Как безопасно объединить сетевые сегменты трех крупных банков: делимся хитростями
Некоторое время назад под брендом ВТБ состоялось объединение трех крупных банков: ВТБ, экс-ВТБ24 и экс-Банка Москвы. Для внешних наблюдателей объединенный банк ВТБ сейчас работает как единое целое, но изнутри все выглядит гораздо сложнее. В этом посте мы расскажем о планах по созданию единой сети объединенного банка ВТБ, поделимся лайфхаками по организации взаимодействия файрволов, стыковке и объединению сетевых сегментов без прерывания сервисов.
Сложности взаимодействия разрозненных инфраструктур
Деятельность ВТБ на текущий момент обеспечивается тремя унаследованными инфраструктурами: экс-Банк Москвы, экс-ВТБ24 и сам ВТБ. Инфраструктуры каждого из них обладают своим набором сетевых периметров, на границе которых стоят средства защиты. Одно из условий для интеграции инфраструктур на уровне сети — это наличие согласованной структуры IP-адресации.
Сразу после объединения мы начали выравнивание адресных пространств, и оно сейчас уже подходит к завершению. Но процесс трудоемкий и небыстрый, а сроки по организации кросс-доступов между инфраструктурами стояли очень жесткие. Поэтому на первом этапе мы соединили инфраструктуры разных банков между собой в том виде, как они есть — через средства межсетевого экранирования по ряду основных зон безопасности. По такой схеме, чтобы организовать доступ из одного сетевого периметра в другой, необходимо прокладывать путь трафику через множество файрволов и других средств защиты, транслировать на стыках адреса ресурсов и пользователей с помощью технологий NAT и PAT. При этом все файрволы на стыках зарезервированы как локально, так и географически, и это приходится всегда учитывать при организации взаимодействий и выстраивании сервисных цепочек.
Такая схема вполне работоспособна, но оптимальной ее точно не назовешь. Здесь есть как технические проблемы, так и организационные. Нужно согласовывать и документировать взаимодействия множества систем, компоненты которых разбросаны по разным инфраструктурам и зонам безопасности. При этом в процессе трансформации инфраструктур необходимо быстро обновлять эту документацию по каждой системе. Ведение этого процесса сильно загружает наш самый ценный ресурс — высококвалифицированных специалистов.
Технические же проблемы выражаются в мультипликации трафика на линках, высокой загрузке средств защиты, сложности организации сетевых взаимодействий, невозможности создания некоторых взаимодействий без трансляции адресов.
Проблема мультипликации трафика возникает, в основном, из-за множества зон безопасности, взаимодействующих между собой через межсетевые экраны на разных сайтах. Независимо от географического местоположения самих серверов, если трафик выходит за периметр зоны безопасности, он пройдет через цепочку средств защиты, которые могут находиться в других локациях. Например, у нас есть два сервера в одном дата-центре, но один — в периметре ВТБ, а другой — в периметре сети экс-ВТБ24. Трафик между ними идет не напрямую, а проходит через 3–4 межсетевых экрана, которые могут быть активны в других дата-центрах, и трафик будет доставлен до файрвола и обратно несколько раз через магистральную сеть.
Для обеспечения высокой надежности каждый файрвол нам нужен в 3–4 экземплярах — два на одном сайте в виде HA-кластера и один или два файрвола на другом сайте, на которые трафик переключится при нарушении работы основного файрвольного кластера или сайта в целом.
Резюмируем. Три независимые сети — это целый ворох проблем: избыточная сложность, необходимость в дополнительном дорогостоящем оборудовании, узкие места, трудности резервирования и, как результат, высокие затраты на эксплуатацию инфраструктуры.
Общий подход к интеграции
Раз уж мы решили взяться за трансформацию сетевой архитектуры, то начнем с базовых вещей. Пойдем сверху вниз, начнем с анализа требований бизнеса, прикладников, системщиков, безопасников.
- Исходя из их потребностей, мы проектируем целевую структуру зон безопасности и принципы межсетевого взаимодействия между этими зонами.
- Эту структуру зон мы накладываем на географию наших основных потребителей — ЦОД и крупных офисов.
- Далее формируем транспортную MPLS-сеть.
- Под неё уже подводим первичную сеть, обеспечивающую услуги физического уровня.
- Выбираем локации размещения edge-модулей и модулей межсетевого экранирования.
