Jenkins Pipeline. Что это и как использовать в тестировании
Меня зовут Александр Михайлов, я работаю в команде интеграционного тестирования компании ЮMoney.
Наша команда занимается приемочным тестированием. Оно включает в себя прогон и разбор автотестов на критичные бизнес-процессы в тестовой среде, приближенной по конфигурации к продакшену. Еще мы пишем фреймворк, заглушки, сервисы для тестирования — в целом, создаем экосистему для автоматизации тестирования и обучаем ручных тестировщиков автоматизации.
Надеюсь, что эта статья будет интересна как новичкам, так и тем, кто съел собаку в автоматизации тестирования. Мы рассмотрим базовый синтаксис Jenkins Pipeline, разберемся, как создать джобу на основе пайплайна, а также я расскажу про опыт внедрения неочевидной функциональности в CI — запуска и дожатия автотестов по условию.
Запуск автотестов на Jenkins — инструкция
Не новость, что автотесты эффективнее всего проводить после каждого изменения системы. Запускать их можно локально, но мы рекомендуем делать это только при отладке автотестов. Больший профит автотесты принесут при запуске на CI. В качестве CI-сервера у нас в компании используется Jenkins, в качестве тестового фреймворка — JUnit, а для отчетов — Allure Report.
Чтобы запускать тесты на Jenkins, нужно создать и сконфигурировать джобу.
Для этого достаточно выполнить несколько несложных шагов.1) Нажать «Создать», выбрать задачу со свободной конфигурацией и назвать ее, например, TestJob.
Естественно, для этого у вас должны быть права в Jenkins. Если их нет, нужно обратиться к администратору Jenkins.
2) Указать репозиторий, откуда будет выкачиваться код проекта: URL, credentials и branch, с которого все будет собираться.
3) Добавить нужные параметры, в этом примере — количество потоков (threadsCount) и список тестов для запуска (testList).
Значение »*Test» для JUnit означает «Запустить все тесты».
4) Добавить команду для запуска тестов.
Наш вариант запускается на Gradle: мы указываем таску теста и передаем параметры в тесты.
./gradlew test -PthreadsCount=$threadsCount -PtestList=$testList
Можно выполнить шаг сборки «Выполнить команду shell», либо через Gradle Plugin использовать шаг «Invoke Gradle Script».
5) Нужно добавить Allure-report (должен быть установлен https://plugins.jenkins.io/allure-jenkins-plugin/) в «Послесборочные операции», указав путь к артефактам Allure после прогона (по умолчанию allure-result).
Создав джобу и прогнав с ее помощью тестов, мы можем получить такой результат.
На скрине — реальный прогон. По таймлайну видно, как тесты разделяются по потокам и где были падения.
Несложно заметить, что тесты у нас падают.
Почему падают тесты
Падения могут случаться по разным причинам. В нашем случае на это влияют:
ограниченные ресурсы тестового стенда,
большое число микросервисов (~140); если при запуске интеграционных тестов какой-то один микросервис подтормаживает, тесты начинают валиться,
большое число интеграционных тестов (>3000 E2E),
врожденная нестабильность UI-тестов.
В итоге проблемы по этим причинам мультиплицируются, и мы получаем комбинаторный взрыв, проявляющийся ошибками в прогонах тестов. Что делать? Дожимать.
Что такое дожим
Дожим — это перезапуск автотестов в рамках их одного прогона. При успешном прохождении автотеста можно считать его пройденным, не учитывая предыдущие падения в прогоне.
«Дожимать? Опасно же!»
Возразите вы и будете полностью правы. Безусловно, дожим автотестов может спровоцировать пропуск дефекта на продакшн. Баг может быть плавающим — при повторном запуске успешно просочиться и попасть на продакшн.
Но мы проанализировали статистику падений автотестов за длительный период и увидели, что большинство падений было связано с нестабильной тестовой средой, тестовыми данными. Поэтому мы взяли на себя риск и стали дожимать тесты. Прошло уже больше года, и не было ни одного дефекта, пропущенного на продакшн по этой причине. Зато стабильность тестов повысилась ощутимо.
Как решать задачу с дожимами
Мы пробовали разные решения: использовали модификацию поведения JUnit 4, JUnit 5, писали обертки на Kotlin. И, к сожалению, каждый раз реализация завязывалась на фичах языка или фреймворка.
