Исследуем и тестируем распределенные вычисления от Hazelcast
Продолжаем тестировать Hazelcast. В предыдущем посте мы познакомились с его очередями. А в этом мы более внимательно взглянем на его возможность распределенного выполнения задач.Работать с данными гораздо эффективнее как можно ближе к ним, а не выкачивать «к себе», потом считать и\или изменять и отправлять обратно в распределенное хранилище. Именно такую возможность нам предоставляет Hazelcast в виде распределенной реализации ExecutorService. Можно управлять и тем, на каких серверах хранить данные, группируя их по общему ключу, и запускать задачи на нужных серверах, используя тот-же ключ.
Мы попытаемся выяснить — так ли это и есть ли какие подводные камни?
Все тесты доступны на GitHub.
И так, поехали. Используется последняя стабильная версия hazelcast — 3.2.3.(в тестах приводятся примерные данные по измерению скорости и количества. Не публикуется и конфигурация тестовой машины. Данные достаточны для сравнения тестов между собой что и является целью)
Test 1 — работаем по старинкеЦель данного теста — замерять производительность при работе без распределенных вычислений для дальнейших сравнений.
Берем два узла и два хранилища (Map). Эмулируем наиболее тяжелый случай, при котором все данные у нас будут не на локальном узле. Т.е. hazelcast будет вынужден скачать данные с другого узла и после их изменения сохранить их так же на другом узле. Создаем все те проблемы, которые должно решить распределенное вычисление задач в будущих тестах.
Ожидаем что быстро забросим 100k задач в очередь, а далее они будут выполнены в 10 потоков.
Результат:
INFO: 100000 713 sec: 0.538INFO: Done tasks: 100000 sec: 15.470
Ожидания оправдались. Забросили 100k быстро — за пол секунды. Во время заброса успело выполниться только 713 задач. Все задачи выполнились за 15,5 секунд.
Test 2 — распределенные вычисления Теперь включим распределенные вычисления от hazelcast. Так же запускаем самый тяжелый случай когда нужные данные на втором узле. Но теперь hazelcast должен это определить и отправить задачу на второй узел и там ее запустить.
Ожидаем что быстро забросим 100k задач в очередь, а далее они будут выполнены так же в 10 потоков (это мы указали в конфигурации hazelcast), но быстрее чем в первом тесте. Дополнительно регистрируем — на каком узле выполнялись задачи.
Результат:
INFO: 100000 99998 sec: 6.308INFO: Done tasks: hz1: 0 hz2: 100000 sec: 6.319
Видим что все задачи выполнились на втором узле (hz2: 100000) и увеличение скорости больше чем в два раза. Это очень хорошо. Тем более эта разница будет расти с ростом объемов обрабатываемых данных в реальности. Сейчас то у нас в хранилище сидят только целые числа.
Но что-то очень непонятное происходит с забросом. Видно что заброс стал очень медленный. Во время заброса выполнились почти все задачи. Эту загадку мы немного отложим, а сейчас посмотрим на более жизненный тест.
Test 3 — еще больше реальности В этом тесте мы уже не будем искусственно создавать задачи только для второго узла. В реальной жизни будут и светлые моменты, когда данные окажутся на том же узле где и инициируются вычисления.
Ожидаем что скорость будет еще выше. Ожидаем близкое к равномерному распределение задач по узлам.
Результат:
INFO: 100000 99857 sec: 5.241INFO: Done tasks: hz1: 50818 hz2: 49182 sec: 5.252
Ожидания оправдались. Видим нормальное распределение задач по узлам (hz1: 50818 hz2: 49182) и скорость выполнения быстрее на секунду.
Test 4 — выполняем медленные задачи Задачи задачам рознь. Некоторые могут и ресурсы ввода вывода эксплуатировать в процессе работы. Поэтому попробуем выполнить медленные задачи (добавим задержку их выполнения 10 миллисекунд). Кроме того нам интересен обнаруженный ранее эффект, что задачи практически все успевают выполнится во время их заброса. Возможно дело в том что они быстрые и появились накладные расходы hazelcast по сравнению с первым тестом?
Не ожидаем снижения времени на заброс задач. Ожидаем увеличение времени выполнения всех задач.
Результат:
INFO: 100000 99978 sec: 59.442INFO: Done tasks: hz1: 49522 hz2: 50478 sec: 59.455
Заброс так же катастрофически замедлился. Это странно, тем более что мы используем метод заброса executorService.executeOnKeyOwner, который в отличии от executorService.submitToKeyOwner не предполагает ожидания результата выполнения. Должен бросить задачу и забыть.
Читаем исходники. Первый момент (код можно пропустить, выводы ниже):
public void executeOnKeyOwner (Runnable command, Object key) { Callable callable = createRunnableAdapter (command); submitToKeyOwner (callable, key); }
Hazelcast преобразует наш вызов в Future
Второй момент еще интересней (код можно пропустить, выводы ниже):
public static final int SYNC_FREQUENCY = 100; private final AtomicInteger consecutiveSubmits = new AtomicInteger (); private volatile long lastSubmitTime; … … boolean sync = ! preventSync && checkSync (); CallableTaskOperation op = new CallableTaskOperation (name, uuid, task); ICompletableFuture future = invoke (partitionId, op); if (sync) { Object response; try { response = future.get (); … … /** * This is a hack to prevent overloading the system with unprocessed tasks. Once backpressure is added, this can * be removed. */ private boolean checkSync () { boolean sync = false; long last = lastSubmitTime; long now = Clock.currentTimeMillis (); if (last + 10 < now) { consecutiveSubmits.set(0); } else if (consecutiveSubmits.incrementAndGet() % SYNC_FREQUENCY == 0) { sync = true; } lastSubmitTime = now; return sync; } По коду видно, что если в ExecutorService придет 100 запросов подряд с интервалом менее 10 миллисекунд, то hazelcast принудительно блокирует текущий поток (100ого запроса) на ожидании результата выполнения задачи.