- После того как целевая картина прояснится, прорабатываем и утверждаем методику миграции с существующей инфраструктуры на целевую — так, чтобы процесс был прозрачным для работающих систем.
Целевая концепция сети
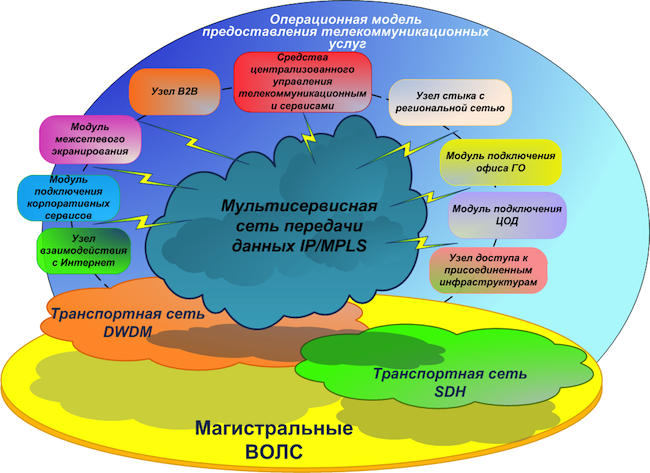
У нас будет первичная магистральная сеть — это транспортная телекоммуникационная инфраструктура на основе волоконно-оптических линий связи (ВОЛС), пассивного и активного каналообразующего оборудования. Также в ней может использоваться подсистема оптического уплотнения каналов xWDM и, возможно, SDH-сеть.
На базе первичной сети мы строим так называемую опорную сеть. Она будет иметь единый адресный план и единый набор протоколов маршрутизации. В опорную сеть входит:
- MPLS — мультисервисная сеть;
- DCI — линки между дата-центрами;
- EDGE-модули — различные модули подключения: межсетевого экранирования, партнерских организаций, интернет-каналов, ЦОД, ЛВС, региональной сети.
Мультисервисную сеть мы создаем по иерархическому принципу с выделением транзитных (P) и конечных (PE) узлов. В ходе предварительного анализа оборудования, имеющегося сегодня на рынке, стало ясно, что вынести уровень P-узлов на отдельное оборудование будет экономически более целесообразно, чем совмещать функционал P/PE в одном устройстве.
Мультисервисная сеть будет обладать высокой доступностью, отказоустойчивостью, минимальным временем сходимости, масштабируемостью, высокой производительностью и функциональностью, в частности поддержкой IPv6 и multicast.
В ходе построения магистральной сети мы намерены отказаться от проприетарных технологий (там, где это возможно без ухудшения качества), так как стремимся, чтобы решение было гибким и не завязанным на конкретного вендора. Но при этом не хотим создавать «винегрет» из оборудования различных вендоров. Наш основополагающий принцип проектирования — предоставлять максимальное количество сервисов при использовании оборудования, минимально достаточного для этого количества вендоров. Это позволит в том числе организовать сопровождение сетевой инфраструктуры, задействуя ограниченное количество персонала. Также важно, чтобы новое оборудование было совместимо с существующим оборудованием для обеспечения процесса бесшовной миграции.
Структуру зон безопасности сетей ВТБ, экс-ВТБ24 и экс-Банка Москвы в рамках проекта планируется полностью переработать с целью объединения функционально дублирующихся сегментов. Планируется единая структура зон безопасности с общими правилами маршрутизации и единой концепцией межсетевых доступов. Межсетевое экранирование между зонами безопасности планируем осуществлять при помощи отдельных аппаратных файрволов, разнесенных по двум основным локациям. Также все edge-модули планируем реализовать независимо на двух разных площадках с автоматическим резервированием между ними на основе стандартизованных протоколов динамической маршрутизации.
Управление оборудованием опорной сети мы организуем через отдельную физическую сеть (out-of-band). Административный доступ ко всему сетевому оборудованию будет осуществляться через единый сервис аутентификации, авторизации и аккаунтинга (AAA).
Для оперативного поиска проблем в сети очень важно иметь возможность скопировать трафик из какой-либо точки сети для анализа и доставить его до анализатора по независимому каналу связи. Для этого мы создадим изолированную сеть для SPAN-трафика, с помощью которой будем собирать, фильтровать и передавать потоки трафика на сервера аналитики.
