Как я создаю себе колоды Anki для немецких слов
Я захотел продолжить некогда заброшенное изучение немецкого языка. Долгое время на просторах интернета слышал мнение, что карточки Anki — чуть ли не самый лучший способ изучение языка, и решил, собственно, посмотреть что к чему. Рекомендации YouTube привели меня к интересному видео, где автор рассказывает о своем шаблоне карточек с немецкими словами. Автор не желал публиковать свою колоду, и не найдя аналогов среди публичных колод, я принялся делать свое. Конечно же не вручную.
Что я хотел получить
Я решил ориентироваться на набор слов от института Гёте, у него такие наборы разделены по уровням изучения языка — A1, A2, B1 и далее. Вы легко их найдете по ключевым словам «goethe wortliste». На каждый уровень я планирую создать по колоде, в которой помимо этих слов будут еще и некоторые фразы для повседневного разговора или устоявшееся выражения, которые мне интересны. На странице с публичными колодами есть множество вариантов со словом «Goethe» в названии, очень неплохой есть с переводом с немецкого на английский, но вот для русскоговорящих я не нашел решения, отвечающего моим запросам качества.
То, что я хотел получить, во многом взято у автора видео, упомянутого выше, с некоторыми изменениями. Мои требования к карточкам можно сформировать так:
карточка с существительными помимо слова должна содержать артикль и множественное число
артикль у существительных должен выделятся цветом в зависимости от рода
во множественном числе у существительных должны быть выделены жирным буквы, отличающиеся от единственного числа
карточка с глаголом должна содержать также иные формы глагола
карточка с прилагательным должна содержать также остальные сравнительные формы прилагательного
в каждой карточке должен быть пример использования слова
в карточке должно быть встроено аудио с произношением немецкого слова и предложения с его примером.
Первым делом, как программист, использующий преимущественно Python в своей работе и проектах, я пошел искать, а нет ли уже готовых инструментов. Сразу же нашел пакет kerrickstaley/genanki, но решил им не пользоваться, так как мои задачи были достижимы пакетом ankitects/anki, который используется как бекэнд самой программой Anki.
Немного про неправильный подход
Я слукавлю если не скажу, что к использованию ankitects/anki я пришел не сразу. Стоит оговорится о том, как Anki хранит данные колоды. Под капотом используется база данных SQLite, более-менее подробное описание структуры которой я нашел здесь. Сразу скажу, что схема уже устарела, и колоды, созданные более новыми версиями Anki, выглядят иначе. Сама БД довольная сложна для понимания — имена колонок здесь редко длиннее 3 символов, какие-то данные хранятся в виде строк, какие-то в списке JSON в одной строке. В общем, работать с ней напрямую — то еще удовольствие, хотя kerrickstaley/genanki использует такой подход, что я понял из беглого чтения кода, вот, например, тут хранятся SQL запросы для инициализации пустой БД.
Мое первое решение мне представлялось примерно таким:
создать пустую SQLite базу данных по структуре, которую использует Anki
создать модели карточек под разные части речи и шаблоны для них используя
dataclassнаполнить БД контентом через «ручную» сериализацию
dataclassв JSON, в котором хранятся карточки.
Такой подход очень быстро привел меня в тупик. Я попытался вручную повторить БД по примеру скачанной колоды автора видео и был удивлен — почему мою, казалось бы такую же колоду не хочет «жевать» программа Anki? Вопросы возникали много где, чего стоили идентификаторы — во многих местах Anki использует в качестве идентификаторов timestamp в миллисекундах. Понятно дело, что модели карточек и слова у меня создавались быстрее чем 1 штука в миллисекунду и возникали коллизии. Я молчу и про уникальные идентификаторы, которые Anki использует для глобальной синхронизации объектов. Их создание решает genanki, но выглядит это довольно странно.
Не стоит забывать и про изменение структуры БД, о котором я говорил ранее. Оказалось, что создаваемые мной таблицы были устаревшими — при просмотре структуры свежесозданной и экспротированной колоды я находил много изменений ровно в тех местах, где еще вчера задавал вопросы «почему так странно сделали то?».
Гораздо более правильным и логичным решением стало создание и экспорт пустой колоды из Anki, а затем редактирование ее пакетом ankitects/anki от разработчиков. Так получалось, что пустую колоду я создавал последней версией программы и работал с ней также новейшей версией библиотеки, что сводило вероятность ошибок совместимости к минимуму. Позже также обнаружил, что разработчики сами в своей документации предостерегают от прямой записи в БД в обход их инструментов:
You should prefer these methods over directly accessing the database, as they take care of marking items as requiring a sync, and they prevent some forms of invalid data from being written to the database.
