Как я сделал самый быстрый в мире файловый сервер

Задача — среди множества файлов найти на диске конкретный и отдать его по HTTP с заголовками «content-encoding», «mime-type» и «content-lenght». И сделать это как можно быстрее — на локальном хосте, чтобы не уткнуться в физические барьеры. Нас интересует скорость ради скорости.
В качестве веб-сервера будем использоваться Kestrel, .NET 7 RC 1, minimal API и F#. Финальная, оптимизированная версия есть и для C#.
Старт
let p =
(Directory.GetCurrentDirectory(), "wwwroot")
|> Path.Combine
WebApplicationOptions(WebRootPath = p)
|> WebApplication.CreateBuilder
|> function
| prod when prod.Environment.IsProduction() ->
prod.WebHost.UseKestrel(fun i ->
i.ListenAnyIP(5001)
i.AddServerHeader <- false)
|> ignore
prod.Logging.ClearProviders() |> ignore
prod
| dev ->
dev.Logging.AddConsole().AddDebug() |> ignore
dev
|> fun b -> b.Build()
|> fun w ->
w.UseFileServer() |> ignore
w.Run()
Самый простой способ запустить файловый сервер на дотнете — это использовать встроенный в kestrel файловый сервер. Код вы видите выше.
Для снятия дополнительных данных — используется BenchmarkDotnet с аппаратными счётчиками.
Чтобы исключить неточности связанные с фрагментацией памяти, все бенчи делались сразу после перезагрузки компьютера. Заодно я сразу отрубил заголовок сервера, чтобы не мешал замерам.
Для сбора данных по пропускной способности в кандидатах были Autocanon, K6 и Bombardier. Bombardier оказался самым быстрым, поэтому в дальнейшем, данные о пропускной способности буду получить им.
| | K6 | Autocannon | Bombardier |
|----------|------|:-----------|------------|
| Avg. RPS | 4704 | 4596 | 6415.2 |
Для тестирования применялись файлы размером 0 байт, 3,5КБ, 22КБ, 31КБ, 130 и 417КБ в 1, 8 и 125 потоков.
Таблицу с результатами. Публиковать нет смысла, я лишь выделю интересные детали.
Вот ссылка на репозиторий, код к каждому бенчмарку выделен в отдельный проект под своим именем.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |Загружаем контент в оперативную память
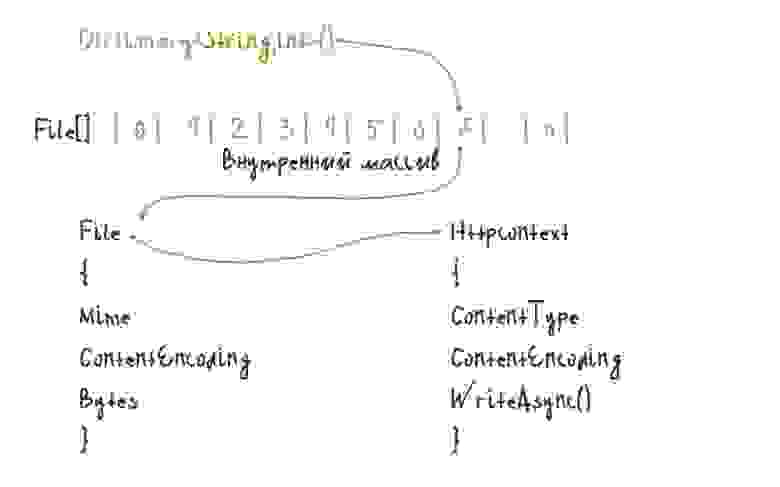
type File =
{ Bytes: byte array
ContentEncoding: StringValues
Mime: string }
let p =
(Directory.GetCurrentDirectory(), "wwwroot")
|> Path.Combine
let extractMime x = "image/webp"
let extractFileName (x: string) = x.LastIndexOf "\\" + 1 |> x.Substring
let dict = Dictionary()
p
|> Directory.GetFiles
|> Seq.iter (fun i ->
(extractFileName i,
{ Bytes = File.ReadAllBytes i
ContentEncoding = StringValues "none"
Mime = extractMime i })
|> dict.Add)
Dictionary — самая быстрая коллекция в дотнете, поэтому её буду использовать для нахождения файлов. Загружаться байты будут во время старта приложения.
