[Перевод] Ричард Хэмминг: Глава 4. История компьютеров — Софт
«Пожалуйста, запомните, что изобретатель часто имеет очень ограниченное представление о том, что он изобрел.»
 Привет, Хабр. Помните офигенную статью «Вы и ваша работа» (+219, 2265 в закладки, 353k прочтений)?
Привет, Хабр. Помните офигенную статью «Вы и ваша работа» (+219, 2265 в закладки, 353k прочтений)?
Так вот у Хэмминга (да, да, самоконтролирующиеся и самокорректирующиеся коды Хэмминга) есть целая книга, написанная по мотивам его лекций. Давайте ее переведем, ведь мужик дело говорит.
Это книга не просто про ИТ, это книга про стиль мышления невероятно крутых людей. «Это не просто заряд положительного мышления; в ней описаны условия, которые увеличивают шансы сделать великую работу.»
Мы уже перевели 9 (из 30) глав.
Глава 4. Софт
(За перевод спасибо Станиславу Суханицкому, который откликнулся на мой призыв в «предыдущей главе».) Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru
Как я указывал в последней главе, в первые дни существования компьютеров контроль вычислений делался вручную. Медленные настольные компьютеры сначала контролировались вручную, например, умножение выполнялось повтором операции сложения в столбик со сдвигом столбцов после каждого множителя. Деление было реализовано аналогичной операцией повторения вычитаний. Со временем начали применяться электродвигатели как для питания, так и для более автоматического управления операциями умножения и деления.
Перфокарточные машины управлялись с помощью проводных соединений, идущих через коммутационную панель, которые сообщали машине где искать необходимую информацию, что с ней делать, и где ставить точки на перфокартах (или напечатанных листах табулятора); однако некоторые управляющие команды могли также поступать с самих карт, обычно изX и Y отверстий на перфокартах (другие цифры также могли время от времени контролировать, что будет происходить с программой). Для каждой выполняемой работы подготавливалась собственная коммутационная панель, снабжавшаяся индивидуальным коммутационным путем, в то время как в бухгалтерии коммутационные платы обычно сохранялись и использовались снова каждую неделю или месяц, так как их нужно было учитывать в цикле учета.
Когда мы перешли к релейным машинам, после создания Стибитцем первого компьютера оперирующего сложными числами, они в основном контролировались перфолентами. Бумажные перфоленты ленты являлись настоящим проклятием для выполнения одноразовых проблем — они беспорядочны, а склеивание перфолент для внесения исправлений, а также создания циклов — представляет собой крайне мучительную процедуру (потому что клей имеет тенденцию проникать в считывающие пальцы машины!). Из-за очень маленького внутреннего хранилища, в первые дни вычислений на компьютерах, программы не могли сохраняться в машинах с экономической точки зрения (хотя я склонен полагать, что именно дизайнеры просчитали этот момент).
ENIAC был сначала (1945–1946), контролируем с помощью проводов, как если бы это был гигантская коммутационная плата, но со временем Ник Метрополис и Дик Клипперэн превратили его в машину, программируемую с баллистических столов, представляющих собой огромные стойки с циферблатами, в которые, с помощью ручек десятичных переключателей, устанавливались десятичные цифры выполняемой программы.
Самостоятельное (внутренне) программирование компьютера стало реальностью, когда хранилище памяти стало более доступным для программ, и, хотя это изобретение обычно приписывают фон Нейманну, он был всего лишь консультантом Мочли и Эккерта и их команды. По словам Гарри Хаски, внутреннее программирование компьютера довольно часто обсуждалось группой до начала консультаций фон Нейманна. Первые широко доступные записки о внутреннем программировании (после того, как Леди Лавлейс написала и опубликовала несколько программ для аналитической машины Бэббиджа), были представлены фон Нейманном в виде отчетов для армии. Эти заметки впоследствии были широко распространены, однако никогда не публиковались в какой-либо типографии.
