Дизайн REST API для высокопроизводительных систем

Александр Лебедев выражает всю нетривиальность дизайна REST API. Это — расшифровка Highload++ 2016.
Всем здравствуйте!
Поднимите руку те, кто фронтенд разработчик в этом зале? Кто мобильный разработчик? Кто бэкенд разработчик?Бэкенд разработчиков большинство в этом зале сейчас, что радостно. Во-вторых, почти все проснулись. Чудесная новость.
Пару слов о себе
Кто я такой? Чем занимаюсь?
Я фронтенд team lead компании «Новые Облачные Технологии». Последние 5 лет я писал веб фронтенд, который работает с REST API и который должен для пользователя работать быстро. Я хочу поделиться опытом о том, какие API должны быть, которые позволяют этого добиться.
Несмотря на то, что я буду рассказывать со стороны фронтенда, принципы — они общие более-менее для всех. Я надеюсь и бэкенд разработчики, и разработчики мобильных приложений так же найдут для себя в этом рассказе полезные вещи.
Пара слов о том, почему важно иметь хорошее API для быстрых приложений
Во-первых — это производительность с точки зрения клиента. То есть не с точки зрения того, чтобы нам поддержать миллион клиентов, пришедших одновременно —, а с точки зрения того, чтобы для каждого из них отдельно приложение работало быстро. Чуть позже я проиллюстрирую в этом докладе кейс, когда изменения в API позволили ускорить примерно в 20 раз получение данных на клиенте и позволили превратить несчастных пользователей в довольных пользователей.
Во-вторых — в моей практике был случай, когда приходилось через очень небольшой промежуток времени писать одинаковый практически функционал к двум разным системам. У одной был удобный API, у другой был неудобный API. Как вы думаете насколько отличалась трудоемкость написания этого функционала? Для первой версии — в 4 раза. То есть с удобным API мы написали первую версию за две недели, с неудобным за два месяца. Стоимость владения, стоимость поддержки, стоимость добавления чего-то нового — она также отличалась в разы.
Если дизайном вашего REST API не заниматься — то вы никак не гарантируете, что вы не окажетесь с неправильной стороны этого диапазона. Поэтому хочется, чтобы подход к REST API был разумным.
Я сегодня буду рассказывать о простых вещах, потому что они более-менее универсальны — они применимы почти ко всем проектам. Как правильно сложные кейсы требуют отельного анализа, они специфичны для каждого проекта, поэтому не так интересны в плане обмена опытом.
Простые вещи интересны почти всем.
Давайте начнём с того, что посмотрим на ситуацию в целом. В каком окружении существует REST API, который нам надо сделать хорошо?
В случаях, с которыми я работал, можно сделать следующее обобщение:

У нас есть некий бэкенд — условно, с точки зрения фронтенда, он един. На самом деле там всё сложно. Наверное, все видели карикатуру, где в качестве фронтенда выступает русалка, а в качестве бэкенда какое-то кошмарное морское чудовище. Это может примерно также работать. Важно, что у нас есть единый с точки зрения фронта бэкенд — у нас есть единое API, к нему есть несколько клиентов.
Достаточно типичный случай: у нас есть веб, и у нас есть две самых популярных мобильных платформы. Что можно сразу вынести из этой картины? Один бэкенд, несколько клиентов. Это означает, что у нас много раз в коде дизайна API будут выборы куда унести сложность. Либо немножко больше работы сделать на бэкенде, либо немножко больше работы сделать на фронте.
Надо понимать, что в такой ситуации, работа на фронте будет умножена на 3. Каждый продукт должен будет содержать ту же самую логику. Так же нужно будет прикладывать дополнительные усилия даже не в ходе разработки, а в ходе дальнейшего тестирования и сопровождения, чтобы эта логика не разъехалась и оставалась одинаковой на всех клиентах.
Надо понимать, что отнесение какой-то логики на фронтенд стоит дорого и должно иметь свои причины, не должно делаться «просто так». Еще хочется отметить, что API на этой картине тоже единый, также неспроста.
Как правило, если мы говорим, что мы хотим разрабатывать эффективно и мы хотим делать приложение быстрым, очень хочется несмотря на то, что на бэкенде может быть зоопарк систем (энтерпрайз интеграция половины десятка систем с разными протоколами, с разными API). С точки зрения общения с фронтендом — это должен быть единый API, желательно построенный на одних и тех же принципах, и который можно менять более-менее целостно.
Если этого нет, то говорить о каком-то осмысленном дизайне API становиться резко сложнее, увеличивается количество решений, про которые приходится сказать: «ну, мы были вынуждены, это такое ограничения». Хочется, чтобы в эту ситуацию не приходилось попадать. Хочется, чтобы мы могли, как минимум с точки зрения того какой API мы предоставляем для клиентских приложений, его весь контролировать.
Еще один момент — давайте добавим на эту схему людей.

