petfinder Pawpularity Prediction, которое проходило в начале 2022 года. Расскажу, как сражался на одном уровне с Nvidia с их суперкомпьютерами, что помогло пережить полет с 400+ места на 13, и конечно же, о главных советах и уроках для улучшения качества ваших ML-систем на соревнованиях и в рабочей практике, даже если у вас почти нет бюджета.

Немного о Kaggle
Kaggle — крупнейшая международная платформа соревнований по Data Science. Соревнования проводятся с поддержкой больших компаний и на реальных данных, а сами постановки задач очень разнообразны: улучшение поиска картинок Google, определение рака на родинках, IQ-тесты для ИИ. За годы работы площадка помогла в организации сотни контестов.
Kaggle имеет очень большое соревновательное комьюнити, с которым можно хорошо прокачать скиллы, изучить новые техники не в контексте тренировочных курсов или искусственных pet-проектов, а при решении реальных, практических задач, равняясь и учась у сильных участников.
Обычное соревнование проводится в течение трех месяцев и собирает тысячи участников, включая очень опытных МЛщиков из крупных компаний. Занимая верхние места соревнований, вы получаете медали, которые навсегда сохраняются в вашем профиле, а лучшие решения получают и хорошие денежные призы. Накапливая медали, вы продвигаетесь по соревновательной прогрессии, достигая различных званий.
В сфере Data Science Kaggle уже давно серьезная альтернатива GitHub для построения портфолио: люди добавляют свои профили в резюме, а в ряде вакансий это указывается как дополнительное преимущество при отборе кандидатов. Звания там служат показателем вашего общего соревновательного успеха — факта того, что вы достигли топовых мест сразу в нескольких контестах.
В этом посте я расскажу про свое второе серьёзное соревнование на Kaggle, которое одновременно стало и самым успешным — Petfinder Pawpularity Prediction, где мне удалось в одиночку попасть в топ 1% участников, заработать свою первую золотую медаль, и совершить ключевой шаг к достижению предпоследнего звания прогрессии — Kaggle Competition Master.
 Таймлайн моих приключений на Kaggle. Зарегистрировавшись в июле 2021 года, я начал практиковаться в тренировочных контестах и быстро втянулся. Первое серебро замотивировало продолжать и больше стараться — за год после регистрации я поучаствовал в 4 соревнованиях и стал Kaggle Competition Master.
Таймлайн моих приключений на Kaggle. Зарегистрировавшись в июле 2021 года, я начал практиковаться в тренировочных контестах и быстро втянулся. Первое серебро замотивировало продолжать и больше стараться — за год после регистрации я поучаствовал в 4 соревнованиях и стал Kaggle Competition Master.
Чем было интересно само соревнование?
Petfinder Pawpularity Prediction — крупное соревнование по компьютерному зрению, проходившее на Kaggle с 23.09.21 по 14.01.22. Компания-организатор Petfinder — это площадка, которая объединяет различные питомники животных.
 Немного статистик с сайта Petfinder. Компания действительно помогает питомцам.
Немного статистик с сайта Petfinder. Компания действительно помогает питомцам.
На сайт работники питомников загружают фотографии питомцев с описанием, а люди могут в удобном формате посмотреть, выбрать и принять к себе понравившихся.
Petfinder хотелось бы создать систему, которая при загрузке фотографии питомца предсказывает, насколько будет популярен питомец c такой фотографией, а если что, сможет предупредить о её плохом качестве или дать рекомендации по улучшению.
Постановка самой задачи соревнования простая — создать систему, предсказывающую популярность питомца по его фотографии.
Соответственно, в качестве данных был предоставлен набор фотографий (не слишком много, около 4000) и некоторый рейтинг популярности питомца. Детали вычисления рейтинга, конечно же, скрыты из целей коммерции и анонимизации, но известно, что он измеряется строго от 0 до 100, и нормализован относительно некоторых побочных факторов, вроде города питомца, породы и подобного, с целью изолировать только фактор влияния фотографии. Последнее, причем, получилось не особо хорошо, потому что кошки/собаки и разные породы имеют несколько разный средний рейтинг.