Для стандартизации предоставляемых сетью услуг и возможности аллокации расходов введем единый каталог с показателями SLA. Мы переходим к сервисной модели, в которой учитываем взаимосвязь сетевой инфраструктуры с прикладными задачами, взаимосвязь элементов управляющих приложений, их влияние на сервисы. И эта сервисная модель поддерживается системой мониторинга сети, чтобы мы могли правильно аллоцировать расходы на IT.
От теории к практике
Теперь спустимся на уровень ниже и расскажем о наиболее интересных решениях в нашей новой инфраструктуре, которые могут быть полезны и вам.
Ресурсный лес: подробности
С ресурсным лесом ВТБ мы хабровчан уже знакомили. Теперь попробуем дать более подробное техническое описание.
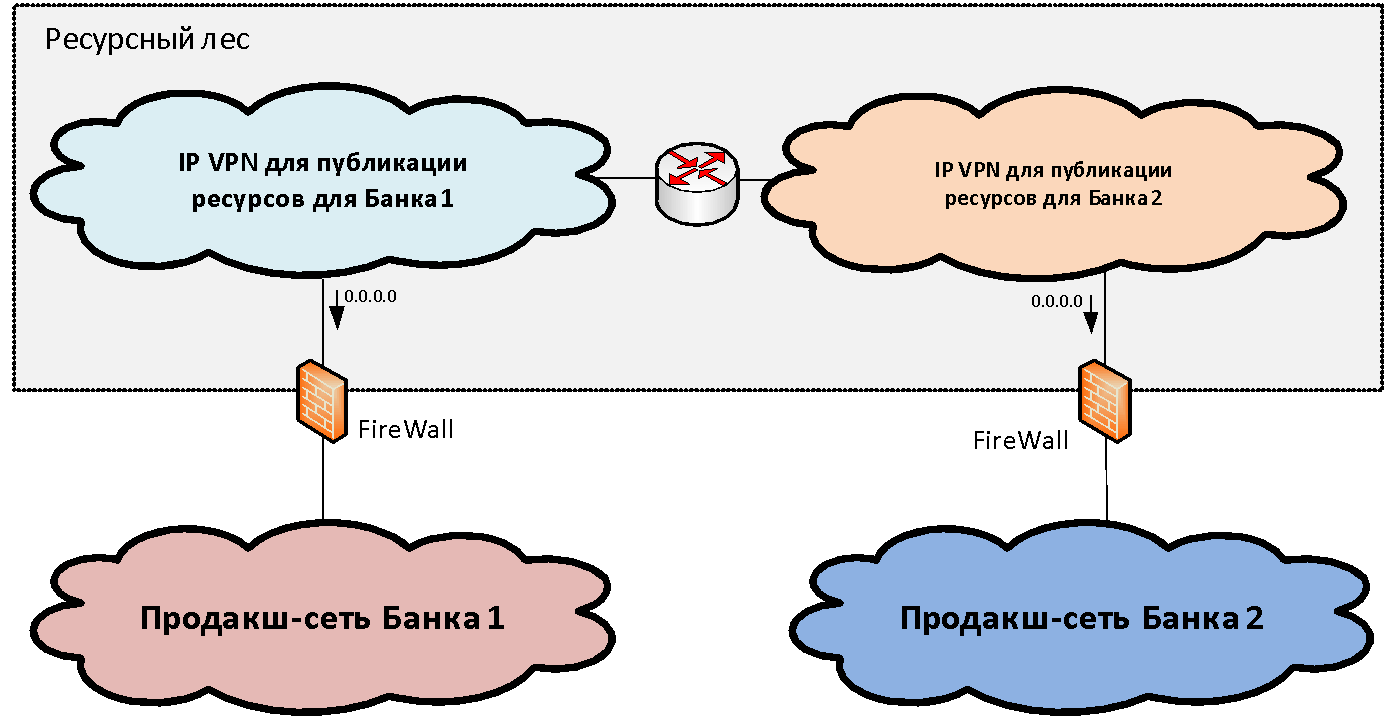
Предположим, у нас есть две (для простоты) сетевых инфраструктуры разных организаций, которые требуется объединить. Внутри каждой инфраструктуры, как правило, среди набора функциональных сетевых сегментов (зон безопасности) можно выделить основной продуктивный сетевой сегмент, где размещены основные промышленные системы. Мы подключаем эти продуктивные зоны к определенной структуре шлюзовых сегментов, которую мы называем «ресурсный лес». В данных шлюзовых сегментах публикуются общие ресурсы доступные из двух инфраструктур.