Документация к пакету, к слову, довольна скудная, либо полной ее версии я не нашел. Разобрался в работе модуля через код, об интересных моментах расскажу далее. Не знаю, правилен ли мой подход с использованием библиотеки для создания карточек, все-таки в документации он подается как инструмент для создания аддонов. Но, учитывая, что используемый инструмент решал поставленные мной задачи, вопросом его задуманного применения я более не задавался.
Терминология
Ранее по тексту я уже упоминал слово «модель». Anki использует свои термины для компонентов, думаю будет не лишним рассказать о них, к тому же, я даже застал их изменение, изучая более старые колоды.
Заполняя поля карточки в программе, мы работаем с моделью, что в коде раньше именовалась как Model, но, видимо, из-за широкого использования термина сейчас именуется как NoteType (дословно — тип заметки). Каждая модель имеет набор полей (Field), это, например, артикль, слово, перевод и пример. Поля могут быть разных типов, не только текстовые. Звуковые поля я уже упоминал, не редко использование также и полей с картинками.
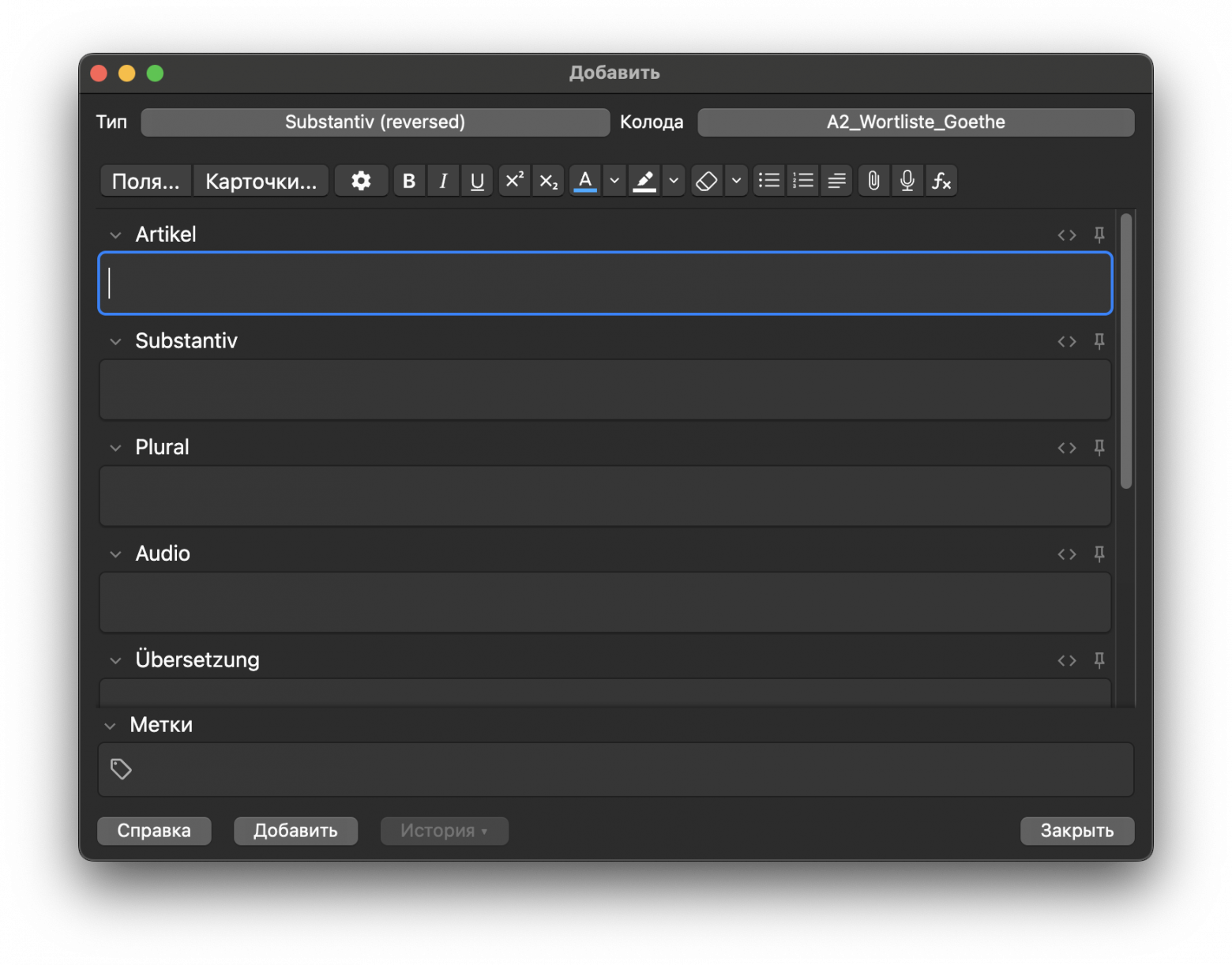
Заполнение полей модели в интерфейсе Anki
У каждой модели есть один или несколько шаблонов (Template). Шаблоны используются для представления одной карточки в разных видах, например, первый вид представляет собой слово на немецком и ответ на русском, второй — слово на русском и ответ на немецком, а третий — слово на русском с полем для ввода ответа на немецком, к слову, именно такие шаблоны я и использовал в большинстве моделей.

