Исследование возможных заимствований и нарушений условий лицензирования в Java-коде на GitHub
Меня зовут Ярослав Голубев, я работаю в JetBrains Research, в лаборатории методов машинного обучения в программной инженерии. Некоторые мои коллеги уже писали здесь о своих проектах (например, о подсказках для онлайн-курсов). Общая цель нашей группы — сделать работу программистов проще, удобнее и эффективнее, используя данные о том, что и как люди программируют. Однако процесс создания программных продуктов состоит не только из написания кода — есть еще документация, комментарии, рабочие обсуждения и многое другое — и со всем этим людям тоже можно и нужно помогать.
Одним из таких побочных аспектов разработки программного обеспечения является лицензирование кода. Некоторым разработчикам лицензирование кажется несколько темным лесом, они стараются в это не влезать и либо не понимают различий и правил лицензий вообще, либо знают о них довольно поверхностно, из-за чего могут допускать различного рода нарушения. Самым частым таким нарушением является копирование (переиспользование) и модификация кода с нарушением прав его автора.
Любая помощь людям начинается с исследования сложившейся ситуации — во-первых, сбор данных необходим для возможности дальнейшей автоматизации, а во-вторых, их анализ позволит нам узнать, что именно люди делают не так. В этой статье я опишу именно такое исследование: познакомлю вас с основными видами лицензий ПО (а также несколькими редкими, но примечательными), расскажу об анализе кода и поиске заимствований в большом объеме данных и дам советы о том, как правильно обращаться с лицензиями в коде и не допускать распространенных ошибок.
Введение в лицензирование кода
В интернете, и даже на Хабре, уже есть подробные описания лицензий, так что мы ограничимся лишь кратким обзором темы, необходимым для понимания сути исследования.
Мы с вами будем говорить только о лицензировании открытого (open-source) программного обеспечения. Во-первых, это связано с тем, что именно в такой парадигме мы можем легко найти много доступных данных, а во-вторых, сам термин «открытое ПО» способен ввести в заблуждение. Когда вы скачиваете и устанавливаете обычную проприетарную программу с сайта компании, вас просят согласиться с условиями лицензии. Разумеется, вы их обычно не читаете, но в целом понимаете, что это чья-то интеллектуальная собственность. В то же время, когда разработчики заходят в проект на GitHub и видят все исходные файлы, отношение к ним совсем другое: да, какая-то лицензия там есть, но она же открытая, и программное обеспечение это открытое, значит, можно просто брать и делать что хочешь, так? К сожалению, не все так просто.
Как же устроено лицензирование? Начнем с самого общего деления прав:
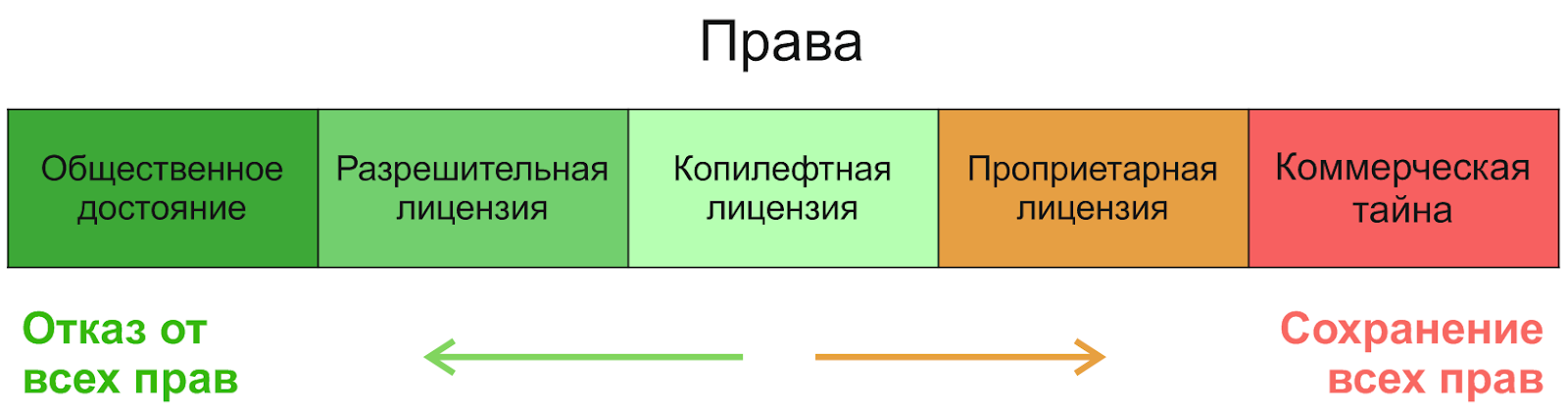
Если идти справа налево, то первой будет коммерческая тайна, за ней проприетарные лицензии — их мы рассматривать не будем. В сфере открытого программного обеспечения можно выделить три категории (по степени увеличения свобод): ограничивающие лицензии (копилефтные), неограничивающие лицензии (разрешительные, пермиссивные) и общественное достояние (которое не является лицензией, но является способом предоставления прав). Чтобы понять разницу между ними, полезно знать, зачем они вообще появились. Понятие общественного достояния старо как мир — создатель полностью отказывается от любых прав и позволяет делать со своим продуктом что угодно. Однако, как ни странно, из этой свободы рождается несвобода — ведь другой человек может взять такое творение, чуть изменить его и делать с ним «что угодно» — в том числе сделать закрытым и продать. Копилефтные лицензии открытого программного обеспечения были созданы, именно чтобы защитить свободу — по их положению на картинке видно, что они призваны поддерживать баланс: разрешать использовать, изменять и распространять продукт, но не запирать его, оставлять свободным. Кроме того, даже если автор не против сценария с закрытием и продажей, понятия общественного достояния в разных странах отличаются и поэтому могут создать юридические сложности. Чтобы их избежать, используются простые разрешительные лицензии.