Концепция ресурсного леса, с сетевой точки зрения, заключается в создании шлюзовой зоны безопасности, состоящей из двух IP VPN (для случая двух банков). Эти IP VPN свободно маршрутизируются между собой и связаны через файрволы с продуктивными сегментами. IP-адресация для этих сегментов выбирается из непересекающегося диапазона IP-адресов. Таким образом маршрутизация в сторону ресурсного леса становится возможна из сетей обоих организаций.
А вот с маршрутизацией из ресурсного леса в сторону промышленных сегментов дело обстоит несколько хуже, так как адресация в них зачастую пересекается и единую таблицу сформировать невозможно. Для решения этой задачи нам как раз и нужно два сегмента в ресурсном лесу. В каждом из сегментов ресурсного леса написан дефолт-маршрут в сторону промышленной сети «своей» организации. То есть пользователи могут получать доступ без трансляции адресов в «свой» сегмент ресурсного леса и в другой сегмент через PAT.
Таким образом, два сегмента ресурсного леса представляют собой единую шлюзовую зону безопасности, если проводить границу по файрволам. В каждом из них своя маршрутизация: default gateway смотрит в сторону «своего» банка. Если мы размещаем ресурс в каком-то сегменте ресурсного леса, то пользователи соответствующего банка могут взаимодействовать с ним без NAT.
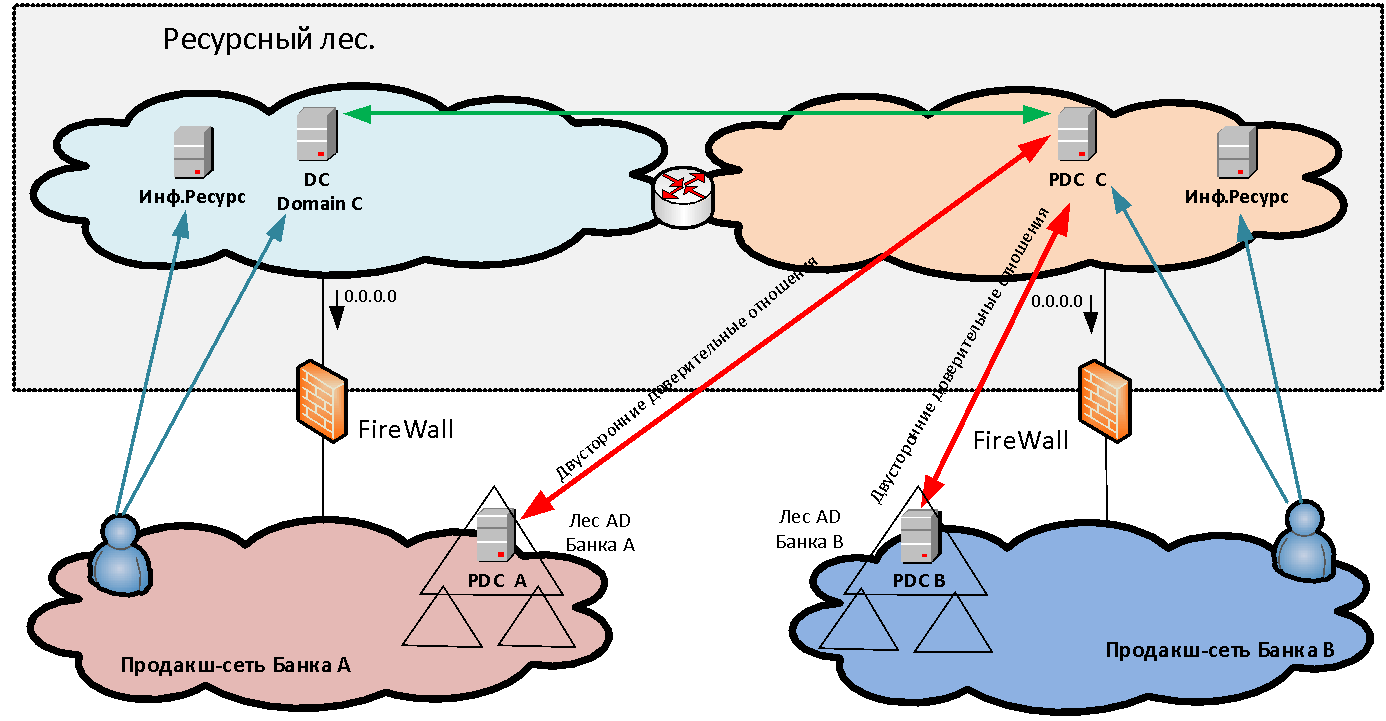
Взаимодействие без NAT очень важно для многих систем и, в первую очередь, для доменных взаимодействий Microsoft — ведь в ресурсном лесу у нас располагаются сервера Active Directory для нового общего домена, трасты с которым устанавливаются со стороны обеих организаций. Также безNAT-взаимодействия требуют такие системы, как Skype for Business, АБС «MBANK» и множество других разнообразных приложений, где от сервера идет обратное обращение на адрес клиента. И если клиент находится за PAT, обратное соединение уже не установится.
