It is Wednesday, my java dudes, или насколько сложно сделать свою JVM
Что делать, если накануне переезда повысилась тревожность, а привычные методы не приносят успокоения?
Конечно же вырабатывать дофамин через решение упоротых инженерных задач!
Мне стало интересно — насколько тяжко было бы сделать свой интерпретатор байт-кода Java? И насколько сложно было бы научить его «новым трюкам»?
Писать я буду на Rust, поэтому и проект, не мудрствуя лукаво, назвал Rjava.

Зачем
В основном just for fun. Но сейчас появилась мысль, что маленькую урезанную JVM можно было бы попытаться запустить на каком-нибудь микроконтроллере, типа arduino. Наверняка такие проекты уже есть, я не гуглил. Тем более интересно было бы попробовать и сравнить. Но уже в следующий раз.
С чего начать
Само собой со спецификации. Последняя версия — 18.
Всю её я не осилил, да и цели такой не было. Фактически я сразу сделал простенький java class и пошёл изучать как он устроен (устройству class файла посвящён отдельный раздел).
Расскажу об этом вкратце.
Устройство class-файла

Проще всего объяснить, глядя на структуру, описывающую «верхний» уровень файла:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}На всякий случай поясню, что u4 — это «беззнаковое целое число занимающее 4 байта», а u2 — «беззнаковое целое число, занимающее 2 байта». Если читать class файл побайтово, то в первых 4х байтах у нас будет «магическое» число (отличительный маркер), а затем 4 байта версии — 2 байта на major часть и 2 байта на minor.
Отличительный маркер, кстати, выглядит вот так:

Следующим идёт Constant Pool (сначала количество записей, а потом сами записи). Constant Pool — это такой справочник, в который занесена вся переиспользуемая информация. Разные части class файла ссылаются на записи в этом справочнике по индексу. Далеко за примером ходить не надо, поля this_class и super_class — это как раз индексы в Constant Pool где указаны полные имена классов (кстати, в формате java/lang/Object, через / вместо точки).
Кроме того, в Constant Pool содержатся:
Сигнатуры методов и типы полей (записи вида
(Ljava/lang/String;)V, переводится как «принимаю ссылку на String, возвращаю void»)Имена методов и полей
Полные имена классов (см выше)
Строки и константы, используемые в коде.
Т.к. многое из этого — просто строки — вы можете открыть class файл в обычном блокноте и увидеть имена всех используемых классов и методов.
Вот тут явно кто-то конкатенирует строки :)
♠append☺ -(Ljava/lang/String;)Ljava/lang/StringBuilder;☺ ∟(I)Ljava/lang/StringBuilder;☺ ◘toString☺ ¶()Ljava/lang/String;Никаких import-ов из исходного java файла тут нет. Все имена и сигнатуры резолвятся на этапе компиляции. Но каких-либо прямых «ссылок» на другие class файлы (оффсетов в них и пр) тоже нет. JVM уже в рантайме подгружает класс по его имени (тут и пригождается соглашение «имя класса == fn (путь)», находит в списке методов класса такой, у которого совпадающие имя и сигнатура, и использует его. Это называется «позднее связывание».
Пояснение: выше я описываю как это работает при вызове не-виртуального метода.
Я отвлёкся. Поле access_flags содержит битовую маску, хранящую информацию о том public у нас класс, final ли, а может вообще interface или enum.
Дальше идёт ссылка на запись в constant pool, где хранится имя текущего класса (интересно зачем, ведь оно по текущему пути легко определяется…), и ссылка на имя родительского класса. Ссылка допустима только одна, так что множественное наследование в принципе не предусмотрено в JVM.
super_class всегда на что-то ссылается. Если нет явного родительского класса, то на java/lang/Object (даже у интерфейсов). Запись 0 допустима только у самого java/lang/Object.
Дальше идёт перечень интерфейсов (вернее ссылок на имена интерфейсов), их уже может быть сколько угодно.
Потом идут списки полей и методов. И вот с методами давайте познакомимся поближе.
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}access_flags нам уже знаком, разве что тут вариантов побольше (protected, private, synchronized…). name_index и descriptor_index отсылают к constant pool. А дальше идут атрибуты.
Атрибуты могут быть произвольными. Есть несколько обязательных, остальные — необязательные. JVM обязана игнорировать неизвестные атрибуты, но не ругаться на их наличие. Таким образом можно добавлять в class файлы дополнительную информацию о классах, полях и методах (атрибуты есть у всех). Runtime аннотации, кстати, тоже записываются в атрибуты.
Один из обязательных атрибутов зовётся Code. Вы найдёте его в любом class-файле, где есть хоть один реализованный метод.
Собственно в этом атрибуте Code и содержится байт-код — последовательность байт, где каждый байт это либо команда, либо аргумент команды.
Например, вот такой код:
public static void main(String[] args) {
System.out.println("Hello world");
}В байт-коде выглядит вот так:
public static void main(java.lang.String[]);
Code:
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Hello world
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return#2, #3 и #4 — это ссылки на constant_pool. В записи номер 2 хранится ссылка на статическое поле System.out (с типом java.io.PrintStream). В записи номер 3 хранится строка «Hello world» — константа. В записи 4 хранится ссылка на метод java.io.PrintStream#println.
Но чтобы всё это работало, JVM должна данные куда-то складывать. Рассмотрим устройство памяти JVM.
Устройство памяти

