Исследование нагрузки на ELK stack и тюнинг Logstash
Всем привет! Меня зовут Александр, и в этой статье я расскажу про то, как столкнувшись с многократно увеличившейся нагрузкой на ELK stack сначала было диагностировано узкое место, а после произведён его тюнинг. Хоть и в заголовке статьи уже есть спойлер что произведен только тюнинг Logstash, тем не менее приступим.
Архитектура
Для начала кратко расскажу про архитектуру ELK
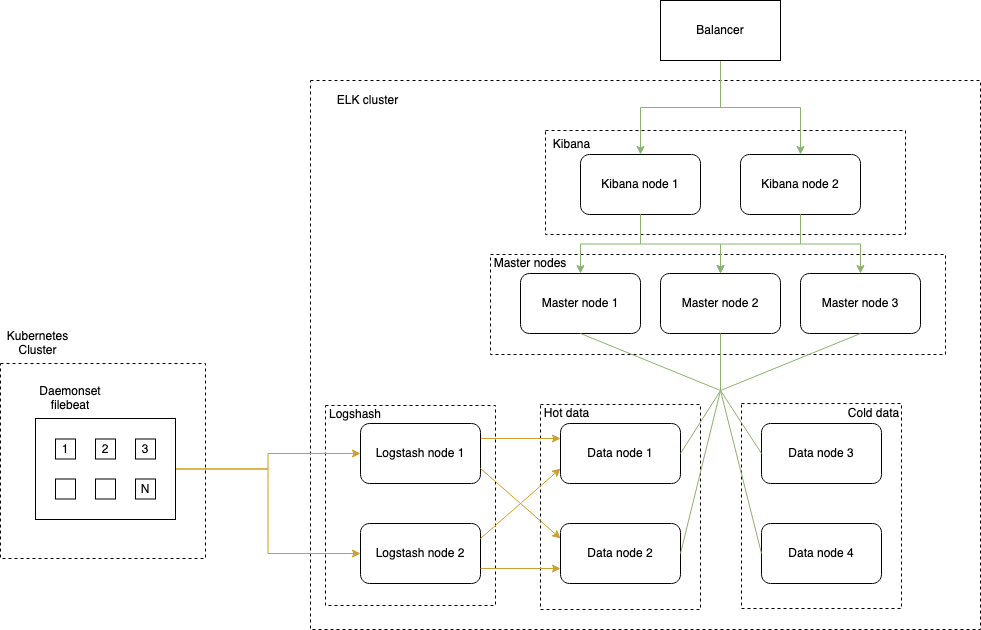
ELK используется для хранения логов сервисов и логов самого кластера Kubernetes.
Кластер ELK состоит из трех мастер нод, четырех нод с данными: по две ноды на ssd и sata дисках, две ноды Logstash для препроцессинга логов и Filebeats в кластере Kubernetes, развернутые daemonset’ом и отправляющие логи в Logstash.
По две ноды Logstash и по две ноды ssd и sata дисков использованы для обеспечения отказоустойчивости.
Начало проблем
Точкой отсчета можно считать триггеры по недостатку свободного места в директории /var/lib/docker на некоторых нодах кластера Kubernetes. В этой директории Docker хранит образы контейнеров, а так же логи контейнеров, которые приложения в кластере Kubernetes пишут в stdout. Беглая диагностика выявила, что место заканчивается потому что Filebeat, читающий эти логи, не успевает их вычитывать и держит открытыми дескрипторы файлов, в то время как Docker уже давно произвел ротацию и удалил устаревшие файлы логов.
Было очевидно что проблема находится в недостаточной производительности стэка ELK, но вычислить, какой из компонентов являлся «бутылочным горлышком», не удавалось, потому что текущего мониторинга было недостаточно.
Настройка мониторинга
Filebeat
Для того, что бы понять что происходит на файлбитах, side-car«ом к поду файлбита был настроен экспортер для prometheus. Он собирает подробную информацию о состоянии самого Filebeat и процессах, происходящих внутри из его API. Для визуализации метрик используется Grafana.
Для исследования был выбрал файлбит на одной из проблемных нод. Проблемы начинались всегда в одно и тоже время: 10–00 (время начала открытия биржи). В это время сервисы в кластере Kubernetes начинали генерировать огромное количество логов с которыми файлбиту предстояло справиться.
Но на графиках видно, что вместо ожидаемого роста нагрузки происходило её падение.
Падение по ЦПУ:

