Индексы в PostgreSQL — 7
Мы уже познакомились с механизмом индексирования PostgreSQL и с интерфейсом методов доступа, и рассмотрели хеш-индексы, B-деревья, индексы GiST и SP-GiST. А в этой части займемся индексом GIN.
GIN
— Джин?… Джин — это, кажется, такой американский спиртной напиток?…
— Не напиток я, о пытливый отрок! — снова вспылил старичок, снова спохватился и снова взял себя в руки. — Не напиток я, а могущественный и неустрашимый дух, и нет в мире такого волшебства, которое было бы мне не по силам.
Лазарь Лагин, «Старик Хоттабыч».
Gin stands for Generalized Inverted Index and should be considered as a genie, not a drink.
README
Общая идея
GIN расшифровывается как Generalized Inverted Index — это так называемый обратный индекс. Он работает с типами данных, значения которых не являются атомарными, а состоят из элементов. При этом индексируются не сами значения, а отдельные элементы; каждый элемент ссылается на те значения, в которых он встречается.
Хорошая аналогия для этого метода — алфавитный указатель в конце книги, где для каждого термина приведен список страниц, где этот термин упоминается. Как и указатель в книге, индексный метод должен обеспечивать быстрый поиск проиндексированных элементов. Для этого они хранятся в виде уже знакомого нам B-дерева (для него используется другая, более простая, реализация, но это не существенно). К каждому элементу привязан упорядоченный набор ссылок на строки таблицы, содержащие значения с этим элементом. Для выборки данных упорядоченность не принципиальна (порядок сортировки TID-ов не несет в себе особого смысла), но она важна с точки зрения внутреннего устройства индекса.
Элементы никогда не удаляются из GIN-индекса. Считается, что значения, содержащие элементы, могут пропадать, появляться, изменяться, но набор элементов, из которых они состоят — довольно статичен. Такое решение существенно упрощает алгоритмы, обеспечивающие параллельную работу с индексом нескольких процессов.
Если список TID-ов достаточно мал, он помещается в ту же страницу, что и элемент (и называется posting list). Но если список большой, нужна более эффективная структура данных, и мы ее уже знаем — это снова B-дерево. Такое дерево располагается в отдельных страницах данных (и называется posting tree).
Таким образом, индекс GIN состоит из B-дерева элементов, к листовым записям которого привязаны B-деревья или плоские списки TID-ов.
Как и рассмотренные ранее индексы GiST и SP-GiST, GIN предоставляет прикладному разработчику интерфейс для поддержки различных операций над сложносоставными типами данных.
Полнотекстовый поиск
Основная область применения метода gin — ускорение полнотекстового поиска, поэтому логично рассматривать этот индекс более подробно именно на этом примере.
В части про GiST уже было небольшое введение в полнотекстовый поиск, так что не будем повторяться и перейдем сразу к делу. Понятно, что сложносоставными значениями в этом случае являются документы, , а элементами этих документов — лексемы.
Возьмем тот же пример, который мы рассматривали в части про GiST (только повторим припев два раза):
postgres=# create table ts(doc text, doc_tsv tsvector);
CREATE TABLE
postgres=# insert into ts(doc) values
('Во поле береза стояла'), ('Во поле кудрявая стояла'),
('Люли, люли, стояла'), ('Люли, люли, стояла'),