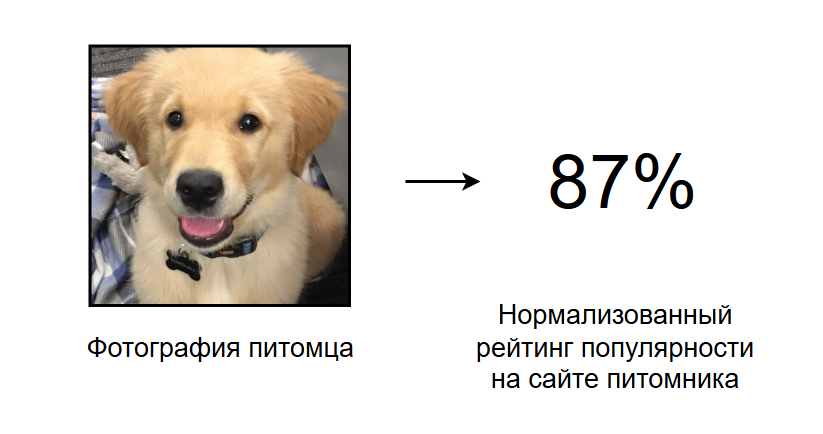
В итоге имеем довольно классическую задачу регрессии по картинкам, но c дополнительной фишкой — таргет определён довольно абстрактно, и фактически говорит, насколько пользователям субъективно приглянулась эта фотография.
Из-за абстрактной сути таргета, малого объема данных и не полностью успешной нормализации, задача получилась достаточно шумной и требует максимальной стабильности подходов в решении. Метрика оценки — корень из среднеквадратичного отклонения (RMSE).
На практике такие задачи решаются при помощи тюнинга предобученных на ImageNet SOTA моделей компьютерного зрения.
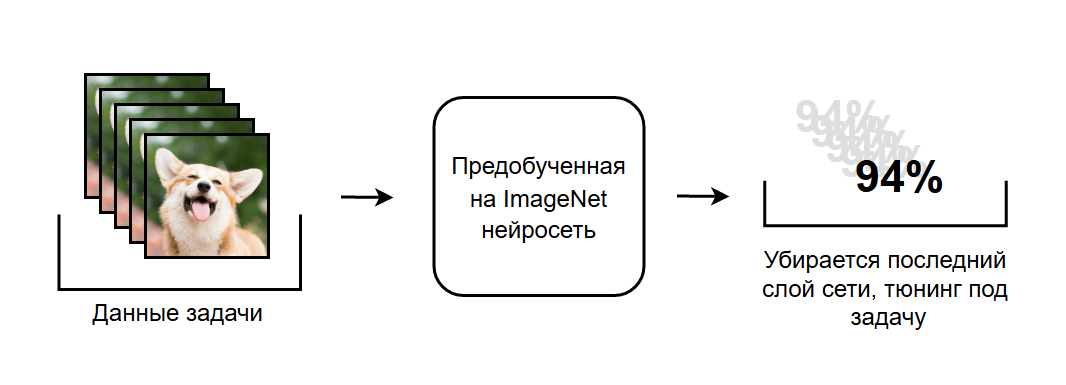
Несмотря на простоту постановки, соревнования этого рода имеют большую пользу для комьюнити:
Из-за знакомства большинства МЛщиков с такими задачами, они собирают много людей: на соревновании было больше 3500 команд, а отдельных людей ещё больше.
Из-за традиционно высокой конкуренции — это тот самый великий барьер для ресерча, когда качество новых моделей проверяется в истинной дикой природе, что является мощным бенчмарком и определяет полезные и ценные в реальности разработки.
Сразу после соревнования я сделал небольшое описание с основными моментами своего решения, но оно получилось наспех и коротким. Здесь я расскажу о главных уроках и советах подробнее.
Компьютерное зрение не заканчивается на свёрточных сетях
Сверточные сети стали применятся в компьютерном зрении давно, и именно они привели его к первым большим успехам и прорывам. Они прошли длинный путь развития — современные сетки отличаются от своих десятилетних собратьев практически всем. Со временем поменялись архитектуры, регуляризация, процедуры обучения и многое другое — кроме, собственно, самой концепции свертки, которая долгое время считалась незыблемым и незаменимым строительным блоком компьютерного зрения.
С недавними большими успехами архитектуры трансформера в NLP, исследователи заинтересовались её применимостью и на других данных, в том числе изображениях. Архитектура Visual Transformer (ViT) стала одной из первых радикально отличных архитектур сетей, показавших сильные результаты на ImageNet.