Так в чем же различие между разрешительными и копилефтными лицензиями? Как и все в нашей теме, этот вопрос достаточно специфический, и здесь есть исключения, но если упростить, то разрешительные лицензии не накладывают ограничений на лицензию измененного продукта. То есть можно взять такой продукт, изменить его и выложить в проект под другой лицензией — даже проприетарной. Главным отличием от общественного достояния тут чаще всего является обязательство сохранять авторство и упоминание оригинального автора. Наиболее известными разрешительными лицензиями являются лицензии MIT, BSD и Apache. Многие исследования указывают MIT как наиболее распространенную лицензию открытого программного обеспечения вообще, а также отмечают значительный рост популярности лицензии Apache-2.0 с момента ее создания в 2004 году (например, исследование для Java).
Копилефтные лицензии чаще всего накладывают ограничения на распространение и модификацию побочных продуктов — вы получаете продукт, имея определенные права, и обязаны «запустить его дальше», предоставляя всем пользователям такие же права. Обычно это означает обязательство распространять программное обеспечение в рамках той же лицензии и предоставлять доступ к исходному коду. На основе такой философии Ричард Столлман создал первую и самую популярную копилефтную лицензию GNU General Public License (GPL). Именно она обеспечивает максимальную защиту свободы для будущих пользователей и разработчиков. Рекомендую почитать историю движения Ричарда Столлмана за свободное программное обеспечение, это очень интересно.
С копилефтными лицензиями есть одна сложность — их традиционно делят на сильный и слабый копилефт. Сильный копилефт представляет собой ровно то, что описано выше, в то время как слабый копилефт предоставляет различные послабления и исключения для разработчиков. Наиболее известный пример такой лицензии — GNU Lesser General Public License (LGPL): так же как и ее старшая версия, она разрешает изменять и распространять код только при условии сохранения данной лицензии, однако при динамическом линковании (использовании ее как библиотеки в приложении) это требование можно не выполнять. Иными словами, если вы хотите позаимствовать отсюда исходный код или что-то поменять — соблюдайте копилефт, но если хотите просто использовать как динамически подключаемую библиотеку — можете делать это где угодно.
Теперь, когда мы разобрались в самих лицензиях, следует поговорить об их совместимости, ведь именно в ней (а вернее, ее отсутствии) кроются нарушения, которые мы хотим предотвратить. Каждый, кто когда-нибудь интересовался данной темой, должен был встречать схемы совместимости лицензий, похожие на эту:

От одного взгляда на такую схему может пропасть всякое желание разбираться в лицензиях. Действительно, лицензий открытого программного обеспечения много, достаточно исчерпывающий список можно найти, например, тут. В то же время, как вы увидите ниже в результатах нашего исследования, знать нужно весьма ограниченное количество (из-за их экстремально неравномерного распределения), а правил, которые нужно помнить для того, чтобы соблюдать все их условия, и того меньше. Общий вектор этой схемы довольно прост: в истоке всего стоит общественное достояние, за ним разрешительные лицензии, потом слабый копилефт, и, наконец, сильный копилефт, и лицензии совместимы «вправо»: в копилефтном проекте можно переиспользовать код под разрешительной лицензией, но не наоборот — все логично.
Тут может возникнуть вопрос:, а что, если у кода нет лицензии? Каким правилам следовать тогда? Такой код можно копировать? На самом деле это очень важный вопрос. Наверное, если код написан на заборе, то его можно считать общественным достоянием, а если он написан на бумаге в бутылке, которую прибило к необитаемому острову (без копирайта), то его можно просто брать и использовать. Когда же дело касается больших и устоявшихся платформ, таких как GitHub или StackOverflow, все не так просто, потому что, просто пользуясь ими, вы автоматически соглашаетесь с их условиями использования. Пока просто оставим об этом заметку в голове и вернемся к этому позже — в конце концов, быть может, это редкость и кода без лицензии практически не бывает?
Постановка задачи и методология
Итак, теперь, когда мы знаем значение всех терминов, давайте точно сформулируем, что мы хотим узнать.
- Насколько распространено копирование кода в открытом программном обеспечении? Много ли среди открытых проектов клонов в коде?
- Под какими лицензиями существуют файлы? Какие лицензии наиболее распространены? Бывает ли в файле сразу несколько лицензий?
- Какие возможные заимствования, то есть переходы кода из одной лицензии в другую, встречаются чаще всего?