Ранние коды были, в основном, одноадресные, что значит каждая инструкция содержала часть инструкции и адрес, в котором должно находится или в который должно отправляться необходимое число. В нашем распоряжении также были двухадресные коды, которые использовались для барабанных компьютеров, что обеспечивало доступность следующей инструкции сразу же после завершения предыдущей инструкции. Та же самая логика применялась для ртутных линий задержки и других устройств хранения информации, которые были серийно доступны в тот момент времени. Такое кодирование называлось кодированием с минимальным временем ожидания, и вы можете представить себе проблемы, с которыми программист сталкивался при вычислении куда следует вводить следующую инструкцию и числа (это делалось для избегания возможных задержек и конфликтов в работе компьютера), не говоря уже о поиске ошибок программирования. Через какое-то время появилась программа с именем SOAP (символическая оптимизационная программа сборки), которая выполняла эту оптимизационную работу на машине IBM 650. Были также трех- и четырехадресные коды, но я о них не буду рассказывать в этой книге.
Интересно рассмотреть работу программы SOAP — копия программы, назовем ее программой A, загружалась в машину как программа и обрабатывалась как данные. Результатом вычислений была программа B. Затем программа B загружалась в IBM650, и программа A запускалась вновь, используясь в качестве данных для создания новой программы B. Разница между этими временами, необходимыми для создания программы B, показывала насколько была оптимизирована программа SOAP (по метрикам SOAP). Это действие представляло собой ранний пример самокомпилирования.
Вначале мы программировали на абсолютном бинарном языке, то есть мы писали фактический адрес и часть инструкции на бинарном языке! У нас было две тенденции избегания бинарного языка — использование восьмеричных чисел, где вы просто группируете двоичные числа в набор из трех чисел, и шестнадцатеричные числа, где вы берете четыре цифры за раз. Для функционирования шестнадцатеричных чисел нам приходилось использовать A, B, C, D, E, F для представления чисел, выходящих за 9 (и вы, конечно, уже знаете таблицы умножения и добавления до 15).
Если при исправлении ошибки вы хотели вставить некоторые пропущенные инструкции, то вы брали предшествующую инструкцию и заменяли ее переносом на какое-то пустое место. В этом пустом месте вы вводили необходимую инструкцию, которую удалили из предыдущей ячейки памяти, добавляли инструкции, которые вы хотели бы вставить, а затем переходили бы обратно к основной программе. Таким образом, программа в скором времени становилась последовательностью прыжков в довольно странные места. Иногда, как это почти всегда случается, обнаруживались и исправлялись программные ошибки, после чего использовался вышеописанный трюк, при котором использовалось другое свободное пространство. В результате путь управления программой с использованием хранилища данных вскоре приобретал вид банки со спагетти. Вы можете спросить: почему бы просто не вставлять исправления непосредственно в работающие инструкций? Потому что в этом случае приходилось проходиться через всю программу и изменять все адреса, которые каким-либо образом относились к любой из перенесенных инструкций! И ничего кроме этого не помогло бы программе корректно отработать!
Мы очень скоро перешли к идее создания повторно используемых программ, как их называют сейчас. У Бэббиджа была следующая идея. Мы писали математические библиотеки для повторного использования блоков кода. Но абсолютная адресация библиотеки означала, что каждый раз, когда использовалась библиотечная процедура, она должна была занимать одни и те же места в хранилище данных. Когда полная библиотека стала слишком большой, мы вынуждены были перейти к перемещаемым программам. Необходимые программные трюки были в отчетах фон Неймана, которые никогда официально не публиковались.
Первой опубликованной книгой, посвященной программированию, была книга Уилкс, Уилер и Гилл, и предназначалась для Кембриджа, Английского EDSAC (1951). Я, между прочим, многому научился из этой книги, и вы почтете об этом через несколько минут.
Затем кто-то понял, что можно написать короткую часть программы, которая будет читать символические имена операций (например, ADD) и переводить их, во время ввода программы, в бинарный код, используемый внутри машины (скажем, 01100101). За этим вскоре последовала идея использования символических адресов памяти в компьютере, что было настоящей ересью для старых программистов. Теперь вы не увидите того самого старого героического абсолютного программирования (если только вы не дурачитесь с программируемым руками компьютером пытаясь заставить его делать больше, чем когда-либо планировал его дизайнер и строитель).