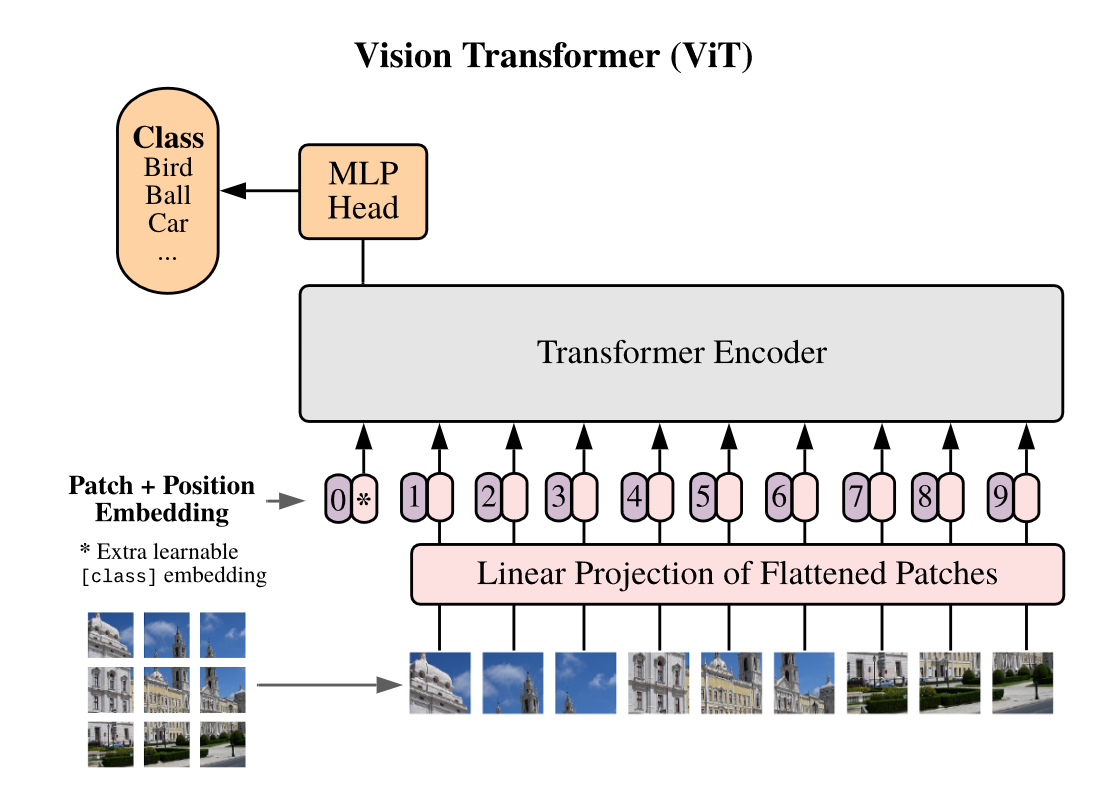 ViT адаптирует стандартную архитектуру трансформера для классификации изображений.
ViT адаптирует стандартную архитектуру трансформера для классификации изображений.
Естественно, что как только был выпущен некоторый успешный proof-of-concept в виде ViT, интерес к использованию трансформеров в компьютерном зрении возрос колоссально. Petfinder Pawpularity Prediction стало первым соревнованием, где визуальные трансформеры показали себя в полной мере — их доминирование над свёрточными сетями не заканчивалось на бумаге и переходило в практику.
Некоторую комбинацию из ViT (Deit, Beit) и Swin-трансформеров содержали все топовые решения.
Основой моего решения стали Swin-трансформеры, позже также добавились и ViT-варианты. А вот с Beit, который очень хвалили другие участники, мне что-то так и не удалось подружиться. Найти правильный подход обучения и уместить всё в разумные рамки времени и памяти оказалось сложной задачей. Как и многие другие, для работы со всеми SOTA моделями я использовал Pytorch и замечательную библиотеку timm — она содержит почти все лучшие модели и предобученные чекпойнты в открытом доступе.
Прошел год с конца соревнования, и визуальные трансформеры развились ещё больше — появились новые и улучшенные варианты архитектур, модификации и исследования процедур обучения и др. Однако свёрточные сети также не отстают — их первенство попыталась вернуть ConvNext (а сейчас уже есть и v2 версия).
Так что же в итоге лучше — сверточные сети или трансформеры? На самом деле, это не совсем правильный вопрос, потому что…
Разнообразие моделей в ансамбле
…Потому что у нас обычно нет нужды выбирать — максимум качества достигается при использовании ансамбля нескольких моделей. Причём чем разнообразнее модели по своей структуре, тем больше они смогут привнести в ансамбль индивидуально.