Сервера, которые мы устанавливаем в сегментах ресурсного леса, делятся на две категории: инфраструктурные (например, сервера MS AD) и предоставляющие доступ к каким-либо информационным системам. Последний тип серверов мы называем «Витрины данных». Витрины — это, как правило, web-сервера, бэкэнд которых уже находится за файрволом в продакшн-сети организации, создавшей данную «витрину» в ресурсном лесу.
А как осуществляется аутентификация пользователей при доступе к опубликованным ресурсам? Если мы просто предоставляем доступ к каким-либо приложениям для одного-двух пользователей в другом домене, то можем завести для них в нашем домене отдельные учетные записи для аутентификации. Но когда мы говорим о массовом слиянии инфраструктур — скажем, 50 тысяч пользователей — заводить и сопровождать для них отдельные перекрестные учетки совершенно нереально. Создание непосредственных трастов между лесами разных организаций также не всегда возможно как по соображениям безопасности, так и из-за необходимости делать PAT пользователей в условиях пересекающихся адресных пространств. Поэтому для решения задачи единой аутентификации пользователей в периметре ресурсного леса создается новый лес MS AD, состоящий из одного домена. В этом новом домене пользователи аутентифицируются при доступе к сервисам. Чтобы это было возможно, организовываются двусторонние доверительные отношения уровня леса между новым лесом и доменными лесами каждой организации. Таким образом, пользователь любой из организаций может аутентифицироваться на любом опубликованном ресурсе.
Начинаем интеграцию сетей
После того, как мы наладили взаимодействие систем через инфраструктуру ресурсного леса и тем самым сняли острые симптомы, пришло время заняться непосредственным объединением сетей.
Для этого мы на первом этапе сделали подключение продуктовых сегментов трех банков к единому мощному файрволу (логически единому, но физически многократно зарезервированному на разных сайтах). Файрвол обеспечивает непосредственное взаимодействие между системами разных банков.
С экс-ВТБ24 мы до организации каких-либо прямых взаимодействий между системами уже успели выровнять адресные пространства. Сформировав таблицы маршрутизации на файрволе и открыв соответствующие доступы, мы смогли обеспечить взаимодействие между системами в двух разных инфраструктурах.
С экс-Банком Москвы адресные пространства на момент организации прикладных взаимодействий еще не были выровнены, и для организации взаимодействия систем мы были вынуждены использовать взаимный NAT. Использование NAT породило ряд проблем с DNS-резолвом, которые были решены ведением дублирующихся зон DNS. Кроме того, из-за NAT возникли трудности с работой ряда прикладных систем. Сейчас мы почти устранили пересечения адресных пространств, но столкнулись с тем, что множество систем ВТБ и экс-Банка Москвы оказались плотно завязаны между собой на взаимодействие по транслированным адресам. Теперь нам нужно мигрировать эти взаимодействия на реальные IP-адреса, сохранив непрерывность бизнеса.
Упразднение NAT
Здесь наша цель — обеспечение работы систем в едином адресном пространстве для проведения дальнейших интеграций как инфраструктурных сервисов (MS AD, DNS), так и прикладных (Skype for Business, MBANK). К сожалению, поскольку часть прикладных систем уже завязана между собой по транслированным адресам, требуется индивидуальная работа с каждой прикладной системой по ликвидации NAT для конкретных взаимодействий.
Иногда можно пойти на такой трюк: выставить один и тот же сервер одновременно и под транслированным адресом, и под реальным. Так прикладные администраторы могут протестировать работу по реальному адресу перед миграцией, самостоятельно попробовать перейти на безNAT-взаимодействие и в случае чего откатиться. При этом мы на файрволе с помощью функции захвата пакетов отслеживаем, общается ли кто-нибудь с сервером через транслированный адрес. Как только такое общение прекращается, мы по согласованию с владельцем ресурса трансляцию прекращаем: у сервера остается только реальный адрес.
