Как я сделал тестер-оптимизатор для нахождения прибыльных стратегий на Бирже — 2

Введение
Примерно три года назад я написал свою первую и не считая этой единственную статью на Хабрахабре «Как я сделал тестер-оптимизатор для нахождения прибыльных стратегий на Бирже». Сработал эффект Хабрахабра, статья оказалась очень популярной и меня буквально засыпали сообщениями и различными предложениями трейдеры. А через месяц эту же статью напечатали в журнале о финансах Financial One. Конечно, я не ожидал такого внимания к моим наработкам и, возможно, благодаря этому я принял окончательное решение заняться алгоритмической торговлей на Бирже профессионально.
С момента написания статьи многое изменилось. Успел поработать в алгоритмическом и хедж-фонде, в процессе реализовал свои идеи в виде полноценной платформы для алгоритмической торговли. Кстати, скоро планирую перевести часть алгоритмов и программного кода в Open Source на GitHub. Разработать платформу было весьма непросто, пришлось значительно подтянуть свои навыки программирования на C# и разобраться с множеством нюансов и сложностей биржевой торговли.
При этом в алгоритмической торговле вопросы оптимизации стратегий по-прежнему стоят очень остро. В этой статье я бы хотел поделиться полученным опытом и некоторыми особенностями оптимизации алгоритмических торговых стратегий.
Оптимизация торговых стратегий
В процессе алгоритмической торговли постоянно возникает необходимость настройки параметров алгоритмов торговых стратегий. Сочетания всех возможных параметров превращается в большое многомерное пространство вариантов стратегий. Чтобы получить самые прибыльные и стабильные стратегии нужно исследовать это пространство и подобрать оптимальные параметры для торговли.
Самый лучший способ исследования любого множества — это полный перебор всех его элементов Brute Force. Однако учитывая колоссальные объемы данных с которыми приходится сталкиваться при оптимизации, как правило, оказывается просто невозможно провести подобное исследование полным перебором. Приходится применять различные аналитические алгоритмы, которые позволяют сократить фактический объем исследований в процессе поиска экстремумов.
Большинство таких алгоритмов хорошо известны: метод Монте-Карло, метод градиентного спуска, метод имитации отжига, эволюционные алгоритмы и т.д. При этом существуют различные модификации данных алгоритмов оптимизации. В алготрейдинге, как правило, встречаются реализации генетических алгоритмов и Монте-Карло. Так или иначе все эти алгоритмы используют «магию случайных чисел» или научно говоря нелинейную стохастическую оптимизацию.
Классическая проблема стохастических алгоритмов оптимизации заключается в том, что при не больших объемах фактических исследований и малых выборках они не репрезентативны. Например, Монте-Карло не эффективен в многоэкстремальном пространстве, он акцентирует исследование на глобальном экстремуме упуская из вида локальные, но не менее интересные экстремумы. Алгоритм не ставит перед собой таких задач, ему просто нужно найти самую прибыльную стратегию. Генетический алгоритм также может пойти не удачной веткой мутаций и остановиться на каком-нибудь локальном экстремуме и т.д.
Все потому, что данным алгоритмам оптимизации на начальных этапах приходится принимать решения на ограниченном объеме данных в еще не изученном пространстве и из исследования могут легко выпасть важные области. Чтобы этого избежать нужно увеличивать выборки данных и время исследования, а в нашем случае время на вес золота. Нужно при минимальных затратах времени максимально подробно исследовать экстремумы пространства. При этом в быстро меняющихся условиях биржевой торговли важно уделять внимание не только прибыльным, но и стабильным параметрам торговых стратегий. Под стабильными понимаются параметры формирующие кластеры с похожими результатами. Прибыльные стратегии, находящиеся вне кластеров, могут оказаться не стабильными и привести к серьезным убыткам. В свою очередь стратегия из кластера в меньшей степени подвержена изменениям на рынке.
Метод стохастической кластерной оптимизации
Учитывая особенности оптимизации биржевых стратегий был разработан гибридный алгоритм (см. прошлую статью) у которого оказался один приятный побочный эффект — он успешно выделял и исследовал кластеры. Я дал название полученному алгоритму — «Метод стохастической кластерной оптимизации».
Процесс исследования поэтому алгоритму проходит в два этапа:
- Исследование пространства стратегий с удалением убыточных и подверженных риску областей
- Подробное исследование экстремумов и кластеров пространства
Этап 1. Исследование пространства стратегий с удалением убыточных и подверженных риску областей.
Чтобы избавиться от неопределенности при нехватке данных на начальных этапах исследования алгоритм не ставит задачу поиска прибыльных стратегий, а наоборот, ищет самые убыточные и удаляет их из пространства вместе с пограничными с ними областями с потенциально высокими рисками убытков.
Работа ведется в следующем порядке:
- Формируется многомерное пространство из всех возможных параметров торговой стратегии
- Из пространства случайно выбираются стратегии и тестируются на исторических данных с указанными параметрами
- По результатам тестирования вокруг самых убыточных стратегий удаляются пограничные микрообласти. Тем самым уменьшается пространство исследования и делается акцент на более прибыльные и стабильные области в дальнейших итерациях.