Если процесс запускался с помощью JUnit 4 или JUnit 5, возможность перезапустить тесты была только сразу при падении. Тест упал, перезапустили его несколько раз подряд — и если сбоил какой-то микросервис из-за нагрузки, либо настройки тестовой среды были некорректные, то тест все три раза падал.
Это сильно удлиняло прогон, особенно когда проблема была в настройке тестовой среды, что приводило к провалу множества тестов.
Мы взглянули на проблему шире, решили убрать зависимость от тестового фреймворка или языка и реализовали перезапуск на более высоком уровне — на уровне CI. И сделали это с помощью Jenkins Pipeline.
Для этого подходил следующий алгоритм: получаем список упавших тестов и проверяем условия перезапуска. Если упавших тестов нет, завершаем прогон. Если есть, решаем, запускать их повторно или нет. Например, можно реализовать логику, чтобы не перезапускались тесты, если их упало больше какого-то критического числа. Или перед запуском можно сделать проверку доступности тестируемого сервиса.
Что такое Jenkins Pipeline
Jenkins Pipeline — набор плагинов, позволяющий определить жизненный цикл сборки и доставки приложения как код. Он представляет собой Groovy-скрипт с использованием Jenkins Pipeline DSL и хранится стандартно в системе контроля версий.
Существует два способа описания пайплайнов — скриптовый и декларативный.
1. Scripted:
node {
stage('Example') {
try {
sh 'exit 1'
}
catch (exc) {
throw exc
}
}
}
2. Declarative
pipeline {
agent any
stages {
stage("Stage name") {
steps {}
}
}
}
Они оба имеют структуру, но в скриптовом она вольная — достаточно указать, на каком слейве запускаться (node), и стадию сборки (stage), а также написать Groovy-код для запуска атомарных степов.
Декларативный пайплайн определен более жестко, и, соответственно, его структура читается лучше.
Рассмотрим подробнее декларативный пайплайн.
В структуре должна быть определена директива pipeline.
Также нужно определить, на каком агенте (agent) будет запущена сборка.
Дальше идет определение stages, которые будут содержаться в пайплайне, и обязательно должен быть конкретный стейдж с названием stage («name»). Если имени нет, тест упадет в runtime с ошибкой «Добавьте имя стейджа».
Обязательно должна быть директива steps, в которой уже содержатся атомарные шаги сборки. Например, вы можете вывести в консоль «Hello».
pipeline { // определение декларативного pipeline
agent any // определяет, на каком агенте будет запущена сборка
stages { // содержит стейджи сборки
stage("Stage name") { // отдельный стейдж сборки
steps { // набор шагов в рамках стейджа
echo "Hello work" // один из шагов сборки
}
}
}
}
Мне нравится декларативный вид пайплайна тем, что он позволяет определить действия после каждого стейджа или, например, после всей сборки. Я рекомендую использовать его при описании пайплайнов на верхнем уровне.
pipeline {
stages {
stage("Post stage") {
post { // определяет действия по завершении стейджа
success { // триггером исполнения секции является состояние сборки
archiveArtifacts artifacts: '**/target/*'
}
}
}
}
post { // после всей сборки
cleanup {
cleanWs()
}
}
}
Если сборка и стейдж завершились успешно, можно сохранить артефакты или почистить workspace после сборки. Если же при таких условиях использовался бы скриптовый пайплайн, пришлось бы за этим «флоу» следить самостоятельно, добавляя обработку исключений, условия и т.д.
При написании своего первого пайплайна я, естественно, использовал официальный мануал — там подробное описание синтаксиса и степов.
Сначала я даже растерялся и не знал, с чего начать — настолько там много информации. Если вы первый раз сталкиваетесь с написанием пайплайна, начать лучше со знакомства с генераторами фрагментов пайплайна из UI-интерфейса.
Если к URL вашего веб-интерфейса Jenkins добавить ендпойнт /pipelines-syntax, откроется страница, в которой есть ссылки на документацию и два сниппет-генератора, позволяющие генерировать пайплайн даже без знания его синтаксиса:
Declarative sections generator
Snippet Generator
Генераторы фрагментов — помощники в мире Jenkins
Для создания пайплайна сначала нужно декларативно его описать, а затем наполнить степами. Давайте посмотрим, как вспомогательные инструменты нам в этом помогут.