Однажды я провел целый год, благодаря помощи леди-программиста из Bell Telephone Laboratories, работая над одной большой проблемой кодирования IBM 701 на абсолютном бинарном языке, который, в то время, использовал имеющиеся 32K регистры. После подобного опыта я поклялся, что больше никогда не попрошу кого-либо делать что-либо подобное. Узнав о символической системе в городке Poughkeepsie, IBM, я прошу леди взять эту символическую систему и использовать ее для разрешения следующей проблемы, что она и сделала. Как я и ожидал, леди сообщила, что работа стала в разы проще. Поэтому мы рассказали всем о новом методе — всего около 100 человек, которые ели в кафетериях офиса IBM, в котором стояла данная машина. Примерно половина из них были людьми из IBM, а половина, как и мы, были нанятыми посторонними рабочими. Насколько мне известно, только один человек — да, только один из всех 100 проявил интерес!
Наконец, была разработана более полная и более полезная программа Symbolic Assembly Program (SAP) — спустя большее количество лет, чем вы думаете, в течение которых большинство программистов продолжали свое героический путь в программировании на бинарном языке. В то время, когда SAP впервые появилась, я бы предположил, что около 1% зрелых программистов были заинтересованы в ней — использование SAP было «для неженок», и настоящий программист не стал бы тратить мощность машины на сборку программы с помощью SAP. Да! Программисты не хотели признавать этого, но, когда на них надавливали, они признавали, что их старые методы программирования использовали гораздо больше машинного времени, которое уходило на поиск и исправление ошибок, чем если бы использовалась программа SAP. Одной из основных жалоб на SAP было в использовании ей символической системы, при наличии которой вы не знаете адрес какой-либо информации в памяти. Хотя в ранние годы мы и предоставляли схему отображения символических ссылок на фактическое хранилище, но, хотите верьте или нет, программисты позже с любовью смотрели на эти схемы, не понимая, что им не нужно больше знать эту информацию, если они сталкивались с проблемами в работе в системы! Но они, при исправлении ошибок, все еще предпочитали делать это в бинарном представлении адреса.
FORTRAN, означающий FORmula TRANslation, был предложен Бэкусом и друзьями, и ему снова противостояли почти все программисты. Во-первых, говорили, что создать подобный язык невозможно. Во-вторых, если его можно было бы сделать, это было бы слишком расточительно для машинного времени и мощности. В-третьих, даже если бы идея подобной системы сработала, ни один уважаемый программист не использовал бы ее — ведь с подобными вещами могут работать только неженки!
Использование FORTRAN, как и более раннее символическое программирование, было очень сложно воспринять профессионалам. И подобное поведение характерно почти для всех профессиональных групп. Врачи совершенно не следуют советам, которые они дают другим, и даже среди них наблюдается высокая доля наркоманов. Адвокаты часто не оставляют порядочных завещаний, когда они умирают. Практически все профессионалы медленно используют собственный опыт в своей работе. Эта ситуация хорошо описывается старой поговоркой: «Дети производителя обуви всегда ходят без обуви». Подумайте, как вы в будущем будете избегать подобной типичной ошибки, когда вы станете серьезным специалистом!
Имея доступ к FORTRAN, я выстраивал с ним работу следующим образом: говорил своему программисту сделать работу на FORTRAN; проанализировать программные ошибки; дать мне проверить эту программу, чтобы убедиться, что она решает проблему верно; и только в этом случае она могла бы, если бы захотела, переписать внутренний цикл рабочей программы на машинном языке для ускорения работы и экономии времени машины. В результате мы смогли, с примерно такой же отдачей с нашей стороны, делать почти в 10 раз больше работы, чем другие. Однако для остальных программирование на FORTRAN все также было не для настоящих программистов!