Таким образом, свёрточные сетки и визуальные трансформеры формируют очень сильные ансамбли — более различных по принципам работы моделей в компьютерном зрении найти сложно.
Различность моделей в ансамбле можно увеличить ещё больше, если использовать модели обученные на разных размерах картинок (например, 224×224 и 384×384), с разными аугментациями или разными функциями потерь (моя лучшая модель переделывала регрессию в классификацию — таргет разбивался на бины, и модель должна было угадать бин, а не числовое значение).
Всего в моем финальном ансамбле использовалось 7 вариантов архитектур — 5 визуальных трансформеров и 2 сверточные сети. Здесь очень бы хотелось привести красивую табличку c конкретными улучшениями от каждой из моделей, но, к сожалению, спустя год я не смог её найти. Большая часть из этих моделей добавилась только к концу соревнования, и принесла небольшие улучшения.
Вишенкой на торте стало добавление ig_resnext101_32×8d — чекпоинта resnext, обученному (судя по описанию в timm) на фотографиях из одной известной социальной сети, в которой, конечно же, очень много постов с фотками животных! Несмотря на относительно низкий индивидуальный скор модели, её добавление сильно забустило итоговый ансамбль. Найти такой уникальный чекпоинт в дремучем лесу предобученных только под imagenet моделей возможно далеко не всегда, но главное — это всегда пробовать.
Даже индивидуально слабая модель, будучи сильно отличной от остальных может существенно увеличить качество всей системы.
Верить валидации и делать её максимально стабильной
Максимизация качества — это конечно хорошо, но только когда это качество на бумаге напрямую отражает качество в реальности. Чтобы участники не занимались созданием переобученных моделей, на Kaggle используется полностью закрытый от всех тестовый набор данных, разделенный на публичную и приватную части:
свой скор на публичных данных видят все в процессе соревнования;
на приватных — только по окончанию, когда все финальные решения уже отправлены.
Именно по приватному набору определяется итоговое место — до самого конца соревнования никто из участников не может знать, где именно они окажутся.
Такой строгий подход требует создания моделей, которые генерализуются на невидимых ранее данных.
Ещё в начале соревнования я заметил сильную нестабильность валидации и её низкую корреляцию с публичным лидербордом. Соответственно, сразу же встает критический выбор — считать, что между трейном и тестом существует сильная разница, и ориентироваться полностью на публичную метрику, или же полностью верить в валидацию, максимизировать на ней качество и считать отклонения на лидерборде обыкновенным шумом.
На самом деле, такой выбор в соревнованиях далеко не всегда однозначен — ситуации бывают разными, и имеются примеры соревнований, где проявляются разные случаи. Однако я всё же выбрал второй путь: учитывая общий шум таргета и малый объем данных в паблик части теста, наблюдать скачки публичной метрики вполне ожидаемо.
Даже в условиях подмены задачи максимизация хорошей валидации всегда некоторый safe bet.
Стабильная валидация нужна и ещё по одной важной причине — искать статистически значимые различия между вашими экспериментами. Если валидационная метрика нереально шумит и скачет от разу к разу, понять разницу между экспериментом А и экспериментом Б становится невозможно, начинается слепое блуждание.
Для стабилизации кросс-валидации я сделал большое число фолдов (10) и стратифицировал их по таргету. Учитывая, что качество прыгает не только от фолда к фолду, но и от эпохи к эпохе, я полностью отказался от любых Early Stopping, выборов лучших эпох и всего такого, беря в качестве финальной метрики усредненный результат на всей кросс-валидации на последней эпохе.
Использование таких техник привносит дополнительный selection bias и неизбежно смещает валидационные метрики, а оценить степень влияния этого смещения — это отдельная полноценная задача, особенно когда с метриками и так происходит непонятно что. Тратить время и рисковать ещё больше не хочется.
Hidden text
Вероятно, что с использованием early stopping и других методик выбора ансамбль моделей оказался бы не сильно хуже (а возможно и немного лучше) по уровню качества — получился бы такой bagging переобученных на отдельных фолдах моделей. Однако прослеживать корреляцию метрики с лидербордом на такой локальной валидации было бы гораздо сложнее.