('Некому березу заломати'), ('Некому кудряву заломати'),
('Люли, люли, заломати'), ('Люли, люли, заломати'),
('Я пойду погуляю'), ('Белую березу заломаю'),
('Люли, люли, заломаю'), ('Люли, люли, заломаю');
INSERT 0 12
postgres=# set default_text_search_config = russian;
SET
postgres=# update ts set doc_tsv = to_tsvector (doc);
UPDATE 12
postgres=# create index on ts using gin (doc_tsv);
CREATE INDEX
Возможная структура такого индекса показана на рисунке:
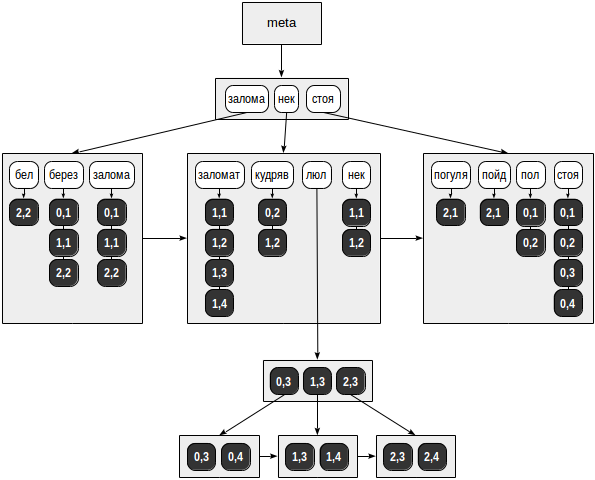
В отличие от всех предыдущих иллюстраций, ссылки на табличные строки (TID-ы) показаны не стрелочками, а числовыми значениями на темном фоне (номер страницы и позиция в странице):
postgres=# select ctid, doc, doc_tsv from ts;
ctid | doc | doc_tsv
--------+-------------------------+--------------------------------
(0,1) | Во поле береза стояла | 'берез':3 'пол':2 'стоя':4
(0,2) | Во поле кудрявая стояла | 'кудряв':3 'пол':2 'стоя':4
(0,3) | Люли, люли, стояла | 'люл':1,2 'стоя':3
(0,4) | Люли, люли, стояла | 'люл':1,2 'стоя':3
(1,1) | Некому березу заломати | 'берез':2 'заломат':3 'нек':1
(1,2) | Некому кудряву заломати | 'заломат':3 'кудряв':2 'нек':1
(1,3) | Люли, люли, заломати | 'заломат':3 'люл':1,2
(1,4) | Люли, люли, заломати | 'заломат':3 'люл':1,2
(2,1) | Я пойду погуляю | 'погуля':3 'пойд':2
(2,2) | Белую березу заломаю | 'бел':1 'берез':2 'залома':3
(2,3) | Люли, люли, заломаю | 'залома':3 'люл':1,2
(2,4) | Люли, люли, заломаю | 'залома':3 'люл':1,2
(12 rows)
В нашем умозрительном примере список TID-ов поместился в обычные страницы для всех лексем, кроме «люл». Эта лексема встретилась в целых шести документах и для нее список TID-ов был помещен в отдельное B-дерево.
Как, кстати, понять, сколько документов содержат лексему? Для небольшой таблицы сработает и «прямой» способ, показанный ниже, а как быть с большими, мы увидим далее.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count
---------+-------
люл | 6
стоя | 4
заломат | 4
берез | 3
залома | 3
пол | 2
нек | 2
кудряв | 2
бел | 1
пойд | 1
погуля | 1
(11 rows)
Еще заметим, что, в отличие от обычного B-дерева, страницы индекса GIN связаны не двунаправленным, а однонаправленным списком. Этого достаточно, поскольку обход дерева выполняется всегда только в одну сторону.
Пример запроса
Как будет выполняться в нашем примере следующий запрос?
postgres=# explain(costs off)
select doc from ts where doc_tsv @@ to_tsquery('стояла & кудрявая');
QUERY PLAN
------------------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('стояла & кудрявая'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('стояла & кудрявая'::text))
(4 rows)
Сначала из поискового запроса выделяются отдельные лексемы (ключи поиска): «стоя» и «кудряв». Это выполняется специальной API-функцией, которая учитывает тип данных и стратегию, определенную классом операторов:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'tsvector_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
@@(tsvector,tsquery) | 1 соответствие поисковому запросу
@@@(tsvector,tsquery) | 2 синоним @@ (для обратной совместимости)
(2 rows)
Далее находим в B-дереве лексем оба ключа и перебираем готовые списки TID-ов. Получаем:
- для «стоя» — (0,1), (0,2), (0,3), (0,4);
- для «кудряв» — (0,2), (1,2).