Что у нас получается
Получается у нас есть одна или несколько бэкенд команд, одна или несколько фронтенд команд. Надо понимать, что, если мы хотим иметь хороший API — он является общим достоянием. С ним работают все команды. Это значит, что решения по API должны приниматься желательно не в одной команде, а совместно. Самое главное — решения должны приниматься в интересах всех этих команд.
Если я, как фронтенд lead, для реализации какой-то функциональности на вебе придумываю API и иду договариваться с бэкенд разработчиками о том, чтобы его реализовать — я должен учесть не только интересы веба, не только интересы бэкенда, но и интересы мобильных команд. Только в таком случае не придётся мучительно переделывать.
Либо я должен сразу чётко понимать, что делаю какой-то временный прототип, который потом нужно будет охватить диапазон, с которого мы собираем требования, включив в него остальные команды и переделать. Если я это понимаю, то можно исходить из интересов отдельной команды. Иначе нужно исходить из интересов системы в целом. Все эти люди должны работать вместе, чтобы API был хорошим.
В таких условиях у меня получилось добиваться того, чтобы API был удобным — чтобы к нему было удобно писать хороший фронтенд.
Давайте еще немножко поговорим об общих идеях, прежде чем перейдем к конкретике.
Три основных принципа, которые хочется осветить
То, о чём я уже немножко говорил применительно к человеческому ключу для технических решений тоже важно. Технические решения по API должны приниматься исходя их всей системы, а не исходя из видения какой-то конкретной его части.
Да, это сложно. Да, это требует какой-то дополнительной информации, когда нужно делать прям сейчас, но это окупается.
Во-вторых, измерение производительности важнее, чем её оптимизация.
Что это значит? Пока вы не начали измерять с какой скоростью работает ваш фронтенд, с какой скоростью работает ваш бэкенд, вам рано их оптимизировать. Потому что, почти всегда — в этом случае будет оптимизироваться не то. Я позже расскажу про пару таких случаев.
Наконец, то что я уже краем задел. Сложные кейсы — они уникальны для каждого проекта.
Простые принципы более-менее универсальны, поэтому хочется рассказать вам про несколько простых ошибок, часть из которых познана на личном опыте. Эти ошибки может не повторять почти любой проект.
Небольшая секция про то, как мерить производительность. На самом деле это очень серьезная тема — по ней есть куча отельной литературы, куча отельных материалов, а также специалисты, которые занимаются только этим.
Что я собираюсь рассказать
Я собираюсь рассказать с чего можно начать, если у вас вообще ничего нет. Какие-то дешёвые и сердитые рецепты, которые помогут вам начать изменять производительность веб фронтенда и начать измерять производительность бэкенда, чтобы потом начать их ускорять. Если у вас уже что-то есть — замечательно. Скорее всего оно лучше того, что я предлагаю.
Производительность бэкенда.
Мы меряем через то, с чем работают клиенты — через REST API. Желательно при этом воссоздавать более-менее точно то, как с этим API работает пользователь.
Производительность UI мы меряем через автоматизированное тестирование фронтенда. То есть в каждом случае мы измеряем не какие-то внутренние элементы — мы измеряем именно тот интерфейс, с которым работает следующий слой.
То есть REST API для бэкенда и UI для пользователя.
Что надо понимать для измерения
Во-первых, чем ближе наша среда к тому, что будет работать в продакшене — тем точнее наши цифры. Очень важно чтобы у нас были данные, похожие на настоящие.
Часто получается, когда мы разрабатываем, у нас вообще нет никаких тестовых данных. Разработчик что-то создаёт на своей машине — обычно по одной записи, для чтобы покрыть каждый сценарий, о котором подумали в ходе анализа и у него получается 5–10 записей. Всё хорошо.
А потом выясняется, что реальным пользователям работать с 500 записей, в том же интерфейсе, в той же системе. Начинаются тормоза и проблемы. Или разработчик создаёт 500 записей, но они все одинаковые и созданы скриптом. При неодинаковых данных из реальной жизни могут начаться всякие аномалии.
Если у вас есть данные с продакшена, самые лучшие тестовые данные — берем выборку данных из продакшена, убираем оттуда всю sensitive информацию, которая является частным достоянием конкретных клиентов. На этом разрабатываем, на этом тестируем. Если мы можем делать так, то это замечательно, потому что не нужно думать над тем какие же эти данные должны быть.
Если у нас пока ранняя стадия жизни системы и мы не можем так сделать — приходится гадать о том, как пользователи будут использовать систему, сколько там данных, каких данных. Обычно эти предложения будут сильно отличаться от реальной жизни, но они всё равно в 100 раз лучше, чем подход «что выросло, то выросло».
Потом, количество пользователей. Тут речь идёт о бэкенде, потому что на фронтенде пользователь обычно один. Есть искушение, когда мы тестируем производительность, пустить небольшое количество пользователей с очень интенсивными запросами. Мы говорим: «к нам придёт 100 тысяч человек, они будут совершать новые запросы в среднем раз в 20 секунд.