На паблик-части лидерборда я был на 437 месте, не дотягиваясь даже до бронзы, которая начинается с 353 места. Находится на таком месте после нескольких недель упорной работы морально сложно — ты всегда думаешь, что делаешь что-то не так. Резкий подъем в топ 0.3% на приватной выборке точно ощущался как праздник — вера в свою валидацию в финале окупилась с лихвой.
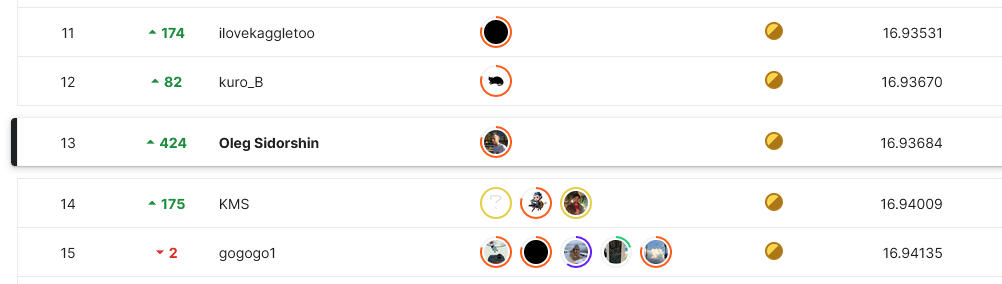
На каждый экстремальный подъем вверх есть и аналогичная ситуация отрицательного роста)) Многие ребята, находясь в топе публичного лидерборда упали на дно на приватном, потому что игнорировали локальную валидацию и ориентировались на маленький публичный набор данных, как основное мерило качества.
В рабочей практике ситуация с маленькими данными, шумным таргетом и нестабильной валидацией очень распространенна.
Уметь комфортно работать с такими сложностями — важный навык для создания успешных на практике систем.
Размер батча — это не только технический гиперпараметр
Многие новички в Deep Learning воспринимают batch size как исключительно технический параметр, в духе количества потоков на даталоадер — «ставь больше пока лезет».
На самом деле, размер батча имеет большой и сложный эффект на градиентный спуск. Малые размеры батча добавляют стохастики в процесс обучения, что способно существенно улучшать генерализацию модели (это старый трюк, можно привести множество референсов, например, такой или такой). Более того, в архитектурах с BatchNorm они очевидно влияют напрямую ещё и на его поведение, и даже есть работы, советующие брать именно для него меньший батч.
Hidden text
Это можно интерпретировать как форму bias/variance tradeoff — меняя размеры батча, мы в некотором плане варьируем смещение и вариативность наших градиентых шагов.
При обучении моделей я использовал малые размеры батчей, вплоть до 8, что считается достаточно экстремальным (до 4, увы, ещё не докатился).
Малые размеры батча можно назвать полноценным и даже довольно универсальным регуляризатором. А ещё они позволяют обучать очень большие модели на самых обычных видеокартах.
С другой стороны, здесь присутствует очевидный трейдофф времени и качества — использование большего размера батча может существенно ускорить обучение (порой даже в разы). А проблемы с генерализацией на практике можно решить, добавив больше данных или аугментациями имеющихся. Также, при использовании определенных критериев оптимизации (напр. Arcface) или в контексте большого дисбаланса классов, малые размеры батчей откровенно вредны — в этих ситуациях градиентный спуск будет делать просто пустые, абсолютно неинформативные шаги.
Опыт и вычислительные ресурсы вторичны — важны мотивация, упорство и время
Изначально кажется, что для успешного участия в таких соревнования требуется большой опыт и наличие суперкомпьютерных мощностей под рукой. Моя история, как и истории других людей показывают, что это не совсем так.
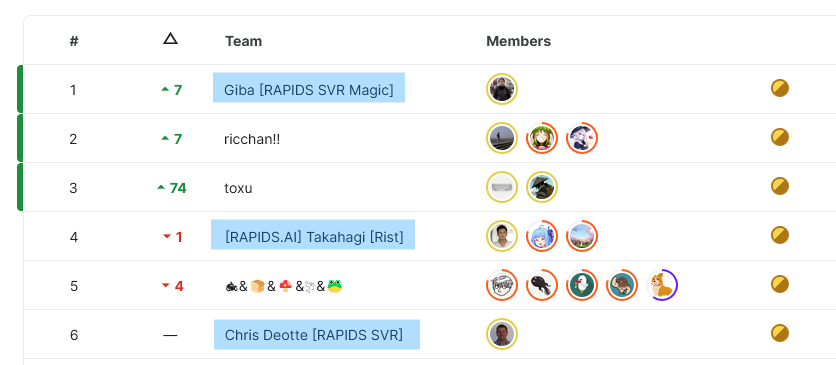 В золотой зоне оказалось три человека из Nvidia — очень опытные ребята, по некоторым слухам активно применяющие свои фирменные компьютеры-холодильники DGX.
