Как я разогнал fail2ban* в тысячу раз с помощью SIMD
Fail2ban — утилита чрезвычайно полезная во многих случаях. Думаю, многие используют её для того, чтобы в автоматическом режиме блокировать особенно назойливых «посетителей». К сожалению, если входящий поток становится слишком большим, fail2ban теряет все свои полезные свойства, потому что разбор лога безнадёжно отстаёт от реальности.
Вот, например, лог nginx из 100 тысяч строчек fail2ban при самых простых настройках (failregex='^) разбирает порядка 45 секунд:
$ fail2ban-regex nginx.log '^'
Running tests
=============
Use failregex line : ^
Use log file : nginx.log
Use encoding : UTF-8
Results
=======
Failregex: 100000 total
|- #) [# of hits] regular expression
| 1) [100000] ^
`-
Ignoreregex: 0 total
Date template hits:
|- [# of hits] date format
| [100000] Day(?P<_sep>[-/])MON(?P=_sep)ExYear[ :]?24hour:Minute:Second(?:\.Microseconds)?(?: Zone offset)?
`-
Lines: 100000 lines, 0 ignored, 100000 matched, 0 missed
[processed in 44.48 sec] Честно разделив одно на другое, получаем производительность порядка 2250 строк в секунду. Возьмём эту цифру за основу.
(По факту разбор происходит медленнее из-за того, что fail2ban банит выявленных нарушителей в том же потоке, на время останавливая чтения лога)
Теперь наступает пора оптимизации. Для начала попробуем остаться вместе с fail2ban и посмотреть, на что же он тратит время. Поскольку fail2ban написан на Python, мы можем просто подключить cProfile без всяких модификаций кода:
$ python -m cProfile -s cumtime /usr/bin/fail2ban-regex nginx.log '^'
...
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 52.734 52.734 fail2ban-regex:26()
1 0.000 0.000 52.640 52.640 fail2banregex.py:784(exec_command_line)
1 0.000 0.000 52.638 52.638 fail2banregex.py:719(start)
1 0.411 0.411 52.636 52.636 fail2banregex.py:571(process)
100000 0.789 0.000 50.909 0.001 fail2banregex.py:448(testRegex)
100000 0.689 0.000 49.839 0.000 filter.py:601(processLine)
100000 3.741 0.000 39.767 0.000 datedetector.py:321(matchTime)
1595350 0.945 0.000 34.731 0.000 datetemplate.py:157(matchDate)
1695573 33.933 0.000 33.933 0.000 {method 'search' of '_sre.SRE_Pattern' objects}
100000 0.205 0.000 5.583 0.000 datedetector.py:469(getTime)
100000 0.187 0.000 5.305 0.000 datetemplate.py:323(getDate)
100000 1.826 0.000 4.858 0.000 strptime.py:172(reGroupDictStrptime)
100000 1.284 0.000 3.519 0.000 filter.py:811(findFailure)
1400000 0.564 0.000 1.479 0.000 utf_8.py:15(decode)
200000/100000 0.615 0.000 1.303 0.000 strptime.py:143(zone2offset)
100000 0.154 0.000 1.100 0.000 strptime.py:124(validateTimeZone)
100000 0.422 0.000 0.965 0.000 {method 'index' of 'list' objects и видим неутешительную картину. Большую часть времени fail2ban тратит на то, чтобы разобраться с форматом даты. К счастью, ему в этом можно помочь — нужно специфицировать, как именно эту самую дату разбирать. Сделать это можно с помощью параметра datepattern в файлах filter.d/*.conf, а для fail2ban-regex достаточно указать параметр -d.