Простоты ради, Content-Type пусть будет — «image/webp», а Content-Encoding — «none».
Закатываем всё это в рекорд и добавляем в Dictionary.
type FileResult(mime, encoding, stream: byte array) =
interface IResult with
member this.ExecuteAsync(ctx: HttpContext) =
ctx.Response.ContentType <- mime
ctx.Response.Headers.ContentEncoding <- encoding
ctx.Response.ContentLength <- stream.LongLength
ctx.Response.Body.WriteAsync(stream, 0, stream.Length)
let FileResult x = FileResult x :> IResult
type IResultExtensions with
member this.FileResult = FileResult
let file (i: string) =
match dict.TryGetValue i with
| false, _ -> Results.NotFound()
| true, x -> Results.Extensions.FileResult(x.Mime, x.ContentEncoding, x.Bytes)
// ......
|> fun b -> b.Build()
|> fun w ->
w.MapGet("/{i}", Func(fun i -> Files.file i))
|> ignore
w.Run()
Я сделал всё по гайду, заимплементил IResult, заэкстендил интерфейс, всё, как написано тут.
Максимальный RPS на файле размером в 0 байт вырос до 26852,44, файл размером 31КБ в один поток скачивается 5858.85 раз с общей скоростью 573,77МБ/с, и 13869.81 раз со скоростью 5,2ГБ/с в 125 потоков.
Это 4,6 гигабит в один поток и 41 гигабит соответственно.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |Таблицы
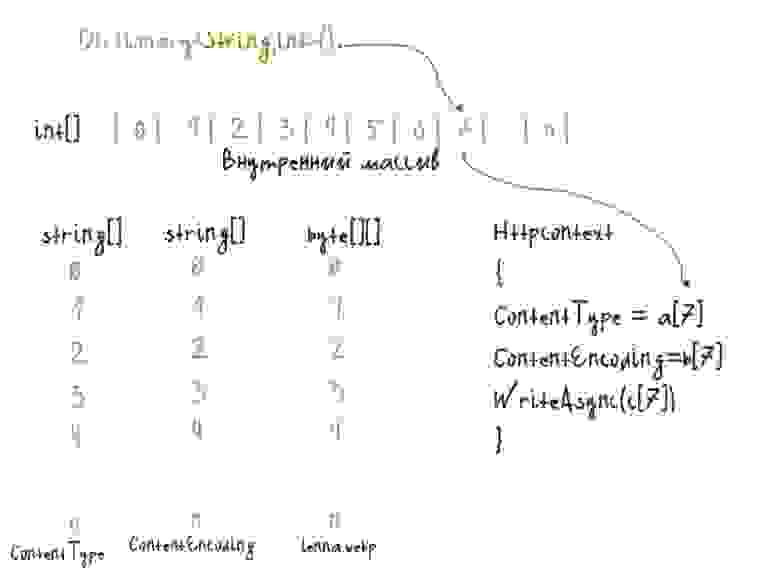
Можно разбить коллекцию объектов на таблицы, где поля этих объектов буду помещены в разные массивы. Тогда в Dictionary мы просто получаем индекс, а значения полей разобранного объекта — берём из разных колонок.
Переход по индексу почти такой же быстрый, как и по референсу, но теперь компьютеру не нужно скакать от одной ссылки к другой. Таким образом, можно сэкономить один переход по ссылкам за одну операцию.