- Итерации тестирования проводятся до тех пор, пока пространство стратегий не будет исследовано в нужной степени
На Рис. 2 видно, как исследование смещается в сторону экстремумов при этом риск упустить маленькие кластеры с возможно хорошими и стабильными параметрами минимален.

Рис. 2. Первый этап алгоритма «Stochastic Cluster Optimization» — исследование пространства стратегий.
Этап 2. Подробное исследование кластеров и экстремумов.
После первого этапа исследования становятся хорошо виды экстремумы. Однако, в силу особенностей алгоритма (вырезается множество микрообластей) пространство получается «рваным» и некоторые экстремумы могут быть исследованы не очень подробно. Чтобы полностью изучить все интересные кластеры алгоритм оптимизации начинает процесс исследования в точности наоборот. Для этого выбираются все лучшие стратегии и вокруг них дополнительно выделяются микрообласти. Если в этих областях обнаруживаются еще не исследованные стратегии, то они дополнительно тестируются (см. Рис. 3).

Рис. 3. Второй этап алгоритма «Stochastic Cluster Optimization» — подробное исследование экстремумов.
В результате после работы алгоритма исследуются все интересные нам области пространства и подробно тестируются кластеры с прибыльными стратегиями. При этом фактический объем исследования, как правило, составляет не более 25–50% от общего объема пространства вариантов стратегий (см. Рис. 4).
 |
 |
Рис. 4. Скорость исследования алгоритма «Stochastic Cluster Optimization» (слева) в 2–4 раза выше скорости алгоритма «Brute Force» (справа).
Walk Forward оптимизация
Казалось бы оптимизировали параметры и можно начинать торговать. Однако на этом процесс иссдедования еще не завершается. Процесс оптимизации подвержен риску «подгонки» или переоптимизации параметров под используемые в процессе исторические данные, поэтому нужно дополнительно проверить полученные результаты. Для этого используется метод Walk Forward. Суть метода заключается в том, что параметры стратегий тестируются на исторических данных отличных от тех, которые использовались в процессе оптимизации.
Для этого весь диапазон исторических данных разбивается на выборки, состоящие из наборов:
- IS («In Sample») — выборка, используемая для оптимизации
- OOS («Out Of Sample») — выборка, используемая для тестирования результатов оптимизации
Причем диапазоны выборок формируются таким образом, чтобы данные OOS следовали последовательно друг за другом (см. Рис. 5).
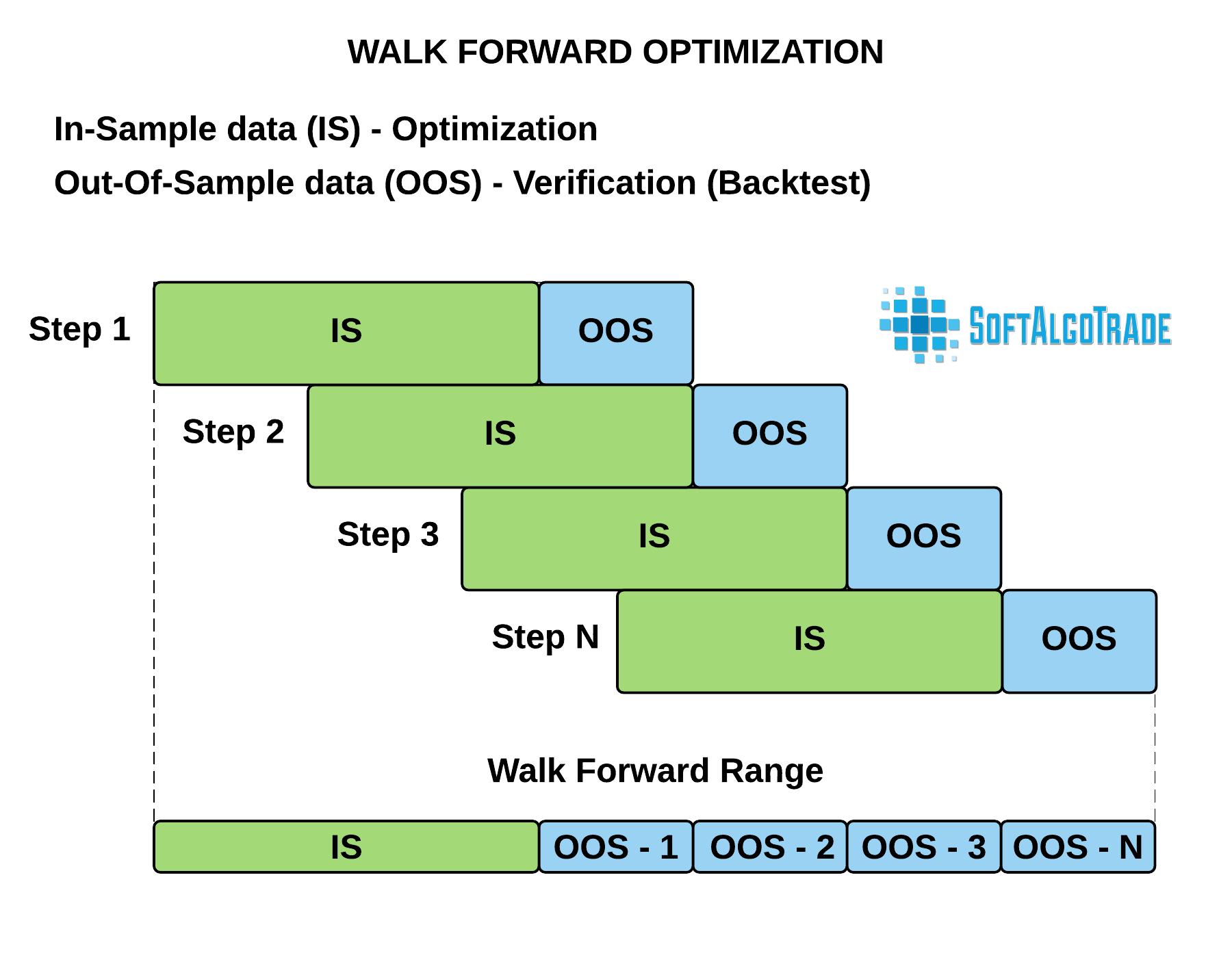
Рис. 5. Схема Walk Forward оптимизации.