Declarative sections generator (JENKINS-URL/directive-generator) — генератор фрагментов для декларативного описания пайплайна.
Для добавления стадии нужно написать ее имя и указать, что будет внутри (steps). После нажатия кнопки «Сгенерировать» будет выведен код, который можно добавлять в пайплайн.
stage("start tests”){
steps { //One or more steps needs to be included within the steps block
}
}Также нам нужны шаги, в которых будут выполняться различные действия — например, запуск джобы Jenkins с тестами.
В Sample Step выбрать build: Build a job.
(Дальше функционал подсказывает) — необходимо определить параметры, которые будут переданы в джобу (для примера задано branch, project).
Нажать кнопку «Generate» — в результате сформируется готовый рабочий код.
Изменим параметры джобы на те, которые определили при ее создании.
build job ‘QA/TestJob’, parameters: [
string(name: 'threadsCount', value: 16),
string(name: 'testList', value: *Test),
string(name: 'runId', value: runId)]где threadsCount — кол-во потоков для распараллеливания тестов, testList — список тестов для запуска, runId — идентификатор прогона тестов. Для чего нужны эти параметры, расскажу далее.
Snippet Generator удобен тем, что подсвечивает шаги в зависимости от установленных плагинов. Если у вас есть, например, Allure-report, то плагин сразу покажет наличие расширения и поможет сгенерировать код, который будет работать.
Вставим сгенерированный код степа в пайплайн на следующем шаге.
Запуск тестов с помощью Pipeline — инструкция
Итак, давайте с помощью Declarative sections generator создадим пайплайн. В нем нужно указать директивы: pipeline, agent (агент, на котором будет запускаться пайплайн), а также stages и steps (вставка ранее сгенерированного кода).
Так получится пайплайн, который запустит джобу, созданную на предыдущем шаге через UI.
pipeline {
agent {
label any
}
stages {
stage("start test") {
steps{
build job: '/QA/TestJob',
parameters: [
string(name: 'threadsCount', value: threadsCount),
string(name: 'runId', value: runId),
string(name: 'testList', value: testList)]
}
}
}
}
Напомню, что в параметры для запуска тестов мы передавали количество потоков и список тестов. Теперь к этому добавляем параметр runId (идентификатор прогона тестов) — он понадобится позднее для перезапуска конкретного сьюта тестов.
Чтобы запустить пайплайн, нужно создать проект.
New Item → Pipeline.
Для этого нужно нажать на кнопку «Создать проект» и выбрать не джобу со свободной конфигурацией, а джобу Pipeline — осталось указать ей имя.
Добавить параметры runId, threadsCount, testList.
Склонировать из Git.
Пайплайн можно описать непосредственно как код и вставить в поле, но для версионирования нужно затягивать пайплайн из Git. Обязательно указываем путь до скрипта с пайплайном.
Готово, джобу можно запускать.
Хотим добавить немного дожатий
На этом этапе у нас уже готова джоба для запуска проекта с автотестами. Но хочу напомнить, что наша задача — не просто запускать тесты, а добавить им стабильности, исключив падения из-за внешних факторов. Для достижения этого результата было принято решение дожать автотесты.
Для реализации нужно:
вынести шаг запуска тестов в библиотечную функцию (shared steps),
получить упавшие тесты из прогона,
добавить условия перезапуска.
Теперь немного подробнее про каждый из этих шагов.
Многократное использование шагов — Shared Steps
В процессе написания пайплайнов я столкнулся с проблемой постоянного дублирования кода (часто используемых степов). Этого хотелось избежать.
Решение нашлось не сразу. Оказывается, для многократного использования кода в Jenkins есть встроенный механизм — shared libraries, который позволяет описать методы один раз и затем применять их во всех пайплайнах.
Существуют два варианта подключения этой библиотеки.
Написанный проект/код подключить через UI Jenkins. Для этого требуются отдельные права на добавление shared libraries или привлечение девопс-специалистов (что не всегда удобно).
Хранить код в отдельном проекте или в проекте с пайплайнами. При использовании этот код подключается как динамическая библиотека и выкачивается каждый раз при запуске пайплайна.
Мы используем второй вариант — размещаем shared steps в проекте с пайплайнами.