Давайте это заменим 100 ботами, которые будут совершать новые запросы раз в 20 миллисекунд».
Казалось бы, общая нагрузка будет одна и та же. Однако, сразу выясняется, что в этом случае мы как бы почти всегда меряем не производительность системы, а производительность кэша где-нибудь на сервере или производительность кэша базы данных, или производительность кэша сервера приложений. Можем получить цифры, которые гораздо лучше, чем реальная жизнь. Желательно, чтобы количество пользователей — количество одновременный сессий, так же было близко к тому, что мы ожидаем в реальной жизни.
Как пользователи работают с системой
Важно чтобы мы прикидывали сколько раз будет использоваться каждый элемент, в рамках средней сессии. У меня был случай, когда мы сценарий нагрузочного тестирования реализовали просто — написав скрипт, которой трогает все важные части системы, по разу. То есть человек заходит, каждой важной функцией пользуется один раз и выходит.
И выяснилось, что у нас есть две самые медленные точки. Мы начали героически оптимизировать. Если бы мы подумали или посмотрели статистику, которой на тот момент не было — мы бы узнали, что первая самая медленная точка используется в 30% сессий, а вторая самая медленная точка используется в 5% сессий.
Это нам, во-первых, позволило бы оптимизировать их по-разному. То, где 30% оно важнее. А во-вторых — позволило бы обратить внимание на то что есть функционал, который, несмотря на то, что не так медленно работает, используется всегда.
Если сессия начинается со входа в систему и просмотра какого-то dashboard, то performance этого входа и performance этого dashboard ощущает на своей шкуре 100% пользователей.
Поэтому, даже если это не самые медленные места — их всё равно имеет смысл оптимизировать. Поэтому важно думать о том, как будет типичным пользователем восприниматься система, а не том какой у нас функционал есть или какой функционал надо проверить на производительность.
На бэкенде — как нам померить производительность REST API?
Подход, которым пользовался лично я, который довольно неплохо работает как первое приближение — это то, что у нас должны быть use case. Есть у нас нет use case, мы их пишем.
Мы прикидываем процент использования функций системы в каждой сессии. Перекладываем это в запросы к REST API. Убеждаемся, что у нас есть данные похожие на реальные для тестовых пользователей. Пишем скрипты, которые генерят их. Дальше всё это выгружаем в JMeter или любой другой инструмент, который нам позволяет устроить походы к REST API большим количеством параллельных пользователей и тестируем. В качестве первого решения — ничего сложного.
Для фронтенда — всё примерно той же степени дубовости.

Набиваем ключевые места в коде, вызовами консольных функций, которые считают время, выводим в консоль, всё — для разработчика достаточно.
Он может запустить отладочную сборку, посмотреть сколько времени показывался тот или иной кусок, сколько времени проходило между теми или иными пользовательскими действиями — всё хорошо.
Если мы хотим делать это автоматизировано мы пишем Selenium сценарий. Для Selenium консольные функции не очень походят — там пишется примитивная обёртка, которая берёт точно время windows.performance.now () и передает его в какой-нибудь глобальный объект, откуда его потом можно забрать. В этом случае мы можем гонять тот же самый сценарий на разных версиях и отслеживать как меняется наша производительность системы со временем.
Теперь хочется перейти к основной части — рецепты, познанные на личном опыте.
Как надо и как не надо делать API
Начнем с одного довольно любопытного кейса: я говорил, что на уровне API можно оптимизировать скорость обработки в 20 раз.
Сейчас я покажу как конкретно этот сценарий был устроен.

У нас есть бэкенд. Он агрегирует в себе данные их трёх разных систем и показывает их пользователю. В нормальной жизни время ответа выглядит примерно вот так:

Уходит три параллельных запроса — бэкенд их агрегирует. Время в секундах. Везде ответ меньше секунды. Добавляется 100 миллисекунд на распараллеливание запрос на агрегацию. Отдаём данные фронтенду и все счастливы.
Казалось бы, всё хорошо, что может пойти не так?