- Какие возможные нарушения, то есть переходы кода, запрещенные условиями оригинальной или принимающей лицензии, наиболее распространены?
- Каково возможное происхождение отдельных фрагментов кода? Какова вероятность, что данный фрагмент кода был скопирован с нарушением?
Чтобы провести такой анализ, нам необходимо:
- Собрать датасет из большого количества открытых проектов.
- Найти среди них клоны фрагментов кода.
- Определить те клоны, которые действительно могут являться заимствованиями.
- Для каждого фрагмента кода определить два параметра — его лицензию и время его последней модификации, которое необходимо, чтобы узнать, какой фрагмент в паре клонов старше, а какой младше, и следовательно — кто мог потенциально скопировать у кого.
- Определить, какие возможные переходы между лицензиями являются разрешенными, а какие нет.
- Проанализировать все полученные данные, чтобы ответить на вышепоставленные вопросы.
Теперь разберем каждый шаг подробнее.
Сбор данных
Для нас очень удобно, что в наше время легко получить доступ к большому количеству открытого кода с помощью GitHub. Там есть не только сам код, но и история его изменений, что очень важно для данного исследования: чтобы выяснить, кто у кого мог скопировать код, необходимо знать, когда каждый фрагмент был добавлен в проект.
Для сбора данных нужно определиться с исследуемым языком программирования. Дело в том, что клоны ищутся в рамках одного языка программирования: говоря о нарушении лицензирования, сложнее оценить переписывание существующего алгоритма на другой язык. Такие сложные концепции защищаются патентами, в то время как в рамках нашего исследования мы говорим про более типичные копирование и модификацию. Мы выбрали язык Java, так как это один из самых широко используемых языков, который особенно популярен в коммерческой разработке ПО — в этом случае потенциальные нарушения лицензирования особенно важны.
За основу мы взяли существующий Public Git Archive, в начале 2018 года собравший воедино все проекты на GitHub, у которых было более 50 звездочек. Мы отобрали все проекты, в которых есть хотя бы одна строчка на Java и скачали их с полной историей изменений. После фильтрации проектов, которые переехали или более недоступны, получилось 23 378 проектов, занимающих примерно 1,25 ТБ места на жестком диске.
Дополнительно для каждого проекта мы выгрузили список форков и нашли пары форков внутри нашего датасета — это необходимо для дальнейшей фильтрации, так как клоны между форками нас не интересуют. Всего проектов, имеющих форки внутри датасета, оказалось 324 штук.
Поиск клонов
Для поиска клонов, то есть похожих кусков кода, тоже необходимо принять некоторые решения. Во-первых, нужно определиться, насколько и в каком качестве нам интересен похожий код. Традиционно выделяют 4 типа клонов (от самых точных до наименее точных):
- Идентичные клоны — это абсолютно одинаковые фрагменты кода, которые могут отличаться только стилистическими решениями, такими как отступы, пустые строки и комментарии.
- Переименованные клоны включают в себя первый тип, но могут дополнительно отличаться именами переменных и объектов.
- Близкие клоны включают в себя все вышеописанное, но могут содержать более значительные изменения, такие как добавление, удаление или перемещение выражений, при которых фрагменты все еще остаются похожими.
- Наконец, семантические клоны — это фрагменты кода, реализующие один и тот же функционал (имеющий одинаковую семантику), но отличающиеся в реализации (синтаксически).
Нас интересует именно копирование и модификация, поэтому мы рассматриваем только клоны первых трех типов.
Второе важное решение заключается в том, какого размера искать клоны. Одинаковые фрагменты кода можно искать среди файлов, классов, методов, отдельных выражений… В нашей работе мы взяли за основу метод, так как это наиболее сбалансированная гранулярность поиска: часто люди копируют код не целыми файлами, а небольшими фрагментами, но вместе с тем метод — это все еще законченная логическая единица.
Исходя из выбранных решений, для поиска клонов мы использовали SourcererCC — инструмент, который ищет клоны методом мешка слов: каждый метод представляется как частотный список токенов (ключевых слов, имен и литералов), после чего такие множества сравниваются, и если больше определенной доли токенов в двух методах совпадает (такая доля называется порогом схожести), то такая пара считается клоном. Несмотря на простоту такого метода (существуют гораздо более сложные методы, основанные на анализе синтаксических деревьев методов и даже их графов программной зависимости), его главным преимуществом является масштабируемость: при таком огромном объеме кода, как у нас, важно, чтобы поиск клонов осуществлялся очень быстро.
Мы использовали различные пороги схожести, чтобы найти разные клоны, а также отдельно провели поиск с порогом схожести 100%, в котором определялись только идентичные клоны. Кроме того, был установлен минимальный исследуемый размер метода, чтобы отбросить тривиальные и универсальные фрагменты кода, которые могут не является заимствованиями.
Такой поиск занял целых 66 суток непрерывных вычислений, было определено 38,6 миллиона методов, из которых только 11,7 миллиона проходили минимальный порог по размеру, а из них 7,6 миллиона приняли участие в клонировании. Всего обнаружилось 1,2 миллиарда пар клонов.