Фундаментально, мало что изменилось, мы всё ещё обращаемся в разные места в памяти, просто адреса берём их из тела функции.
let mimes = files |> Array.map extractMime
let encodings =
Array.init p.Length (fun _ -> StringValues "none")
let bytes =
files |> Array.map File.ReadAllBytes
// ......
let file (i: string) =
match dict.TryGetValue i with
| false, _ -> Results.NotFound()
| true, idx -> Results.Extensions.FileResult(mimes.[idx], encodings.[idx], bytes.[idx])
RPS увеличился на 100 и 150 для 1 и 125 потоков соответственно.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |
| Tables | 51.56 us | 0.931 us | 0.870 us | 101 | 185 | 16,119 |Не все методы одинаковы
▍ 1. Убираем расширение интерфейса
let FileResult x = FileResult x :> IResult
//type IResultExtensions with
// member this.FileResult = FileResult
let file (i: string) =
match dict.TryGetValue i with
| false, _ -> Results.NotFound()
//| true, idx -> Results.Extensions.FileResult(mimes.[idx], encodings.[idx], bytes.[idx])
| true, idx -> FileResult(mimes.[idx], encodings.[idx], bytes.[idx])
Виртуальные вызовы, вызовы интерфейсов, и абстрактных классов дорогие, вы, наверное, слышали это. Ситуация с девиртуализацией никак не изменилась и посей день. Если убрать обращение через расширение интерфейса, то можно сэкономить пару тактов.
Максимальный RPS вырос до ещё на 271.2, до 27131.54. Пропускная способность в один поток не изменилась, зато раздача в 125 потоков ускорилась на 30МБ/с.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |
| Tables | 51.56 us | 0.931 us | 0.870 us | 101 | 185 | 16,119 |
| Tables_WithoutInterfaces | 52.04 us | 0.640 us | 0.599 us | 108 | 175 | 16,251 |▍ 2. Task вместо IResult
let file (i: string) (ctx: HttpContext) =
match dict.TryGetValue i with
| false, _ ->
ctx.Response.StatusCode <- 404
Task.CompletedTask
| true, idx ->
ctx.Response.ContentType <- mimes.[idx]
ctx.Response.Headers.ContentEncoding <- encodings.[idx]
let b = bytes.[idx]
ctx.Response.ContentLength <- b.LongLength
ctx.Response.Body.WriteAsync(b, 0, b.Length)
Если делать через IResult, то каждый вызов аллоцирует новый объект этого IResult. Если заменить этот метод на Task, то можно выиграть пару тактов.
Так мы ускоряемся ещё на 410.53 RPS, до 27542.07. Раздача в один поток ускорилась на 10МБ/с, а раздача в 125 потоков, на 16МБ/с.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |
| Tables | 51.56 us | 0.931 us | 0.870 us | 101 | 185 | 16,119 |
| Tables_WithoutInterfaces | 52.04 us | 0.640 us | 0.599 us | 108 | 175 | 16,251 |
| Tables_Task | 51.40 us | 0.757 us | 0.708 us | 114 | 190 | 16,730 |▍ 3. Только Httpcontext
//let extractFileName (x: string) = x.LastIndexOf "\\" + 1 |> x.Substring
let extractFileName (x: string) =
"/" + (x.LastIndexOf "\\" + 1 |> x.Substring)
// ......
//let file (i: string) (ctx: HttpContext) =
let file (ctx: HttpContext) =
//match dict.TryGetValue i with
match dict.TryGetValue ctx.Request.Path.Value with
| false, _ ->
ctx.Response.StatusCode <- 404
Task.CompletedTask
| true, idx ->
ctx.Response.ContentType <- mimes.[idx]
ctx.Response.Headers.ContentEncoding <- encodings.[idx]
let b = bytes.[idx]
ctx.Response.ContentLength <- b.LongLength
ctx.Response.Body.WriteAsync(b, 0, b.Length)
Функция возвращающая таск, хоть и быстрее IResult, она аллоцирует String на каждый новый вызов. Мы можем брать путь из HttpContext«а, и работать с ним напрямую.