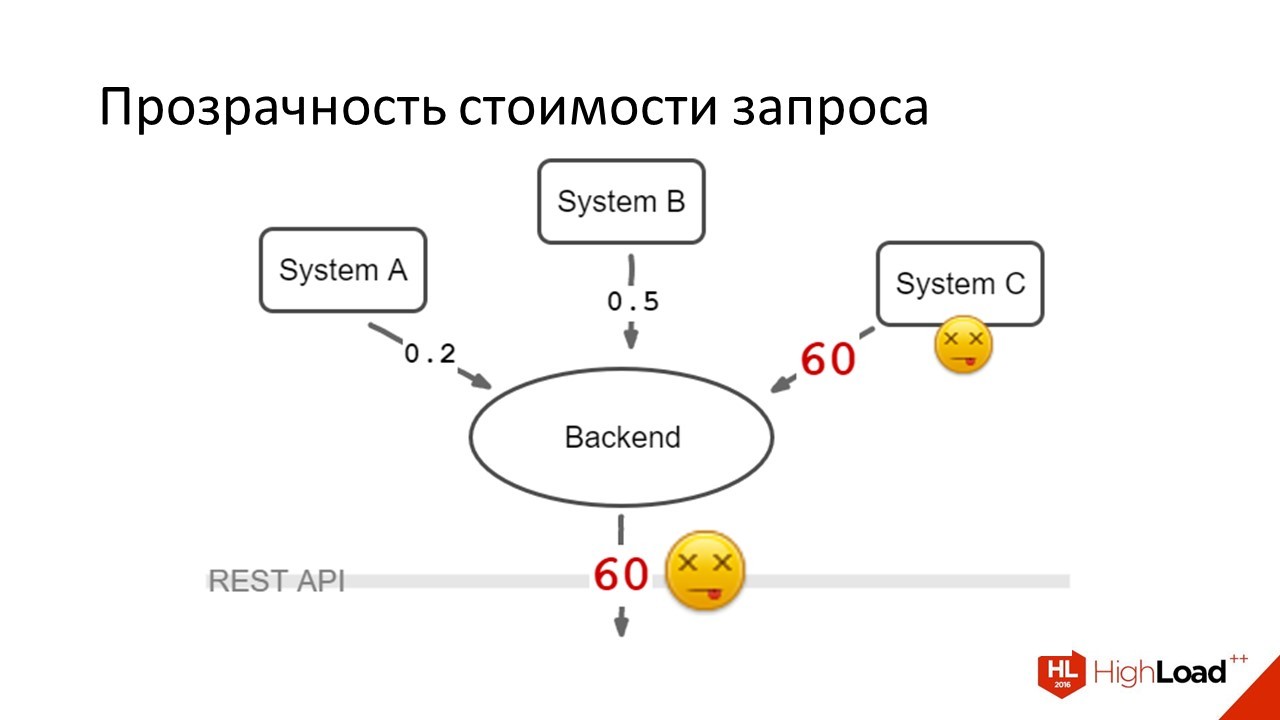
Одна из систем внезапно умирает — притом она умирает весьма поганым способом, когда вместо того чтобы сразу честно ответить, что система недоступна — она висит по таймауту.
Это происходит в те дни, когда нагрузка на систему в целом — когда у нас больше всего пользователей. Пользователи радостно видят, что их loading spinner не исчезает, они жмут F5, мы отправляем новые запросы, всё плохо.
Что мы делали в этом случае
Первое, что мы сделали — это понизили таймауты. Стало вот так:
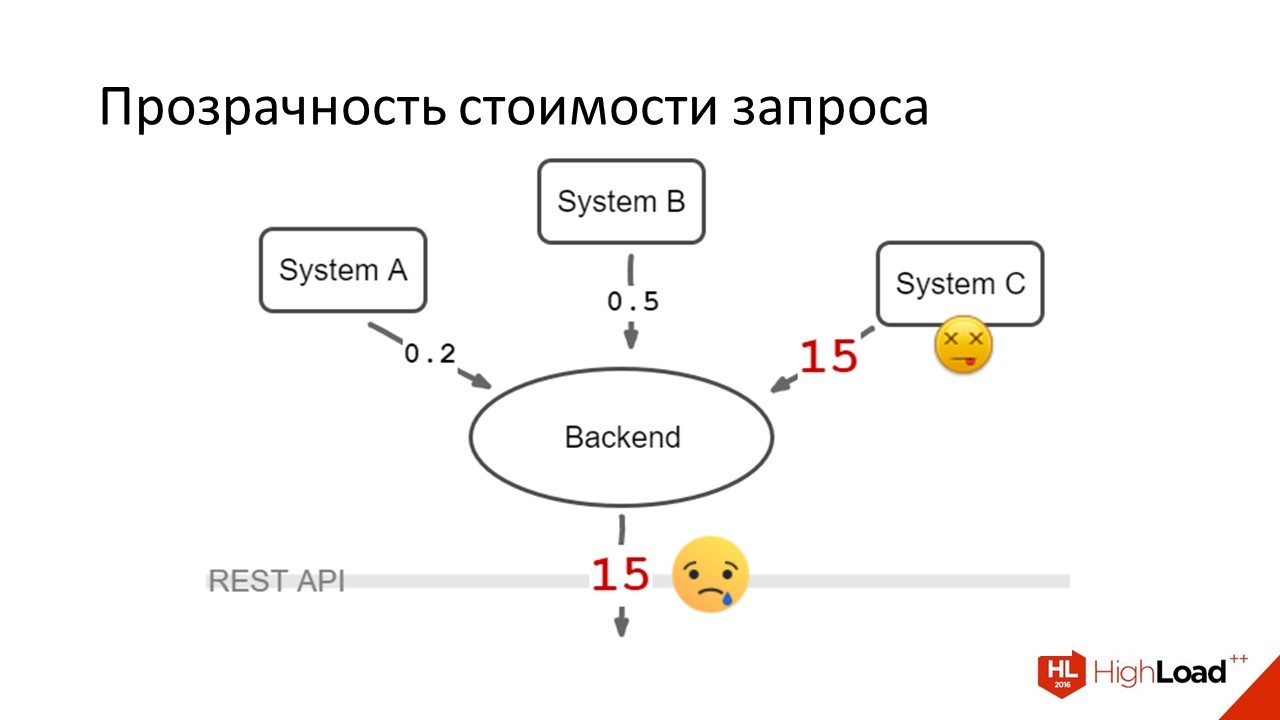
Пользователи стали в среднем дожидаться своих ответов, но всё равно они были очень несчастны. Потому что 15 секунд там, где раньше была одна — это крайне тяжело. Проблема была переходящая. Система C то работала с нормальной скоростью, то ложилась, то снова работала.