Для этого в проекте нужно:
создать папку var,
в ней создать файл с названием метода, который планируется запускать — например, gradlew.groovy,
стандартно определить имя метода (должен называться call), то есть написать «def call» и определить входящие параметры,
в теле метода можно написать произвольный Groovy-код и/или Pipeline-степы.
Pipeline script:
//Подключение библиотеки
//https://www.jenkins.io/doc/book/pipeline/shared-libraries/ - описание с картинками
library identifier: 'pipeline-shared-lib'
pipeline {
stages {
stage("Build") {
steps {
gradlew(tasks: ["build"]) // вызов метода из библиотеки
}
}
}
}var/gradlew.groovy
def call(Map> parameters) {
// стандратное имя для глобального метода
def tasks = parameters["tasks"]
def args = parameters["args"] ?: []
sh "./gradlew ${args.join(' ')}
${tasks.join(' ')}"
// произвольный groovy код + pipeline-методы
} Вынесение запуска тестов в shared steps в /var
Выносим startTests.groovy в /var.
Во-первых, нужно вынести запуск тестов в отдельный метод. Выглядит это так — создаем файл, называем метод def call, берем кусок кода, который был в пайплайне, и выносим его в этот step.
def call(Map params) {
def threadsCount = params["threadsCount"] ?: "3"
def testList = params["testList"] ?: "*Test"
stage("start test job") {
runTest = build job: '/QA/TestJob',
parameters: [
string(name: 'threadsCount', value: threadsCount),
string(name: 'runId', value: runId),
string(name: 'testList', value: testList)],
propagate: false
}
}
Для передачи параметров используется Map
Структура проекта будет выглядеть так.
Подключение shared steps как внешней библиотеки.
Дальше нужно добавить вынесенные шаги в пайплайн. При динамической подгрузке библиотек (во время запуска пайплайна) эти шаги выкачиваются из репозитория и подключаются на лету.
Сделать это можно с помощью сниппет-генератора — выбираем степ library и указываем ветку, в которую все будет собираться и репозиторий. Дальше нажимаем кнопку «Сгенерировать» и вставляем получившийся пайплайн.
library changelog: false,
identifier: 'shared-lib@master',
retriever: modernSCM([
$class : 'GitSCMSource',
remote : 'ssh://git@bitbucket.ru/qa/jenkins-groovy-scripts.git'])Теперь после подключения shared steps вместо шага запуска тестов build нужно вставить startTest. Не забудьте, что имя метода должно совпадать с именем файла.
Теперь наш пайплайн выглядит так.
//Динамическое подключение библиотеки
library changelog: false,
identifier: 'shared-lib@master',
retriever: modernSCM([
$class : 'GitSCMSource',
remote : 'ssh://git@bitbucket.ru/qa/jenkins-groovy-scripts.git'])
pipeline {
agent {
label any
}
stages {
stage("start test") {
steps{
startTests(runId: runId ) //Вызов метода из библиотеки
}
}
}
}Первый шаг реализован, теперь можно многократно запускать тесты в разных местах. Переходим к 2 шагу.
Получение упавших тестов из прогона
Теперь нам нужны упавшие тесты. Каким образом их извлечь?
Установить в Jenkins плагин JUnit Test Result Report и использовать его API.
Взять результаты прогона JUnit (обычно в формате XML), распарсить и извлечь нужные данные.
Запросить список упавших тестов из нужного места.
В нашем случае таким местом является собственный написанный сервис — Reporter. Во время прогона тестов результат по каждому из них отправляется именно туда. В конце прогона делаем http-запрос и получаем упавшие тесты.
http://reporter:8080/failedTests/$runId
Добавление условий перезапуска
На этом шаге следует добавить getFailedTests.groovy в /var. Представим, что у вас есть такой сервис — Reporter. Нужно назвать файл getFailedTests, сделать запрос httpRequest в этот сервис и распарсить его.
def call(String runId) {
def response = httpRequest httpMode: 'GET',
url: "http://reporter:8080/failedTests/$runId"
def json = new JsonSlurper().parseText(response.content)
return json.data
}Отлично, второй шаг выполнен. Осталось добавить ту самую изюминку — условия перезапуска. Но сначала посмотрим, что получается.