Есть общая память — «куча» — с которой работают все потоки. В ней создаются объекты и массивы, там наводит порядок GC.
И есть стек, который относится к одному потоку, и состоит из фреймов. Фрейм добавляется в стек, когда происходит вызов метода, и убирается из стека при возврате из метода. Фрейм в свою очередь тоже состоит из стека поменьше (т.н. стек операндов, operand stack) и набора локальных переменных. Размер фрейма должен быть известен заранее и подсчитан на этапе компиляции.
В каждый момент времени каждый поток выполняет байт-код одного метода и имеет доступ к значениям, хранящимся в крайнем фрейме. В фрейме могут находиться ссылки на объекты в куче. Но на значения внутри фреймов никто, кроме кода текущего метода, доступа не имеет.

Собственно большая часть команд байт-кода так или иначе манипулируют с фреймом — берут локальные переменные и складывают в стек, потом достают и складывают в другие локальные переменные. При вызове других методов аргументы помещаются в стек, после вызова результат появляется на вершине стека.
Как поизучать байт-код самостоятельно, если интересно.
Компилируем:
javac YourFile.javaА потом выводим байт-код в человеко-читаемом виде:
javap -c YourFile.class
Выполнение байт-кода
Возьмём простую функцию:
public static int sum(int a, int b) {
return a + b;
}И скомпилируем её:
public int sum(int, int);
Code:
0: iload_0
1: iload_1
2: iadd
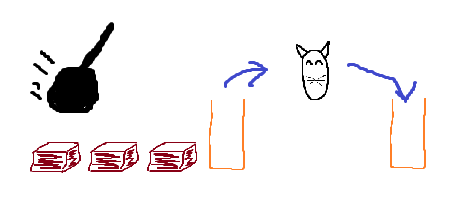
3: ireturnКак выполняется этот байт-код на примере котиков:

Вот фрейм, в нём 3 локальных переменных (коробки) и стек операндов. Стек пустой, в первые две локальные переменные переданы аргументы.
Команда iload_0 достаёт котика из первой коробки и копирует в стек.

При этом из коробки котик никуда не девается, значение этой переменной можно использовать ещё раз.
Iload_1 кладёт второго котика поверх первого. В стеке теперь два значения.

Команда iadd складывает двух целочисленных котиков (если бы котики были с плавающей запятой, была бы команда fadd) из вершины стека и помещает результат сложения обратно в стек.

Команда ireturn же берёт верхнего котика из стека и возвращает туда, откуда был вызван текущий метод. Сложенный котик попадает в другой стек фрейма, а этот фрейм разрушается.
В общем, как вы понимаете, выполнение байт-кода само по себе дело не очень хитрое. Если выполнять его «в лоб», как написано. Но на самом деле спецификация предписывает выполнять массу проверок на этапе выполнения — сравнивать типы, сигнатуры и пр. И как бы реализация этих проверок (и вообще валидация class-файла) не заняла в разы больше времени, чем всё остальное.
Runtime
Допустим, складывать числа мы умеем. Но и сами числа, и результат работы хранятся где-то в памяти. Нужна связь с «внешним миром», вернее, с операционной системой.
Как она устроена в java, на примере работы с файлами.
В стандартной библиотеке есть класс java.io.File. В нём реализована часто используемая логика работы с файлами, абстрагированная от конкретной реализации файловой системы через абстракцию java.io.FileSystem. В зависимости от ОС выбирается реализация, например, для Windows это будет WinNTFileSystem. А в этом классе можно найти вот такие методы, помеченные как native.
@Override
public native boolean checkAccess(File f, int access);
@Override
public native long getLastModifiedTime(File f);
@Override
public native long getLength(File f);
Эти методы не имеют реализации в байт-коде. При их вызове JVM находит по определённым правилам С-функцию из некой dll библиотеки и передаёт управление ей.
Собственно через native методы JVM и общается с окружающим миром.
Моя RJAVA тоже так будет делать. Но мне не хотелось на данном этапе поддерживать всё многообразие стандартной библиотеки Java, поэтому я завёл небольшой вспомогательный класс, который использовал вместо System, и который было в разы проще реализовать.
public class RVM {
native public static void print(String message);
native public static void print(Object object);
native public static void print(int value);
native public static void println();
native public static void logState();
native public static int tick();
native public static int heapSize();
}
При компиляции у таких методов в access_flags добавляется флажок ACC_NATIVE и отсутствует атрибут Code. Реализацию native методов я для начала просто встроил в код, динамическую подгрузку библиотечных функций можно будет реализовать позднее.
impl NativeMethod for RvmClass {
fn invoke(
&self,
vm: &VM,
class_name: &String,
name: &String,
arguments: Vec,
) -> Option {
match (class_name.as_str(), name.as_str()) {
(RVM_CLASS_NAME, PRINT) => self.print(&arguments, &vm.heap),
(RVM_CLASS_NAME, PRINTLN) => self.println(),
(RVM_CLASS_NAME, LOG_STATE) => self.log_state(vm),
(RVM_CLASS_NAME, HEAP_SIZE) => Some(Value::Int(vm.heap.inspect().len() as i32)),
(RVM_CLASS_NAME, TICK) => Some(Value::Int(
SystemTime::now()
.duration_since(vm.start_time)
.unwrap()
.as_millis() as i32,
)),
_ => None,
}
}
}
После того, как простенькие классы стали корректно выполняться и выводить что-то в консоль, пришло время попробовать что-то новое.