Таймауты ниже этой цифры понизить не удавалось, потому что были ситуации, когда она в норме отвечала секунд 10–12. Это было редко.
Но если бы мы понижали таймаут, мы начали бы делать несчастными еще и пользователей, которые попали в этот хвост времени ответа.
Первое решение в лоб было сделано в тот же день. Оно улучшило ситуацию, но всё равно она оставалась плохой. Каким было правильное глобальное решение?
Мы сделали вот так:
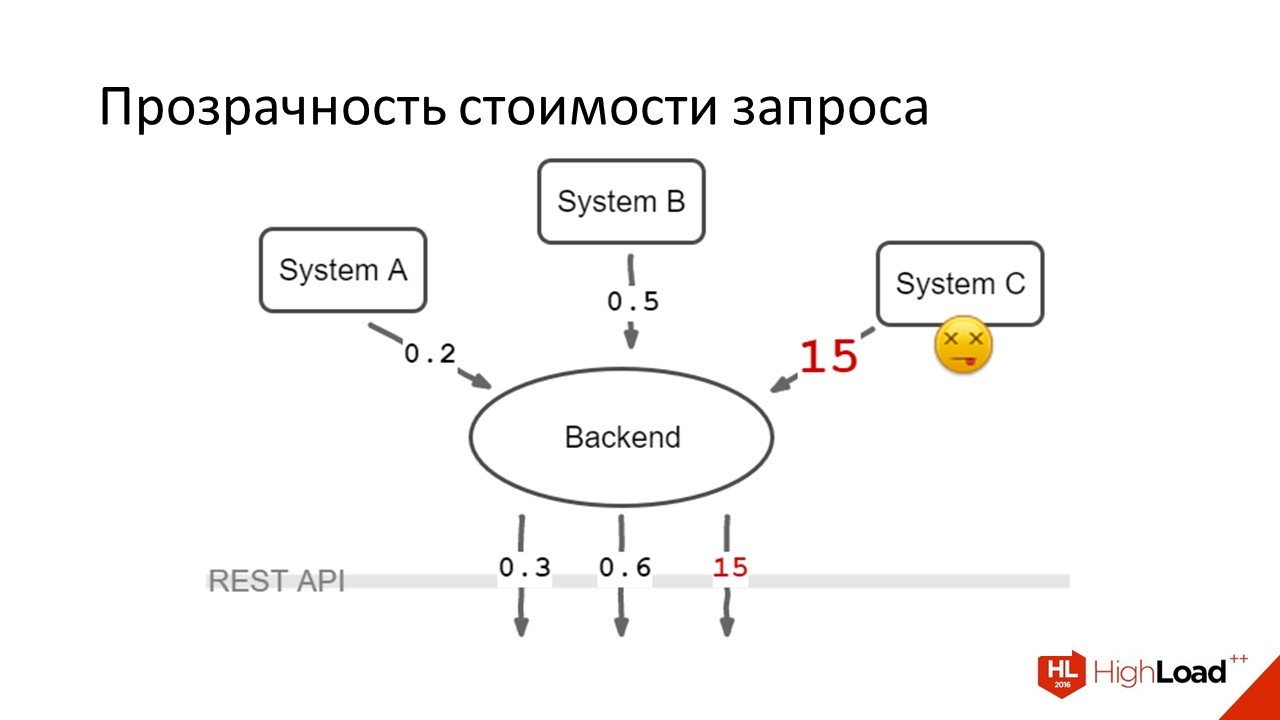
Через REST API уходили запросы в которых было написано: клиент передавал данные из какой системы он хочет получить, уходило три запроса в параллель, данные агрегировались на клиенте. Получилось, что те 80% пользователей, которым данных из системы A и B было достаточно чтобы работать — они были счастливы. Те пользователи (20%) кому данные из системы С тоже нужны были — они продолжали страдать. Но страдания 20% гораздо лучше страдания абсолютно всех.