Есть запуск тестов и получение результатов прогона. Теперь нужно добавить те самые условия, которые будут говорить: «Если все хорошо, завершай прогон. Если плохо, давай перезапускать».
Условия перезапуска
Какие условия для перезапуска можно реализовать?
Приведу часть условий, которые используем мы.
1) Если нет упавших тестов, прогон завершается.
if (countFailedTests == 0) {
echo «FINISHED»
…
}2) Как я уже писал выше, на тестовой среде ресурсы ограничены, и бывает такое, что ТС захлебывается в большом количестве параллельных тестов. Чтобы на дожатии избежать падений тестов по этой причине, понижаем число потоков на повторном запуске. Именно для этого при создании джобы и в самом пайплайне мы добавили параметр threadsCount.
Если и после уменьшения потоков тесты не дожимаются (количество упавших тестов на предыдущем прогоне равно числу упавших тестов на текущем), тогда считаем, что дело не во влиянии ТС на тесты. Останавливаем прогон для анализа причин падений — и тем самым предотвращаем последующий холостой запуск.
if (countFailedTests == previousCountFailedTests) {
echo «TERMINATED - no one new passed test after retry»
…
}3) Третья и самая простая проверка состоит в том, что если падает большое количество тестов, то дожимать долго. Скорее всего, причина падений какая-то глобальная, и ее нужно изучать.
Для себя мы определили: если тестов > 40, дожимать не автоматически не будем, потому что 40 наших E2E могут проходить порядка 15 минут.
if (countFailedTests > FAILEDTESTSTRESHOLD) {
echo «TERMINATED - too much failed tests»
…
}https://github.com/useriq/retry-flaky-tests/blob/master/jenkins-pipeline-retry/var/testsWithRerun.groovy
def call(Map params) {
assert params["runId"]
def threadsCount = params["threadsCount"] ?: "8"
def testList = params["testList"] ?: "*Test"
def runId = params["runId"]
int FAILED_TESTS_TRESHOLD = 40
def countFailedTests = 0
def failedTests
int run = 1
boolean isFinished = false
int threads = threadsCount as int
while (run <= Integer.valueOf(runCount) && !isFinished) {
if (run == 1) {
startTests()
} else {
if (countFailedTests > 0) {
threads = reduceThreads(threads)
testList = failedTests.toString().minus('[').minus(']').minus(' ')
startTests()
}
}
stage("check ${run}_run result ") {
failedTests = getFailedTests(runId)
def previousCountFailedTests = countFailedTests
countFailedTests = failedTests.size()
if (countFailedTests == 0) {
echo "FINISHED"
isFinished = true
}
if (countFailedTests > FAILED_TESTS_TRESHOLD) {
echo "TERMINATED - too much failed tests > ${FAILED_TESTS_TRESHOLD}"
isFinished = true
}
if (countFailedTests == previousCountFailedTests) {
echo "TERMINATED - no one new passed test after retry"
isFinished = true
}
}
run += 1
}
} Последние два условия — так называемые fail fast. Они позволяют при глобальных проблемах на тестовом стенде не делать прогоны, которые не приведут к дожиму тестов, но будут занимать ресурсы тестового стенда.
Итоговый pipeline
Итак, все 3 шага реализованы — итоговый пайплайн выглядит так.
