Интересные сюрпризы ConcurrentDictionary (+разбор задачи с DotNext 2017 Moscow)
Привет всем, кто пишет код для .NET, особенно многопоточный. Редко встретишь потокобезопасный код без потокобезопасных коллекций, а значит, нужно уметь ими пользоваться. Я расскажу о самой популярной из них — ConcurrentDictionary. В ней спрятано на удивление много интересных сюрпризов: как приятных, так и не очень.
Сначала разберём устройство ConcurrentDictionary и вычислительную сложность операций с ним, а затем поговорим об удобных трюках и подводных камнях, связанных с memory traffic и сборкой мусора.
Область применимости
Все наблюдения из этой статьи проверены на свежайшей на момент публикации версии .NET Framework (4.7.1). Вероятно, они справедливы и в .NET Core, но проверка этого утверждения остаётся упражнением для читателя.
Кратко об устройстве
Под капотом у ConcurrentDictionary работает привычная реализация хэш-таблицы. Она основана на массиве так называемых bucket-ов, каждый из которых соответствует определенному множеству значений хэш-функции. Внутри каждого bucket-а содержится односвязный список элементов: в случае коллизии в нем производится линейный поиск ключа.
Потокобезопасность обеспечивается с помощью техники под названием striped locking. Имеется небольшой массив обычных локов, и каждый из них отвечает за целый диапазон bucket-ов (отсюда и stripe в названии). Для того, чтобы записать что-то в произвольный bucket, необходимо захватить соответствующий ему лок. Обычно локов намного меньше, чем bucket-ов.

А вот как эти понятия соотносятся с параметрами конструктора ConcurrentDictionary(int concurrencyLevel, int capacity):
capacity— количество bucket-ов. По умолчанию — 31.concurrencyLevel— количество локов. По умолчанию — 4 × количество ядер.
Реализация старается поддерживать размер bucket-ов небольшим, увеличивая по мере необходимости их количество. При расширении происходит следующее:
- Емкость увеличивается примерно вдвое. Примерно, потому что величина выбирается так, чтобы она не делилась на 2, 3, 5 и 7 (емкость полезно делать простым или плохо факторизуемым числом).
- Количество локов увеличивается вдвое, если
concurrencyLevelне был задан явно. В противном случае оно остается прежним.
Сложность операций
Сводная табличка для словаря с N элементов и K локов:
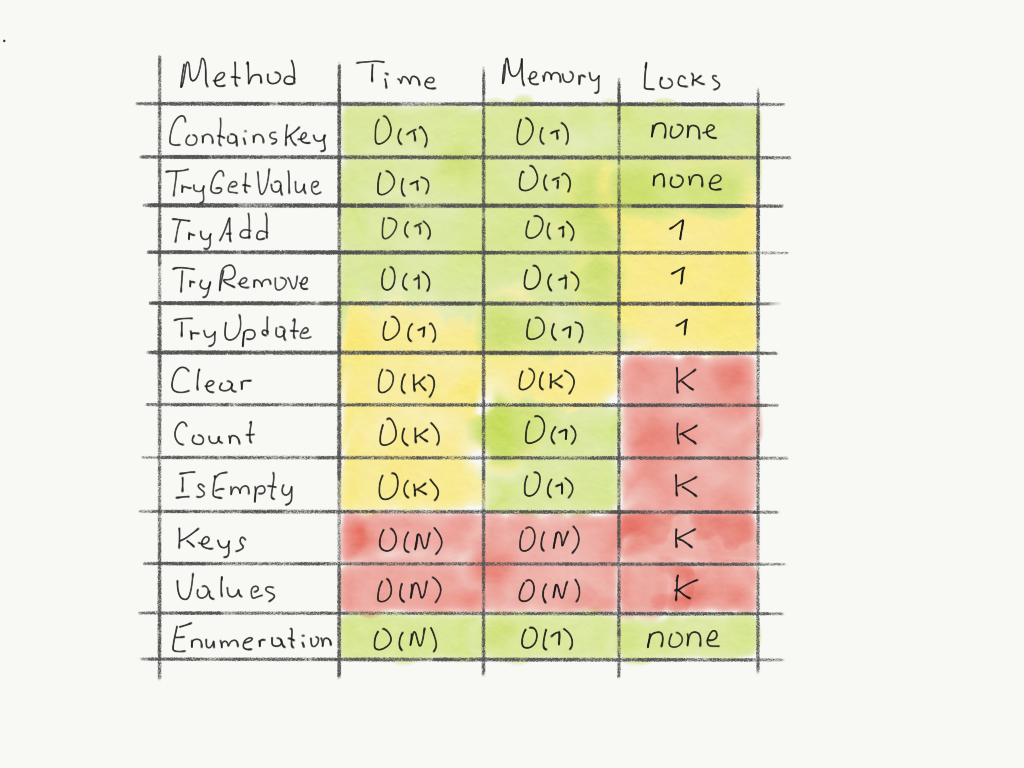
Остальные операции являются производными от этих:
GetOrAdd=TryGetValue+TryAddAddOrUpdate=TryGetValue+TryAdd+TryUpdateIndexer(get)=TryGetValueIndexer(set)=TryAddс перезаписью
Плохие новости
Свойства Count и IsEmpty коварно захватывают все локи в словаре. Лучше воздержаться от частого вызова этих свойств из нескольких потоков.