В золотой зоне оказалось три человека из Nvidia — очень опытные ребята, по некоторым слухам активно применяющие свои фирменные компьютеры-холодильники DGX.
Как реалист я не буду спорить, что длительное знакомство с ML даёт существенное преимущество в виде моря идей и грамотного планирования экспериментов, а вычислительные ресурсы позволяют ещё и быстро все эти эксперименты воплощать в реальность. Однако, все это скорее дополнительные плюшки, а не необходимые условия. Для меня это соревнование было третьим серьезным ML-проектом, а в компьютерном зрении на тот момент я был вообще зелёнкой.
О суперкомпьютерных мощностях и речи быть не может — модели я обучал локально на обычной 2060 Super с 8 Гб видеопамяти.
Сам Kaggle абсолютно бесплатно предоставляет всем пользователям около 40 часов использования их собственных видеокарт. С недавним обновлением можно получить машины даже с двумя GPU, и существенно ускорить обучение. Квота обновляется еженедельно — учитывая, что соревнование длится 3 месяца, вы можете бесплатно использовать под 500 часов GPU за 0 рублей, чем я, конечно же, воспользовался.
Зато, будучи относительным новичком, я очень хотел разобраться в том, как именно работает современное компьютерное зрение на практике, а соревновательный дух подстегивает делать системы не просто хорошими, а лучшими.
Когда у вас ограничен бюджет, важно правильно выбирать свои битвы.
Некоторые соревнования реально требуют хороших видеокарт даже для минимального прогресса. Например, это относится к NLP, из-за необходимости обучать и тюнить огромные современные трансформеры, которые не всегда лезут даже в промышленные видеокарты. Другая часть соревнований может требовать большой объём оперативной памяти для подгрузки многомиллионных датасетов.
Нельзя не отметить то, что соревнования могут сильно затягивать в целом, и серьезное участие в них предполагает много потраченного времени. Это может быть отчасти оптимизированно за счет автоматизации пайплайнов экспериментов, однако у всех оптимизаций есть свой предел.
Мотивация, упорство и время — ваши важнейшие преимущества в любой деятельности.
Уникальное решение с первого места
Под конец поста хотелось бы дополнительно разобрать решение с первого места, которое, кроме очевидного фактора первенства, поражает своей простотой и элегантностью.
Сама идея крайне простая: в timm лежит огромное количество предобученных моделей (более 700 различных чекпоинтов, по идее), и использовать каждую из них можно просто указав название. Вместо того, чтобы долго тюнить отдельные модели, давайте прогоним вообще всё на датасете соревнования, соберем их эмбеддинги в единую табличку и обучим поверх нее регрессионную модель, которая и будет предсказывать рейтинг популярности питомца.
Слабое место данной идеи заключается в размерности: из-за того, что моделей очень много, размерность итоговой таблички будет очень большой и очень сильно перекошенной в сторону количества фичей: если считать, что средний размер эмбеддинга с последнего слоя равен 1000, то в конце получим табличку ~4000 семплов на ~700.000 фичей. Обучить хоть что-то полезное в таком формате будет невозможно. Решается этот момент отбором лучших моделей forward-процедурой: подобно отбору фичей в табличных задачах, только вместо отдельных колонок отбираются целые модели и их эмбеддинги.
Таким образом, автор решения отобрал 3 лучших набора моделей, примерно по 11 моделей в каждом. В качестве верхней модели был выбран SVM-регрессор с rbf-кернелом — по всей видимости, именно SVM оказался очень устойчив к огромному числу фичей итоговых таблиц, к тому же, он обучается очень быстро.
Hidden text
Итоговое решение с первого места для максимизации качества содержало ещё и тюненные нейронки, но, по словам автора, чисто часть с SVM уже попадала в золотую зону.
Заметим, что все модели прогоняются только один раз на всем датасете, после чего их эмбеддинги мы просто сохраняем. При этом, прогоняются они в режиме инференса, что на порядки быстрее трейна отдельных моделей.