И bombardier не показывает никакого измеримого результата.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |
| Tables | 51.56 us | 0.931 us | 0.870 us | 101 | 185 | 16,119 |
| Tables_WithoutInterfaces | 52.04 us | 0.640 us | 0.599 us | 108 | 175 | 16,251 |
| Tables_Task | 51.40 us | 0.757 us | 0.708 us | 114 | 190 | 16,730 |
| Tables_TaskNoAlloc | 50.95 us | 0.614 us | 0.575 us | 105 | 184 | 16,423 |▍ 4. Своя мидлварь

Стандартный роутинг, осуществляется сопоставлением двух строк, пути из URL и HTTP метода. Такое количество проверок для файлового сервера, объективно избыточно.
Можно написать свою мидлварь, которая будет перехватывать и обрабатывать подходящие запросы. Это быстрее, но мы больше не отличаем PUT, DELETE и POST, всё будет обрабатываться как GET, про CORS можно забыть.
Для создания своей мидлвари нам на выбор предлагаю два оверлоада, «Func
Недостаток первого в том, что он каждый вызов аллоцирует новый Func, поэтому я выбираю оверлоад с RequestDelegate.
Вот так выглядит готовая мидлварь:
let file (ctx: HttpContext) ( next: RequestDelegate) =
match dict.TryGetValue ctx.Request.Path.Value with
| false, _ -> next.Invoke ctx
| true, idx ->
ctx.Response.ContentType <- mimes.[idx]
ctx.Response.Headers.ContentEncoding <- encodings.[idx]
let b = bytes.[idx]
ctx.Response.ContentLength <- b.LongLength
ctx.Response.Body.WriteAsync(b, 0, b.Length)
Вот так выглядит её регистрация:
|> fun b -> b.Build()
|> fun w ->
w.Use Files.file |> ignore
w.UseRouting() |> ignore
w.Run()
Опустив лишние проверки, RPS увеличился на 985.48, до 28527.55. Раздача файлов в 1 поток ускорилась ещё на 6МБ/с, а в 125 потоков, на 21МБ/с.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |
| Tables | 51.56 us | 0.931 us | 0.870 us | 101 | 185 | 16,119 |
| Tables_WithoutInterfaces | 52.04 us | 0.640 us | 0.599 us | 108 | 175 | 16,251 |
| Tables_Task | 51.40 us | 0.757 us | 0.708 us | 114 | 190 | 16,730 |
| Tables_TaskNoAlloc | 50.95 us | 0.614 us | 0.575 us | 105 | 184 | 16,423 |
| Tables_Middleware | 48.95 us | 0.977 us | 1.045 us | 109 | 181 | 16,031 |Знакомьтесь — Unsafe
▍ Unsafe.As

Эта штука позволяет нам переинтерпретировать одни данные как другие. Например, можно прочитать string как byte[], не без ограничений.
Если взять строку и попытаться её перечислить как массив, то мы сможем перечислить его по индексам, через for или foreach, но если запустить enumerator, то приложение упадёт с (Fatal error. Internal CLR error. (0×80131506).
Тут нужно знать, какие методы каких данных совместимы друг с другом. Энуметарторы string и 'T[] несовместимы.

Тоже самое касается структур. Мы не можем представить int64 как byte[], однако каждый байт в этом int64 можно прочитать отдельно, если переинтерпретировать int64 как другую структуру.
Перед использованием убедитесь, что обе структуры одинакового размера и разложены так, как надо.
▍ Unsafe.Add

[]
let MutateString () =
let mutable s = "abcde"
let mutable res: char array = Unsafe.As &s
let ref =
&MemoryMarshal.GetArrayDataReference res
// заголовок массива это 8 байт
// заголовок строки это 4 байта
// нужно сдвинуть поинтер влево
// ещё на 2 char'a, то есть на 4 байта
for i = -2 to s.Length - 3 do
Unsafe.Add(&ref, i) <- '-'
printfn "%s" s
Assert.AreEqual("-----", s)
Тут начинается магия работы с поинтерами. Вот этот код может мутировать иммутабельное, представив string как, char[].
Сместив поинтер ещё на 4 байта влево, можно читать и редактировать заголовок, изменяя длину строки. В этом примере я изменил содержимое строки.
Больше можно не заморачиваться с voidptr«ами и intptr«ами. К тому же — такой способ просто быстрее, чем использование fixed. Так вот, к чему я это?