Какие идеи хочется проиллюстрировать этим кейсом
Этот тот случай, когда удалось для всех очень сильно ускорить.
Во-первых, оптимизация, часто — это дополнительная работа, это ухудшение кода. С точки зрения сложности понятно, что агрегировать данные на фронтенде сложнее — нужно делать параллельные запросы, нужно обрабатывать ошибки, нужно размножить на все наши фронтенды бизнес логику по агрегации данных.
В случае, когда мы работаем с тяжелым сценарием, где производительность критична для пользователя — это иногда необходимо. Именно поэтому так важно мерить производительность, потому что, если такое геройство начать совершать в любом месте где будет чуть медленнее, можно потратить очень много усилий зря. Это была первая мысль.
Вторая мысль. Есть замечательный принцип инкапсуляции, который говорит о том, что «мы должны скрывать незначимые детали за API и не показывать их клиенту».
Если мы хотим иметь быструю систему — мы не должны инкапсулировать стоимость выполнения операций. В ситуации, когда у нас есть абстрактное API, которое возвращает только все данные сразу и он может сделать это только очень дорого и мы хотим иметь быстрый клиент. Нам пришлось принцип инкапсуляции в данном месте сломать и сделать так, чтобы у нас была возможность отправить дешёвые запросы и была возможность дорогой запрос. Это были разные параметры одного вызова.
Хочется рассказать несколько мыслей про использование Pagination, про плюсы/минусы, накопленный опыт.
В эпоху web 1.0 очень много где можно было увидеть интерфейсы, которые показывают 10–20–50 записей и листалку страниц бесконечную: поисковые системы, форумы, что угодно.
К сожалению, эта штука пролезла в очень большое количество API. Почему к сожалению? Несмотря на то, что решение старое и проверенное — все более-менее знают, как с ним работать, там есть проблемы, о которых хочется рассказать.
Во-первых, вспомните экран выдачи Яндекса, который говорит, что нашлось 500 тысяч результатов за 0,5 секунды.

Цифры из воздуха — я уверен, Яндекс работает быстрее.
Один из кейсов, которые я видел, когда для того чтобы показать первую страницу, выборка данных стоила 120 миллисекунд —, а подсчет общего количества данных, которые попадают в критерии поиска стоил 450 миллисекунд. Внимание вопрос: для пользователя, правда информация о том, что всего результатов n — она в 4 раза важнее чем данные первой страницы?
Почти всегда нет. Хочется, чтобы если для пользователя данные не очень важны, то их получение было либо максимально дешёвым, либо эти данные надо исключать из интерфейса.
Тут можно этот кейс значительно улучшить тем, что отказаться от показа общего количества результатов — написать результатов много. Допустим, был случай, когда мы примерно в такой ситуации, вместо того чтобы писать, что «показывается 100 результатов из 1200» начали писать, что «общее количество результатов больше 100, пожалуйста уточните критерии поиска, если вы хотите увидеть что-то ещё».
Это не во всех системах так, поэтому меряйте прежде чем что-то менять.
Какие еще есть проблемы
С точки зрения usability, даже когда мы не ходим на сервер за следующей страницей — всё равно в хорошо выстроенных пользовательских интерфейсах не так часто пользователю нужно ходить куда-то далеко за данными.
Например, поход на вторую страницу Google и Яндекса лично у меня происходит только от отчаяния, когда я искал, не нашёл, попробовал сформулировать по-другому, тоже не нашел, попробовал третий, четвертый вариант — и тут я уже могу залезть на вторую страницу этих вариантов поиска, но я не помню, когда я последний раз это делал.
Кто за последний месяц хоть раз ходил на вторую страницу Google или Яндекса? Довольно много людей.
В любом случае, первая-вторая страница. Может быть нужно просто больше данных показать сразу, но нет никаких причин по которому вашему пользователю в нормально сделанном интерфейсе может понадобиться ходить допустим на 50-ую страницу. Есть вопросы с usability у пагинации.
Ещё одна очень больная проблема. Что вы будете делать, если набор данных попадающих в выборку поменялся между запросами страниц?
Это особенно актуально для приложений, у которых не такая надежная сеть или частый офлайн.
На мобильных вообще тяжело. На вебе, который затачивается под возможность работы в офлайн, тоже нелегко. Там начинается очень кучерявая и своеобразная логика по тому, как нам инвалидировать данные предыдущих страниц — что нам делать если данные первой страницы частично показываются на второй, как нам эти страницы сшить. Это сложно.
Есть много статей на тему как это делать и решение есть. Просто хочется предупредить, что, если вы идете в эту сторону — знайте эту проблему и заранее оцените во что вам встанет её решение. Оно довольно неприятное.