Шаблон оборота карточки с предпросмотром
Заметка или Note это сами слова. То есть данные, которыми наполняются поля модели (NoteType). Поля могут быть заполнены не все. Очевидно, что модель может быть использована множеством заметок, но одна заметка всегда принадлежит одной модели.
Под словом «карточка» я подразумеваю конечный продукт, который получается при наложении данных заметки на модель и отображении ее в виде одного из шаблонов.

Пример готовой карточки
Все вышеописанное принадлежит колоде (Deck), думаю, это и так понятно. Есть также термин коллекция (Collection), она может содержать несколько колод с медиа материалами для них — это то, что эскпортирует программа Anki. Файл .apkg есть ничто иное как переименованный .zip архив, можете смело вернуть ему его расширение и распаковать. Внутри найдете файл .anki2, это уже как раз база данных SQLite, можете также открыть ее соответствующей программой.
Используемые модели
Для достижения поставленных задач, мне было мало одной модели «слово», но и создавать модель под каждую часть речи мне тоже не хотелось. Я остановился на чем-то среднем. Выделим основные поля, которые будут в каждой модели:
слово (существительное, глагол, прилагательное…)
перевод
аудио слова
пример
перевод примера
аудио примера.
Существительное (Substantiv) имеет дополнительно поля для артикля и множественного числа. Также аудио слова создается в формате »{артикль} {существительное}, die {мн. форма}». Приведу код создания модели существительного. Код создания остальных моделей мало отличается, потому не буду приводить его в статье, но поделюсь репозиторием в конце.
from anki.models import ModelManager, NotetypeDict
def create_noun_notetype(manager: ModelManager) -> NotetypeDict:
"""Creates notetype (model) for noun with templates"""
noun = manager.new(name="Substantiv (reversed)")
# Notes will be sorted by second field (Substantiv)
noun["sortf"] = 1
# Adding card fields
manager.add_field(notetype=noun, field=manager.new_field("Artikel"))
manager.add_field(notetype=noun, field=manager.new_field("Substantiv"))
manager.add_field(notetype=noun, field=manager.new_field("Plural"))
manager.add_field(notetype=noun, field=manager.new_field("Audio"))
manager.add_field(notetype=noun, field=manager.new_field("Übersetzung"))
manager.add_field(notetype=noun, field=manager.new_field("Beispiel"))
manager.add_field(notetype=noun, field=manager.new_field("Audio des Beispiels"))
manager.add_field(
notetype=noun, field=manager.new_field("Übersetzung des Beispiels")
)
manager.add_field(notetype=noun, field=manager.new_field("Kommentar"))
# Adding card templates
card_1 = manager.new_template(name="de -> ru")
card_1["qfmt"] = "{{Artikel}} {{Substantiv}}
{{Plural}}
{{Audio}}"
card_1["afmt"] = (
"{{FrontSide}}
"
"{{Übersetzung}}
"
"{{Beispiel}}
"
"{{Übersetzung des Beispiels}}
"
"{{Audio des Beispiels}}
"
"{{Kommentar}}"
)
card_2 = manager.new_template(name="ru -> de")
card_2["qfmt"] = "{{Übersetzung}}"
card_2["afmt"] = (
"{{FrontSide}}
"
"{{Artikel}} {{Substantiv}}
"
"{{Plural}}
"
"{{Audio}}
"
"{{Beispiel}}
"
"{{Übersetzung des Beispiels}}
"
"{{Audio des Beispiels}}
"
"{{Kommentar}}"
)
card_3 = manager.new_template(name="ru -> de (with typing)")
card_3["qfmt"] = "{{Übersetzung}}
{{type:Substantiv}}"
card_3["afmt"] = (
"{{FrontSide}}
"
"{{Artikel}} {{Substantiv}}
"
"{{Plural}}
"
"{{Audio}}
"
"{{Beispiel}}
"
"{{Übersetzung des Beispiels}}
"
"{{Audio des Beispiels}}
"
"{{Kommentar}}"
)
manager.add_template(notetype=noun, template=card_1)
manager.add_template(notetype=noun, template=card_2)
manager.add_template(notetype=noun, template=card_3)
manager.save(notetype=noun)
return nounЗдесь qfmt и afmt ничто иное как «question format» и «answer format», в них мы размечаем внешний вид итоговой карточки. В {{}} вставляется название ранее созданного поля модели, а
