Исследуем и тестируем очереди от Hazelcast
Многие из нас слышали о Hazelcast. Это удобный продукт, который реализует различные распределенные объекты. В частности: key-value хранилища, очереди, блокировки и т.д. К нему в целом применяются утверждения о распределенности, масштабируемости, отказоустойчивости и другие положительные свойства.Так ли это применительно к его реализации очередей? Где границы их использования? Это мы и попытаемся выяснить.
Все тесты доступны на GitHub. На всех устанавливалось ограничение памяти JVM в 64mb для ускорения достижения цели, дамп памяти при ее переполнении (OOM) и принудительное убиение приложение в случае возникновения этой беды
-Xms64m -Xmx64m -XX:+HeapDumpOnOutOfMemoryError -XX: HeapDumpPath=/tmp -XX: OnOutOfMemoryError=«kill -9%p
И так, поехали. Используется последняя стабильная версия hazelcast — 3.2.3.(в тестах приводятся примерные данные по измерению скорости и количества. Не публикуется и конфигурация тестовой машины. Данные достаточны для сравнения тестов между собой что и является целью)
Тест 1 — память не безмернаВ первом тесте мы будем использовать один узел hazelcast. Создаем очередь и добавляем туда элементы пока не упадем от нехватки памяти.
Результат ожидаем. Удалось записать 460 тысяч объектов со скоростью 0.026ms на один элемент. Эти данные нам будут полезны далее для сравнения.
Изучаем дамп памяти:
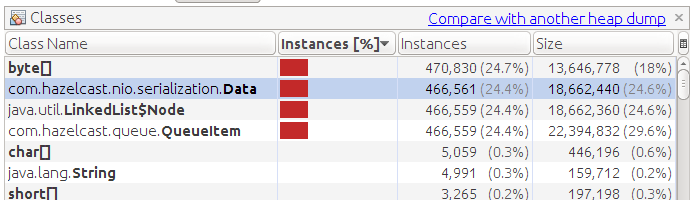
Видим большое количество объектов QueueItem. Этот внутренний объект создается для каждого элемента очереди. Содержит в себе уникальный идентификатор элемента и собственно сами данные (объект Data)
Тест 2 — подключаем хранилище Для того чтобы не хранить данные в памяти и тем самым освободить ее, мы можем подключить к очереди хранилище. Для теста мы подготовили MockQueueStore, которое ничего не делает, но исправно изображает хранилище, теряя все посланные в него элементы. Укажем параметр «memory-limit=0» для того чтобы совсем исключить хранение данных в памяти (по умолчанию хранится 1000 элементов).
Наши ожидания в избавлении от OOM, но не тут то было. Удалось записать больше объектов — 980k, но мы все равно упали.
Смотрим дамп памяти:
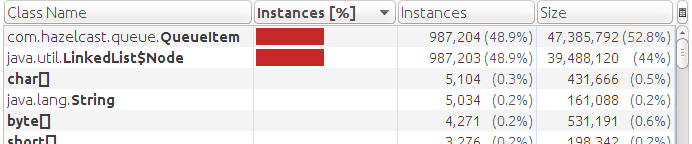
Видно что объектов типа Data нет, но QueueItem по прежнему в памяти. Это первое наше открытие. Реализация очередей hazelcast (QueueContainer) не избавляется от вспомогательного объекта при наличии хранилища. Она всегда их хранит во внутренней очереди (LinkedList).
Данное обстоятельство не позволит применять очереди там, где потенциально возможен их не контролируемый рост в объемы, превышающие наличие свободной памяти. Это не ставит крест, отнюдь. В 50 мегабайт влазит примерно миллион элементов. Не на всяких задачах возможно такое количество, да и памяти поболее будет в реальности. Но помнить о данном ограничении необходимо. Идем дальше.
Тест 3 — подсмотренная фича с транзакциями Читая исходники реализации была обнаружена еще одна фича или баг. Hazelcast позволяет нам манипулировать своими распределенными объектами в транзакции. Давайте посмотрим что будет если мы в третий тест добавим транзакции во время добавления элементов.