Для уменьшения объемов исследования на этапах проверки результатов, можно после оптимизации сразу отфильтровать стратегии с плохими показателями, тем самым сокращая общее время тестирования. В результате такой проверки мы получим объективные параметры торговых стратегий, защищенные от переоптимизации (см. Рис. 6 и Рис. 7).
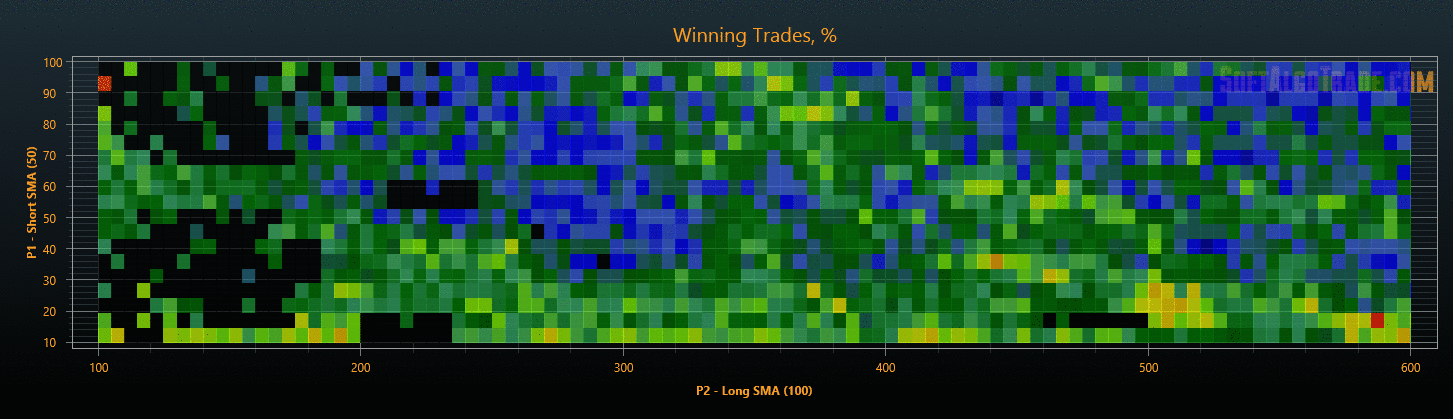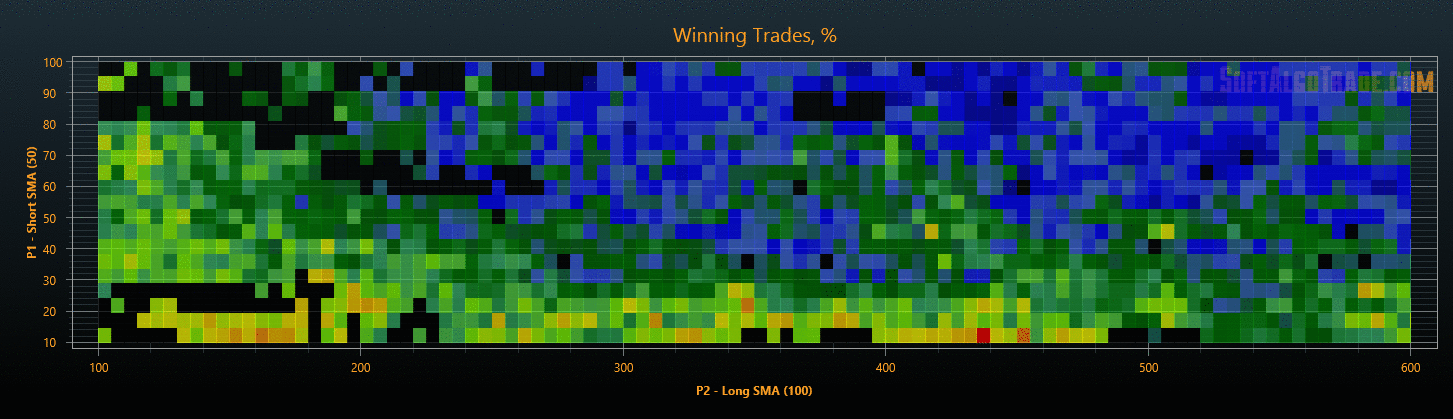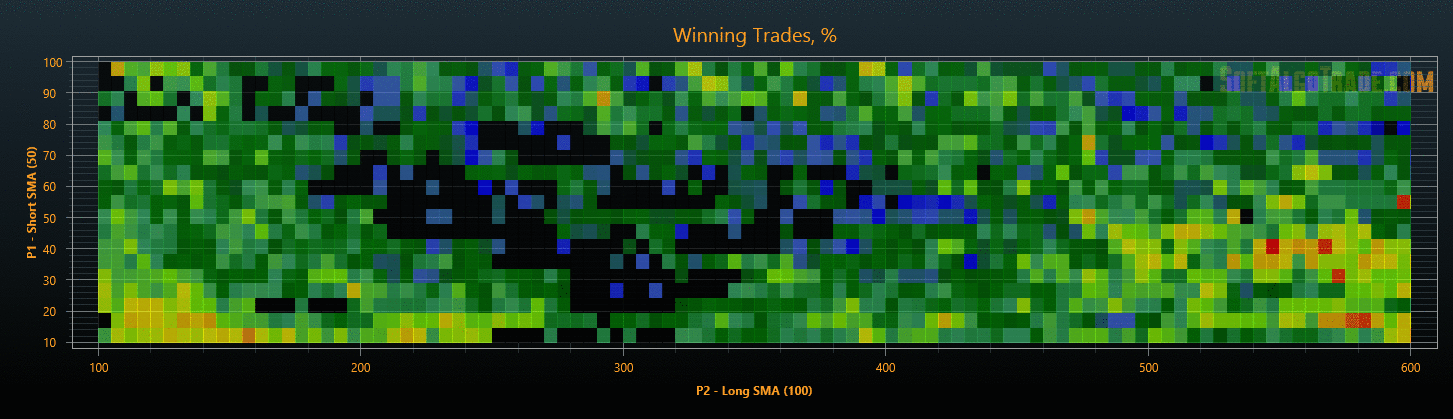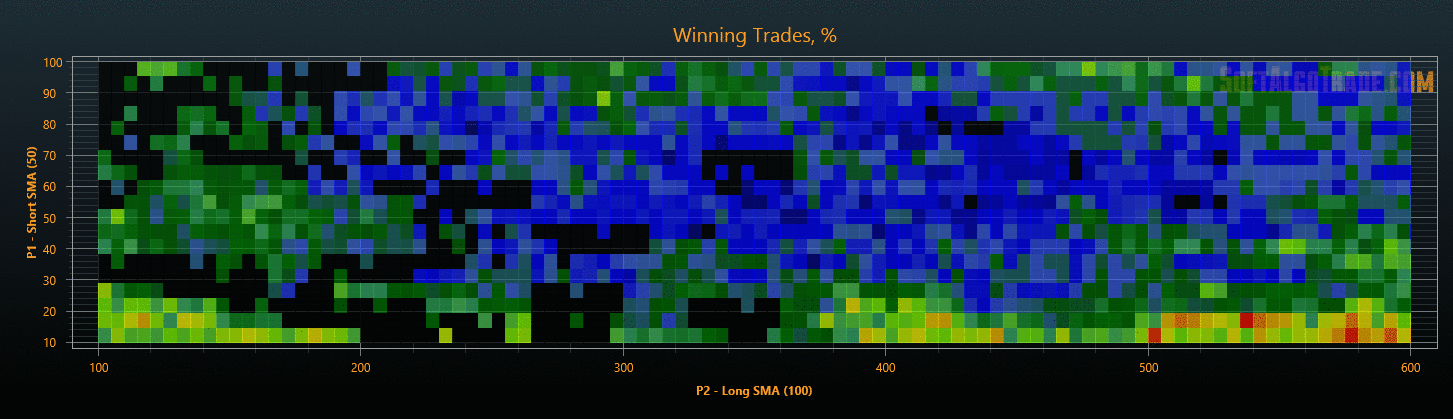
Рис. 6. Результаты оптимизации на данных «In Sample».