Физически управление IBM 701 в штаб-квартире IBM в Нью-Йорке, где мы ее снимали, было ужасно. Это было пустой тратой машинного (в то время оно стоило 300 долларов в час, и это было много) и человеческого времени. В результате я отказался от заказа большей машины, пока не выяснил, откуда можно взять систему мониторинга, которую кто-то создал для нашего первого IBM 709, а затем модифицировал его и для IBM 7096.
Опять же, мониторы, часто называемые «системами мониторинга» в наши дни, как и все предыдущие вещи, о которых я упоминал, должны быть очевидным приобретением для всех, кто использовал компьютер изо дня в день; однако большинство пользователей, как мне кажется, были слишком заняты для раздумий или наблюдений, чтобы увидеть насколько все плохо и сколько может сделать компьютер для облегчения и удешевления использования различных вещей. Очевидные вещи довольно часто замечает человек, отстраненный от работы, или кто-то вроде меня, кто задумывается и задается вопросом, что он это делает и почему эта работа необходима. Старики будут учиться и работать как они привыкли, вероятно, из-за гордости за свое прошлое и нежелания признать, что есть способы лучше, чем те, которыми они пользовались такое долгое время.
Одним из способов описания того, что произошло в истории программного обеспечения, является то, что мы постепенно переходим от абсолютных к виртуальным машинам. Во-первых, мы избавились от фактических кодовых инструкций, а затем от фактических адресов, а затем в FORTRAN и от необходимости изучения множества внутренних компонентов сложных компьютеров и того как они работали. Мы делали пользователя машины из самой машины.
Довольно рано в Bell Telephone Laboratories мы построили устройство, которое делало ленточные устройства виртуальными, независимыми от самой машины. Тогда, и только тогда, когда у вас есть полностью виртуальная машина, вы сможете передавать программное обеспечение с одной машины на другую без бесконечных проблем и ошибок.
FORTRAN был невероятно успешным, гораздо успешнее ожиданий кого-либо из-за психологического факта, что он делал именно то, что подразумевалось под именем — транслировал в формульном виде все те вещи, которые изучались еще в школе. И это не требовало изучения нового набора способов мышления.
Алгол, примерно в 1958–1960 годах, поддерживался многими всемирными компьютерными организациями, включая ACM. Это было попыткой теоретиков значительно улучшить ФОРТРАН. Но, будучи логиками, они создали логический, а не человеческий язык и, конечно, как вы знаете, этот эксперимент провалился. Это, между прочим, было из-за Булевой логики, которая не понятна простым смертным (и часто даже самим логикам!). Многие другие разработанные логические языки, которые должны были заменить первопроходца FORTRAN, приходили и уходили, в то время как FORTRAN (стоит отметить несколько модифицированный) остается широко используемым языком, четко показывающим силу языков разработанных с учетом психологии над языками разработанными с учетом логики.
Это стало началом большой надежды для специализированных языков, которые были POLs, что означает проблемно-ориентированные языки. Существует некоторая заслуга в этой идее, но энтузиазм вскоре исчез, потому что слишком много проблем возникали в более чем одной области и языки, как правило, оказывались несовместимы. Более того, в долгосрочной перспективе они были слишком сложными на этапе обучения для людей на достаточном уровне.
В 1962 году появился язык LISP. Разнообразные слухи распространялись вокруг того, как на самом деле он появился, вероятная истина такова: Джон МакКарти предложил элементы языка для теоретических целей; это предложение было рассмотрено и значительно переработано другими людьми, и когда какой-то ученик заметил, что он мог бы написать компилятор для этого языка на LISP, используя простой трюк с самокомпилированием, все были поражены, в том числе, по-видимому, сам Маккарти. Он призвал ученика попробовать это сделать и почти за одну ночь они перешли от теории к реальному компилятору LISP!