Время последней модификации
Для дальнейшего анализа мы отобрали только межпроектные пары клонов, то есть пары похожих фрагментов кода, которые встречаются в разных проектах. С точки зрения лицензирования нас мало интересуют фрагменты кода в рамках одного проекта: повторять свой же код считается плохой практикой, но не запрещено. Всего межпроектных пар оказалось примерно 561 миллион, то есть приблизительно половина всех пар. Данные пары включали в себя 3,8 миллиона методов, для которых и нужно было определить время последней модификации. Для этого к каждому файлу (которых оказалось 898 тысяч, потому что в файлах может быть более одного метода) была применена команда git blame, которая выдает время последней модификации для каждой строки в файле.
Таким образом, у нас есть время последней модификации для каждой строки в методе, но как определить время последней модификации всего метода? Кажется, что это очевидно — берешь самое недавнее из времен и используешь его: в конце концов, это действительно показывает, когда метод менялся в последний раз. Однако для нашей задачи такое определение неидеально. Рассмотрим пример:
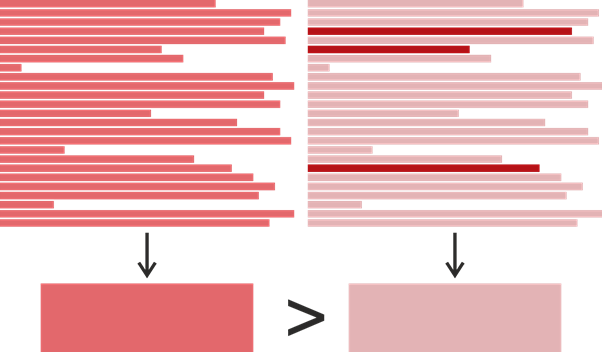
Предположим, мы нашли клон в виде пары фрагментов, каждый по 25 строчек. Более насыщенный цвет тут означает более позднее время модификации. Допустим, фрагмент слева был написан за раз в 2017 году, а во фрагменте справа 22 строчки были написаны в 2015, а три модифицированы в 2019. Выходит, фрагмент справа был модифицирован позднее, однако если бы мы хотели определить, кто у кого мог скопировать, логичнее было бы предположить обратное: левый фрагмент заимствовал правый, а правый позднее незначительно поменялся. Исходя из этого, мы определяли время последнего изменения фрагмента кода как наиболее часто встречающееся время последнего изменения его отдельных строк. Если вдруг таких времен было несколько, выбиралось более позднее.
Интересно, что наиболее старый фрагмент кода в нашем датасете был написан аж в апреле 1997 года, на самой заре создания Java, — и у него нашелся клон, сделанный в 2019!
Определение лицензий
Вторым и наиболее важным этапом является определение лицензии для каждого фрагмента. Для этого мы использовали следующую схему. Для начала с помощью инструмента Ninka определялась лицензия, указанная непосредственно в заголовке файла. Если таковая есть, то она и считается лицензией каждого метода в нем (Ninka способна распознавать и несколько лицензий одновременно). Если же в файле ничего не указано, либо указано недостаточно информации (например, только копирайт), то использовалась лицензия всего проекта, к которому относится файл. Данные о ней содержались в оригинальном Public Git Archive, на основании которого мы собирали датасет, и определялись с помощью другого инструмента — Go License Detector. Если же лицензии нет ни в файле, ни в проекте, то такие методы отмечались как GitHub, так как в таком случае они подчиняются условиям использования GitHub (именно оттуда были скачаны все наши данные).
Определив таким образом все лицензии, мы можем, наконец, ответить на вопрос, какие лицензии наиболее популярны. Всего мы обнаружили 94 различные лицензии. Приведем здесь статистику для файлов, чтобы скомпенсировать возможные перегибы из-за очень больших файлов с большим количеством методов.
Главная особенность данного графика состоит в сильнейшей неравномерности распределения лицензий. На графике можно заметить три области: две «лицензии» с более чем 100 тысячами файлов, еще десять с 10–100 тысячами и длинный хвост из лицензий с менее чем 10 тысячами файлов.
