Использование полнотекстового индексирования и поиска в PostgreSQL
Всем привет, Описываются базовые возможности, плюсы и минусы использования встроенного полнотекстового поиска СУБД Postgre на основе опыта его практического использования.

При разработке приложений, особенно web-приложений, в 95% возникает задача выбрать системы для управления как структурированным контентом, так и неструктурированными (текстовая информация произвольной структуры), а также данными мультимедиа (выходит за рамки данной статьи).Архитектор приложения задается вопросом: совместить эти данные под управлением одной СУБД, либо же взять отдельное специализированное средство для каждого вида информации.
Существуют проверенные временем инструменты для индексирования и поиска неструктурированных текстовых данных — Django, Sphinx, Lucene, на Хабре есть хорошие авторские статьи на эту тему.Преимущество в том, что это отдельная система и она приспособлена для своей задачи максимально хорошо.Но есть и архитектурный минус такого решения — ведь структурная и описательная часть данных чаще всего связаны между собой, а следовательно придется сконструировать комбинированные запросы.
Рассмотрим на примереЕсть задача учета кандидатов-соискателей, которые присылают свои резюме в текстовом формате. Была изначально поставлена задача находить информацию по кандидатам на основании их навыков и практического опыта владения этими навыками.Создаем реляционную модель (упрощенно): 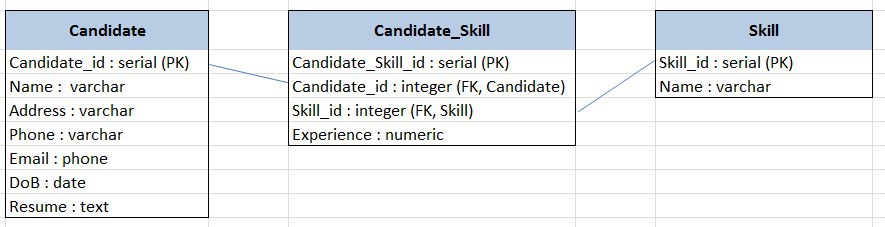
рекрутеры принимают резюме, изучают их, заполняют наши таблички, после чего запрос вида «дай мне список кандидатов с опытом C (но не C++) не менее 2 года и не старше 100 лет» задаются примерно следующим образом:
SELECT candidate.name, skill.name, candidate_skill.expericence, candidate.phone, candidate.email FROM candidate, candidate_skill, skillWHERE (year (candidate.dob) > (year (now ()) — 100)) AND candidate.candidate_id = candidate_skill.candidate_id ANDcandidate_skill.experience > 2 AND candidate_skill.skill_id = skill.skill_id AND skill.name = 'C' ORDER BY candidate_skill.experience DESC;
Всех находит, все довольны.
Затем случается неожиданность — заказчик из Тмутаракани требует специалиста с опытом работы на C, но чтобы опыт был обязательно в Тмутаракани.
У нас тексты резюме проиндексированы в системе Shpinx, например, так что мы можем быстро найти всех кандидатов с опытом работы в Тмутаракани, но при поиске по C уже возникнут сложности (попадут C++, C-Sharp и всякое другое C). Младшему рекрутеру светит вручную перелопатить многие тысячи кандидатов с опытом работы в Тмутаракани, чтобы найти у кого есть там опыт 2 года на C (сам такое видел не раз).
Но не обязательно — если изначально была благоразумно выбрана СУБД Postgre, выручит текстовая колонка Resume: text в таблице Candidate — туда рекрутеры с самого начала тупо копипастили текст резюме, на всякий случай.
Надо заставить систему искать по текстовому полю. Что сделать:
1. Postgre устанавливается без словарей русского языка, поэтому их нужно отдельно скачать например тут. Если база данных (что скорей всего) в uft-8 — придется еще переконвертировать словари из koi8-r в utf-8, вот так: iconv -f koi8-r -t utf-8 < ru_RU.aff > russian.affixiconv -f koi8-r -t utf-8 < ru_RU.dic > russian.dictПолучившиеся файлы скопировать в подпапку tsearch_data папки, где у вас установлена Postgre.