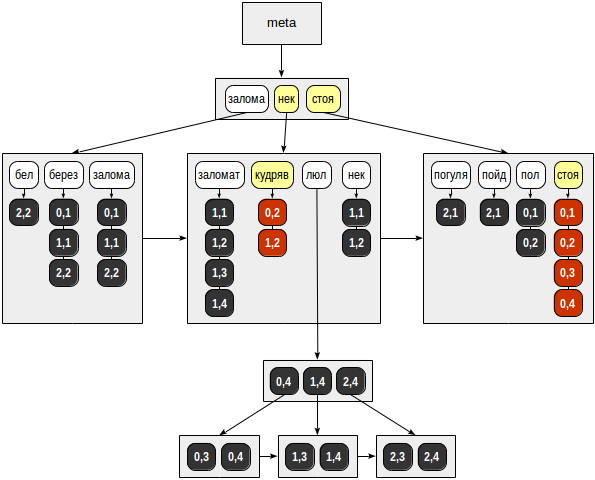
Наконец, для каждого найденного TID-а вызывается API-функция соответствия, которая должна определить, какие из найденных строк подходят под поисковый запрос. Поскольку в нашем запросе лексемы объединены логическим «и», возвращается единственная строка (0,2):
| | | функция
| | | согласованности
TID | стоя | кудряв | стоя & кудряв
-------+------+--------+-----------------
(0,1) | T | f | f
(0,2) | T | T | T
(0,3) | T | f | f
(0,4) | T | f | f
(1,2) | f | T | f
И получаем результат:
postgres=# select doc from ts where doc_tsv @@ to_tsquery('стояла & кудрявая');
doc
-------------------------
Во поле кудрявая стояла
(1 row)
Если сравнить этот подход с тем, который мы рассматривали применительно к GiST, преимущество GIN для полнотекстового поиска кажется очевидным. Но не все так просто.
Проблема медленного обновления
Дело в том, что вставка или обновление данных в GIN-индексе выполняется относительно медленно. Каждый документ обычно содержит много лексем, подлежащих индексированию. Поэтому при появлении или изменении одного-единственного документа приходится вносить массовые изменение в дерево индекса.
С другой стороны, если изменяется сразу несколько документов, то часть лексем у них может совпасть, и общий объем работы окажется меньше, чем при изменении документов поодиночке.
У GIN-индекса есть параметр хранения fastupdate, который можно указать при создании индекса или изменить позже:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
CREATE INDEX
При включенном параметре изменения будут накапливаться в виде отдельного неупорядоченного списка (в отдельных связанных страницах). Когда этот список становится достаточно большим, либо при выполнении процесса очистки, все накопленные изменения одномоментно вносятся в индекс. Что считать «достаточно большим» списком, определяется конфигурационным параметром gin_pending_list_limit или одноименным параметром хранения самого индекса.
Но такой подход имеет и негативные стороны: во-первых, замедляется поиск (за счет того, что кроме дерева приходится просматривать еще и неупорядоченный список), а во-вторых, очередное изменение может внезапно занять много времени, если неупорядоченный список переполнился.
Поиск частичного совпадения
В полнотекстовом поиске можно использовать частичное совпадение. Запрос формулируется, например, следующим образом:
gin=# select doc from ts where doc_tsv @@ to_tsquery('залом:*');
doc
-------------------------
Некому березу заломати
Некому кудряву заломати
Люли, люли, заломати
Люли, люли, заломати
Белую березу заломаю
Люли, люли, заломаю
Люли, люли, заломаю
(7 rows)
Такой запрос найдет документы, в которых есть лексемы, начинающиеся на «залом». То есть, в нашем примере, «залома» (которая получилась из слова «заломаю») и «заломат» (из слова «заломати»).
Запрос, разумеется, будет работать в любом случае, даже и без индексов, но GIN позволяет ускорить и такой поиск:
postgres=# explain (costs off)
select doc from ts where doc_tsv @@ to_tsquery('залом:*');
QUERY PLAN
--------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('залом:*'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('залом:*'::text))
(4 rows)
При этом в дереве лексем находятся все лексемы, имеющие указанный в поисковом запросе префикс, и объединяются логическим «или».
Частые и редкие лексемы
Чтобы посмотреть, как индексирование работает на реальных данных, возьмем архив рассылки pgsql-hackers, который мы уже использовали в теме про GiST. В этой версии архива содержится 356125 писем с датой отправления, темой, автором и текстом.
fts=# alter table mail_messages add column tsv tsvector;
ALTER TABLE
fts=# set default_text_search_config = default;
SET
fts=# update mail_messages
set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed
DETAIL: Words longer than 2047 characters are ignored.
...
UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
CREATE INDEX
Возьмем лексему, которая встречается в большом числе документов. Запрос, использующий unnest, на таком объеме данных уже не отработает, а правильный способ — использовать функцию ts_stat, которая выдает информацию о лексемах, числе документов, в которых они встретились, и общем количестве вхождений.
fts=# select word, ndoc
from ts_stat('select tsv from mail_messages')
order by ndoc desc limit 3;
word | ndoc
-------+--------
re | 322141
wrote | 231174
use | 176917
(3 rows)
Выберем «wrote».
И возьмем какое-нибудь редкое в рассылке разработчиков слово, например, «tattoo»:
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc
--------+------
tattoo | 2
(1 row)
Есть ли документы, в которых эти лексемы встречаются одновременно? Оказывается, есть:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)
Вопрос в том, как выполнить этот запрос. Если, как было описано выше, получать списки TID-ов для обоих лексем, поиск получится очевидно неэффективным: нам придется перебрать более двухсот тысяч значений, из которых в результате останется только одно. К счастью, используя статистику планировщика, алгоритм понимает, что лексема «wrote» встречается часто, а «tattoo» — редко. Поэтому поиск выполняется по редкой лексеме, а полученные два документа затем проверяются на наличие в них лексемы «wrote». Что и видно — запрос выполняется быстро:
fts=# \timing on
Timing is on.
fts=# select count (*) from mail_messages where tsv @@ to_tsquery ('wrote & tattoo');
count
-------
1
(1 row)
Time: 0,959 ms
Хотя поиск просто «wrote» — существенно дольше:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
--------
231174
(1 row)
Time: 2875,543 ms (00:02,876)
Такая оптимизация работает, конечно, не только для двух лексем, но и в более сложных случаях.
Ограничение выборки
Особенность метода доступа gin состоит в том, что результат всегда возвращается в виде битовой карты: выдавать TID-ы по одному этот метод не умеет. Именно поэтому все планы запросов, которые встречаются в этой части, используют сканирование по битовой карте (bitmap scan).
Поэтому ограничение выборки по индексу с помощью фразы LIMIT не вполне эффективно. Обратите внимание на прогнозируемую стоимость операции (поле «cost» узла Limit):
fts=# explain (costs off)
select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN
-----------------------------------------------------------------------------------------
Limit (cost=1283.61..1285.13 rows=1)
-> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207)
Recheck Cond: (tsv @@ to_tsquery('wrote'::text))
-> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207)
Index Cond: (tsv @@ to_tsquery('wrote'::text))
(5 rows)
Стоимость оценена как 1283.61, что чуть больше, чем стоимость построения всей битовой карты 1249.30 (поле «cost» узла Bitmap Index Scan).
Поэтому индекс имеет специальную возможность ограничивать количество результатов. Пороговое значение задается в конфигурационном параметре gin_fuzzy_search_limit и по умолчанию равно нулю (ограничения не происходит). Однако его можно установить:
fts=# set gin_fuzzy_search_limit = 1000;
SET
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
5746
(1 row)
fts=# set gin_fuzzy_search_limit = 10000;
SET
fts=# select count (*) from mail_messages where tsv @@ to_tsquery ('wrote');
count
-------
14726
(1 row)
Как видно, запрос выдает разное количество строк при разных значениях параметра (если используется доступ по индексу). Ограничение не точное; может быть выдано больше строк, чем указано — поэтому и fuzzy.
Компактное представление
Помимо прочего, GIN-индексы хороши своей компактностью. Во-первых, если одна и та же лексема встречается в нескольких документах (а так обычно и бывает), она хранится в индексе только один раз. Во-вторых, TID-ы хранятся в индексе упорядоченно, а это дает возможность использовать простое сжатие: каждый следующий в списке TID хранится на самом деле как разность с предыдущим — обычно это небольшое число, на которое нужно гораздо меньше битов, чем на полный 6-байтовый TID.
Чтобы получить какое-то представление об объеме, создадим B-дерево по тексту писем. Честного сравнения, конечно, не получится:
- GIN строится на другом типа данных (tsvector, а не text), а он меньше,
- зато размер писем для B-дерева приходится укорачивать примерно до двух килобайт.