Вывод fail2ban-regex
$ fail2ban-regex nginx.log -d '%d/%B/%Y:%H:%M:%S' '^ - [^ ]+ '
Running tests
=============
Use datepattern : %d/%B/%Y:%H:%M:%S : Day/MONTH/Year:24hour:Minute:Second
Use failregex line : ^ - [^ ]+
Use log file : nginx.log
Use encoding : UTF-8
Results
=======
Failregex: 100000 total
|- #) [# of hits] regular expression
| 1) [100000] ^ - [^ ]+
`-
Ignoreregex: 0 total
Date template hits:
|- [# of hits] date format
| [100000] Day/MONTH/Year:24hour:Minute:Second
`-
Lines: 100000 lines, 0 ignored, 100000 matched, 0 missed
[processed in 8.07 sec] Итого скорость разбора выросла почти в шесть раз — до почти 12,5 тысяч строк в секунду. К сожалению, такая скорость достижима только при разборе с помощью fail2ban-regex: как уже было сказано выше, в боевом режиме при непрерывном чтении логов это происходит несколько медленнее.
Перепишем на чём-то компилируемом
Поскольку на этом возможности fail2ban исчерпались, мне пришлось искать альтернативные способы. В последнее время я начал изучать Rust и пребываю в полном восторге от этого языка, поэтому выбрал его.
Для того, чтобы эффективно банить нарушителей, нужно хранить последние N запросов (или меньше) для каждого IP-адреса и проверять, не слишком ли часто они приходят. Здесь хорошо подходит кольцевой буфер с несложной логикой: добавляем таймстампы запросов по кругу, и когда накопим ring_size значений, то при добавлении возвращаем разницу времени вновь добавленного запроса и N запросов назад.
Код кольцевого буфера
struct RingBanBuffer {
timestamps: Vec>,
last_index: usize,
}
impl RingBanBuffer {
fn new(ring_size: usize) -> RingBanBuffer {
RingBanBuffer {
timestamps: vec![None; ring_size],
last_index: 0
}
}
fn add_query(&mut self, ts: i64) -> Option {
self.timestamps[self.last_index] = Some(ts);
self.last_index = (self.last_index + 1) % self.timestamps.len();
self.timestamps[self.last_index].map(|prev| ts - prev)
}
}
Собственно парсер логов тоже не слишком сложно написать: сначала выдираем интересующие нас поля (IP и дату) с помощью регулярного выражения, потом разбираем их. Если что-то не то, то возвращаем None.
Код парсера
use chrono::*;
use regex::Regex;
use std::net::IpAddr;
struct ParseResult {
ip: IpAddr,
timestamp: i64,
}
struct RegexParser {
regex: Regex,
date_format: String,
}
impl RegexParser {
fn new(regex: &str, date_format: &str) -> Self {
let re = Regex::new(regex).unwrap();
RegexParser {
regex: re,
date_format: date_format.to_string(),
}
}
fn parse_line(&self, line: &str) -> Option {
let caps = self.regex.captures(line)?;
let timestamp = DateTime::parse_from_str(&caps["DT"], &self.date_format).ok()?.timestamp();
let ip: IpAddr = caps["ip"].parse().ok()?;
Some(ParseResult { ip, timestamp })
}
} Для парсинга даты понадобится крейт chrono.
Осталось всё соединить воедино. Заведём HashMap, сопоставляющий IP-адреса с кольцевыми буферами и состоянием забаненности, читаем файл по строчкам и наполняем структуру данных. Когда весь файл прочитан, то печатаем список забаненных в stdout и статистику в stderr.