После разбора NAT, к сожалению, еще некоторое время придется сохранять файрволинг между функционально идентичными сегментами, потому что не все зоны соответствуют единым стандартам безопасности. После стандартизации сегментов файрволинг между сегментами заменяется на маршрутизацию и функционально одинаковые зоны безопасности сливаются воедино.
Межсетевой файрволинг
Перейдем к проблеме межсетевого файрволинга. В принципе, она актуальна для любой крупной организации, в которой нужно обеспечить и локальную, и глобальную отказоустойчивость средств защиты.
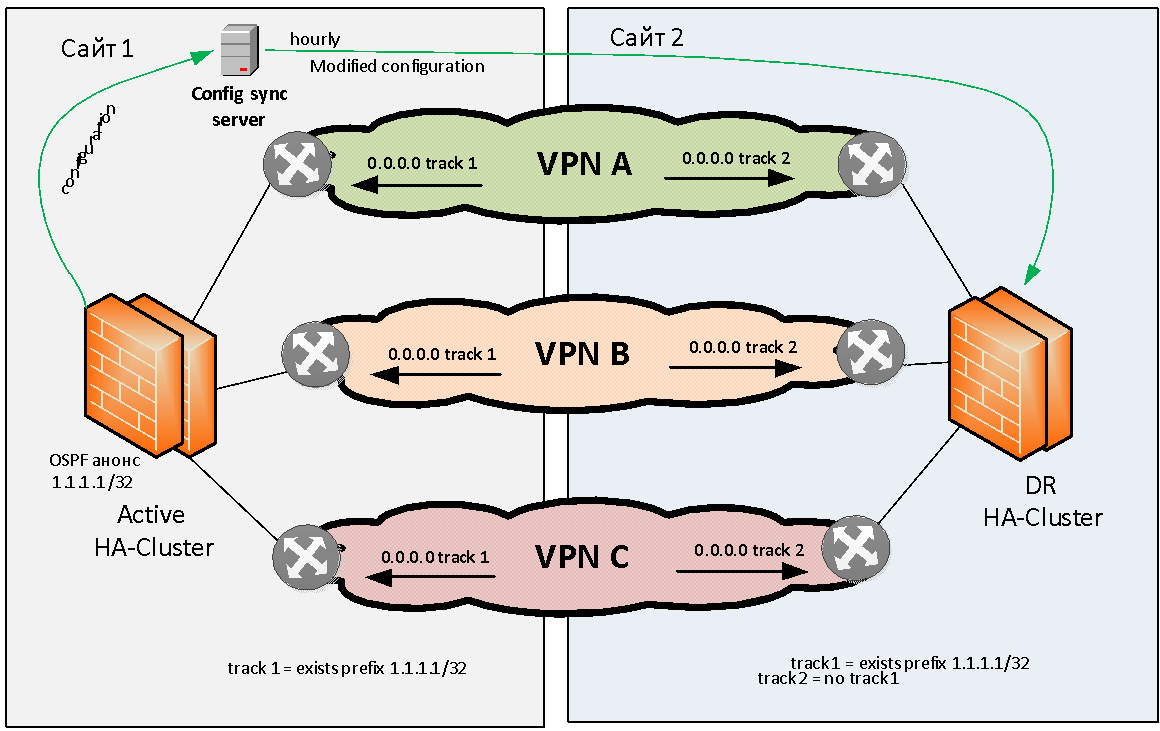
Попробуем сформулировать проблему резервирования файрволов в общем. У нас есть два сайта: сайт 1 и сайт 2. Есть несколько (например, три) MPLS IP VPN, взаимодействующие между собой через stateful файрвол. Требуется этот файрвол зарезервировать локально и географически.
Проблему локального резервирования файрволов мы рассматривать не будем, почти любой производитель предоставляет возможность собрать файрволы в локальный HA-кластер. Что касается географического резервирования файрволов, практически ни у одного вендора эта задача «из коробки» не решена.
Конечно, можно «растянуть» по L2 файрвольный кластер на несколько сайтов, но тогда этот кластер будет представлять собой единую точку отказа и надежность нашего решения будет не очень высокой. Потому что кластеры иногда зависают целиком из-за ошибок ПО, либо впадают в состояние split brain из-за обрыва L2-линка между площадками. Из-за этого от растягивания файрвольных кластеров по L2 мы сразу отказались.