Закатываем всё в один массив
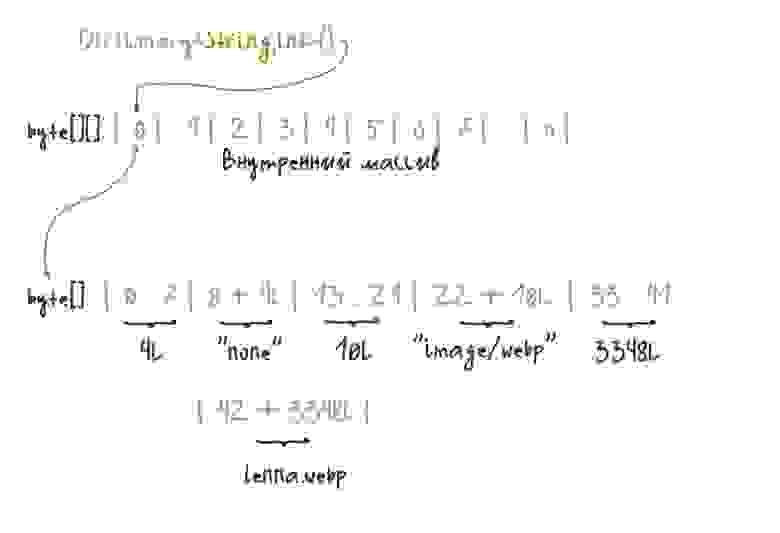
Линия кэша скайлейков — 64 байта, 64 байта можно загрузить в кэш за один поход в оперативную память. Как только мы обработаем загруженные данные — к тому времени префетчер уже начнёт загружать следующие. Всё записано в строчку и читается очень быстро.
Давайте представим себе, что первые 8 байт массива это long обозначающий длину заголовка Content-Encoding, последующие N+1 байт — это длина заголовка Content-Type, следующие за ними N+1 байты это Content-Length и массив байтов за ним это байты файла lenna.webp. Как на картине.
let enc = UTF8Encoding false
[]
type LongBytes =
{ A: byte
B: byte
C: byte
D: byte
E: byte
F: byte
G: byte
H: byte }
let inlineFileBytes =
fun f ->
let mimeBytes =
extractMime f |> enc.GetBytes
let mutable mimeBytesLongLength =
mimeBytes.LongLength
let mimeLen: LongBytes =
Unsafe.As(&mimeBytesLongLength)
let encodingBytes = "none" |> enc.GetBytes
let mutable mimeBytesLongLength =
encodingBytes.LongLength
let encLen: LongBytes =
Unsafe.As(&mimeBytesLongLength)
let mutable fileBytes = File.ReadAllBytes f
let mutable fileBytesLongLength =
fileBytes.LongLength
let fileLen: LongBytes =
Unsafe.As(&fileBytesLongLength)
[| [| mimeLen.A
mimeLen.B
mimeLen.C
mimeLen.D
mimeLen.E
mimeLen.F
mimeLen.G
mimeLen.H |]
mimeBytes
[| encLen.A
encLen.B
encLen.C
encLen.D
encLen.E
encLen.F
encLen.G
encLen.H |]
encodingBytes
[| fileLen.A
fileLen.B
fileLen.C
fileLen.D
fileLen.E
fileLen.F
fileLen.G
fileLen.H |]
fileBytes |]
|> Array.concat
|> Array.pin
Переинтерпретировать структуры как коллекции мы не можем, поэтому каждый байт Int64 приходится забивать вручную в конструктор массивов.