Код main
fn main() {
let reader = BufReader::new(File::open("nginx.log").unwrap());
let parser = RegexParser::new(
r"^(?P[\d.]+) - [^ ]+ \[(?P[^\]]+)\]",
"%d/%B/%Y:%H:%M:%S %z",
);
let mut requests: HashMap = HashMap::new();
let mut line_count = 0;
let start = std::time::Instant::now();
for line in reader.lines() {
line_count += 1;
if let Some(ParseResult { ip, timestamp }) = line.ok().and_then(|l| parser.parse_line(&l) ) {
let entry = requests.entry(ip).or_insert((RingBanBuffer::new(30), false));
if let Some(delta) = entry.0.add_query(timestamp) {
if delta < 30 {
entry.1 = true;
}
};
}
}
let elapsed = start.elapsed();
let banned_ips: Vec<&IpAddr> = requests.iter()
.filter(|(_, (_, banned))| *banned)
.map(|(k, _)| k)
.collect();
for ip in banned_ips.iter() {
println!("{}", ip);
}
eprintln!(
"elapsed {} ms, {} lines parsed, {} lines/s, banned = {}/{}",
(elapsed.as_micros() as f64 / 1e3),
line_count,
line_count as f64 / (elapsed.as_micros() as f64 / 1e6),
banned_ips.len(),
requests.len()
);
} Запускаем, проверяем…
elapsed 208.154 ms, 100000 lines parsed, 480413.5399752107 lines/s, banned = 565/3506480 тысяч строк в секунду, ускорение приблизительно в 38 раз, вау. Необходимую на практике скорость этот вариант уже перекрывает, но тут мне стало интересно, а насколько ещё это можно ускорить.
Разбор за линейное время
Прежде чем заниматься оптимизацией производительности, хорошо бы выяснить, а что же, собственно говоря, тормозит. Для профилирования кода можно воспользоваться прекрасным профайлером perf (у него есть целая wiki с документацией, а на Хабре есть введение в картинках).
$ perf record target/release/fast2ban > /dev/null
elapsed 206.889 ms, 100000 lines parsed, 483350.97564394434 lines/s, banned = 565/3506
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.031 MB perf.data (789 samples) ]
$ perf reportВидим вполне ожидаемую картину: большую часть времени занимает исполнение регулярного выражения, а именно — бэктрекинг.
 perf report в цвете выглядит лучше
perf report в цвете выглядит лучше
Как же так — думаю я — вроде же регулярные выражения должны отлично оптимизироваться с помощью преобразования в конечные автоматы, а здесь этого явно не происходит.
После некоторых поисков я выяснил, что преобразование регулярных выражений в конечные автоматы, конечно, возможно: это в некоторых случаях умеет и крейт regex. Есть специальный крейт regex-automata, но для регулярных выражений, которые содержат capturing groups, оно не работает.
Кроме этого, существует расширение конечных автоматов под названием Tagged DFA, и готовые решения на его основе, например, RE2C (оно даже может генерировать код на и Rust). Регулярное выражение здесь достаточно простое, поэтому нечто аналогичное здесь несложно написать и своими руками.
Заодно обратим внимание на бесполезный вызов decode_utf8 — nginx по умолчанию пишет логи в ASCII. Линейный разбор можно сделать и на сыром массиве байтов, преобразуя их в строки только для компилятора с помощью unsafe-функции from_utf8_unchecked, которая по факту делает ничего.
Всё содержимое строки до первого пробела будем считать IP-адресом, потом пропустим три байта, затем до следующего пробела, затем до [, а затем до ]. Код при этом можно писать достаточно высокоуровнево, пользуясь итераторами: компилятор эффективно их оптимизирует. Получается разбор «в лоб»:
parse_line_automata
use std::str::from_utf8_unchecked;
fn parse_line_automata(line: &[u8], date_format: &str) -> Option {
let mut iter = line.iter().enumerate();
let ip_end = iter.position(|(_, &c)| c == b' ')?;
let ip_str = unsafe { from_utf8_unchecked(&line[..ip_end]) };
let ip: IpAddr = ip_str.parse().ok()?;
let mut iter = iter
.skip(3)
.skip_while(|&(_, &c)| c != b' ')
.skip_while(|&(_, &c) | c != b'[');
let (date_start, _) = iter.next()?;
let date_end = iter.position(|(_, &c)| c == b']')?;
let date = unsafe { from_utf8_unchecked(&line[date_start+1..date_start+date_end+1]) };
let timestamp = DateTime::parse_from_str(date, date_format)
.ok()?
.timestamp();
Some(ParseResult { ip, timestamp })
} Единственное необходимое изменение в main: строки нужно получать теперь не с помощью lines(), а с помощью split(b'\n'), чтобы на выходе были не String, а [u8].