Нам нужно было придумать схему, в которой при выходе из строя файрвольного модуля на одном сайте происходил бы автоматический переход на другую площадку. Вот как мы это сделали.
Решено было придерживаться модели георезервирования Active/Standby, когда активный кластер у нас находится на одной площадке. В противном случае мы сразу сталкиваемся с проблемами ассиметричной маршрутизации, которая трудно решается при большом количестве L3 VPN.
Активный файрвольный кластер как-то должен сигнализировать о своей корректной работе. В качестве метода сигнализации мы выбрали анонсирование по OSPF с файрвола в сеть тестового (флагового) маршрута с маской /32. Сетевое оборудование на сайте 1 отслеживает наличие данного маршрута от файрвола и при его наличии активизирует статическую маршрутизацию (например, 0.0.0.0 /0), в сторону данного файрвольного кластера. Этот статический дефолт-маршрут далее помещается (через редистрибьюцию) в таблицу протокола MP BGP и распространяется по всей магистральной сети. Когда основной файрвольный кластер живой, он исправно вещает по OSPF флаговый маршрут, роутеры следят за ним, вся маршрутизация обращена именно к этому файрволу и весь трафик стекается на него по всем IP VPN.
На резервном сайте также отслеживается наличие флагового маршрута, но статическая маршрутизация в сторону резервного файрвольного кластера настроена инверсно, то есть трафик направляется на резервный файрвол не при наличии, а при отсутствии флагового маршрута с основного сайта.
Если с файрволом на сайте 1 что-то случается, то флаговый маршрут пропадает, роутеры на сайте 1 удаляют соответствующие маршруты из таблицы маршрутизации, а роутеры на сайте 2 наоборот — поднимают статические маршруты в сторону резервного файрвола. И через некоторое время, зависящее от сходимости протоколов, весь обмен трафика между VPN«ами переходит на другой сайт. Например, если один сайт оказывается обесточен, дефолтные маршруты автоматически меняются так, чтобы задействовать файрвол на рабочем сайте.
Как мы описали выше, файрвольные кластеры у нас зарезервированы на между сайтами по схеме active/standby. Все изменения вносятся только в active-файрвол. Для синхронизации настроек между основной и резервной площадками у нас используется отдельный сервер, на котором работает самописный софт. Софт забирает настройки, удаляет из них специфичные для конкретной площадки параметры конфигурации (например, IP-адреса интерфейсов и таблицы маршрутизации). А затем загружает обработанную конфигурацию в файрволы на других сайтах. Эта процедура проводится автоматически с определенной частотой. Такая схема работы файрволов позволяет добиться полной независимости площадок.
Многие производители давно обещают создать географически разнесенный L3 файрвол, но полностью удовлетворяющего нас решения пока мы не встречали. Пришлось сделать его самостоятельно.
Одноногий файрвол
Иногда нужно организовать межсетевое экранирование между множеством однотипных зон безопасности. Например, их может быть несколько десятков, а то и больше — в случае, скажем, использования тестовых сред. Если на каждую такую зону безопасности на файрволе выделять отдельный L3-интерфейс, то инфраструктура будет не очень гибкой и плохо масштабируемой.
Для таких случаев мы используем отдельное решение для организации сервисной цепочки через файрвол, в котором файрвол подключен в сеть всего одним IP-интерфейсом. Для подачи трафика на этот файрвол мы используем частично связанные MPLS VPN. У нас есть один MPLS VPN «IN» и один VPN «OUT». Оба этих VPN являются хабами в топологии HUB-and-spoke VPN. В качестве Spoke у этих HUB«ов выступает один и тот же набор VPN, между которыми и нужно отфильтровать трафик.
Хаб «IN» только экспортирует дефолт-маршрут в подключенные к нему Spoke VPN«ы и не импортирует никаких маршрутов из других VPN. Хаб «OUT» только импортирует маршруты из подключенных к нему Spoke VPN«ы и не экспортирует ничего.
Файрвол включен своим единственным интерфейсом в MPLS VPN «IN». Дефолт в этом VPN смотрит в сторону файрвола. Таким образом весь трафик стекается по дефолту из множества VPN в HUB-VPN «IN» и направляется на файрвол. На файрволе осуществляется фильтрация трафика в соответствии с глобальными политиками. Далее файрвол отдает отфильтрованный трафик обратно в тот же единственный интерфейс, на котором возвратный трафик перехватывается политиками Policy Based Routing. Они помещают этот трафик в VPN «OUT», откуда он уже растекается в соответствии с полной таблицей маршрутизации VPN «OUT» в нужные Spoke-VPN.