Оптимизация хвостовой рекурсии
Что это такое и почему нет в JVM хорошо написано в этой статье на хабре.
Наше преимущество в том, что в своей JVM мы можем нарушать спецификацию как нам угодно. Чем сейчас и займёмся.
Вот такая функция годится для оптимизации хвостовой рекурсии:
private static int tailCallFibonacci(int prevPrevFib, int prevFib, int remaining) {
if (remaining <= 0) return prevPrevFib;
if (remaining == 1) {
RVM.logState();
return prevFib;
}
return tailCallFibonacci(prevFib, prevPrevFib + prevFib, remaining-1);
}
public static int tailCallFibonacci(int nth) {
return tailCallFibonacci(0, 1, nth);
}
Без этой оптимизации у нас будет много вложенных вызовов tailCallFibonacci, что потенциально может привести к stack overflow, т.к. на каждый вызов в стек помещается новый фрейм.
Когда тело метода заканчивается на вызов этого самого метода, по сути нам нужно просто вернуться в его начало и «подменить» входящие аргументы на новые.
Чтобы передать дополнительную информацию в JVM через class-файл, можно было бы завести свой атрибут. Но это нужно учить компилятор этот самый атрибут вставлять. Самое простое, что можно сделать — добавить специальную аннотацию и учитывать её при выполнении.
@RVM.TailRecursion
private static int tailCallFibonacciOptimized(
int prevPrevFib, int prevFib, int remaining) Сама обработка выглядит так: выполняется вызов того же метода на том же frame. Перед этим проверяется, что хвостовая рекурсия имеет место быть и оптимизация возможна.
if is_tail_rec_optimization_requested {
let mut frame = self.stack.top_frame_mut();
let not_native = !method_flags.contains(AccessFlags::NATIVE);
let same_method = frame.class_method_idxs == (class_idx, method_idx);
let last_in_current_method = is_return(frame.pick_u8(self));
let is_tail_rec_optimization_available =
not_native && same_method && last_in_current_method;
if is_tail_rec_optimization_available {
self.perform_call(class_idx, method_idx, &args, &mut frame);
return;
}
}
Если сделать простенький бенчмарк, то можно увидеть даже разницу во времени выполнения.
Fibonacci without optimization = 102334155 (took 376ms)
Fibonacci with optimization = 102334155 (took 90ms)А если включить логирование, то и размер стека будет хорошо виден.
Мемоизация
Возьмём страшный сон любого интервьювера — наивная реализация вычисления чисел Фибоначчи через рекурсию.
public int naiveFibonacci(int nth) {
if (nth <= 0) return 0;
if (nth <= 2) return 1;
return naiveFibonacci(nth - 1) + naiveFibonacci(nth - 2);
}Процессор может довольно долго делать «бррр» , т.к. вызовов тут будет огромное количество. Но если запоминать соответствие аргументов и результата выполнения (и быстро их находить), то вычисление можно ускорить.