Увеличиваем тестовый файл до одного миллиона строк, запускаем…
elapsed 1269.688 ms, 1000000 lines parsed, 787595.0627240709 lines/s, banned = 1375/3506Получили дополнительный выигрыш чуть больше, чем в полтора раза. Интересно, что там в профиле?
 Теперь больше всего времени занимает разбор времени
Теперь больше всего времени занимает разбор времени
Теперь мы упёрлись в strftime, который, в общем-то, нам не нужен. Более того, для того, чтобы банить нарушителей вообще не нужно разбирать дату, а только время. При необходимости можно добавлять к отрицательным разницам 86400, но и без этого окажется потерянной максимум одна минута вокруг полуночи.
Для этого достаточно после второго пропускать символы аж до :, и не нужно искать закрывающую скобку, поскольку длина времени всегда составляет восемь символов.
Разбор только времени
fn parse_line_automata_time_only(line: &[u8], time_format: &str) -> Option {
let mut iter = line.iter().enumerate();
let ip_end = iter.position(|(_, &c)| c == b' ')?;
let ip_str = unsafe { from_utf8_unchecked(&line[..ip_end]) };
let ip: IpAddr = ip_str.parse().ok()?;
let mut iter = iter
.skip(3)
.skip_while(|&(_, &c)| c != b' ')
.skip_while(|&(_, &c)| c != b':');
let (date_start, _) = iter.next()?;
let time = unsafe { from_utf8_unchecked(&line[date_start + 1..date_start + 9]) };
let timestamp = NaiveTime::parse_from_str(time, time_format)
.ok()?
.num_seconds_from_midnight() as i64;
Some(ParseResult { ip, timestamp })
} Результаты запуска радуют:
elapsed 699.125 ms, 1000000 lines parsed, 1430359.3777936706 lines/s, banned = 1375/3506Ускорение ещё почти вдвое, но разбор времени всё ещё занимает почти 20% времени:
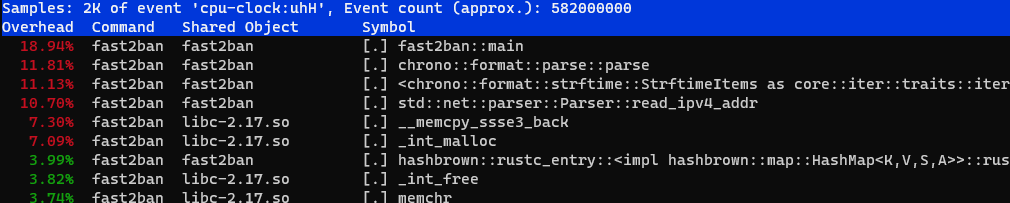 NB: время на вызовы функций из chrono: нужно суммировать
NB: время на вызовы функций из chrono: нужно суммировать
Разбор и парсинг за один проход
Если внимательно подумать над тем, что происходит в предыдущем варианте, то окажется, что при разборе строки часть с IP-адресом строки читается дважды: сначала при поиске его конца, а затем — ещё раз — при парсинге в IpAddr. Поскольку формат строки уже довольно плотно прибит к функции парсинга, почему бы не разбирать адрес и время сразу по мере просмотра строки?
Скучный код парсинга
fn parse_line_v2(line: &[u8]) -> Option {
let mut ip = 0u32;
let mut cur_grp = 0u32;
let mut timestamp = 0i64;
let mut cur_time = 0i64;
let mut iter = line.iter();
for c in iter.by_ref() {
if *c == b'.' {
ip = ip * 256 + cur_grp;
cur_grp = 0;
continue;
}
if *c == b' ' {
break;
}
cur_grp = cur_grp * 10 + (*c - b'0') as u32;
}
ip = ip * 256 + cur_grp;
let iter = iter.skip(3).skip_while(|c| **c != b' ').skip_while(|c| **c != b':');
for c in iter {
if *c == b':' {
timestamp = timestamp * 60 + cur_time;
cur_time = 0;
continue;
}
if *c == b' ' {
break;
}
cur_time = cur_time * 10 + (*c - b'0') as i64;
}
timestamp = timestamp * 60 + cur_time;
let ip: IpAddr = IpAddr::V4(Ipv4Addr::from(ip));
Some(ParseResult { ip, timestamp })
}
Кода получилось, конечно, побольше, но что насчёт эффективности?