let file (ctx: HttpContext) (next: RequestDelegate) =
match dict.TryGetValue ctx.Request.Path.Value with
| false, _ -> next.Invoke ctx
| true, arr ->
let spanRef =
&arr.AsSpan().GetPinnableReference()
let mimeLen: int32 =
Unsafe.ReadUnaligned(&spanRef)
ctx.Response.ContentType <- enc.GetString(arr, 8, mimeLen)
let encStart = mimeLen + 8
let encLen: int32 =
Unsafe.ReadUnaligned(&Unsafe.Add(&spanRef, encStart))
ctx.Response.Headers.ContentEncoding <- enc.GetString(arr, encStart + 8, encLen)
let fileStart = encStart + encLen + 8
let mutable fileSize: int64 =
Unsafe.ReadUnaligned(&Unsafe.Add(&spanRef, fileStart))
ctx.Response.ContentLength <- fileSize
ctx.Response.Body.WriteAsync(arr, fileStart + 8, Unsafe.As(&fileSize))
Чтение происходит в том же порядке, как мы это массив и строили. Читаем первые 8 байт как длину заголовка и так далее, как на картинке выше.
Тестирование показало, что в массив лучше помещать long, а читать его как int, так быстрее, поэтому так и оставил.
Что ещё интересно, на этом этапе Jit встроил буквально все вызовы прямо в функцию. ASM функции теперь представляет из себя длинное полотно длиной в 7030 байт. 175 встроенных вызовов. Вот это действительно серьёзно.
; Assembly listing for method Files:file(HttpContext,RequestDelegate):Task
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-1 compilation
; optimized code
; optimized using profile data
; rsp based frame
; fully interruptible
; with Dynamic PGO: edge weights are invalid, and fgCalledCount is 63369
; 63 inlinees with PGO data; 109 single block inlinees; 3 inlinees without PGO data
......
; Total bytes of code 7030
RPS увеличился ещё на 179.44, до 28706.99. Даже BenchmarkDotnet показывает улучшение.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |
| Tables | 51.56 us | 0.931 us | 0.870 us | 101 | 185 | 16,119 |
| Tables_WithoutInterfaces | 52.04 us | 0.640 us | 0.599 us | 108 | 175 | 16,251 |
| Tables_Task | 51.40 us | 0.757 us | 0.708 us | 114 | 190 | 16,730 |
| Tables_TaskNoAlloc | 50.95 us | 0.614 us | 0.575 us | 105 | 184 | 16,423 |
| Tables_Middleware | 48.95 us | 0.977 us | 1.045 us | 109 | 181 | 16,031 |
| InlineEverything | 49.97 us | 0.752 us | 0.666 us | 98 | 190 | 15,784 |Закатываем всё в один массив v2

Брать всё из одного места это быстро. Однако, при декодировании строк из байтов мы каждый раз создаём новую строку. Возможно, поэтому пропускная способность не увеличилась.
Давайте представим себе, что первые два байта массива это энумы, указывающие на Content-Encoding, и Content-Type, а байты с индексами 2 по 10 это long, обозначающий длину контента. Все индексы мы знаем заранее, они будут вкомпилены в функцию.
let file (ctx: HttpContext) (next: RequestDelegate) =
match dict.TryGetValue ctx.Request.Path.Value with
| false, _ -> next.Invoke ctx
| true, arr ->
ctx.Response.ContentType <- Unsafe.As &arr.[0] |> ContentType.toString
ctx.Response.Headers.ContentEncoding <-
Unsafe.As &arr.[1]
|> ContentEncoding.toStringValues
ctx.Response.ContentLength <- (Unsafe.As &arr.[2]: int64)
ctx.Response.Body.WriteAsync(arr, 10, Unsafe.As &arr.[2])
Получился очень лаконичный код. Лаконичность так же отразилась и на производительности. Тело вызова после рефакторинга похудело на 1904 байт, до 5126 байт.
; Assembly listing for method Files:file(HttpContext,RequestDelegate):Task
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-1 compilation
; optimized code
; optimized using profile data
; rsp based frame
; fully interruptible
; with Dynamic PGO: edge weights are invalid, and fgCalledCount is 83072
; 49 inlinees with PGO data; 96 single block inlinees; 3 inlinees without PGO data
......
; Total bytes of code 5126
RPS не увеличился, но скорость раздачи в один поток выросла на 26МБ/с, а в 125 потоков на 15МБ/с, что в общем счёте даёт нам 621,72МБ/с в один поток и 5,85ГБ/с в 125 потоков, а это без малого 5 и 46,8 гигабит в секунду соответственно.