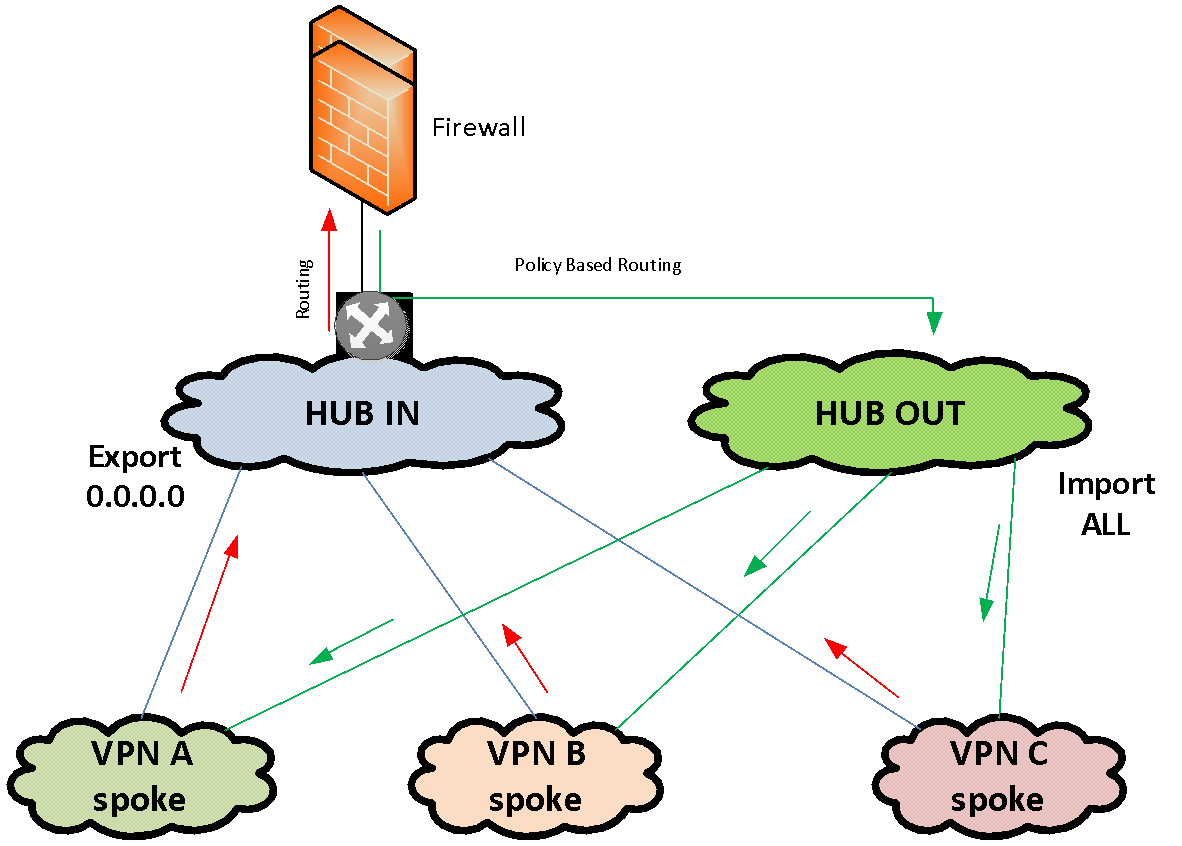
Эта схема позволяет быстро объединять большое число VPN, которые работают через один файрвол. Фактически для подключения сегмента к файрволу достаточно только добавить записи MPLS import / export в соответствующие HUB VPN.
В классической же схеме каждый VPN подключается к файрволу отдельным интерфейсом, что с учетом многократного дублирования файрволов реализуется не быстро — приходится выделять адресацию для связных сетей, нумерацию VLAN, обеспечивать маршрутизацию и т.д.
Заключение
На настоящий момент мы обеспечили возможность взаимодействия систем трех объединенных банков, связав сети по их периметрам, но временная схема получилась не оптимальной с точки зрения эксплуатации. Проект объединения сетей только начинается, и в ходе него мы надеемся построить оптимальную инфраструктуру, эффективную как с точки зрения капитальных затрат, так и с точки зрения эксплуатации. В следующих постах мы постараемся рассказать о других интересных решениях.