2. создать словарь и конфигурацию для русского языка: CREATE TEXT SEARCH DICTIONARY russian_ispell (Template = ispell, DictFile = russian, AffFile = russian, StopWords = russian); CREATE TEXT SEARCH CONFIGURATION ru (Copy = russian); Для полнотыALTER TEXT SEARCH CONFIGURATION ru ALTER MAPPING FOR hword, hword_part, word WITH russian_ispell, russian_stem; ALTER TEXT SEARCH CONFIGURATION ru ALTER MAPPING FOR asciihword, asciiword, hword_asciipart WITH english_ispell, english_stem;
После этого уже можно получить результат, доработав наш запрос
SELECT Candidate.Name, Skill.Name, Candidate_Skill.Expericence, Candidate.Phone, Candidate.Email FROM Candidate, Candidate_Skill, SkillWHERE (year (Candidate.DoB) > (year (now ()) — 100)) AND Candidate.Candidate_id = Candidate_Skill.Candidate_id ANDCandidate_Skill.Experience > 2 AND Candidate_Skill.Skill_id = Skill.Skill_id AND Skill.Name = 'C' ANDto_tsvector ('ru', Candidate.Resume) @@ to_tsquery ('ru','Тмутаракань')ORDER BY Candidate_Skill.Experience DESC;
3. Операция to_tsvector трудоемкая, и каждый раз при запросе конвертировать всё резюме для каждой строчки нерационально, создание индекса типа GIN по полю Resume, сконвертированному в тип данных tsvector, решит этот вопрос.Для этого сначала создаем поле fulltext: tsvector в таблице Candidate, затем создаем триггер, который будет заполнять это поле на основании значения поля Resume при создании или изменении записи Candidate — не будем загромождать кодом, всё стандартно — в триггере присвоить fulltext:= to_tsvector ('ru', NEW.resume)
Затем создаем индекс по полю Fulltext: CREATE INDEX candidate_fulltext ON candidate USING gin (fulltext);
GIN — специальный тип индекса, для данных типа tsvector и для массивов (всего в Postgre 9.3 уже 5 разных типов индексов, подробно можно узнать изучив доку Postgre).
Запрос тогда принимает вид: SELECT Candidate.Name, Skill.Name, Candidate_Skill.Expericence, Candidate.Phone, Candidate.Email FROM Candidate, Candidate_Skill, SkillWHERE (year (Candidate.DoB) > (year (now ()) — 100)) AND Candidate.Candidate_id = Candidate_Skill.Candidate_id ANDCandidate_Skill.Experience > 2 AND Candidate_Skill.Skill_id = Skill.Skill_id AND Skill.Name = 'C' ANDCandidate.fulltext @@ to_tsquery ('ru','Тмутаракань')ORDER BY Candidate_Skill.Experience DESC;
Вот и всё — запрос выдаст точнейший из возможных результат по заданному критерию.
Плюсы и минусы Главный плюс очевиден — компактность и точность запросов за счет комбинирования структурных и полнотекстовых критериев. Ради него и сыр-бор.Еще один плюс — в установке и поддержке Sphinx уже нет необходимости.
Поиск по готовому индексу GIN очень быстрый, в сложных запросах Postgre умеет его «склеивать» с другими индексами (хотя сам GIN составным быть не может).
Минусы тоже очевидны— необходимо содержать дополнительное поле tsvector (немаленькое), нужен триггер, нужен дополнительный индекс. Потери производительности при вставке и обновлении записей будут довольно ощутимыми.— дополнительная нагрузка на сервер Postgre
На одной чаше весов у нас 1) простота, точность и скорость запросов SQL 2) минус 1 система в ландшафте, на другой — 1) несколько дополнительных объектов в схеме БД, 2) замедление производительности запросов DML.
Если есть сомнения, что это будет хорошо работать — не стоит тогда сразу сносить Sphinx. Но мы свой снесли уже очень давно, всё прекрасно без сбоев под нагрузкой работает.