Рассмотрим сначала наиболее популярные, для чего представим первые две области в линейной шкале:
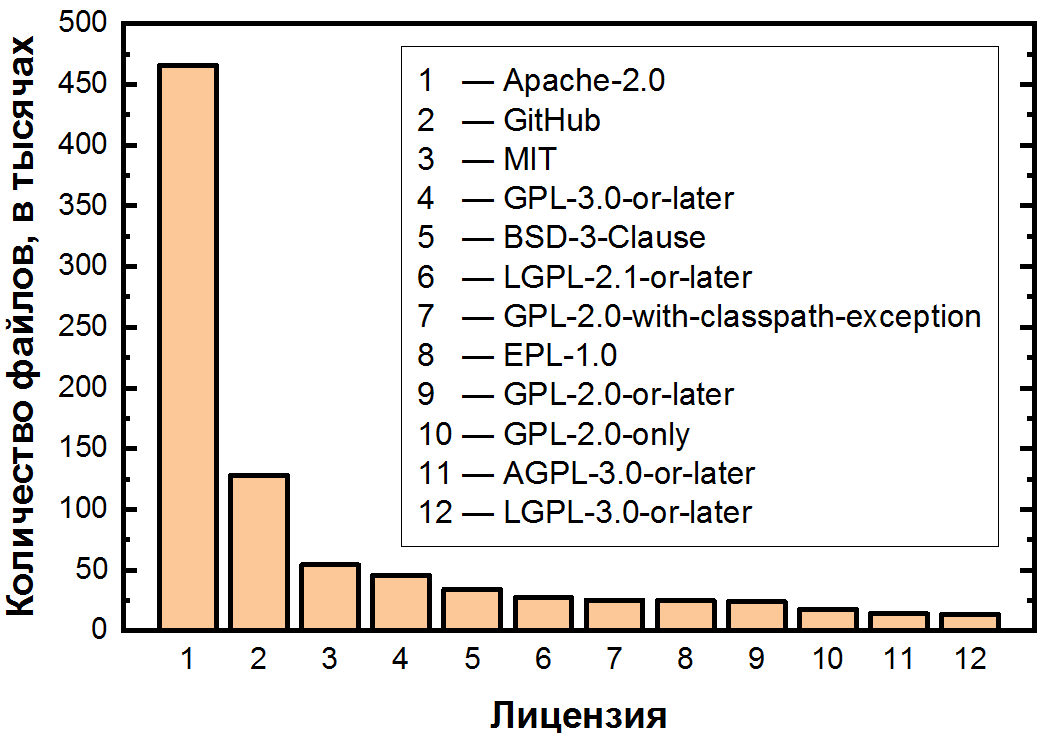
Видна неравномерность даже среди самых популярных лицензий. С огромным отрывом на первом месте расположилась Apache-2.0 — самая сбалансированная из всех разрешительных лицензий, она покрывает чуть более половины всех файлов.
Следом за ней находится пресловутое отсутствие лицензии, и нам все же придется разобрать его подробнее, раз уж данная ситуация настолько часто встречается даже среди средних и крупных репозиториев (более 50 звезд). Данное обстоятельство очень важно, поскольку просто загрузка кода на GitHub не делает его открытым — и если что-то практическое и нужно запомнить из данной статьи, то это оно. Загружая код на GitHub, вы соглашаетесь с условиями использования, которые гласят, что ваш код можно будет просматривать и форкать. Однако за исключением этого, все права на код остаются у автора, поэтому распространение, модификация и даже использование требуют явного разрешения. Получается, мало того, что не весь открытый код является полностью свободным, даже не весь код на GitHub является в полном смысле открытым! И так как такого кода много (14% файлов, а среди менее популярных проектов, не вошедших в датасет, скорее всего, и того больше), это может являться причиной значительного количества нарушений.
В пятерке мы также видим уже упомянутые разрешительные лицензии MIT и BSD, а также копилефтную GPL-3.0-or-later. Лицензии из семейства GPL разнятся не только значительным количеством версий (полбеды), но еще и припиской «or later», которая позволяет пользователю использовать условия данной лицензии или ее более поздних версий. Это наводит еще на один вопрос: среди этих 94 лицензий явно встречаются подобные «семейства» — какие из них самые большие?
На третьем месте как раз GPL-лицензии — их в списке 8 видов. Именно это семейство самое значимое, потому что вместе они покрывают 12,6% файлов, уступая только Apache-2.0 и отсутствию лицензии. На втором месте, неожиданно, BSD. Кроме традиционной версии с 3 параграфами и даже версий с 2 и 4 пунктами, существуют очень специфичные лицензии — всего 11 штук. К таким, например, относится BSD 3-Clause No Nuclear License, которая представляет собой обычную BSD с 3 пунктами, к которой снизу приписано, что данное ПО не должно применяться для создания или эксплуатации ничего ядерного:
You acknowledge that this software is not designed, licensed or intended for use in the design, construction, operation or maintenance of any nuclear facility.
Самым разнообразным является семейство лицензий Creative Commons, о которых можно почитать тут. Их встретилось целых 13 и их тоже стоит хотя бы пробежать глазами по одной важной причине: весь код на StackOverflow лицензирован под СС-BY-SA.
Среди более редких лицензий есть некоторые примечательные, например, Do What The F*ck You Want To Public License (WTFPL), которая покрывает 529 файлов и позволяет делать с кодом именно то, что указано в названии. Есть еще, например, Beerware License, которая также разрешает делать что угодно и призывает купить автору пива при встрече. В нашем датасете мы также встретили вариацию этой лицензии, которую больше нигде не нашли — Sushiware License. Она, соответственно, призывает купить автору суши.
Еще любопытна ситуация, когда в одном файле (именно в файле) встречается сразу несколько лицензий. В нашем датасете таких файлов всего 0,9%. 7,4 тысячи файлов покрываются сразу двумя лицензиями, и всего обнаружилось 74 разные пары таких лицензий. 419 файлов покрывается аж тремя лицензиями, и таких троек насчитывается 8. И, наконец, один файл в нашем датасете упоминает четыре разные лицензии в заголовке.
Возможные заимствования
Теперь, когда мы поговорили о лицензиях, можно обсудить отношения между ними. Первое, что необходимо сделать, это убрать клоны, которые не являются возможными заимствованиями. Напомню, что на данный момент мы постарались учесть это двумя способами — минимальным размером фрагментов кода и исключением клонов внутри одного проекта. Теперь мы отфильтруем еще три типа пар:
- Нас не интересуют пары между форком и оригиналом (а также, например, между двумя форками одного проекта) — для этого мы их и собирали.