Заведём ещё одну аннотацию для этих целей. А с каждым помеченным методом сопоставим словарик, в котором и будут храниться аргументы и значения.
Можно было бы сделать всё это в недрах моей JVM, но я подумал, что неплохо было бы использовать операцию equals, если таковая определена для объектов передаваемых в аргументах. Поэтому делается так:
В момент вызова мемоизированного метода происходит принудительный вызов другого метода, который получает те же аргументы и проводит поиск в словарике. Этот другой метод тоже сделан на java.
В фрейме выставляется специальный флажок. Поэтому когда метод поиска возвращает значение, JVM смотрит на флажок и понимает — надо ли вернуть найденное значение, или ничего не нашлось и надо продолжать выполнение.
Если выполнение продолжилось, то результат сохраняется
Вот как это выглядит в коде.
@RVM.Mem
public Integer naiveFibonacciMem(Integer nth) {
if (nth <= 0) return 0;
if (nth <= 2) return 1;
return naiveFibonacciMem(nth - 1) + naiveFibonacciMem(nth - 2);
}А вот так это выглядит, если все вышеперечисленные операции добавить явно:
//хранится в недрах rjava
private MemEntry naiveFibonacciMemActualMemEntry = null;
public Integer naiveFibonacciMemActual(Integer nth) {
Integer result = (Integer) RVM.getAnswer(naiveFibonacciMemActualMemEntry, nth) ;
if (result != null) return result;
if (nth <= 0) return 0;
if (nth <= 2) return 1;
result = naiveFibonacciMemActual(nth - 1) + naiveFibonacciMemActual(nth - 2);
MemEntry oldEntry = naiveFibonacciMemActualMemEntry;
naiveFibonacciMemActualMemEntry = new MemEntry(new Object[]{nth}, result);
naiveFibonacciMemActualMemEntry.next = oldEntry;
return result;
}
Ну и результат налицо:
Fibonacci without memoization = 832040 (took 1794ms)
Fibonacci with memoization = 832040 (took 1ms)Заключение
JVM — это сложный программный продукт. То, что у меня получилось в итоге, пожалуй не дотягивает до 0.1% той колоссальной работы, что была проделана при реализации HotSpot VM. Да, у меня class-файлы читаются и выполняются, но:
Управление памятью условное. В heap-е всё выделяется как попало. А нужно заботиться и о фрагментации памяти, и о том, чтобы соседние данные лежали рядом, и ещё о куче других вещей
Нет GC. Я попытался сделать что-то очень простое, типа привязываться к стеку и уничтожать объекты при выходе из метода, но такой подход оправдан только в ограниченном числе случаев.
Фактически нет Runtime. Файлы, сеть, устройства ввода/вывода — вот это всё.
Это именно что интерпретатор байт-кода, который не компилирует его в машинный код конкретной архитектуры, как это делает HotSpot. Я изначально думал сделать графики типа «время выполнения куска кода у меня и на HotSpot», но они получились такие смешные, что я не стал :)
Валидация прав доступа, валидация корректности байт-кода, поддержка synchronized…
Ну и далеко не все команды я реализовал, т.к. добавлял их по мере необходимости.
Да и типы данных не все
И массивы примитивов не сделал
С другой стороны, ограниченную и урезанную реализацию JVM можно применять в условиях, где «большая» JVM по какой-то причине не подходит. Может быть из-за ограниченных вычислительных ресурсов, может быть из-за специфичности сценариев. Почему бы, скажем, не писать скрипты для игр не на lua, а на java, используя маленькую встраиваемую JVM? Там и рантайм свой, и часть функциональности можно выкинуть, зато — привычный синтаксис и инструментарий.
Сделанные мною оптимизации — спорный момент. Пока что мне кажется, что лучше бы их выполнял компилятор, а не JVM. Это было бы очевиднее, удобнее в отладке (т.к. компилятор в этом случае может добавить отладочной информации и иметь ввиду выполненные оптимизации), и более портируемо. Да, какие-то сценарии я ускорил, но дополнительные if-ы в коде — это дополнительные if-ы, и выполняются они если не для каждой команды из байт-кода, то для каждого вызова метода, даже когда не нужны. То есть палка о двух концах.
Дальше я, наверное, попробовал бы допилить это чудо до состояния, когда оно запускается и мигает светодиодами на ардуине, а потом сравнить с похожими решениями. Конечно, для этого мне придётся очень сильно перелопатить код. Явно у меня чаще, чем нужно, выполняются копирования кусков памяти (потому что только так можно «обмануть» borrow checker)

Но в общем и целом, я доволен результатом. На всё это у меня ушло примерно 5 полных рабочих дней (размазанных по томным вечерам), за время которых я узнал много нового. Оказалось, что можно взять и выполнить class-файл, именно в этом нет никакой чёрной магии. Вот как это сделать быстро и эффективно — это уже другой разговор.
На этом всё.

Ссылка на проект