BanchmarkDotnet показывает, что такой код, увы, менее дружелюбен к железу.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |
| Tables | 51.56 us | 0.931 us | 0.870 us | 101 | 185 | 16,119 |
| Tables_WithoutInterfaces | 52.04 us | 0.640 us | 0.599 us | 108 | 175 | 16,251 |
| Tables_Task | 51.40 us | 0.757 us | 0.708 us | 114 | 190 | 16,730 |
| Tables_TaskNoAlloc | 50.95 us | 0.614 us | 0.575 us | 105 | 184 | 16,423 |
| Tables_Middleware | 48.95 us | 0.977 us | 1.045 us | 109 | 181 | 16,031 |
| InlineEverything | 49.97 us | 0.752 us | 0.666 us | 98 | 190 | 15,784 |
| FsharpFinal | 48.85 us | 0.966 us | 2.405 us | 120 | 205 | 16,394 |Порт на C#

Эквивалентный код на F# и C#, как правило, компилят в один и тот же IL. Все оптимизации, которые я привёл, хорошо лягут и на наш C# проект, но есть различия.
В F#, Unsafe.As даёт возможность небезопасно кастить любую область памяти во что угодно и работать с ней как с любым типом. C# такие выкрутасы делать не даёт.
Unsafe.As был придуман для анбоксинга и в теории, должен работать только с референс тайпами, однако, об этом знает C# компилятор, F# этого не знает, поэтому работает с любой памятью так, как ты захочешь.
Работа с поинтерами тоже различается, Unsafe.Add в C# сдвигает поинтер на sizeof<’T>, где «T это тип, который указал пользователь.
F# манипулирует поинтерами как до переинтерпретации, сдвигая поинтер на sizeof<’T>, где «T это оригинальный тип элемента массива, различия как на картинке.
На этом различия между языками не заканчиваются, но это то, с чем я столкнулся, пока портировал.
ASM, который я получил в порте, на 208 байт длиннее, чем на F#. C# не даёт писать самый оптимальный код, поэтому производительность, ожидаемо, меньше.
В один поток, порт медленнее на 20МБ/с, и на 29МБ/с в 125 потоков. То есть версия на C# медленнее на 160 и 232 мегабит соответственно.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 170.10 us | 1.328 us | 1.243 us | 141 | 328 | 18,083 |
| InMemory | 51.67 us | 1.028 us | 1.142 us | 101 | 193 | 16,888 |
| Tables | 51.56 us | 0.931 us | 0.870 us | 101 | 185 | 16,119 |
| Tables_WithoutInterfaces | 52.04 us | 0.640 us | 0.599 us | 108 | 175 | 16,251 |
| Tables_Task | 51.40 us | 0.757 us | 0.708 us | 114 | 190 | 16,730 |
| Tables_TaskNoAlloc | 50.95 us | 0.614 us | 0.575 us | 105 | 184 | 16,423 |
| Tables_Middleware | 48.95 us | 0.977 us | 1.045 us | 109 | 181 | 16,031 |
| InlineEverything | 49.97 us | 0.752 us | 0.666 us | 98 | 190 | 15,784 |
| FsharpFinal | 48.85 us | 0.966 us | 2.405 us | 120 | 205 | 16,394 |
| CsharpFinal | 49.45 us | 0.985 us | 1.590 us | 112 | 189 | 16,469 |FULL PGO
Пока я занимался фундаментальными оптимизациями, я подло утаивал от вас секретную, быструю и надёжную оптимизацию, без которой мои результаты выглядят не так впечатляюще.
Эта штука, на основе данных с рантайма, умеет переставлять if/else и свитчи переставлять вызовы местами.
Функции сначала компилируется tier0 — неоптимизированный код со счётчиками для сбора профиля, а потом компилируется tier1, оптимизированный по профилю код.
DOTNET_ReadyToRun=0
Ready to run это форма ahead of time компиляции, ASM метода компилится заранее и не подлежит перекомпиляции Jit’ом.