Но тем не менее:
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
CREATE INDEX
Заодно построим и GiST-индекс:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
CREATE INDEX
Размер индексов после полной очистки (vacuum full):
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin,
pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist,
pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree
--------+--------+--------
179 MB | 125 MB | 546 MB
(1 row)
Благодаря компактности представления индекс GIN можно попробовать использовать при миграции с Oracle в качестве замены bitmap-индексам (не буду вдаваться в подробности, но для пытливых умов оставлю ссылку на пост Льюиса). Как правило, bitmap-индексы применяются для полей, которые имеют немного уникальных значений — что прекрасно и для GIN. А строить битовую карту, как мы видели в первой части, PostgreSQL умеет на лету на основе любого индекса, в том числе и GIN.
GiST или GIN?
Для многих типов данных существуют классы операторов и для GiST, и для GIN, что вызывает вопрос: чем же пользоваться? Пожалуй, уже можно сделать какие-то выводы.
Как правило, GIN выигрывает в точности и скорости поиска у GiST. Если данные изменяются не часто, а искать надо быстро — скорее всего выбор падет на GIN.
С другой стороны, если данные изменяются активно, накладные расходы на обновление GIN могут оказаться слишком велики. В этом случае придется сравнивать оба варианта и выбирать тот, чьи показатели будут лучше сбалансированы.
Массивы
Другой пример использования метода gin — индексирование массивов. В этом случае в индекс попадают элементы массивов, что позволяет ускорять ряд операций над ними:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'array_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
&&(anyarray,anyarray) | 1 пересечение
@>(anyarray,anyarray) | 2 содержит массив
<@(anyarray,anyarray) | 3 содержится в массиве
=(anyarray,anyarray) | 4 равенство
(4 rows)
В нашей демо-базе есть представление routes с информацией о рейсах. В числе прочего оно содержит столбец days_of_week — массив дней недели, по которым совершаются полеты. Например, рейс из Внуково в Геленджик отправляется по вторникам, четвергам и воскресеньям:
demo=# select departure_airport_name, arrival_airport_name, days_of_week
from routes
where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week
------------------------+----------------------+--------------
Внуково | Геленджик | {2,4,7}
(1 row)
Чтобы построить индекс, «материализуем» представление в таблицу:
demo=# create table routes_t as select * from routes;
SELECT 710
demo=# create index on routes_t using gin(days_of_week);
CREATE INDEX
Теперь с помощью индекса мы можем узнать все рейсы, отправляющиеся по вторникам, четвергам и воскресеньям:
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: (days_of_week = '{2,4,7}'::integer[])
-> Bitmap Index Scan on routes_t_days_of_week_idx
Index Cond: (days_of_week = '{2,4,7}'::integer[])
(4 rows)
Оказывается, таких 6 штук:
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week
-----------+------------------------+----------------------+--------------
PG0005 | Домодедово | Псков | {2,4,7}
PG0049 | Внуково | Геленджик | {2,4,7}
PG0113 | Нарьян-Мар | Домодедово | {2,4,7}
PG0249 | Домодедово | Геленджик | {2,4,7}
PG0449 | Ставрополь | Внуково | {2,4,7}
PG0540 | Барнаул | Внуково | {2,4,7}
(6 rows)
Как выполняется такой запрос? Точно так же, как было описано выше:
- Из поискового запроса, роль которого здесь играет массив {2,4,7}, выделяются элементы (ключи поиска). Очевидно, это будут значения »2»,»4» и »7».
- В дереве элементов находятся выделенные ключи и для каждого из них выбирается список TID-ов.
- Из всех найденных TID-ов функция согласованности выбирает те, что подходят под оператор из запроса. Для оператора = годятся только те TID-ы, которые встретились во всех трех списках (иными словами, исходный массив должен содержать все элементы). Но этого недостаточно: нужно еще, чтобы массив не содержал никаких других значений —, а это условие мы не можем проверить по индексу. Поэтому в данном случае метод доступа просит механизм индексирования перепроверить все выданные TID-ы по таблице.
Интересно, что бывают стратегии (например, «содержится в массиве»), которые вообще ничего не могут проверить и вынуждены перепроверять по таблице все найденные TID-ы.