- Нас также не интересуют клоны между различными проектами, принадлежащими одной организации или пользователю (так как мы предполагаем, что авторские права в рамках одной организации разделены).
- Наконец, вручную проверяя аномально большое количество клонов между двумя проектами, мы нашли значимые зеркала (они же непрямые форки), то есть одинаковые проекты, загруженные в несвязанные репозитории.
Любопытно, что из оставшихся пар целых 11,7% составляют идентичные клоны с порогом схожести 100% — возможно, интуитивно кажется, что абсолютно одинакового кода на GitHub должно быть меньше.
Все оставшиеся после данной фильтрации пары мы обрабатываем следующим образом:
- Сравниваем время последней модификации двух методов в паре.
- Если они совпадают с точностью до дня, игнорируем такую пару: нет смысла искать нарушения с такой точностью.
- Если же они не совпадают, берем пару их лицензий от «старшего» к «младшему» и записываем. Например, если у блока из 2015 года лицензия MIT, а у блока из 2018 — Apache-2.0, то записываем такую пару как потенциальное заимствование MIT → Apache-2.0.
В конце мы просуммировали количество пар для каждого потенциального заимствования и отсортировали их по убыванию:
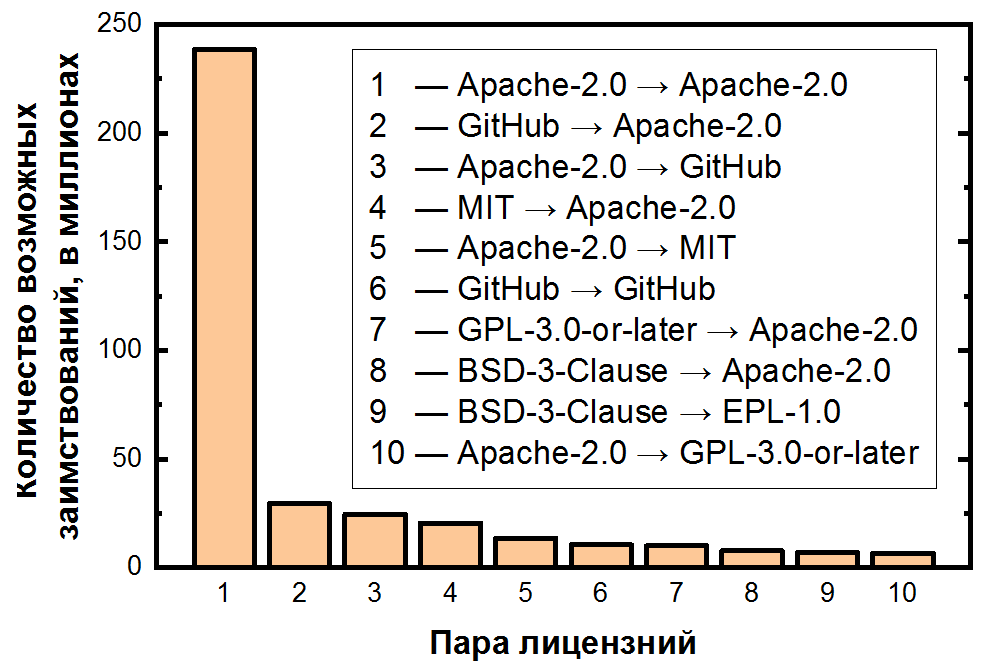
Здесь зависимость еще более экстремальная: возможное заимствование кода внутри Apache-2.0 составляет более половины всех пар клонов, а первые 10 пар лицензий покрывают уже более 80% клонов. Важно также отметить, что вторая и третья самая частые пары имеют дело с нелицензированными файлами — также явное следствие их частоты. Для пяти наиболее популярных лицензий можно изобразить переходы в виде «тепловой карты»:
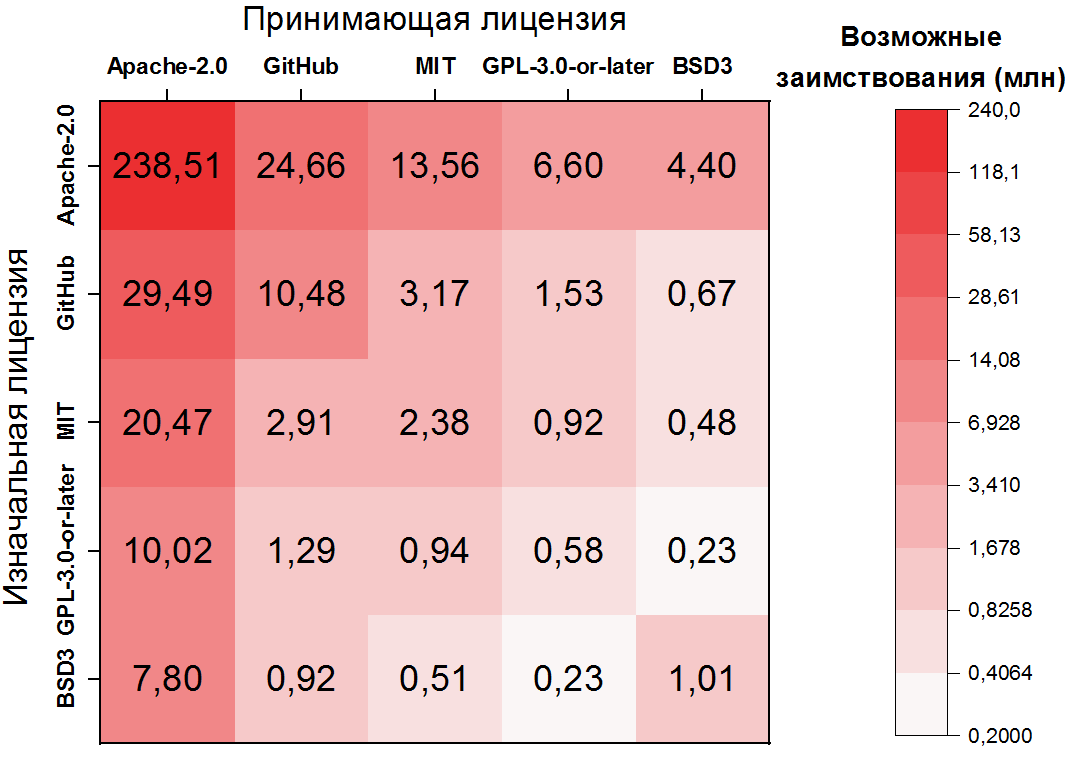
Возможные нарушения лицензирования
Следующий шаг в нашем исследовании — определить пары клонов, являющиеся потенциальными нарушениями, то есть заимствованиями, которые нарушают условия оригинальной и принимающей лицензий. Для этого необходимо разметить вышеупомянутые пары лицензий как разрешенные либо запрещенные переходы. Так, например, наиболее популярный переход (Apache-2.0 → Apache-2.0), разумеется, разрешен, а вот второй (GitHub → Apache-2.0) запрещен. Но их очень и очень много, таких пар тысячи.
Чтобы с этим справиться, вспомним, что визуализированные первые 10 пар лицензий покрывают 80% всех пар клонов. Благодаря такой неравномерности, оказалось достаточно вручную разметить всего 176 пар лицензий, чтобы покрыть 99% пар клонов, что показалось нам вполне приемлемой точностью. Среди этих пар, мы считали запрещенными пары четырех типов:
- Копирование из файлов без лицензии (GitHub). Как уже было сказано, такое копирование требует прямого разрешения от автора кода, и мы предполагаем, что в подавляющем большинстве случаев его нет.