library changelog: false,
identifier: 'shared-lib@master',
retriever: modernSCM([
$class : 'GitSCMSource',
remote : 'ssh://git@bitbucket.ru/qa/jenkins-groovy-scripts.git'])
assert runId != null
pipeline {
agent {
label any
}
stages {
stage("start test") {
steps {
testsWithRerun(runId: runId)
}
}
}
}
Визуализация с Blue Ocean
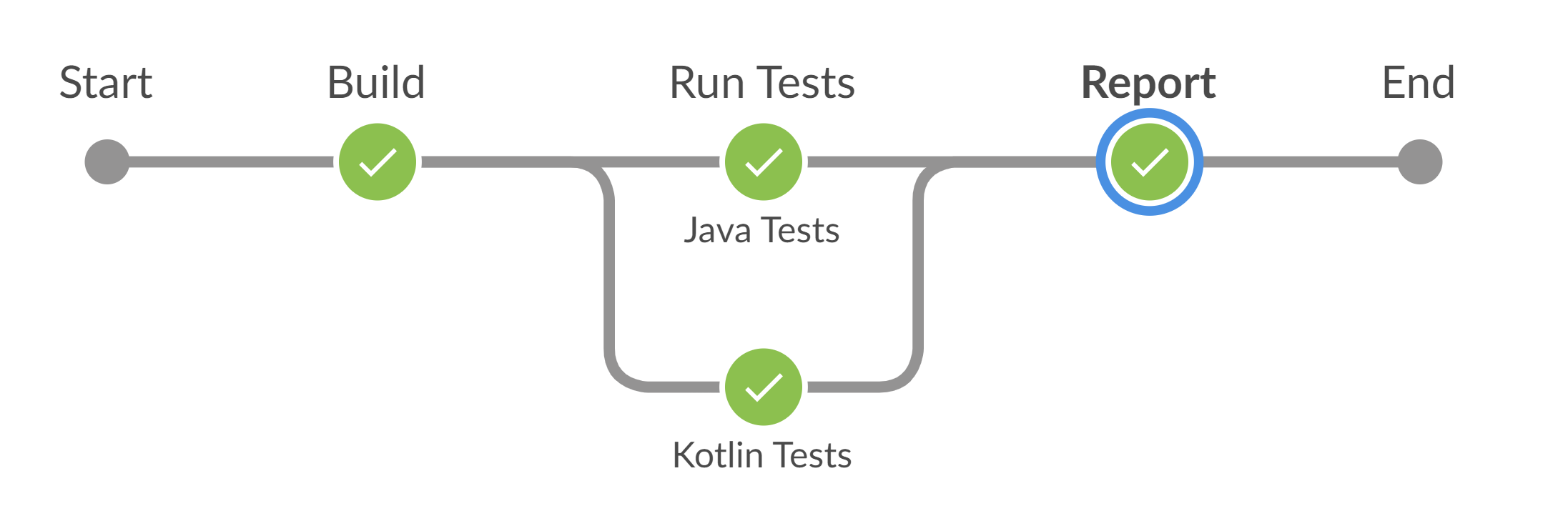
Как все это выглядит при прогоне в Jenkins? У нас, к примеру, для визуализации в Jenkins установлен плагин Blue Ocean.
На картинке ниже можно увидеть, что:
запустился метод testwith_rerun,
прошел первый запуск,
прошла проверка упавших тестов,
запустился второй прогон,
после успешной проверки джоба завершилась.

Вот так выглядит визуализация нашего настоящего прогона.
В реальном примере две ветки: мы параллельно запускаем два проекта с тестами (на Java и Kotlin). Можно заметить, что тесты одного проекта прошли с первого раза, а вот тесты другого пришлось дожимать еще раз. Таким образом визуализация помогает найти этап, на котором падают тесты.
А так выглядит реальный timeline приемки релиза.
После первого прогона отправили дожимать упавшие тесты. Во второй раз упавших тестов намного меньше, дожимаем в третий раз — и вуаля, успешный build.
Задача решена.
Итог
Мы перенесли логику перезапусков упавших тестов из тестового проекта на уровень выше — на CI. Таким образом сделали механизм перезапуска универсальным, более гибким и независимым от стека, на котором написаны автотесты.
Раньше наши тесты дожимались безусловно, по несколько раз, с неизменным количеством параллельных потоков. При перегрузке тестового стенда, некорректных настройках тестового окружения либо каких-то других проблемах — красные тесты перезапускались фиксированное число раз без шансов дожаться. В худшем случае прогоны могли длиться часами. Добавив условия fail fast, мы сократили это время.
При падении тестов инженер, ответственный за приемку, в некоторых ситуациях вручную стартовал джобу перезапуска, выполняя прогон с меньшим числом потоков. На это тоже уходило время. Добавив в условия пайплайна уменьшение числа потоков на перезапуске, мы сократили и это время.
Какой профит мы получили:
уменьшили time-to-market тестируемых изменений,
сократили длительность аренды тестового стенда под приемочное тестирование,
увеличили пропускную способность очереди приемочного тестирования,
не завязаны на тестовый фреймворк («под капотом» может быть что угодно — дожатия будут работать),
поделились знаниями об использовании Jenkins Pipeline.
Примеры кода выложены на GitHub. Если будут вопросы, задавайте — обязательно отвечу.