А как быть, если нам нужно узнать рейсы, отправляющиеся по вторникам, четвергам и воскресеньям из Москвы? Дополнительное условие не будет поддержано индексом и попадет в графу Filter:
demo=# explain (costs off)
select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Москва';
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: (days_of_week = '{2,4,7}'::integer[])
Filter: (departure_city = 'Москва'::text)
-> Bitmap Index Scan on routes_t_days_of_week_idx
Index Cond: (days_of_week = '{2,4,7}'::integer[])
(5 rows)
В данном случае это не страшно (индекс и так отбирает всего 6 строк), но в случаях, когда дополнительное условие увеличивает селективность, хотелось бы иметь такую возможность. Правда, просто так создать индекс не получится:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin"
HINT: You must specify an operator class for the index or define a default operator class for the data type.
Зато поможет расширение btree_gin, добавляющее классы операторов GIN, имитирующие работу обычного B-дерева.
demo=# create extension btree_gin;
CREATE EXTENSION
demo=# create index on routes_t using gin(days_of_week,departure_city);
CREATE INDEX
demo=# explain (costs off)
select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Москва';
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: ((days_of_week = '{2,4,7}':: integer[]) AND
(departure_city = 'Москва':: text))
→ Bitmap Index Scan on routes_t_days_of_week_departure_city_idx
Index Cond: ((days_of_week = '{2,4,7}':: integer[]) AND
(departure_city = 'Москва':: text))
(4 rows)
JSONB
Еще один пример сложносоставного типа данных, для которого есть встроенная GIN-поддержка — JSON. Для работы со значениями JSON в настоящее время определен ряд операторов и функций, часть из которых может быть ускорена с помощью индексов:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname in ('jsonb_ops','jsonb_path_ops')
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str
----------------+------------------+-----
jsonb_ops | ?(jsonb,text) | 9 существует ключ верхнего уровня
jsonb_ops | ?|(jsonb,text[]) | 10 существует какой-нибудь ключ верхнего уровня
jsonb_ops | ?&(jsonb,text[]) | 11 существуют все ключи верхнего уровня
jsonb_ops | @>(jsonb,jsonb) | 7 JSON-значение содержится на верхнем уровне
jsonb_path_ops | @>(jsonb,jsonb) | 7
(5 rows)
Существует, как видно, два класса операторов: jsonb_ops и jsonb_path_ops.
Первый класс операторов, jsonb_ops, используется по умолчанию. В индекс в качестве элементов исходного JSON-документа попадают все ключи, значения и элементы массивов. К каждому из них добавляется признак, является ли данный элемент ключом (это необходимо для стратегий «существует», которые различают ключи и значения).
Например, представим несколько строк из routes в виде JSON таким образом:
demo=# create table routes_jsonb as
select to_jsonb(t) route
from (
select departure_airport_name, arrival_airport_name, days_of_week
from routes
order by flight_no limit 4
) t;
SELECT 4
demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty
-------+-----------------------------------------------
(0,1) | { +
| "days_of_week": [ +
| 1 +
| ], +
| "arrival_airport_name": "Сургут", +
| "departure_airport_name": "Усть-Илимск" +
| }
(0,2) | { +
| "days_of_week": [ +
| 2 +
| ], +
| "arrival_airport_name": "Усть-Илимск", +
| "departure_airport_name": "Сургут" +
| }
(0,3) | { +
| "days_of_week": [ +
| 1, +
| 4 +
| ], +
| "arrival_airport_name": "Сочи", +
| "departure_airport_name": "Иваново-Южный"+
| }
(0,4) | { +
| "days_of_week": [ +
| 2, +
| 5 +
| ], +
| "arrival_airport_name": "Иваново-Южный", +
| "departure_airport_name": "Сочи" +
| }
(4 rows)
demo=# create index on routes_jsonb using gin (route);
CREATE INDEX
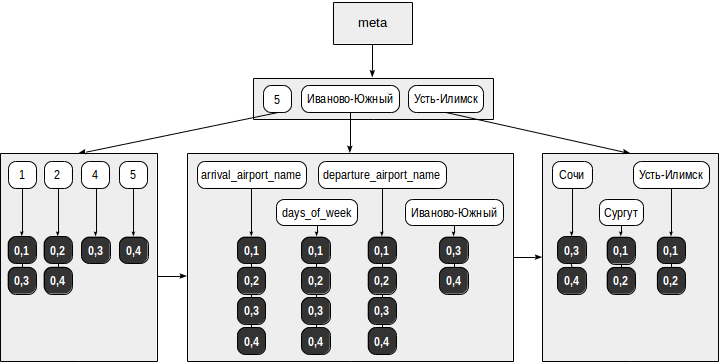
Индекс может иметь такой вид:
Теперь, например, такой запрос может быть выполнен с помощью индекса:
demo=# explain (costs off)
select jsonb_pretty(route)
from routes_jsonb
where route @> '{"days_of_week": [5]}';