elapsed 552.038 ms, 1000000 lines parsed, 1811469.5002880236 lines/s, banned = 1375/3506 Всё больше libc в верхних строчках профиля
Всё больше libc в верхних строчках профиля
Примерно ещё на четверть быстрее. В профиле начинает заметное время занимать функция __memcpy_ssse3_back из libc, которая вызывается при чтении файла, и… подождите, мы же можем использовать SIMD для разбора!
Разбор IP и времени из строки с помощью SIMD
Решение, которое я использую, основано на ответе на StackOverflow, и, если верить совпадению никнеймов, принадлежит @stgatilov. Оно основано на том, что IP-адрес в виде строки целиком всегда помещается в 128-битный регистр, в который влезает 16 символов, а максимальная длина IP-адреса — 15 символов (12 цифр и 3 точки).
Автор достаточно подробно объяснил в комментариях механизм работы этого алгоритма, я переведу его с некоторыми сокращениями:
Сначала мы загружаем 16 байт с невыровненного адреса с помощью инструкции lddqu. <...> Последующий код будет правильно работать вне зависимости от байтов после окончания адреса. В любом случае, вам лучше убедиться, что каждый IP-адрес занимает не менее 16 байт памяти.
Затем мы вычитаем
'0'из всех символов. После этого'.'превращается в-2, а все цифры остаются неотрицательными. Теперь мы вычисляем битовую маску знаков всех байтов с помощью_mm_movemask_epi8.В зависимости от значения этой маски мы извлекаем нетривиальную 16-байтовую маску перестановки из таблицы
shuffleTable. Таблица весит целый мегабайт, и для предварительного вычисления требуется довольно много времени <...>.Интринсик
_mm_shuffle_epi8позволяет нам изменять порядок байтов в XMM-регистре с помощью маски перестановки. В результате регистр XMM содержит четыре 4-байтовых блока, каждый блок содержит цифры (в little-endian). Мы преобразуем каждый блок в 16-битное число с помощью_mm_maddubs_epi16, за которым следует_mm_hadd_epi16. Затем мы переупорядочиваем байты регистра так, чтобы весь IP-адрес занимал нижние 4 байта.Наконец, мы извлекаем младшие 4 байта из XMM-регистра с помощью
_mm_extract_epi32. Если у вас его нет, можно воспользоваться_mm_extract_epi16, но это будет работать немного медленнее.