Глагол (Verb) имеет дополнительно поле для иных форм глагола. Аудио слова создается в формате »{глагол}, {остальные формы глагола}». В качестве остальных форм я подразумеваю инфинитив, третья форма, Perfekt, например anklicken, klickt an, hat angeklickt. Наверное, можно еще добавить Präteritum.
Прилагательное (Adjektiv) имеет дополнительно поле для сравнительных степеней. Аудио слова создается в формате »{прилагательное}, {остальные сравнительные формы прилагательного}».
Слово (Wort) — модель, которая не имеет дополнительных полей. Она будет использоваться для предлогов, местоимений, частиц и других слов, дополнительные формы которых либо отсутствуют, либо не существенны в рамках такого формата обучения.
Фраза (Phrase) имеет только поля для фразы и ее перевода. Этой моделью будут представлены заметки с разговорными фразами или устоявшимися выражениями, поговорками.
Озвучивание слов
Над этим моментом много кто предпочитает не заморачиваться, так как существует аддон (дополнение) AwesomeTTS к Anki, которое генерирует звук произношения текста прямо во время просмотра карточки. Позже я узнал, что это дополнение может также сохранять созданный звук в карточку, но мне оно не было интересно, потому что я нуждался в программном доступе до функционала синтеза текста и максимально правильном произношении, насколько это возможно без реального диктора.
В поисках решения я вышел на OpenAI, давно слышал об их API для синтеза текста или text-to-speech, иными словами. Я попробовал сгенерировать аудио произношения нескольких слов через их API и выделил несколько минусов, которые заставили меня отказаться от их решения:
нет возможности выбрать язык, он понимается моделью самостоятельно;
нет возможности управлять дикцией через разметку текста, например, нельзя обозначить паузу.
На первый взгляд, полученный результат был неплохим. Немецкое произношение было приемлемо, за исключением случаев синтеза коротких слов, написание которых схоже с таковым в английском или иных языках, понимаемых моделью. А с разметкой было совсем плохо. Я хотел отделить произношение слова от произношения иных его форм, чтобы они не формировали однотонную фразу, но сделать это было нельзя.
Мои дальнейшие поиски привели меня к Яндексу, в котором нашлось все и даже Yandex SpeechKit, который имеет множество инструментов для озвучки (синтеза) текста или наоборот, его распознавания. Я был поражен качеством произношения, по сравнению с сэмплами от OpenAI. Также технология Яндекса позволяет указывать язык и использовать TTS разметку текста, что позволяло обозначать паузы, ударения или даже разложить слово на фонемы. Еще и заплатить можно было родной валютой, и кажется даже дешевле чем за решения от создателей chatGPT.
Воспользоваться технологией можно через пакет yandex-speechkit, в документации описан пример синтеза текста. Отмечу только, что у меня на MacBook с процессором Apple серии M возникли проблемы со сборкой grpcio, который является зависимостью yandex-speechkit и указан с версией <=1.46.3, в которой проблемы сборки еще не были исправлены. Проблема решилась использованием более ранней версией Python, я остановился на 3.9.
Подготовка данных
Понятно дело, полностью автоматизировать все до степени «загрузил PDF со словами — получил колоду для изучения» не получится, и придется все таки немного поработать руками и подготовить слова. Я выбрал формат .csv, так как его очень просто читать построчно без полного помещения в память, например, файлы .json или .xls таким преимуществом не обладают, хотя были бы более удобны для заполнения данными. Тем не менее, можно смело использовать Excel для редактирования файла со словами, позже экспортируя данные в .csv.