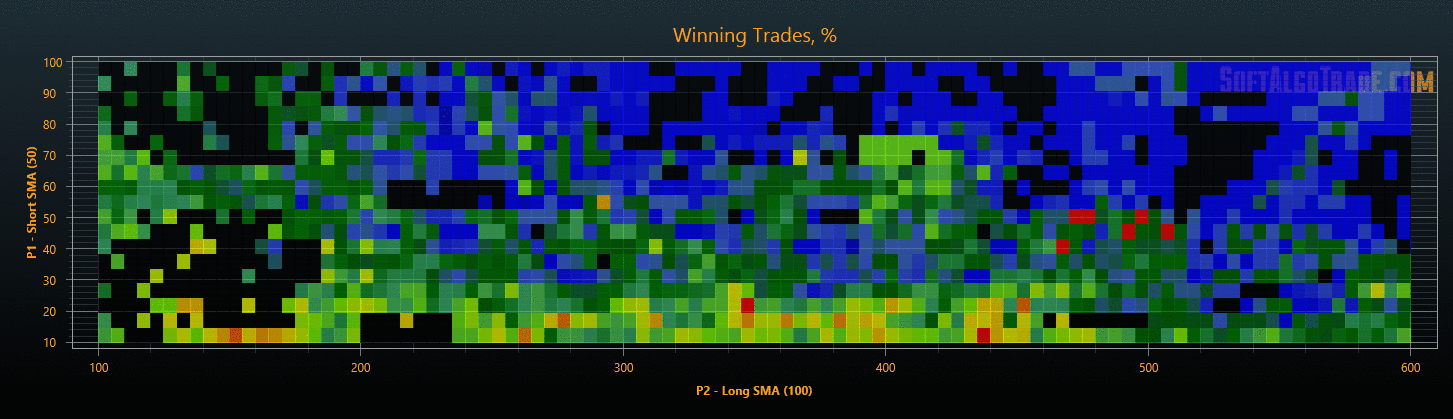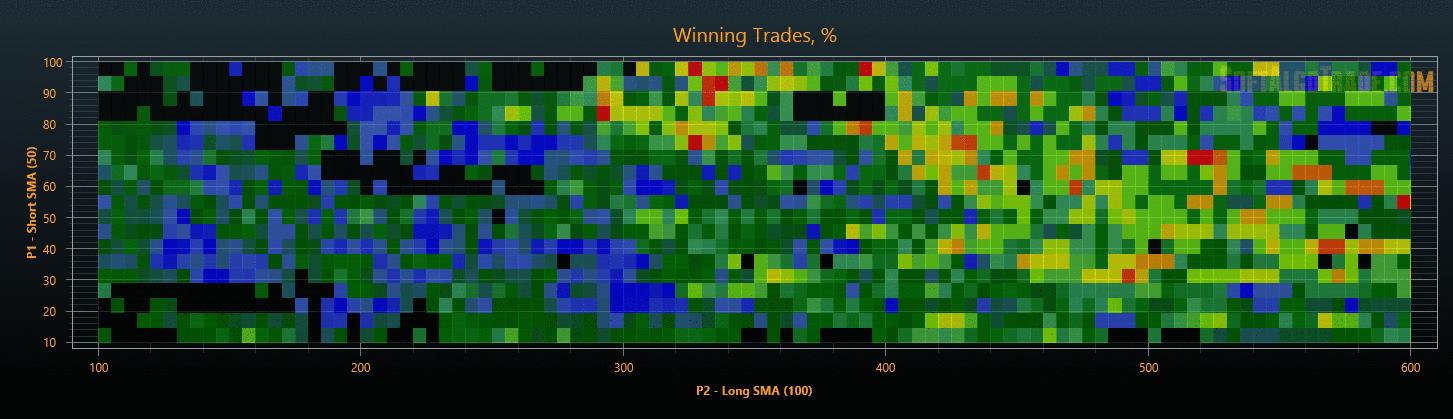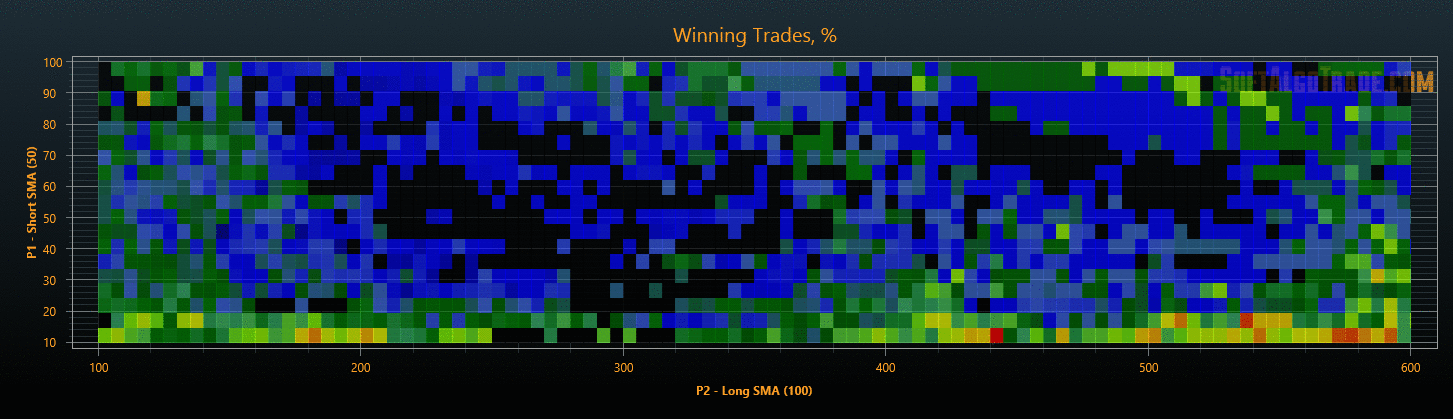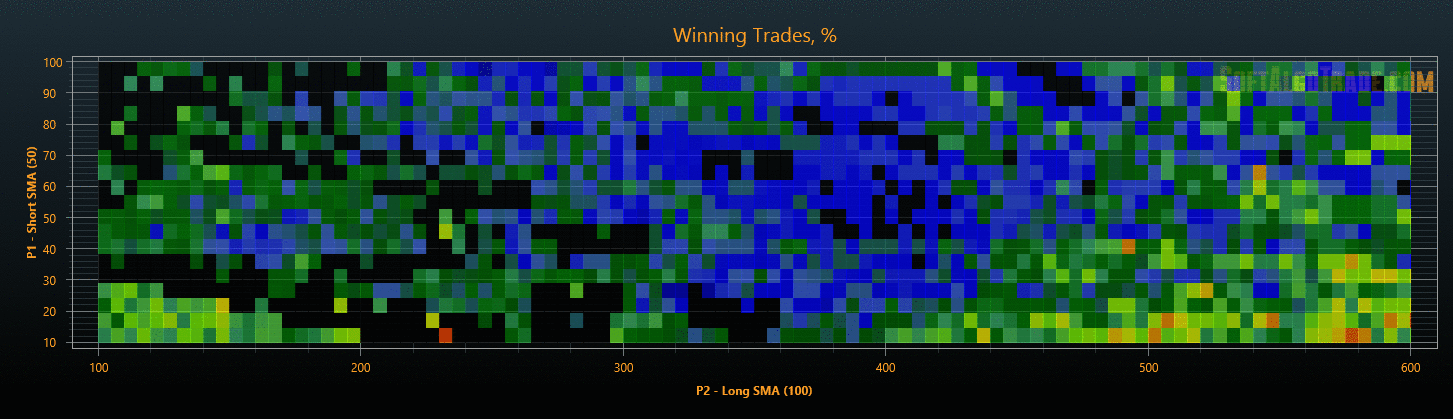
Рис. 7. Проверка результатов оптимизации на данных «Out Of Sample».
Анализ результатов
Как правило после проверки по методу Walk Forward большая часть торговых стратегий выглядит уже не так привлекательно, как после оптимизации. В идеальном варианте стратегии должны подтвердить свои статистические показатели, а экстремумы и кластеры сохранить свою форму и положение в пространстве.
Для комфортного анализа полученных результатов я визуализировал многомерное пространство стратегий по каждому параметру в формате