Позвольте отвлечься и обсудить мой опыт работы с IBM 650. Это была двухадрессная барабанная машина, которая работала с фиксированными десятичными числами. Из моего прошлого опыта в области исследований я знал, что мне необходимы числа с плавающей точкой (архитектура фон Неймана, если говорить иначе), и мне нужны индексные регистры, которых не было в предоставленной машине. IBM однажды предложит подпрограммы с плавающей точкой, как они говорили, но этого было для меня недостаточно. Я просмотрел журнал «EDSAC» по программированию, и там, в Приложении D, была специальная программа, написанная для размещения большой программы в маленьком хранилище. Это был интерпретатор. Но если это было в Приложении D, видели ли они важность этой программы? Я в этом сомневаюсь! Кроме того, во втором издании он все еще присутствовал в Приложении D, по-видимому все еще не признанный авторами.
Это поднимает, как я надеюсь, уродливый вопрос: когда что-то начинает понимается? Да, они написали одну программу и использовали ее, но поняли ли они всеобщность интерпретаторов и компиляторов? Я думаю нет. Точно так же, когда примерно в то время многие из нас поняли, что компьютеры на самом деле являются машинами манипулирующими символами, а не просто машинами, предназначенными для обработки чисел. Мы ходили и обсуждали эту идею, и я видел, как люди злобно кивали головами, когда я это говорил, но я также понял, что большинство из них не понимало о чем идет речь. Конечно, вы можете сказать, что оригинальная статья Тьюринга (1937) ясно показала, что компьютеры были машинами для манипулирования символами, но, если тщательно перечитывать отчеты фон Неймана, вы можете заметить, что авторы не поняли этого — они сделали только одну комбинаторную программу и процедуру сортировки.
История очень щедра на подобные примеры. Это дает понять, что что-то значит, когда мы что-то делаем впервые. Но есть мудрое высказывание: «Почти каждый, кто открывает нечто новое, на самом деле не понимает это знание так, как это делают последователи». Свидетельства этого высказывания, к сожалению, слишком хорошо известны. Как было сказано, что в физике никто из создателей каких-либо значительных вещей никогда до конца не понимал, что он сделал.
Специальная теория относительности Эйнштейна была понята очень ясно лишь некоторыми поздними комментаторами. И, по крайней мере, один мой друг сказал за моей спиной: «Хэмминг, похоже, не понимает исправляющие ошибки коды!». Вероятно, он прав. Я не смогу понять что я придумал также ясно как он. Причина, по которой это случается так часто, заключается в том, что создатели вынуждены бороться с такими темными трудностями и пробираться сквозь столько недоразумений и путаницы, что они не могут видеть свет так ярко, как другие, когда открывается дверь знаний и последующий путь к пониманию становится достаточно легким. Пожалуйста, запомните, что изобретатель часто имеет очень ограниченное представление о том, что он изобрел, а некоторые другие люди (вы?) могут видеть гораздо больше. Но также помните это, когда вы сами являетесь автором какой-то блестящей новой идеи; в скором времени это, возможно, станет верным и для вас. Ранее говорилось, что Ньютон был последним из древних, а не первым из современников, хотя он сыграл значительную роль в создании нашего современного мира.
Вернемся к IBM 650 и мне. Я начал (в 1956 или около того) со следующих четырех правил для разработки языка:
1. Легкий в изучении.
2. Простой в использовании.
3. Легкий для отладки (нахождения и исправления ошибок).
4. Простой в использовании подпрограмм.
Последний пункт не должен сейчас вас беспокоить, поскольку в те дни мы проводили различие между «открытыми» и «закрытыми» подпрограммами, которые трудно объяснить сейчас!
Вы могли бы утверждать, что я занимаюсь нисходящим подходом (top-down) в программировании, однако я сразу же писал детали внутреннего цикла для проверки эффективности моего кода (восходящий подход (bottom-up) в программировании), и только после этого возобновлял свой нисходящий, философский подход. Таким образом, хотя я считаю, что нисходящее программирование является хорошим подходом, я отчетливо осознаю, что восходящее программирование также необходимо время от времени.