Однако, необычно использовать .csv файл для хранения неоднородных данных. Как правило, в таком формате одна колонка содержит данные одного типа на протяжении всего файла. Я же использую разные модели для разных частей речи, потому файл будет слегка неконсистентный.

Пример csv файла со словами
Я не нашел ничего лучше чем в первой колонке обозначать модель, поля которой следуют дальше в строке. Вот, например, строка с полями модели Substantiv (существительное) начинается со слова «noun», модель Verb (глагол) — со слова «verb» и так далее. Строка содержит все текстовые поля модели, вместе с переводом. Я не стал делать автоматический перевод, потому что считаю это неприемлемым в данном случае. Я хочу учить слова с полной уверенностью в их переводе.
Алгоритм работы
Скрипт начинается с инициализации пакета yandex-speechkit, для пользования технологией необходима авторизация на основе API ключа, подробнее об этом в документации. Далее открывается коллекция. Как я уже упоминал, новая колода создается внутри экспортированной пустой коллекции из программы Anki.
from anki.collection import Collection
from speechkit import configure_credentials, creds
from config import YANDEX_KEY
configure_credentials(
yandex_credentials=creds.YandexCredentials(api_key=YANDEX_KEY)
)
# Openning collection and cleaning it
collection = Collection("path_to_collection.anki2")
_clean_deck(collection=collection)Далее вызываю метод очистки коллекции. Да, в ней нет карточек, но могут быть модели и пустая колода, которые создаются по умолчанию. Удалим их, чтобы они затем не повторялись при импорте обратно в программу.
from anki.collection import Collection
def _clean_deck(collection: Collection) -> None:
# Removing all models (notetypes)
collection.models.remove_all_notetypes()
# Removing all decks
deck_ids = (i["id"] for i in collection.decks.all())
collection.decks.remove(deck_ids)Создадим новую колоду и модели. Функции создания модели существительного с шаблонами я уже показывал ранее, тут вызывается создание остальных моделей.
# Creating new deck
deck = collection.decks.add_normal_deck_with_name(name="your_deck_name")
deck = collection.decks.get(did=deck.id)
# Creating models (note types)
noun_model = create_noun_notetype(manager=collection.models)
verb_model = create_verb_notetype(manager=collection.models)
adjective_model = create_adjective_notetype(manager=collection.models)
word_model = create_word_notetype(manager=collection.models)
phrase_model = create_phrase_notetype(manager=collection.models)Начнем чтение .csv файла со словами и сборку заметки по входящим данным.
with open("path_to_words.csv") as words_csv:
file_reader = reader(words_csv, delimiter=";")
for row in file_reader:
if len(row) <= 1:
continue
elif row[0] == "noun":
note = build_noun_note(
collection=collection,
model=noun_model,
row=row,
)
...Далее в зависимости от первого слова файла вызываются разные функции сборки заметок. Самая сложная заметка для существительного, в ней больше всего логики. Рассмотрим ее для примера.
from typing import Sequence, Union
from anki.collection import Collection
from anki.models import NotetypeDict
from config import AUDIO_DIR, DEFAULT_EXAMPLE_AUDIO_SPEED, DEFAULT_WORD_AUDIO_SPEED
def build_noun_note(
collection: Collection,
model: NotetypeDict,
row: Sequence[str],
) -> Union[Note, None]:
try:
_, article, word, plural, tran, example, example_tran, _ = row
except ValueError as e:
logging.error(f"Skipped noun row '{row}': {e}")
return
# Generating word sound
word_sound_filename = AUDIO_DIR / f"{article}{word.lower()}_n.mp3"
if not word_sound_filename.exists():
input_str = word
if article:
input_str = article + " " + input_str
if plural:
input_str = input_str + ", sil<[200]> die " + plural
text_to_speech(
text=input_str,
speed=DEFAULT_WORD_AUDIO_SPEED,
filename=word_sound_filename,
)
word_sound = collection.media.add_file(word_sound_filename)
# Generating example sound
example_sound = None
if example:
example_sound_filename = AUDIO_DIR / f"{article}{word.lower()}_nex.mp3"
if not example_sound_filename.exists() and example:
text_to_speech(
text=example,
speed=DEFAULT_EXAMPLE_AUDIO_SPEED,
filename=example_sound_filename,
)
example_sound = collection.media.add_file(example_sound_filename)
# Adding color to article
if article == "der":
article = f'{article}'
elif article == "die":
article = f'{article}'
else:
article = f'{article}'
# Marking plural diff with bold
if plural:
plural = _highlight_plural_diff(word, plural)
# Creating note
note = collection.new_note(notetype=model)
note.fields = [
article,
word,
# f'die {plural}',
f"die {plural}" if plural else "",
f"[sound:{word_sound}]",
tran,
f'{example}',
f"[sound:{example_sound}]" if example_sound else "",
f'{example_tran}',
"",
]
return noteСинтез слова и примера происходит в функции text_to_speech(). Данные звука будут записаны в файл с переданным именем. Реализация функции практически не отличается от приведенной в документации. Перед вызовом функции проверяется, не существует ли уже файл с произношением этого слова. Также обратите внимание на sil<[200]> — это обозначение паузы, ее длину можно менять с помощью числа в квадратных скобках.