тепловой карты (см. Рис. 8). По карте визуально оцениваются форма и размеры кластеров, положение экстремумов, проверяется влияние параметров на результативность стратегии, оцениваются изменения после проверки на переоптимизацию и т.д.

Рис. 8. Пример сечения пространства по оптимизируемым параметрам и целевой функции.
Для комплексной оценки результатов Walk Forward оптимизации строится матрица со всеми шагами и параметрами, прошедшими фильтрацию. Зеленым цветом выделяются шаги, на которых параметры подтвердили свои показатели и красным, соответственно, если не подтвердили. Параметры, показавшие себя хорошо на большом количестве шагов можно считать более пригодными для торговли (см. Рис. 9).
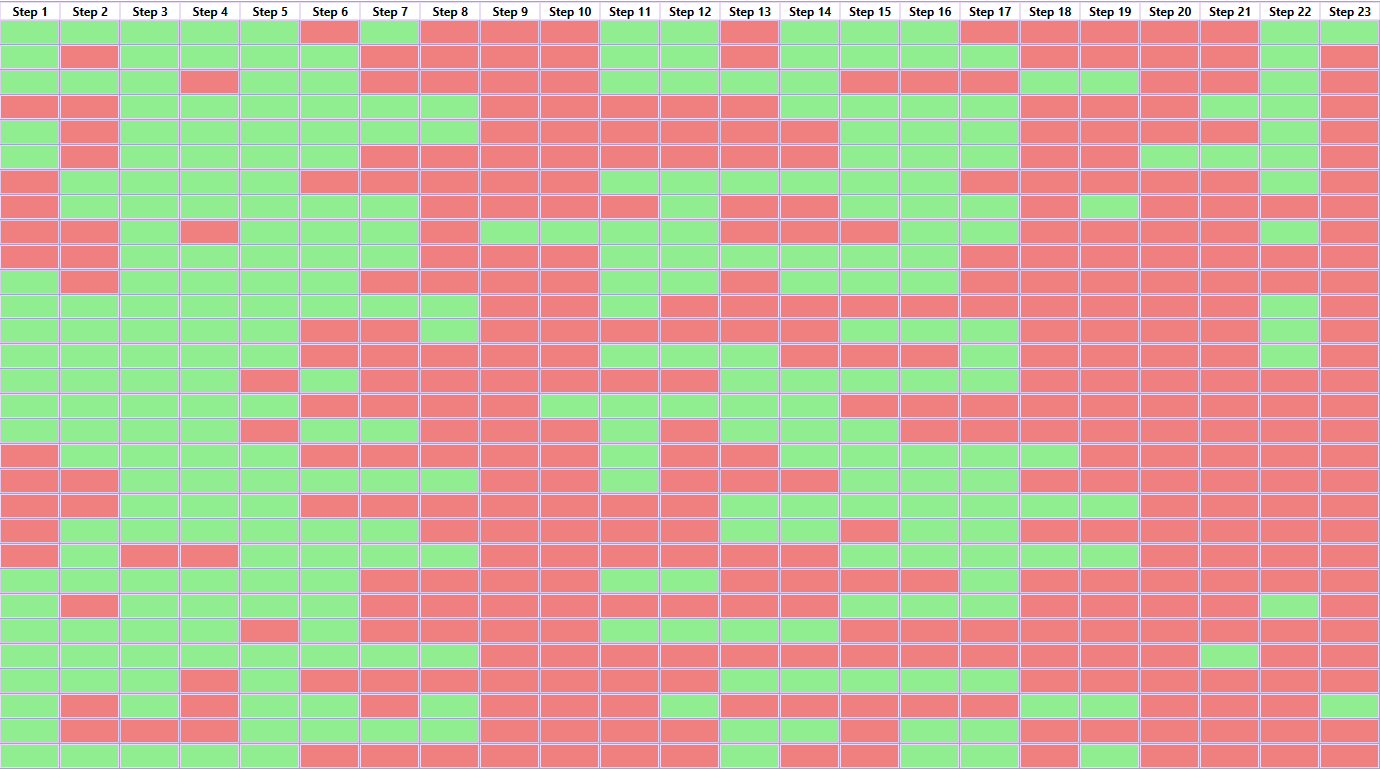
Рис. 9. Матрица Walk Forward со всеми результатами провеки на данных OOS.
В случае необходимости полученные результаты можно экспортировать в сторонние системы анализа для более детального исследования. Например, в R, Excel или Mathlab (см. Рис. 10).

Рис. 10. Экспорт результатов оптимизации в Excel.
Чтобы окончательно убедиться в правильности выборанных параметров проводятся детальные тесты стратегий, оценивается плавность кривой доходности, выводятся заявки на график и изучается лог торговых сделок (см. Рис. 11).
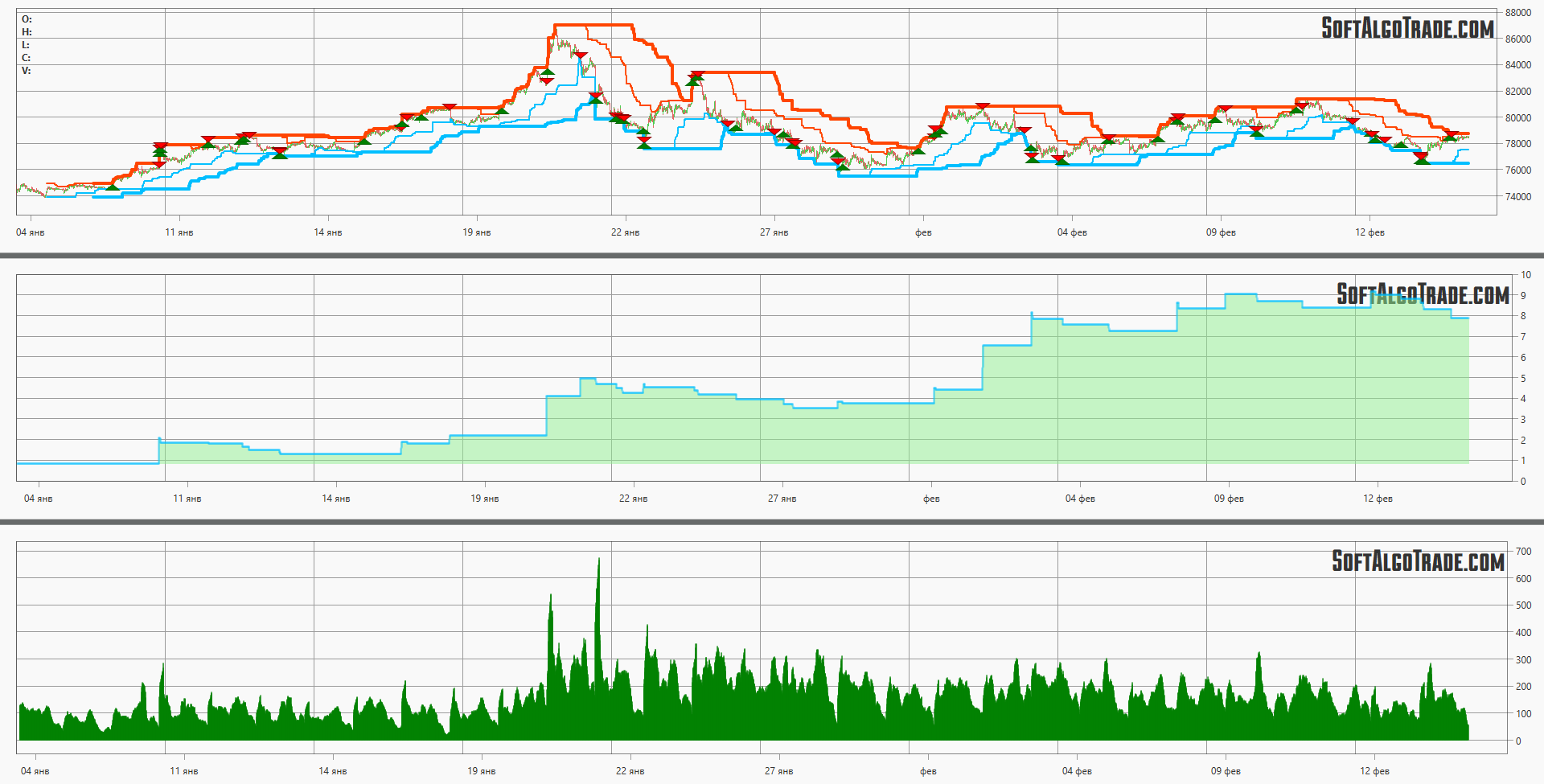
Рис. 11. Подробный анализ параметров торговой стратегии.