Свойства Keys и Values еще более коварны: они не только берут все локи, но и целиком копируют в отдельный List все ключи и значения. В отличие от традиционного Dictionary, одноимённые свойства которого возвращают «тонкие» обертки, здесь нужно быть готовым к крупным аллокациям памяти.
Такая вопиющая неэффективность вызвана желанием обеспечить семантику снепшота: возвращать некоторое консистентное состояние, существовавшее в определенный момент времени.
Хорошие новости
Не всё так плохо. Первая: самое обычное перечисление (работающее через GetEnumerator) является неблокирующим и работает без лишнего копирования данных. За это приходится платить отсутствием семантики снепшота: по мере перечисления на результате могут отражаться производимые параллельно операции записи.
Вторая хорошая новость: чаще всего такое поведение является либо допустимым, либо вовсе желаемым, и этим можно пользоваться. Например, эффективно перечислять ключи или значения:
var keys = dictionary.Select(pair => pair.Key);
var values = dictionary.Select(pair => pair.Value);
Tips and tricks
В отличие от обычного Dictionary, можно производить вставку в ConcurrentDictionary или удаление из него прямо во время перечисления! Это, например, позволяет удобно вычищать устаревшие элементы из словарика-кэша с временем жизни:
foreach (var pair in cache)
{
if (IsStale(pair.Value))
{
cache.TryRemove(pair.Key, out _);
}
}Удалять элементы можно не только по ключу, но и по точному совпадению key + value, причем атомарно! Это недокументированная возможность, скрытая за explicit-реализацией интерфейса ICollection. Она позволяет безопасно очищать такой кэш даже в условиях гонки с обновлением значения:
var collection = cache as ICollection>
foreach (var pair in cache)
{
if (IsStale(pair.Value))
{
// Remove() will return false in case of race with value update
var removed = collection.Remove(pair);
}
} Это и так все знают, но напомню: в условиях конкурентного доступа GetOrAdd может вызвать делегат-фабрику для одного ключа сильно больше одного раза. Если так делать нельзя или дорого, достаточно обернуть значение в Lazy:
var dictionary = new ConcurrentDictionary>();
var lazyMode = LazyThreadSafetyMode.ExecutionAndPublication;
var value = dictionary
.GetOrAdd(key, _ => new Lazy(() => new MyValue(), lazyMode))
.Value;
GC overhead
При использовании больших словарей (начиная от десятков тысяч элементов), нужно помнить, что, в отличие от обычного Dictionary, в ConcurrentDictionary на каждый элемент создается дополнительный объект на куче. Резидентный ConcurrentDictionary с десятками миллионов элементов легко может обеспечить секундные паузы при сборке мусора второго поколения.
// Only a handful of objects in final dictionary.
// Value types dominate in its internals.
Dictionary ordinary = Enumerable
.Range(0, 10 * 1000 * 1000)
.ToDictionary(i => i, i => i);
// ~10kk objects in concurrent version (due to linked lists).
var concurrent = new ConcurrentDictionary(ordinary); При перезаписи существующего значения также может выделяться новый объект, порождая memory traffic. Это происходит в случае, если стандарт языка не гарантирует атомарность записи типа значения. Например:
- Если значение — int или reference type, его запись атомарна. Тогда перезапись производится in-place, без выделения нового объекта.
- Если значение — Guid или другой «широкий» value type, его запись не является атомарной. Здесь реализация вынуждена создавать новый внутренний объект.
Задача на DotNext 2017 Moscow
Я впервые опубликовал эту статью осенью 2017 года во внутренней соцсети. А коллеги, которые были в прошлом ноябре на конференции DotNext в Москве, сделали по мотивам статьи задачку, которую можно было решить на стенде Контура.
Там был фрагмент кода:
public void TestIteration(ConcurrentDictionary dictionary)
{
Parallel.For(0, 1000, new ParallelOptions { MaxDegreeOfParallelism = 8 }, (i) =>
{
foreach (var keyValuePair in dictionary)
{
dictionary.AddOrUpdate(keyValuePair.Key, (key) => i, (key, value) => i);
}
});
}
public void TestKeysProperty(ConcurrentDictionary dictionary)
{
Parallel.For(0, 1000, new ParallelOptions { MaxDegreeOfParallelism = 8 }, (i) =>
{
foreach (var key in dictionary.Keys)
{
dictionary.AddOrUpdate(key, (k) => i, (k, value) => i);
}
});
} И три вопроса — нужно было сравнить эффективность методов TestIteration и TestKeysProperty по количеству операций, по памяти и по времени выполнения. Если вы внимательно читали статью, то должно быть понятно, что во всех трёх случаях TestIteration эффективнее.
Выводы
Инструменты параллельного программирования бывают полны неочевидных тонкостей, когда речь заходит о производительности: при неосторожном использовании ConcurrentDictionary, например, можно столкнуться с глобальными блокировками и линейной стоимостью в памяти. Надеюсь, эта шпаргалка поможет не наступить на грабли при написании очередного кэша или индекса в своем приложении.
Всем добра и эффективного кода!