В теории, данное решение может быть сделано даже без GPU — инференс моделей не зависит от батч-сайза, и может быть выполнен в приемлемое время на процессоре. И, естественно, оно точно выполнимо чисто на предоставляемом Kaggle железе. Это ещё один аргумент в копилку «железо не решает», хотя, конечно же, случай этого решения уникальный и очень редкий.
Но почему это в принципе работает?
Ведь всегда говорится, что под целевую задачу Deep Learning модели необходимо либо обучать с нуля, либо тюнить предобученные варианты. Работает это здесь потому, что данные из соревнования все жё близки к данным ImageNet, под который и были обучены все модели из timm. В частности, в имеджнете уже есть много разных картинок кошек и собак разных пород, и модели оказались хорошо знакомыми c их особенностями, выдавая полезные итоговые признаки. Более того, использование множества моделей в таком формате — один из вариантов ансамблирования, которое улучшает итоговое качество ещё больше.
Kaggle это интересно и даже полезно
Я много раз слышал мнение, что соревнования по ML и Kaggle — это некоторая странная активность, на которой люди занимаются бездумным подбором гиперпараметров до посинения.
На самом деле, такой подход приводит как раз к тем ситуациям, когда «упал на 800-е место с 8-го». Как было описано выше, чтобы получить действительно хорошее решение, требуется задумываться о физическом смысле самой задачи и много креативить. В этом контексте подборы циферок уходят на задний план.
Немного расскажу о самой механике наград. Занимая верхние места соревнований, вы получаете медали. Обычно, топ 10% соревнования — бронзовая медаль, топ 5% — серебро, а лучшие 10–15 (~топ 0.7%) участников получают золото. Для самых лучших решений есть и хорошие денежные призы.
 Kaggle регулярно проводит соревнования с призовыми больше 100 000 долларов, и призовых мест было всего 3. Большая часть людей соревнуется на Kaggle не из-за денег, а для улучшения навыков и развития портфолио.
Kaggle регулярно проводит соревнования с призовыми больше 100 000 долларов, и призовых мест было всего 3. Большая часть людей соревнуется на Kaggle не из-за денег, а для улучшения навыков и развития портфолио.
Разница между золотом и серебром колоссальна — это видно и по процентилям, и на практике, из-за очень сильных и соревновательных участников степени борьбы за золото и серебро отличаются на порядки.
Сами медали определяют ваше звание в соревновательной прогрессии.
Вы начинаете с Contributor.
Получение следующего звания Kaggle Competition Expert требует 2 бронзовые медали
Master — 2 серебряных и одну золотую.
А Grandmaster — это 5 золотых медалей. Причем одна из них должна быть обязательно получена в одиночку.
Золотая медаль, которую я получил на этом соревновании, стала очень важным шагом в достижении звания Мастера — одна серебряная у меня уже была, а получить второе серебро после золота дело техники (хотя и это оказалось непростым и удалось только со второй попытки).
Красивая строчка в резюме про Kaggle Competition Masterа стала личным PR-аргументом и помогла пройти на стажировку в Лабораторию машинного обучения Альфа-Банка.
Но самым главным призом оказались полученные навыки и знания, которые активно пригождаются и в рабочих задачах.
В Лаборатории мы улучшаем банковские бизнес процессы и клиентский сервис с помощью глубокого обучения. Знание современных техник позволяет решать задачи эффективно, а различные соревновательные идеи помогают ускорить обучение, максимизировать качество или решить возникшую нестандартную ситуацию. Узнать больше о работе нашей команды можно в Телеграм-канале Нескучный Data Science — кстати говоря, один раз и я писал туда пост.
Возможно, когда-нибудь я соберусь получать и Грандмастера, благо золотая в одиночку уже есть, но 4 других пока что выглядят как огромная эпопея. Из четырех соревнований, в которых я участвовал на Kaggle, получить золотую медаль удалось только один раз. Учитывая, что рядовое соревнование проходит в течение трех месяцев, для хороших результатов требуются сотни часов работы — при этом, получение именно золотых медалей далеко не гарантированно из-за множества факторов. Совмещать длинные соревнования с фуллтайм работой очень непросто — как по причине нехватки времени, так и из-за неизбежного разделения вашего внимания между рабочими и соревновательными задачами.
Рекомендуем почитать [подборка от редактора]
Также подписывайтесь на Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