Я заставил работать двухадресную машину оперирующую числами с фиксированной точкой, как трехадресную машину оперирующую числами с плавающей точкой — такова была моя цель -A операция В = С. Я использовал десять десятичных цифр машины (это был настолько десятичный компьютер, насколько был заинтересован в работе этой машины типичный пользователь) в виде:
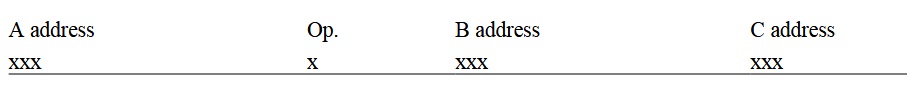
Как же я это сделал? Легко! Я написал в моем воображении следующий цикл (Рисунок 4.I): Во-первых, мне нужен был регистр текущих адресов, CAR, и для этого я назначил один из 2000 компьютерных регистров IBM 650 хранения этой информации. Затем мы написали программу, пользуясь следующими шагами. (1) Использовать CAR для нахождения адреса считывания следующей инструкции написанной программы. (2) Выделение инструкции выполнения программы, и сохранение трех адресов, A, B и C, в подходящих ячейках в памяти IBM650. (3) добавление фиксированной константы к операции и переход к ее адресу хранения. Там для каждой инструкции должна находиться подпрограмма, описывающая соответствующую операцию. Вы могли бы подумать, что у меня было всего десять возможных операций, однако существует только четыре возможные операции с тремя адресами: сложение, вычитание, умножение и деление. Поэтому, я использовал нулевую команду, которая обозначала «перейти на адрес B и найти дальнейшую необходимую информацию». Каждая подпрограмма, когда заканчивалась, передавала управление в заданное место в цикле.(4) Добавление 1 к содержимому регистра CAR, изменение некоторых параметров и очередной вход в систему, таким же образом, как это делает машина. Конечно, инструкции перехода (их было 7 штук, насколько я помню) помещают адрес в CAR и переносятся в свое место в цикл только после добавления единицы к содержимому регистра CAR.
Изучение процесса показывает — какой бы смысл вы бы ни хотели дать инструкциям, он должен исходить из подпрограмм, которые пишутся в соответствии с номерами инструкций. Эти подпрограммы определяют смысл языка программирования. В этом простом случае каждая инструкция имела свой собственный смысл независимо от какой-либо другой инструкции, но разумеется, некоторые инструкции могут устанавливать переключатели, флаги или другие биты, поэтому некоторые более поздние выполняющиеся инструкции будут воспринимать эту информацию и интерпретироваться различными способами. Таким образом, вы сможете понять, как следует разрабатывать любой язык, если вы сможете однозначно определить его назначение. Понимание назначения выходит за рамки конкретного описания языка для машины, превращая одну определенную машину в любую другую которую вы захотите.
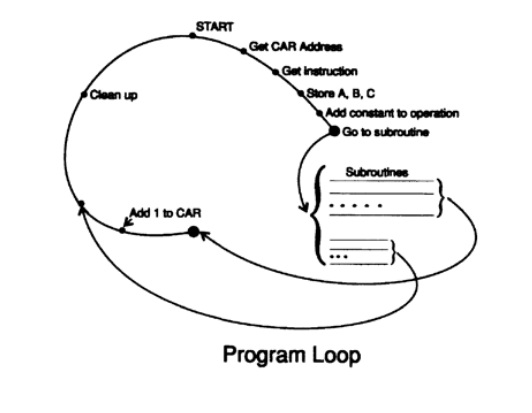
Конечно, это именно то, что сделал Тьюринг со своей Универсальной машиной Тьюринга, но, как отмечалось выше, назначение этой машины не было до конца понято, пока люди не начали ее использовать.
Созданная мной программная система была помещена в регистры хранения с 1000 по 1999.
Таким образом, любая программа, описанная на синтетическом языке, имеющая только 3 десятичных цифры, могла ссылаться только на адреса от 000 до 999 и не могла ссылаться на любой другой регистр в программном обеспечении, тем самым переписывая его. Эта система была разработана для защиты программного обеспечения от пользователя.