Перекомпиляцию R2R метода на основе профиля хотят добавить в будущих версиях дотнета, а пока, R2R ради производительности нужно отключать.
DOTNET_TC_QuickJitForLoops=1
Циклы сразу компилируются в tier1. Чтобы оптимизировать циклы по профилю, нужно сначала компилировать их в tier0, отключить оптимизацию.
DOTNET_TieredPGO=1
Ну и включаем сам Profile Guided Optimization.
По отдельности — эти оптимизации не дают особо большого прироста, но вместе показывают значительные цифры.
Я отключил оптимизацию и прогнал бенчмарк ещё раз. Задержки увеличились, стало больше промахов в кэш и меньше правильных предсказаний ветвлений.
| Method | Mean | Error | StdDev | CacheMisses/Op | BranchMispredictions/Op | LLCReference/Op |
|------------------------- |----------:|---------:|---------:|---------------:|------------------------:|----------------:|
| Base | 184.60 us | 2.295 us | 2.147 us | 222 | 497 | 20,967 |
| InMemory | 56.59 us | 0.803 us | 0.751 us | 127 | 241 | 17,654 |
| Tables | 56.90 us | 1.033 us | 0.966 us | 124 | 252 | 17,465 |
| Tables_WithoutInterfaces | 56.36 us | 1.096 us | 1.606 us | 146 | 273 | 18,370 |
| Tables_Task | 56.60 us | 1.094 us | 1.074 us | 149 | 269 | 17,872 |
| Tables_TaskNoAlloc | 56.04 us | 1.094 us | 1.260 us | 158 | 280 | 17,682 |
| Tables_Middleware | 55.30 us | 0.831 us | 0.778 us | 137 | 261 | 17,711 |
| InlineEverything | 54.37 us | 1.087 us | 1.627 us | 144 | 260 | 17,949 |
| FsharpFinal | 53.97 us | 1.026 us | 1.098 us | 148 | 250 | 17,646 |
| CsharpFinal | 54.08 us | 1.053 us | 1.081 us | 156 | 267 | 17,466 |Тестим в продакшене
А продакшен для нас выглядит так же, как и для наших клиентов. Мы используем свои интерфейсы и свои апишки для деплоя наших программ.
Мы пилим вторую версию API и как закончим, возможно, расскажем обо всех улучшениях.
Ну, а пока она в разработке, я зашёл на сайт, купил дефолтную конфигурацию на Windows Server 2022. Вербозный процесс закупки серверов нам не нравится, мы сделаем лучше.

Тестирование провёл файлами 0КБ и 3,5КБ. Это не похоже на тестирование полезной нагрузкой, но пойдёт, чтобы выяснить степень моей оптимизации.
Чтобы сеть не стала узким местом, я подбирал количество потоков так, чтобы загрузка сети не превышала 85Мбс.
Тестировать будем только стоковый файловый сервер, самую первую и самую последнюю версию оптимизации. Вот результаты:
Тестирование файлом 3,5КБ:
| | Потоки | Утилизация ЦП | RPS | StdDev |
|------------------|---------|:--------------|---------|---------|
| Base | 22 | 52% | 2579.06 | 455.11 |
| InlineEverything | 16 | 15% | 2984.72 | 329.30 |
| FsharpFinal | 16 | 14% | 2990.31 | 315.68 |
Тестирование файлом 0 байт:
| | Потоки | Утилизация ЦП | RPS | StdDev |
|------------------|--------|:--------------|----------|---------|
| Base | 125 | 100% | 6607.07 | 1625.44 |
| InlineEverything | 125 | 47% | 20105.82 | 2929.65 |
| FsharpFinal | 125 | 44% | 19986.56 | 2860.83 |Послесловие
Вывода не будет. По большому счёту — я просто зря потратил время на оптимизацию неоптимизируемого. Лучше бы я траву на улице трогал, чесслово.
Но я узнал много нового и надеюсь, что и вы тоже узнали что-то полезное, новое, или хотя бы интересное.
Telegram-канал с полезностями и уютный чат