Во всех случаях, где мне приходилось работать, мы обычно от пагинации либо отказывались на этапе проектирования, либо делали грубый прототип, а потом переделывали на что-нибудь. Удалось уйти от проблемы до того, как начали сталкиваться с ней.
Подведём итоги
Хочется сказать, что пагинация особенно в форме бесконечного скроллинга вполне уместна в ряде ситуаций. Например, мы делаем какую-то новостную ленту. Лента ВКонтакте, где пользователь мотает её сверху вниз и читает в развлекательных целях, без попытки найти что-то конкретное — это прямо один из тех случаев где постраничная загрузка, с бесконечным скроллингом, будет замечательно работать.
Если у вас какой-то бизнес интерфейс и там речь не идет о потоке событий —, а речь идёт о поиске объектов с которыми надо взаимодействовать, объектов более-менее долгосрочно живущих. Скорее всего есть другое UI решение которое позволяет вам не иметь этих проблем с API и которое позволяет сделать вам более удобный интерфейс.
Хотите идти в сторону пагинации? Подумайте о том, чего будет стоить выбор общего числа элементов и можно ли без них обойтись. И подумайте о том, как вам заниматься вопросами синхронизации, изменяющимися между страницами данных.
Давайте поговорим о следующей проблеме — она очень простая.
У нас есть 10 элементов интерфейса, которые мы показываем пользователю:

В нормальном случае мы сделаем 1 запрос, получим все данные, покажем.
Что произойдет в случае, когда мы не подумали?
Мы сделаем 1 запрос за списком, дальше сходим отдельно за каждым элементом списка, эти данные на клиенте помёржим, покажем.
Проблема очень стара — она пришла еще из SQL баз данных, возможно, до SQL она тоже где-то существовала. Она продолжает существовать и сейчас.
Тут две очень простых причины почему это происходит.
Либо мы делали API и не подумали о том какой будет интерфейс и поэтому в API не включили достаточно данных или мы, делая интерфейс, не подумали какие данные нам может дать API и включили слишком много. Решения тоже довольно простые.
Мы либо добавляем данные в запрос и учимся получать то, что нам нужно для показа одним запросом, либо мы какие-то данные по отдельным объектам убираем либо в страницу деталей, либо делаем какую-нибудь правую панель, где выбираешь элемент и тебе подгружаются и показываются данные.
Нет кейсов, когда имеет смысл работать вот так и списки делать больше одного запроса за данными.
Давайте представим, что мы добавили очень много данных. Мы сразу столкнёмся со следующей проблемой:

У нас есть список. Для отображения его нам нужно одно количество данных, но мы реально загружаем в 10 раз больше. Почему так происходит?
Очень часто API дизайнится по принципу того, что в списки мы отдаем ровно те же представления объектов, что при детальном запросе. У нас есть какая-нибудь страница детали объекта на 10 экранов, с кучей атрибутов и всё это мы получаем одним запросом. В списке объектов мы используем такое же представление. Чем это плохо?
Тем что такой запрос может быть дороже и тем, что мы очень много данных качаем по сети, что особенно актуально для всяких мобильных приложений.
Как лично я с этим боролся
Делается API, которое позволяет отдавать по каждому объекту такого типа две версии: краткую и полную. Запрос списка в API отдаёт краткие версии и это нам хватает чтобы отрисовать интерфейс. Для страницы детали мы запрашиваем полную.
Тут важно чтобы в каждом объекте был признак того, кратную или полную версию он представляет. Потому что, если у нас очень много необязательных полей, бизнес логика по определению «есть ли у нас уже полная версия объекта или её надо запрашивать» может стать довольно кучерявой. Этого не нужно.
Нужно просто поле, которое можно проверить.
Давайте поговорим о том, как кэшировать?
В общем случае, для той экосистемы которую я описал: бэкенд, REST API, фронтенд. Есть три уровня кэширования. Что-то кэширует сервер, что-то можно кэширование на HTTP уровне, что-то можно кэшировать на клиенте.
С точки зрения фронтенда разработчика — серверного кэша как бы нет. Это просто какая-то хитрая магия, которой серверные разработчики пользуются чтобы бэкенд работал быстро.
Давайте поговорим о том, на что мы можем влиять.
HTTP-кэш. Чем он хорош?
Он хорош тем, что это старый общепринятый стандарт, который все знают, который реализует почти все клиенты. Мы получаете готовую реализацию как на клиенте, так и сервере, без необходимости писать какой-то код. Максимум, что можем потребоваться — это что-то донастроить.
В чем проблема
HTTP-кэш довольно ограничен, в том плане, что есть стандарты и если вашего случая в нём не предусмотрено — то извините, вы его не сделаете. Его надо делать программно в таком случае.
Ещё одна особенность. Инвалидация данных в HTTP-кэше происходит через серверный запрос, что можем несколько замедлить работу, особенно на мобильных сетях. В принципе, когда у вас свой кэш у вас этой проблемы нет.