Я подробно рассмотрел эту тему, поскольку мы обычно пишем язык в качестве обертки для машинного языка и даже можем написать еще несколько более высокоуровневых языков, один поверх другого, пока мы не получим тот язык, который мы хотим использовать для выражения наших мыслей машине. Если вы используете интерпретатор на каждом этапе, то, конечно, эти операции будут не эффективны. Использование компилятора высокоуровневыми языками будет означать, что самый высокоуровневый язык переводится на один из низкоуровневый язык, хотя на каком-то уровне все равно может наблюдаться интерпретатор. Это также означает, как и в случае с EDSAC, как правило, увеличение отдачи от написанных программ и улучшение их хранения.
Я хочу еще раз указать разницу между написанием логического и психологического языка. К сожалению, логически ориентированные программисты редко ориентируются на человека, и склонны использовать и превозносить логические языки. Возможно, абсолютным примером этого стремления является APL. С логической стороны APL — отличный язык, и по сей день у него есть ярые фанаты, однако он совершенно не подходит для обычных людей. Пользователи этого языка часто играют в игру «одна строка», в которой играющему выдается одна строка кода, и его спрашивают, что она выполняет. Известно, что даже эксперты этого языка часто не могут ответить на некоторые варианты программ.
Изменение одной буквы в APL может полностью изменить смысл программы, поэтому язык почти не имеет избыточности. Но люди ненадежны и требуют избыточности; наш разговорный язык примерно на 60% избыточен, а письменный язык — примерно на 40%. Вы, наверное, думаете, что письменный и разговорный языки одинаковые, однако вы ошибаетесь. Чтобы увидеть это различие, попробуйте написать диалог, а затем прочитайте его, и послушайте как это звучит. Почти никто не в состоянии написать такой диалог, чтобы он звучал правильно, и даже если диалог звучит правильно, он еще не является разговорным языком.
Человек ненадежен, и я продолжаю настаивать на этом, поэтому низкая избыточность означает множество необнаруженных ошибок, в то время как высокая избыточность способствует отлавливанию ошибок. Разговорный язык представляет собой акустический канал со всем его шумом, и язык должен быть пойман на лету. Письменный язык печатается, и вы можете сделать паузу, сканировать прочитанный текст и сделать другие вещи, для более глубокого раскрытия смысла слов автора. Обратите внимание, что в английском языке чаще разные слова имеют одинаковое звучание и разное написание (например, «there» («там») и «their» («их»)), чем одинаковое написание и разное звучание («record» («записывать») как существительное или глагол, и «tear» («слеза»), as in tear in the eye, vs. tear in a dress (слеза в глазу, разрыв в платье)). Таким образом, вы должны судить языки по тому как хорошо он подходит для человека — и учтите, я также беру в расчет то, как они обучаются языку в школе; иначе вы должны быть готовыми тратить много времени на обучение людей новому языку, которым они будут пользоваться. То, что язык для программиста является простым, не означает, что он будет таким же простым для неспециалиста, и в ближайшем будущем, скорее всего, неспециалисты будут делать основную часть программирования компьютеров (будут заниматься кодированием, если хотите).
Разумеется, в конечном итоге нам необходимо решение, при котором человек имеющий проблему сможет ее решить без участия интерфейса в виде специалист-компьютер. Однако в наши дни можно слишком часто наблюдать ситуацию, когда есть человек, который знает только проблему, и человек, который знает только язык программирования. К сожалению, прогнозируемая дата этого события слишком далека, но я полагаю, что к 2020 году для экспертов в практических областях было бы достаточно универсальной практикой выполнять лишь подготовку программы к работе, без экспертов в компьютерах (которые не являются специалистами в практических областях) для этого дела.
К сожалению, по крайней мере, на мой взгляд, язык ADA был разработан экспертами, и он имеет полный набор нечеловеческих (логических) функции, которые только можно ожидать. Этот продукт, на мой взгляд, является типичной работой по хакингу компьютерных наук — не пытаться понять, что вы делаете, а просто заставить эту вещь работать. В результате плохого психологического дизайна ADA, мною был проведен частный опрос среди умудренных опытом людей, который показал, что хотя правительственные организации требуют от своих заказчиков написание программ на языке ADA, вероятнее всего, более 90% программы будет написана, отлажена и проверена на FORTRAN и после этого она будет болезненно, вручную, переписана в программу на ADA с высоким содержанием ошибок!