Получаем OOM примерно на 250k элементах очереди. Смотрим дамп:
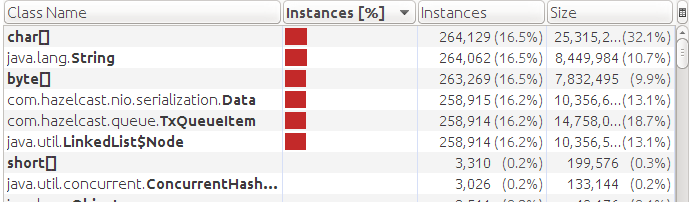
Видим что присутствует хранение данные в памяти (Data) хотя у нас подключено хранилище. И вместо объектов QueueItem используются TxQueueItem. Это все следствие реализации. При использовании транзакций не производится сброс данных в хранилище. А так как объект TxQueueItem это наследник QueueItem с доп полями, потребляющий больше памяти, то мы получили даже меньше элементов до OMM чем в первом тесте.
Вывод — транзакции и хранилище для очередей не работают вместе.
Двинемся дальше. Посмотрим как работают очереди в кластере.
Тест 4 — просто два узла Не используем никакие доп настройки очередей. Все по умолчанию. Без хранилища. Укладываем и читаем 100k элементов. Укладываем и читаем в узел, владеющий очередью. Последнее иногда важно для скорости доступа к данным. Дело в том, что в отличии от Map, реализация очередей не распределенная. Все элементы очереди живут на одном из узлов кластера — у владельца очереди. Если точнее — у владельца партиции к которой принадлежит очередь. Мы ожидаем, что доступ будет быстрый — как без кластера так как взаимодействуем с владельцем.
В результате имеем следующую скорость: INFO: add 100000 0.255msINFO: poll 100000 0.223ms
Скорость упала на порядок (по сравнению с 0.026ms в первом тесте). Дело в том, что по умолчанию для очереди используется один бэкап. И hazelcast при добавлении и чтении синхронизировал данные со вторым узлом.
Тест 4_1 — попробуем работать не с владельцем А если ли разница в скорости, если добавлять в очередь и читать не с владельца партиции?
Оказывается существенной разницы нет: INFO: add 100000 0.215msINFO: poll 100000 0.201ms
Видим сравнимую скорость. Также как в тесте 4, оба узла выполняют схожий набор операций и от перемены мест слагаемых результат практически не меняется. Фактическая работа идет с владельцем очереди через посредника содержащего бэкап.
Тест 5 — убьем владельца Попробуем после заполнения очереди убить узел, являющийся владельцем очереди. И прочитать данные с оставшегося узла. Получаем следующий результат:
INFO: add 100000 0.267msINFO: poll 100000 0.025ms
Один оставшийся узел начинает работать на порядок быстрее. Он остается один в кластере и не тратить ресурсы на коммуникации по созданию бэкапа.
Тест 6 — выключаем бэкап Посмотрим что будет если в конфигурации очереди отключить бэкап и как в предыдущем тесте — удалить владельца.
INFO: add 100000 0.022ms
Результат — большая скорость работы с владельцем очереди. Он не тратит ресурсы на бэкап. Но после его падения — вся очередь теряется.
Тест 7 — подключим хранилище к кластеру Бэкапа у нас нет и совершенно справедливо мы потеряли все данные после гибели узла — владельца очереди. Давайте подключим хранилище к этой конфигурации и посмотрим, выживут ли данные? Хранилище подсунем чуть более умное, чтоб хранило и отдавало данные из памяти (MemoryQueueStore).
Результат:
INFO: add 100000 0.023msINFO: poll 100000 0.018ms
Видим что скорость везде хорошая — на порядок выше чем с бэкапом. Видим также, что очередь восстановилась на оставшемся узле.
Немного деталей про восстановление очереди на втором узле. В этом процессе сначала считываются все ключи из хранилища в память реализацией QueueContainer и определяется наибольшее значение из них для дальнейшей генерации новых. Заполняется внутренняя очередь на LinkedList сразу всеми элементами очереди, но без данных. Для того чтобы порядок элементов в очереди после восстановления из хранилища сохранился — хранилище должно выдавать их в правильном порядке в наборе (Set). Далее по необходимости подгружаются данные из хранилища. Подгрузка идет пачками. По умолчанию по 250 штук.
Некоторые выводы Использование хранилища не освобождает полностью память. Надо прогнозировать объем данных и не попасть на OOM При использовании хранилища надо принудительно отключать бэкап. По умолчанию он включен и будет влиять на скорость и используемую память других узлов Реализация восстановления очереди из хранилища ресурсоемкая и не оптимальная. При восстановлении новый владелец должен иметь не меньше памяти чем предыдущий Ну и конечно продолжать тестировать продукты перед их использованием на критических задачах.
PS: Путь исправления реализации QueueContainer оставлен за рамками этого документа. Надеюсь будут время и силы с этим тоже поделиться.