Код разбора IP
use std::arch::x86_64::*;
fn parse_ip_simd(addr: &[u8]) -> IpAddr {
let result: u32;
unsafe {
let input = _mm_lddqu_si128(addr.as_ptr() as *const __m128i);
let input = _mm_sub_epi8(input, _mm_set1_epi8(b'0' as i8));
let cmp = input;
let mask = _mm_movemask_epi8(cmp);
let shuf = SHUFFLE_TABLE[mask as usize];
let arr = _mm_shuffle_epi8(input, shuf);
let coeffs = _mm_set_epi8(0, 100, 10, 1, 0, 100, 10, 1, 0, 100, 10, 1, 0, 100, 10, 1);
let prod = _mm_maddubs_epi16(coeffs, arr);
let prod = _mm_hadd_epi16(prod, prod);
let imm = _mm_set_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 6, 4, 2, 0);
let prod = _mm_shuffle_epi8(prod, imm);
result = transmute(_mm_extract_epi32::<0>(prod))
}
IpAddr::V4(Ipv4Addr::from(result))
}Код для подготовки таблицы перестановок
fn init_shuffle_table() {
for len0 in 1..4 {
for len1 in 1..4 {
for len2 in 1..4 {
for len3 in 1..4 {
let slen = len0 + len1 + len2 + len3 + 4;
let lens = [&len0, &len1, &len2, &len3];
let rem = 16 - slen;
for rmask in 0..(1 << rem) {
let mut mask = 0;
let mut shuf: [i8; 16] = [-1; 16];
let mut pos = 0;
for i in 0..4 {
for j in 0..*lens[i] {
shuf[((3 - i) * 4 + (lens[i] - 1 - j))] = pos;
pos += 1;
}
mask ^= (1) << pos;
pos += 1;
}
mask ^= rmask << slen;
unsafe {
_mm_store_si128(
&mut SHUFFLE_TABLE[mask],
_mm_loadu_si128(&shuf as *const i8 as *const __m128i),
);
}
}
}
}
}
}
}Аналогичным образом можно разбирать и время с помощью SIMD-инструкций. Это значительно проще, поскольку минуты, секунды и часы всегда занимают ровно по два символа, и таблица с масками перестановок здесь не нужна.
Секунды и минуты располагаются в первых двух 16-битных словах (и умножаются на 1 и 60, соответственно), а часы — в пятом (и умножаются на 3600, т. е. 14×256+16). Выполняем умножение с горизонтальным сложением и извлекаем два двойных слова результата, которые остаётся просто сложить.
Разбор времени с помощью SIMD
fn parse_time_simd(x: &[u8]) -> u32 {
unsafe {
let input = _mm_loadu_si64(x.as_ptr() as *const _);
let input = _mm_sub_epi8(input, _mm_set1_epi8(b'0' as i8));
let input = _mm_shuffle_epi8(
input,
_mm_set_epi8(7, 6, 4, 3, -1, -1, -1, -1, 1, 0, -1, -1, -1, -1, -1, -1),
);
let coeffs = _mm_set_epi8(1, 10, 1, 10, 1, 10, 0, 0, 1, 10, 0, 0, 0, 0, 0, 0);
let prod = _mm_maddubs_epi16(coeffs, input);
let prod2 = _mm_madd_epi16(
prod,
_mm_set_epi8(0, 1, 0, 60, 0, 0, 0, 0, 14, 16, 0, 0, 0, 0, 0, 0),
);
let ms: u32 = std::mem::transmute(_mm_extract_epi32::<1>(prod2));
let h: u32 = std::mem::transmute(_mm_extract_epi32::<3>(prod2));
ms + h
}
}Заодно для поиска разделителей в строке можно использовать memchr, но не из стандартной библиотеки, а из крейта memchr который имеет оптимизированные для разных процессоров версии. Заодно и код стал короче:
parse_line_simd с memchr
fn parse_line_simd(line: &[u8]) -> Option {
let ip = parse_ip_simd(&line[..16]);
let first_space = memchr(b' ', &line[7..])? + 7;
let second_space = memchr(b' ', &line[(first_space + 3)..])? + first_space + 3;
let time_begin = memchr(b':', &line[second_space..])? + second_space + 1;
let timestamp = parse_time_simd(&line[time_begin..time_begin + 8]) as i64;
Some(ParseResult { ip, timestamp })
} Результаты выглядят неплохо, добавилось ещё ~10%:
elapsed 471.925 ms, 1000000 lines parsed, 2118980.77024951 lines/s, banned = 1375/3506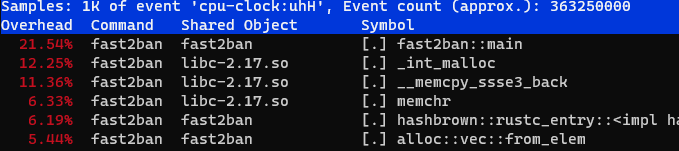 Профиль выглядит примерно так же, как и предыдущий
Профиль выглядит примерно так же, как и предыдущий
Осталось избавиться от копирования памяти при чтении файла (__memcpy_ssse3_back), и для этого можно использовать mmap. Да, это накладывает определённые ограничения, но в погоне за скоростью сложно остановиться. Итак, берём крейт memmap и несколько переписываем код парсинга, чтобы он заодно возвращал, сколько байт он прочитал:
Парсинг, возвращающий количество обработанных символов
fn parse_line_simd(line: &[u8]) -> Option<(ParseResult, usize)> {
let ip = parse_ip_simd(&line[..16]);
let first_space = memchr(b' ', &line[7..])? + 7;
let second_space = memchr(b' ', &line[(first_space + 3)..])? + first_space + 3;
let time_begin = memchr(b':', &line[second_space..])? + second_space + 1;
let timestamp = parse_time_simd(&line[time_begin..time_begin + 8]) as i64;
Some((ParseResult { ip, timestamp }, time_begin + 8))
}В главном цикле, соответственно, будем искать следующий символ переноса строки с учётом этого значения, проверяя, что до конца файла осталось больше 16 байт (потому что именно столько прочитает разбор IP).