Основы языков не понимаются и по сей день. Где-то в начале 1950-х годов я взял тогдашнего местного эксперта по естественному языку (по мнению общественности), для посещения IBM 701, а затем на обеде во время десерта я сказал: «Профессор Пей, не могли бы мы обсудить техническую эффективность языков». Он просто не мог понять этот вопрос и продолжал рассказывать нам, как конкретный язык образует слова во множественном числе, используя середину выбранного слова, какие характерные особенности имеют языки и т.д. Что бы я хотел знать — можно ли разработать эффективные язык для коммуникации (если мы в состоянии разработать собственный язык), в котором одной стороной в общении был бы человек со всеми своими недостатками, а на другой — машина с высокой надежностью, которая делает только что ей говорят, но не более того. Я хотел бы знать, какой процент избыточности должны иметь эти языки; с какой частотой в языке встречаются нерегулярные и регулярные глаголы; каково процентное соотношение синонимов к антонимам; почему в языке есть только определенное количество слов; как можно эффективно сжать канал связи, оставляя язык пригодным для использования человеком с точки зрения избыточности языка и т. д. Как я уже сказал, он не понял мой вопрос, который касался инженерной эффективности языков, и с тех пор я не наблюдал большого количества исследований в этой области. Но до тех пор, пока мы действительно не поймем эти вещи — считая, если это разумно, что существующие естественные языки прошли долгую эволюцию и идеально подходят для людей, пока мы не поймем этого — мы не сможем создать искусственные языки для общения человек-машина. Поэтому я ожидаю много неприятностей на пути к пониманию человеческого общения через естественные языки.
Конечно, проблема общения человек-машина существенно отличается от общения человек-человек, но каким образом и насколько они отличаются, нам до сих пор неизвестно.
Пока мы не сможем лучше понимать языки общения людей (или их можно легко обучить), маловероятно, в таком случае многие из наших проблем в программном обеспечении исчезнут.
Некоторое время назад, когда было введено «пятое поколение» компьютеров, которое японцы планировали использовать совместно с ИИ, для получения лучшего интерфейс между машиной и человеком. Большие претензии предъявлялись как машинам, так и языкам. В результате появились машины, которые рекламировались, и инженеры вернулись к чертежным доскам по использованию ИИ, для помощи людям в программировании. Это произошло, как я и предсказывал в то время (для Лос-Аламоса), поскольку я не видел, чтобы японцы пытались понять основы языка в вышеупомянутом инженерном смысле. Есть много вещей, которые мы можем сделать, чтобы уменьшить «проблему программного обеспечения», как мы ее называем, но нам требуется некоторое базовое понимание того, как мы понимаем язык, который используется для общения между людьми и между людьми и машинами, прежде чем мы получим действительно достойное решение этой дорогостоящей проблемы. И эта проблема просто так не исчезнет.
Вы постоянно читаете о «разработке продукции программного обеспечения», как для эффективности производства, так и для надежности продукта. Но вы не ожидаете, что романисты «спроектируют производство романов». Возникает вопрос: «Является ли программирование ближе к письму, чем к классической инженерии?» Я полагаю да! Учитывая проблему попадания человека в космическое пространство, как русские, так и американцы реализовали эту цель почти одинаково, учитывая все обстоятельство, и допуская какую-то долю шпионажа. Они были ограничены одними и теми же законами физики. Но дайте двум романистам задачу написать «о величии и нищете человека», и вы, вероятно, получите два совершенно разных романа (даже не упоминая того, как вы будете измерять разницу). Дайте такую же сложную проблему двум современным программистам, и я уверяю вас, вы получите две совершенно разные программы. Поэтому я верю, что современное программирование ближе к письменному, чем к инженерному искусству. Романисты связаны только своими фантазиями, что также верно и для программистов в написании программного обеспечения. Оба действиях предполагают большой творческий компонент, и, ес