Падение по трафику:
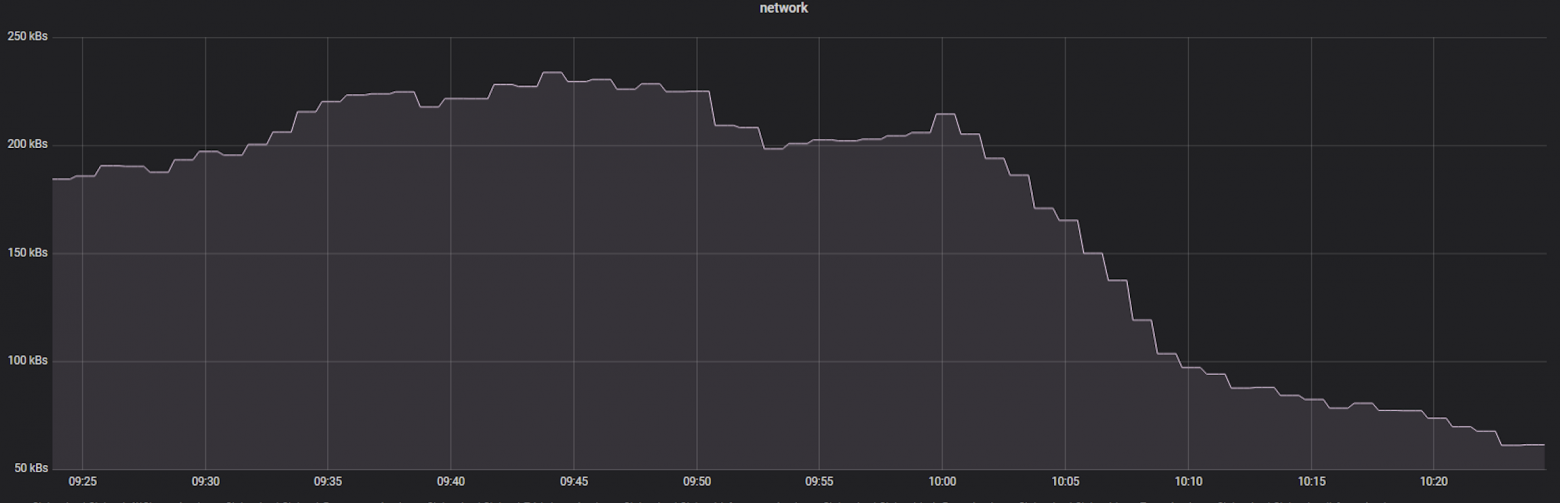
Падение по количеству отправляемых сообщений:

Но в тоже время при общем падении нагрузки количество открытых дескрипторов файлов росло:

Получалась неоднозначная ситуация — вместо ожидаемого роста нагрузки на ЦПУ Filebeat’a при многократно увеличившимся количестве логов, происходило падение нагрузки на ЦПУ. Можно было предположить, что падение нагрузки на ЦПУ является следствием возросшей нагрузки на ноду, где расположены клиентские сервисы и Filebat, но мониторинг на ноде показывал, что ядра загружены на ноде не полностью и причина не в этом.
В действительности, такое поведение объяснялось механизмом «Back Pressure» на стороне Logstash. Смысл его в том, что когда у Logstash заполнена внутренняя очередь и он не успевает обрабатывать сообщения, Logstash перестает принимать новые сообщения и Filebat ожидает пока Logstash не освободит свою очередь.
Logstash
Но мониторинг показывал, что утилизация ЦПУ на нодах с Logstash около 35%.

По этому потребовалось настроить дополнительный мониторинг, который так же как и Filebeat, берет информацию о работе Logstash из его API.
К сожалению экспортер не отдает метрики по очереди эвентов в памяти (точнее такую информацию не предоставляет API Logtash), но прекрасно мониторит персистентную очередь, включим ее:
queue.type: persisted
queue.max_bytes: 8gb
Персистентная очередь сохраняет сообщения на диске перед дальшейшей обработкой сообщений по пайплайну, но на самом деле замедляет работу Logstash (и дело не в диске, а потому что Logstash пишет сообщения в очередь последовательно, а не параллельно), по этому целью было ускорить работу Logstash настолько, что бы сообщения в персистетной очереди не скапливались совсем.
После того, как появился график загруженности очереди на Logstash, стало видно, что очередь заполняется почти сразу после 10–00 по МСК (время когда на Filebeat начинаются проблемы) и не разбирается до самого вечера:

pipeline.workers: 12
pipeline.batch.size: 2000
По умолчанию, количество workers равно количеству ядер на ноде, но при низкой утилизации ЦПУ рекомендуется повысить значение для увеличения количества потоков параллельной обработки сообщений от Filebeat.
Параметр pipeline.batch.size определяет, сколько сообщений возьмет один worker из очереди для дальнейшей обработки по пайплайну. Чем выше это значение, тем более эффективно будет работать каждый worker, но при этом Logstash начинает потреблять больше оперативной памяти, по этому значение Xms и Xmx для ява машины было увеличено до максимально рекомендуемых 8Gb.
Видно, что после применения параметров сообщения в очереди перестали копиться, размер очереди не превышает 150mb, а количество сообщений в ней в пиках достигает 400, в то время как среднее занчение в районе 60:


Выводы
Проведенное исследование показало, что хорошо настроенный мониторинг критически важен для всех компонентов инфраструктуры. Тюнинг Logstash позволил увеличить производительность в дневное время в среднем с 5500 до 11000 сообщений в секунду.

В качестве дальнейших шагов по построению отказоустойчивого кластера можно рассмотреть apache kafka как буферное хранилище логов (filebeat → kafka → logstash). Но в любом случае стек должен быть достататочно производительный для обработки рабочей дневной нагрузки (с задежкой не более 5ти минут).
Список источников
Экспортер для файлбитов
Описание механизма back pressure на стороне логстеш
Экспортер для логстеш
Поиск узкого места логстеш
Тест производительности логстшеш от разработчиков эластика