Переписанные фрагменты main
fn main() {
// ....
let reader = unsafe { MmapOptions::new().map(&File::open("nginx.log").unwrap()).unwrap() };
let mut start_pos = 0;
let mut remains = reader.len();
loop {
let line = &reader[start_pos..start_pos + min(remains, 512)];
if let Some((ParseResult { ip, timestamp }, shift)) = parse_line_simd(line) {
start_pos += shift;
remains -= shift;
let entry = requests
.entry(ip)
.or_insert((RingBanBuffer::new(30), false));
if let Some(delta) = entry.0.add_query(timestamp) {
if delta < 30 {
entry.1 = true;
}
};
}
let next_line = memchr(b'\n', &reader[start_pos..]);
if next_line.is_none() {
break;
}
let shift = next_line.unwrap() + 1;
start_pos += shift;
remains -= shift;
line_count += 1;
if remains < 16 {
break;
}
}Выигрыш от использования mmap может быть незаметен в том случае, если данные читаются с диска недостаточно быстро: в этом случае копирование памяти не становится узким местом. Файл для тестирования содержит миллион строк и занимает 260 мегабайт, таким образом, на скорости порядка 1500 мб/с чтение файла займёт приблизительно 175 мс. Но если файл уже лежит в файловом кеше системы, то использование mmap даёт заметный выигрыш:
elapsed 373.291 ms, 1000000 lines parsed, 2678875.1938835923 lines/s, banned = 1375/3506 В этом запуске треть времени занимает поиск следующего разделителя в файле
В этом запуске треть времени занимает поиск следующего разделителя в файле
Чтобы увидеть, сколько на самом деле занимает чтение файла, нужно запустить perf от рута с ключом -a:
# perf record -a target/release/fast2ban > /dev/null
elapsed 370.284 ms, 1000000 lines parsed, 2700629.786866297 lines/s, banned = 1375/3506
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.786 MB perf.data (2473 samples) ]
# perf report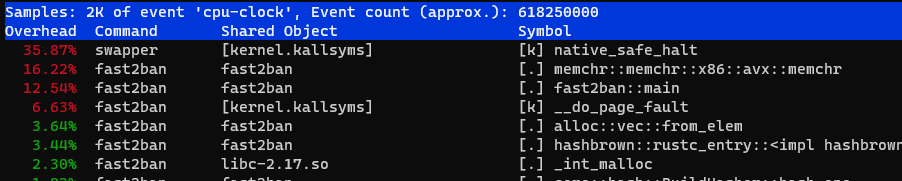
Нормальные замеры и итоги
Теперь пришло время сделать более нормальные замеры скорости. Методология будет следующая: исполняем каждый вариант 100 раз, отбрасываем 10% самых быстрых и 10% самых медленных результатов, остальное усредняем по времени на строку и считаем стандартное отклонение.
lscpu виртуалки для тестов
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel Xeon Processor (Skylake, IBRS)
Stepping: 4
CPU MHz: 2294.608
BogoMIPS: 4589.21
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
L3 cache: 16384K
NUMA node0 CPU(s): 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 arat md_clear spec_ctrlПравда, fail2ban-regex слишком медленный и я запускал его только по 10 раз. Кроме того, код на Rust разбирал по одному миллиону строк, а fail2ban-regex — по 100 тысяч. Сам fail2ban выводит замеренное время с точностью до 10 мс, поэтому результаты для fail2ban округлены до 100 нс.