- Копирование в файлы без лицензии также запрещено, потому что это есть по сути стирание, убирание лицензий. Разрешительные лицензии вроде Apache-2.0 или BSD разрешают переиспользовать код в других лицензиях (в том числе проприетарных), однако даже они требуют, чтобы сохранялось упоминание оригинальной лицензии в файле.
- Копирование из копилефтных лицензий в более слабые.
- Специфические несовместимости между версиями лицензий (например, Apache-2.0 → GPL-2.0).
Все остальные редкие пары лицензий, покрывающие 1% клонов, были отмечены как разрешительные (чтобы никого излишне не обвинить), кроме тех, где фигурирует код без лицензий (который никогда нельзя копировать).
В итоге после разметки оказалось, что 72,8% заимствований представляют собой разрешенные заимствования, а 27,2% — запрещенные. На следующих графиках представлены наиболее нарушаемые и наиболее нарушающие лицензии.

Слева представлены наиболее нарушаемые лицензии, то есть источники наибольшего количества возможных нарушений. Среди них первое место занимают файлы без лицензий, что является важным практическим замечанием — нужно особенно пристально следить за файлами без лицензий. Можно удивиться, что в этом списке делает разрешительная лицензия Apache-2.0. Однако, как видно из вышепредставленной тепловой карты, ~25 миллионов запрещенных заимствований из нее — это заимствования в файл без лицензии, так что это следствие ее популярности.
Справа представлены лицензии, в которые копируют с нарушениями, и здесь больше всего представлены все те же Apache-2.0 и GitHub.
Происхождение отдельных методов
Наконец, мы подошли к последнему пункту нашего исследования. Все это время мы говорили о парах клонов, как и принято в таких исследованиях. Однако нужно понимать некую однобокость, неполноту таких суждений. Дело в том, что если, например, у одного фрагмента кода есть 20 «старших» братьев (или «родителей», кто знает), то все 20 пар будут считаться потенциальными заимствованиями. Именно поэтому мы говорим о «потенциальных» и «возможных» заимствованиях — вряд ли автор конкретного метода заимствовал его из 20 разных мест. Несмотря на это, данные рассуждения можно рассматривать как рассуждения о клонах между различными лицензиями.
Чтобы избежать такой неполноты суждений, можно взглянуть на ту же картину с другого угла. Картина клонирования на самом деле представляет собой ориентированный граф: все методы являются на нем вершинами, которые соединены направленными ребрами от старшего к младшему (если не учитывать методы, датированные одним днем). В предыдущих двух разделах мы смотрели на этот граф с точки зрения ребер: мы брали каждое ребро и изучали его вершины (получая те самые пары лицензий). Теперь же давайте посмотрим на него с точки зрения вершин. У каждой вершины (метода) на графе есть предки («старшие» клоны) и потомки («младшие» клоны). Связи между ними также можно разделить на «разрешенные» и «запрещенные».