Ряд ключевых слов, которые надо знать по работе HTTP-кэша. У меня не очень много времени. Просто скажу — читайте спецификацию, там всё есть.
Про клиентский кэш. У него плюсы/минусы ровно обратные. Это максимально быстрый по времени ответа, максимально гибкий кэш —, но его надо писать. Его надо писать так, чтобы он более-менее одинаковым образом работал на всех ваших клиентах. Кроме того — нет готовой спецификации, где всё написано, надо что-то придумывать.
Общая рекомендация
Если для вашего сценария HTTP-кэш подходит, используйте его — если нет, то кэшируйте на клиенте с четким пониманием, что это некоторые дополнительные затраты.
Несколько простых способов клиентского кэширования, которые лично приходилось использовать.
Всё, что можно вычислить чистой функцией — можно закэшировать набором аргументов и использовать их как ключ к вычисленному значению. В Lodash есть функция memoize (), очень удобно, всем рекомендую.
Дальше — есть возможность на транспортном уровне. То есть у вас какая-нибудь библиотека, которая делает REST запросы и обеспечивает вам data abstraction layer. Есть возможность на её уровне написать кэш, в фоне сложить данные в память или local storage и при следующем запросе за ними не ходить, если они там есть.
Я не рекомендую это делать, потому что на моём опыте выяснилось, что мы по сути дублируем HTTP-кэш и пишем сами дополнительный код, не имея никаких плюсов — зато имея кучу проблем, багов, несовместимость версий кэша, проблемы с инвалидацией и кучу других прелестей. При этом такой кэш, если он прозрачный и делается на транспортном уровне, он ничего не даёт относительно HTTP.
Самодельный программный кэш, который позволяет вам спросить есть ли у него данные, позволяет вам инвалидировать что-то — хорошая штука. Требует некоторых усилий в реализации, но позволяет вам очень гибко всё делать.
Наконец, та вещь, которую настоятельно рекомендую. Это In-memory база — когда у вас данные не просто хаотично разбросаны во фронтенд приложении, а есть какое-то единое хранилище, которое обеспечивает вам наличие только одной копии всех данных и которое позволяет вам писать какие-то простые запросы. Тоже очень удобно. Тоже хорошо работает, как стратегия кэширования.
Несколько слов о том, как инвалидировать клиентский кэш.
Во-первых, обычный TTL. У каждой записи есть время жизни, время кончилось — запись протухает.
Можно поднять веб-сокеты и слушать события сервера. Но надо помнить, что этот веб-сокет может отвалиться, а мы об этом узнаем далеко не сразу.
Ну и наконец — можно слушать какие-то интерфейсные вещи слушать. Например, если мы в веб-банке заплатили за свой мобильный телефон с карточки, наверное, кэш, в котором баланс этой карточки, хранится можно инвалидировать.
Такие вещи тоже позволяют вам инвалидировать клиентский кэш.
Надо помнить одну вещь: всё это ненадежно! Истинные данные живут только на сервере!
Не надо пытаться играть в мастер-репликацию при разработке фронтенд приложений.
Это производит очень много проблем. Помните, что данные на сервере — и ваша жизнь станет проще.
Несколько простых вещей, которые не попали в другие пункты
Что мешает быстрей фронтенд с точки зрения API?
Зависимость запросов, когда мы не можем отправить следующий запросов без результатов от предыдущего. То есть, в том месте где мы могли бы отправить три запроса в параллель — мы вынуждены получить результат от первого, обработать, из них мы соберём url второго запроса, отправим, обработаем, соберём url третьего запроса, отправим, обработаем.
Мы получили тройной latency — там, где мог бы быть одинарный. На ровном месте. Не надо такого делать.
Данные в любом формате, кроме JSON. Сразу говорю, что это касается только веба — на мобильных приложениях всё может быть сложнее. На вебе нет ни одной причины использовать не JSON-данные в REST API.
Наконец, какие-то вещи, когда мы нарушаем семантику HTTP кэширования. Например, у нас один и тот же ресурс имеет несколько разных адресов в разных сессиях, поэтому у нас не работает кэширование. Если этого всего нет, то мы не имеем ряд простых проблем и можем больше времени потратить на то, чтобы наше приложение стало лучше.
Давайте подведём итоги
Как сделать API хорошим?
- Хороший API проектируется всеми командами его использующими и разрабатывающими. С учетом их общих интересов.
- Мы сначала меряем скорость приложения, а потом занимается оптимизацией.
- Мы позволяем делать через API не только дорогие — абстрактные запросы, но и дешёвые конкретные.
- Мы проектируем структуру данных API исходя из структуры UI чтобы данных было достаточно, но не было сильно лишних.
- Мы правильно пользуемся кэшами и мы не делаем каких-то простых ошибок, о которых я рассказал.
На этом всё. Задавайте вопросы?