Заключение
После оптимизации и всех проверок у нас останутся стратегии потенциально пригодные к реальной торговле на Бирже.
Наконец мы все перепроверили, наверное, уже можно начинать торговать? На самом деле мы только на полпути, еще рано отправлять торговые алгоритмы в бой. Далее предстоит:
- Проверить стратегии на «живых» данных с Биржи для подтверждения показателей, полученных во время тестирования.
- Сформировать портфель из торговых стратегий для диверсификации рисков. Кстати, его тоже нужно оптимизировать.
- В процессе реальной торговли периодически сводить полученные результаты с результатами тестов для корректировки настроек тестера-оптимизатора.
Но об этом, наверное, в другой раз.
Всем удачной торговли!
P.S. Меня зовут Алексей, я алгоритмический трейдер, профессиональный разработчик программного обеспечения для алгоритмической торговли на Бирже, основатель проекта SoftAlgoTrade. Скайп — softalgotrade.
Комментарии (8)
1 марта 2017 в 20:37
+1↑
↓
Эх, занимался этим всем лет 10 назад со своим роботом.
Мои методы были проще: скрипт на Perl, который тестировал какую-нибудь стратегию на скачанных с биржи исторических CVS-файлах нескольких сотен позиций за несколько лет дневных свечек (SQL оказался слишком медленным). Проверка одного набора параметров занимала примерно 20 сек, перебор параметров стратегии и поиск самых оптимальных — 1–2 часа.
С тех пор биржу наводнили другие роботы, прибыльность уменьшалась до уровня, что комиссия все забирает, и надо было становится брокером, чтобы продолжать торговать в плюсе. Bond_algotrade
Bond_algotrade
1 марта 2017 в 21:12
0↑
↓
Вначале я тоже использовал SQL базу данных и, действительно, по производительности это оказалось не лучшим решением. В основном оптимизирую стратегии на тиках, так как результаты получаются точнее по сравнению с тестами на свечках, поэтому данных очень много — сотни миллионов тиков. В этом случае No SQL база данных оказалась в разы производительнее.
Производительность тестирования во многом зависит от архитектуры приложения и оптимизации кода при работе с большими объемами данных. Здесь у меня все весьма не плохо, долго оптимизировал ядро платформы, чтобы получить высокую производительность. Тесты на тиках проходят быстро, а со свечками проблем вообще нет.
 Danov
Danov
1 марта 2017 в 21:00
+1↑
↓
Как долго работает найденная стратегия?-
Bond_algotrade
1 марта 2017 в 21:22
0↑
↓
По разному, ведь видов торговых стратегий очень много и они могут работать по самым различным принципам. Одни работают годами, а другие нужно каждую неделю переоптимизировать. Как правило, чем меньше параметров для настройки у стратегии, тем реже ее приходится оптимизировать.
1 марта 2017 в 21:26
+6↑
↓
Вам удалось заработать на этом?-
Bond_algotrade
1 марта 2017 в 21:33
0↑
↓
В основном я занимаюсь разработкой торговой платформы. Алгоритмические трейдеры с которыми я сотрудничаю весьма успешно торгуют как на Московской бирже, так и на Америке.
1 марта 2017 в 22:15
+1↑
↓
Скорость исследования алгоритма «Stochastic Cluster Optimization» (слева) в 2–4 раза выше скорости алгоритма «Brute Force»
… при слегка меньшей надёжности (остаётся шанс пропустить хорошее решение). И ускореение всего в несколько раз. Не проще ли железо докупить?-
Bond_algotrade
1 марта 2017 в 22:43
0↑
↓
В определенный момент железо начинает обходиться слишком дорого и получить прирост производительности в несколько раз без дополнительных затрат явно того стоит.
Например, с большим портфелем торговых алгоритмов вы вполне можете арендовать пару десятков виртуальных машин для периодической оптимизации торговых стратегий по различным инструментам на нескольких Биржах на различных таймфреймах. Поверьте, мощностей всегда дефицит, а с применением аналитических алгоритмов, вы сможете не плохо так сократить свои издержки.
