Использовать машинное обучение не сложно. Для этого достаточно в течение недели…

В прошлых статьях я попытался рассказать про основы ценообразования и построения дерева принятия решений покупателя для классического ритейла. В данной статье расскажу про очень нестандартный кейс и постараюсь убедить вас, что использовать машинное обучение не так сложно, как кажется. Статья менее техничная и скорее призвана показать, что можно начать с малого и это уже принесет ощутимую пользу для бизнеса.
Изначальная проблема
На нашем континенте есть сеть магазинов, которая изменяет свой ассортимент раз в неделю, например сначала продает оверлоки, а затем мужскую спортивную одежду. Все нераспроданные товары отправляются на склады и через полгода опять возвращаются в магазины. Одновременно в магазине присутствует около 6 различных категорий товаров. Т.е. ассортимент магазинов на каждой неделе выглядят следующим образом:
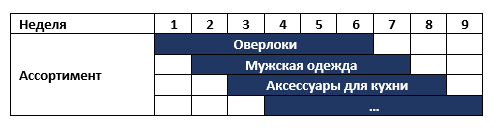
Сеть обратилась с запросом на систему планирования ассортимента с обязательным условием аналитической поддержки принятия решений для категорийных менеджеров. Пообщавшись с бизнесом, предложили два очень быстрых потенциальных решения, которые могут принести результат, пока будет идти развертывание системы планирования:
- распродажи товаров, которые не проданы за время основных продаж
- улучшение точности прогнозирования спроса на магазинах
Первый пункт заказчика не устроил — компания гордится тем, что не устраивает распродаж и поддерживает постоянный уровень маржинальности. При этом тратятся огромные деньги на логистику и хранение товара. В итоге было решено улучшить точность прогнозирования спроса для более точного распределения по магазинам и складам.
Текущий процесс
Ввиду особенностей бизнеса каждый отдельный товар не продается длительный срок и набрать достаточной истории для классического анализа проблематично. Текущий процесс прогнозирования очень прост и построен следующим образом — за несколько недель до старта основных продаж на малой части магазинов начинаются тестовые продажи. По итогам тестовых продаж принимается решение о вводе товара на всю сеть и предполагается, что каждый магазин будет продавать в среднем столько же, сколько было продано на тестовых магазинах.
Десантировавшись к заказчика, мы проанализировали текущие данные, поняли, что к чему, и предложили очень простое решение по улучшению точности прогноза.
Анализируем данные
Из данных нам предоставили:
- История транзакционных данных за 1 год и 2 месяца
- Товарная иерархия для планирования. К сожалению, в ней практически полностью отсутствовали атрибуты товаров, но об этом чуть позже
- Информация об ассортименте и ценах на конкретные недели
- Информация о городах, в которых находятся магазины
Нам не смогли в короткий срок выгрузить информацию об остатках, которая является критичной в подобного рода анализе (если не храните эту информацию — начинайте), поэтому в дальнейшем мы использовали предположение, что товар присутствует на полках и дефицита товара нет.
Сразу мы отделили 2 месяца на тестовую выборку для демонстрации результатов. Затем соединили все имеющиеся данные в одну большую витрину, очистив их от возвратов и странных продаж (например, количество в чеке 0,51 на штучный товар). На это ушло несколько дней. После подготовки витрины мы посмотрели на продажи товаров [шт.] на самом верхнем уровне и увидели следующую картину:
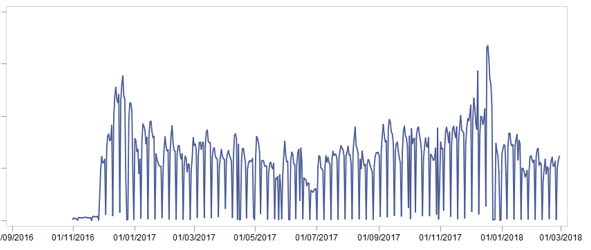
Чем нам может помочь эта картинка?… А вот чем:
- Очевидно, что присутствует сезонность — продажи в конце года выше, чем в середине
- Существует сезонность в рамках месяца — в середине месяца продажи выше, чем в начале и в конце
- Существует сезонность в рамках недели — она не так интересна, т.к. в итоге прогноз строился по неделям
Описанные пункты подтвердил бизнес. А ведь это еще и отличные фичи для того, чтобы улучшить прогноз! Перед тем, как добавить их в модель прогнозирования давайте подумаем, какие еще особенности продаж следует учесть… В голову приходят «очевидные» идеи:
- Продажи в среднем различаются между различными товарными группами
- Продажи различаются между различными магазинами
- (Схож с предыдущим пунктом) Продажи различаются между различными городами
- (Менее очевидная идея) из-за специфики бизнеса видна следующая зависимость: если будущий и предыдущий ассортимент схожи, то продажи нового ассортимента будут ниже.
На этом мы решили остановиться и построить модель.
Построение ABT (analytical base table)
В рамках построения модели, все найденные особенности были переведены в «фичи» модели. Вот список использованных в итоге фичей:
- текущий прогноз, т.е. средние продажи тестовых магазинов в [шт.] распространенные на все магазины
- номер месяца и номер недели в месяце
- все категориальные переменные (город, магазин, товарные категории) были закодированы с помощью smoothed likelihood (полезная техника — кто еще не использует, берите на вооружение)
- посчитан лаг 4 средних продаж категории товара. Т.е. если компания планирует продавать майку синего цвета, то был рассчитан лаг средних продаж категории майки
ABT получилась простой, каждый параметр был понятен бизнесу и не вызывал непонимания или отторжения. Затем необходимо было понять, как мы будем сравнивать качество прогноза.
Выбор метрики
Заказчик измерял текущую точность прогнозирования, используя метрику MAPE. Метрика популярна и проста, но обладает определенными недостатками, когда речь идет о прогнозировании спроса. Дело в том, что при использовании MAPE, наибольшее влияние на итоговый показатель оказывают ошибки прогноза вида:

Относительная ошибка прогноза 900% — кажется большой, но давайте посмотрим на продажи другого товара:

Относительная ошибка прогноза составляет 33%, что гораздо меньше 900%, но абсолютное отклонение отклонение в 100 [шт.] гораздо важнее для бизнеса, чем отклонение 18 [шт.]. Для учета данных особенностей можно придумать свои интересные меры, а можно воспользоваться другой популярной мерой при прогнозировании спроса — WAPE. Данная мера дает больший вес товарам с более высокими продажами, что отлично подходит для задачи.
Про различные подходы к измерению ошибки прогноза мы рассказали компании, и заказчик охотно согласился с тем, что использовать WAPE в данной задаче более разумно. После этого мы запустили Random Forest практически без тюнинга гиперпараметров и получили следующие результаты.
Результаты
После прогнозирования тестового периода мы сравнили спрогнозированные значения с фактическими, а также с прогнозом компании. В результате MAPE уменьшился более чем на 15%, WAPE более чем на 10%. Рассчитав влияние улучшенного прогноза на бизнес показатели, получилось сокращение издержек на очень немаленькую сумму, исчисляемую миллионами долларов.
На всю работу потрачена 1 неделя!
Дальнейшие шаги
В качестве бонуса для заказчика мы провели небольшой DQ эксперимент. Для одной товарной группы из названий товаров мы распарсили характеристики (цвет, вид товара, состав и пр.) и добавили их в прогноз. Результат получился вдохновляющий — на данной категории обе меры ошибок улучшились дополнительно более чем на 8%.
В итоге заказчику было передано описание каждой фичи, параметры модели, параметры сборки ABT-витрины и описаны дальнейшие шаги по улучшения прогноза (использовать исторические данные более, чем за один год; использовать остатки; использовать характеристики товаров и пр.).
Вывод
За одну неделю совместной работы с заказчиком удалось значительно увеличить точность прогнозирования, при этом практически не изменяя бизнес-процесс.
Наверняка многие сейчас думают, что данный случай очень простой и у них в компании таким подходом уже не отделаешься. Опыт показывает, что практически всегда есть места, где используются лишь базовые предположения и экспертные мнения. С этих мест можно начать применение машинного обучения. Для этого нужно аккуратно подготовить и изучить данные, поговорить с бизнесом и попробовать применить популярные модели, не требующие долгого тюнинга. А стэкинг, embedding фичи, сложные модели — это все на потом. Надеюсь, я убедил вас, что это не так сложно, как может показаться, надо лишь немного подумать и не бояться начать.
Не бойтесь машинного обучения, ищите места, где его можно применить в процессах, не бойтесь исследовать свои данные и пускать к ним консультантов и получайте классные результаты.
P.S. Мы набираем в ритейл практику юных падаванов-студентов для стажировки под руководством опытных джедаев. Для старта достаточно здравого смысла и знания SQL, остальному научим. Развиться можно в бизнес-эксперта или технического консультанта, смотря, что будет интереснее. Если есть заинтересованность или рекомендации — пишите в личку