Исходя из этого, каждый метод можно отнести к одной из следующих категорий, графы которых представлены на изображении (здесь сплошные линии обозначают запрещенные заимствования, а пунктирные — разрешенные):

Две из представленных конфигураций могут являть собой нарушение условий лицензирования:
- Сильное нарушение означает, что у метода есть предки и все переходы от них являются запрещенными. Это значит, что если разработчик действительно скопировал код, то сделал это в нарушение лицензий.
- Слабое нарушение означает, что у метода есть предки, и только часть из них находятся за запрещенными переходами. Это значит, что разработчик мог скопировать код с нарушением лицензии.
Остальные конфигурации не являются нарушениями:
- Легальное заимствование соответствует случаю, когда у метода есть предки, но все переходы из их лицензий разрешены.
- Источник — это метод, который участвует в заимствовании только как источник — у него есть потомки, но нет предков.
- И, наконец, уникальные методы — это методы, которые вообще не участвуют в копировании. Формально они не представлены в выводе поиска клонов, однако их легко обнаружить как все методы, которые прошли порог минимального размера и не были представлены в результатах — это просто значит, что для них не нашлось клонов. Такие методы тоже можно разделить: можно отметить методы, у которых клонов нет вообще, а можно те, у которых клонов нет только в несвязанных проектах, зато есть в связанных (в форках, зеркалах, проектах того же автора или даже внутри одного проекта).
Итак, как же распределены методы в нашем датасете?

Можно заметить, что примерно треть методов не имеет клонов вообще, и еще треть имеет клоны только в связанных проектах. С другой стороны, 5,4% методов представляют «слабое нарушение», а 4% — «сильное нарушение». Хотя такие цифры и могут показаться не очень большими, это все еще сотни тысяч методов в более-менее крупных проектах.
TL; DR
Учитывая, что в этой статье много эмпирических цифр и графиков, повторим наши основные находки:
- Методы, у которых есть клоны, исчисляются миллионами, а пар между ними — больше миллиарда.
- Всего в нашем датасете, состоящем из Java-проектов с более чем 50 звездами, найдено 94 вида лицензий, которые распределены очень неравномерно: наиболее часто встречаются Apache-2.0 и файлы без лицензии. Возможные переходы также встречаются чаще всего между Apache-2.0 и файлами без лицензии.
- Что касается запрещенных возможных переходов, то таких 27,2%, и наиболее часто нарушаются права авторов файлов без лицензии.
- Из самих методов всего 35,4% не имеют клонов вообще, у 5,4% часть «старших» клонов запрещают возможное заимствование, а у 4% все «старшие» клоны таковы.
А к чему все это?
В заключении хочется поговорить о том, а зачем вообще нужно все вышеописанное. У меня есть по меньшей мере три ответа.
Во-первых, это интересно. Лицензирование так же разнообразно, как и все другие аспекты программирования. Сам по себе список лицензий достаточно любопытен в силу специфичности и редкости некоторых лицензий, люди по-разному их пишут и работают с ними. Также это несомненно относится к клонам в коде и похожести кода вообще. Есть методы с тысячами клонов, а есть — без единого, в то время как беглым взглядом не всегда легко заметить принципиальную разницу между ними.
Во-вторых, подробный разбор наших находок позволяет сформулировать несколько практических советов:
- Не стоит бояться юридического веса темы лицензирования и переживать из-за большого количества лицензий и их параметров. Для начала вполне достаточно понимать суть лицензий Apache-2.0, MIT, BSD-3-Clause, GPL и LGPL.
- Даже для этих лицензий достаточно понимания одного главного параметра: является ли лицензия разрешительной или копилефтной. Так что если вы вдруг встретите какую-то незнакомую редкую лицензию, не обязательно читать все пять мониторов ее текста, для начала можно просто отыскать в интернете именно это ее свойство.
- Наиболее пристального внимания требуют файлы на GitHub, для которых лицензия не задана. Такие файлы по умолчанию не являются открытыми и их заимствование требует разрешения автора. Вместе с тем отсутствие лицензии очень редко является намеренным выбором — скорее, люди просто забывают об этом. В нашей лаборатории мы ввели следующую практику: когда кому-то надо позаимствовать код, не защищенный лицензией, мы просто пишем автору или создаем ишью, объясняя нашу заинтересованность, и просим добавить в проект лицензию. В подавляющем большинстве случаев разработчик добавляет лицензию, и сообщество открытого программного обеспечения становится чуточку лучше.
За понятными описаниями лицензий, а также за советами по выбору лицензии для своего нового проекта, можно обратиться к таким сервисам как tldrlegal или choosealicense.
Ну и, наконец, полученные данные можно использовать для создания инструментов. Прямо сейчас наши коллеги разрабатывают способ быстрого определения лицензий с помощью методов машинного обучения (для чего как раз нужно много определенных лицензий)