Мы не будем разбирать глубоко причины по которым так сделано, а акцентируемся на последствии для нас. При наступлении данных условий, т.е. при большом количестве добавляемых задач, добавляющая их сторона становится зависима от времени их выполнения. Чем более тяжелая задача, тем больше будет время блокировки. Это случится так же и на задачах, где не нужно ожидать результат их выполнения.
Идем дальше
Test 5 — обходим хак хаком В реальности может быть много серверов и много в них пользователей и много еще чего, что приведет нас к ситуации в тесте 4. Но может быть и так, что искусственная задержка в коде hazelcast не сработает. Эту ситуацию мы и попробуем смоделировать. Добавим при забросе каждой 100 ой задачи искусственную задержку.
Ожидаем что код hazelcast перестанет блокировать заброс. Увеличится время заброса.
Результат:
INFO: 100000 25223 sec: 13.350INFO: Done tasks: hz1: 49257 hz2: 50743 sec: 52.837
Видно что время заброса сократилось и к его концу успело выполнится только 25k задач. Таким образом, если очень нужно быстро забросить много задач, то все-таки это сделать можно. Но надо понимать что это приведет к нагрузке на hazelcast (задачи сильно оттянут одеяло на себя) и к увеличению потребляемой памяти на той стороне, где они будут копиться во внутренней очереди.
Если в этом тесте ограничить память, 64 мегабайтами то мы получим OOME
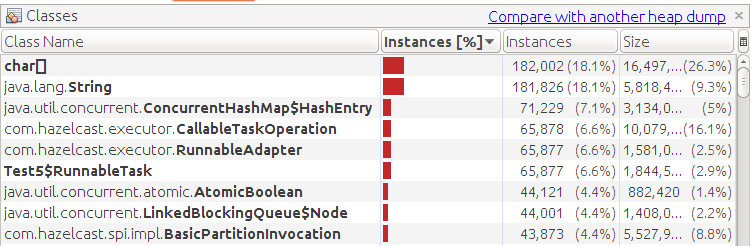
Видно скопление наших задач. Хотя съели память вспомогательные объекты, но это особенность теста. Наша задача — это очень легковесный объект.
Test 6 — убираем OOME Hazelcast дает нам возможность установить предел для очереди задач. Тем самым мы можем избежать перерасхода памяти. Попробуем выставить этот предел в тысяч 10.
В результате мы начинаем видеть в консоли много таких вот предупреждений:
WARNING: [10.0.0.3]:5701 [dev] [3.2.3] While executing RunnableAdapter{task=Test6$RunnableTask@219307f2} on Executor[exe] java.util.concurrent.RejectedExecutionException: Executor[exe] is overloaded! at com.hazelcast.util.executor.CachedExecutorServiceDelegate.execute (CachedExecutorServiceDelegate.java:98)
Смотрим код:
public void execute (Runnable command) { if (! taskQ.offer (command)) { throw new RejectedExecutionException («Executor[» + name + »] is overloaded!»); } … Если очередь наполнена полностью, то новые задачи в нее не помещаются и соответственно — не выполняются. Если задачи забрасываются без ожидания результата (методом executeOnKeyOwner), то клиент и не узнает о том что они не выполнились.
И общий результат понятен:
INFO: 100000 32604 sec: 16.931INFO: Done tasks: hz1: 26304 hz2: 26281 sec: 27.269
Почти половина задач не выполнены.
Test 7 — анализ ошибок клиентом И в последнем тесте ответим на вопрос — может ли клиент, закидывающий задачи понять, что они не отработали? Для этого заменим метод executeOnKeyOwner на Future submitToKeyOwner и нашу задачу изменим на Callable чтоб сообщала результат вычислений.
Получаем следующий результат:
INFO: 100000 31790 sec: 16.713INFO: Done tasks: hz1: 25898 hz2: 25873 sec: 27.046INFO: Canceled tasks: 0 execution exceptions: 48229 rejected tasks: 48229
С этим все в порядке. Клиент может подготовиться к данной ситуации.
Некоторые выводы hazelcast может не явно тормозить код, запускающий выполнение распределенных задач если они запускаются с частотой менее 10 миллисекунд и их более 99; есть способ обойти это искусственное замедление, но надо понимать риски; возможны ситуации, когда искусственное торможение не будет срабатывать и большое количество задач будет скапливаться на серверах. Нужно это прогнозировать и не попасть на OOM; при ограничении размера очереди возможно ее переполнение и появятся отвергнутые задачи. К этому может быть готов клиент; Ну и главный вывод — распределенное выполнение задач кардинально увеличивает производительность. И тем больше увеличивает, чем больший объем данных с которым приходится манипулировать в рамках задачи. Не забывая о выявленных моментах можно с пользой использовать данную фичу в проектах.