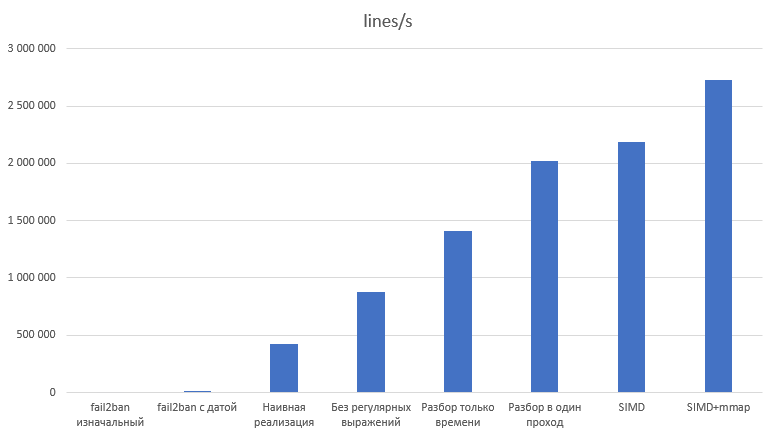
Вариант | ns/line | lines/s | Ускорение | Относительно предыдущего |
fail2ban изначальный | 488 600 ± 9 500 | 2 047 | ||
fail2ban с датой | 79 900 ± 2 800 | 12 514 | 6,11x | 6,11x |
Наивная реализация | 2 337,55 ± 96,66 | 427 799 | 209,04x | 34,19x |
Без регулярных выражений | 1 143,58 ± 73,79 | 874 448 | 427,29x | 2,04x |
Разбор только времени | 710,55 ± 43,93 | 1 407 366 | 687,69x | 1,60x |
Разбор в один проход | 494,64 ± 32,65 | 2 021 688 | 987,87x | 1,43x |
SIMD | 457,74 ± 30,96 | 2 184 669 | 1 067,51x | 1,08x |
SIMD+mmap | 366,22 ± 23,56 | 2 730 612 | 1 334,28x | 1,24x |
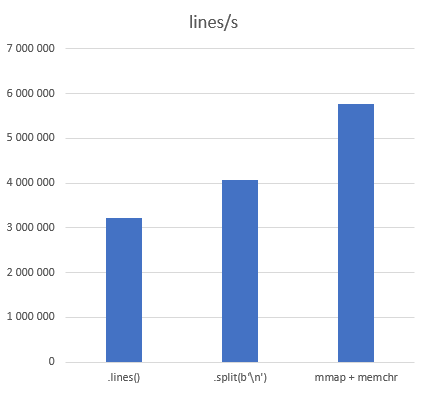
Дополнительно я измерил просто итерирование по строкам различными методами:
Метод | ns/line | lines/s | Ускорение |
| 311,04 ± 12,89 | 3 214 981 | |
.split (b'\n') | 245,63 ± 10,82 | 4 071 210 | 1,27 |
| 173,55 ± 7,15 | 5 762 122 | 1,79 |
Исходники выложены на github, код разных вариантов из статьи находится в ветке habr разными коммитами. Пулл-реквесты, как всегда, приветствуются.
P.S. Внимательные читатели могли заметить, что само использование SIMD не дало большого выигрыша — всего 8%. Тем не менее, желтоватый заголовок статьи корректен: тысячекратное ускорение было достигнуто именно на этом шаге.