Окрашивание артикля реализовано просто через HTML тэг . RGB коды цветов подобрал те, что больше понравились. А так это синий для der, красный для die и зеленый для das.
В конце в заметку передаются поля для наполнения модели. Шрифт некоторых полей я уменьшил, как написание примера использования слова и его перевода, например. Некоторые поля также изменил на курсивные. Остановимся чуть подробнее на _highlight_plural_diff().
Задача функции выделить жирным те буквы во множественной форме числа, которые отличаются от единственной формы. Например, Auto → Autos, Haus → Häuser. Выделение происходит с помощью HTML-тэга . Также хотелось бы не оборачивать каждую отдельную букву тэгами, а выделять сразу группу букв, если изменяются подряд идущие буквы.
def _highlight_plural_diff(word: str, plural: str) -> str:
tag_offset = 0 # offset of the lenght of html tag
missing_corr = 0 # correction for missing letters
prev_index_diff = ""
for index, diff in enumerate(differ.compare(word, plural)):
if diff[0] != "+":
if diff[0] == "-":
missing_corr += 1
if prev_index_diff == "+":
plural = (
plural[: index - missing_corr + tag_offset]
+ ""
+ plural[index - missing_corr + tag_offset :]
)
tag_offset += 4
prev_index_diff = diff[0]
continue
if diff[0] == "+":
if prev_index_diff != "+":
plural = (
plural[: index - missing_corr + tag_offset]
+ ""
+ plural[index - missing_corr + tag_offset :]
)
prev_index_diff = "+"
tag_offset += 3
continue
if prev_index_diff == "+":
plural += ""
return pluralВозможно, не самая лучшая реализация, но зато работает. Здесь differ возвращает последовательность с символами, обозначающими изменение и буквами, к которым относится изменение.

Демонстрация работы Differ
Символ » », означает, что буква в обоих вариантах не поменялась,»+» — буква добавилась,»-» — буква пропала. missing_corr увеличивается на 1 каждый раз, когда буква пропала, чтобы компенсировать сдвиг индекса, потому что differ считает пропавшую букву и добавившуюся как за два изменения, хотя речь идет об одном символе слова. tag_offset увеличивается на длину вставленного тэга, это либо , либо . При обнаружении измененной буквы, в строку множественной формы вставляется тэг в позицию перед измененной буквой. Если изменение закончилось, вставляет закрывающий тэг. Отправив в функцию слова Hause и Häuser, на выходе получим Häuser.
Результат
Полученные карточки меня более чем устраивают. Отличный синтез слов, простое оформление и нужная мне информация на карточках.

Карточка существительного
Пока я не закончил собирать колоду даже для уровня A1, все таки в источнике 29 страниц со словами — составление CSV файла с переводом и примерами занимает много времени. Зато я рад что мне не нужно создавать карточки руками в интерфейса, думаю все-таки время я сэкономил.
Оговорюсь, что синтез текста через Yandex SpeechKit, как и через OpenAI — развлечение не бесплатное. Не сориентирую по тому, сколько в итоге потратил, так как работу не закончил. Тарифы можно найти здесь.
Я выложил колоду с 20 словами для примера здесь. Вы можете скачать ее и импортировать в Anki, чтобы самостоятельно оценить. Исходный код вместе с датасетом слов и аудио к ним залил в pavelmakis/anki-deck-generator. Быть может, вас заинтересовала тема и вы захотите принять участие в сборке колод, напишите комментарий!
А как вы создавали свои колоды Anki?