QUERY PLAN
---------------------------------------------------------------
Bitmap Heap Scan on routes_jsonb
Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb)
-> Bitmap Index Scan on routes_jsonb_route_idx
Index Cond: (route @> '{"days_of_week": [5]}'::jsonb)
(4 rows)
Оператор @> проверяет, присутствует ли указанный путь ("days_of_week": [5]), начиная от корня JSON-документа. В нашем случае запрос вернет одну строку:
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty
----------------------------------------------
{ +
"days_of_week": [ +
2, +
5 +
], +
"arrival_airport_name": "Иваново-Южный",+
"departure_airport_name": "Сочи" +
}
(1 row)
Выполняется запрос следующим образом:
- Из поискового запроса (
"days_of_week": [5]) выделяются элементы (ключи поиска): «days_of_week» и »5». - В дереве элементов находятся выделенные ключи и для каждого из них выбирается список TID-ов: для »5» — (0,4) и для «days_of_week» — (0,1), (0,2), (0,3), (0,4).
- Из всех найденных TID-ов функция согласованности выбирает те, что подходят под оператор из запроса. Для оператора
@>точно не годятся документы, которые содержат не все элементы из поискового запроса, так что остается только (0,4). Но и оставшийся TID необходимо перепроверить по таблице, потому что по индексу непонятно, в каком порядке в JSON-документе встречаются найденные элементы.
Подробнее про другие операторы можно почитать в документации.
Помимо штатных операций для работы с JSON, уже давольно давно существует расширение jsquery, определяющее язык запросов с более богатыми возможностями (и, разумеется, с поддержкой GIN-индексов). А в 2016 году вышел новый стандарт SQL, который определяет свой набор операций и язык запросов SQL/JSON path. Реализация этого стандарта уже выполнена и мы надеемся на ее появление в PostgreSQL 11.
Внутри
Заглянуть внутрь индекса GIN можно с помощью расширения pageinspect.
fts=# create extension pageinspect;
CREATE EXTENSION
Информация из метастраницы показывает общую статистику:
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+-----------
pending_head | 4294967295
pending_tail | 4294967295
tail_free_size | 0
n_pending_pages | 0
n_pending_tuples | 0
n_total_pages | 22968
n_entry_pages | 13751
n_data_pages | 9216
n_entries | 1423598
version | 2
Структура страницы предусматривает специальную область, «непрозрачную» (opaque) для обычных программ вроде очистки (vacuum), в которой методы доступа могут сохранять свою информацию. Эти данные для GIN показывает функция gin_page_opaque_info. Например, можно узнать состав страниц индекса:
fts=# select flags, count(*)
from generate_series(1,22967) as g(id), -- n_total_pages
gin_page_opaque_info(get_raw_page('mail_messages_tsv_idx',g.id))
group by flags;
flags | count
------------------------+-------
{meta} | 1 метастраница
{} | 133 внутренняя страница B-дерева элементов
{leaf} | 13618 листовая страница B-дерева элементов
{data} | 1497 внутренняя страница B-дерева TID-ов
{data,leaf,compressed} | 7719 листовая страница B-дерева TID-ов
(5 rows)
Функция gin_leafpage_items выдает информацию о TID-ах, хранящихся в страницах {data, leaf, compressed}:
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]---------------------------------------------------------------------
first_tid | (239,44)
nbytes | 248
tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",...
-[ RECORD 2 ]---------------------------------------------------------------------
first_tid | (247,40)
nbytes | 248
tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",...
...
Тут можно заметить, что листовые страницы дерева TID-ов на самом деле содержит не отдельные указатели на табличные строки, а небольшие сжатые списки.
Свойства
Посмотрим на свойства метода доступа gin (запросы приводились ранее):
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
gin | can_order | f
gin | can_unique | f
gin | can_multi_col | t
gin | can_exclude | f
Интересно, что GIN поддерживает создание многоколоночных индексов. При этом, в отличие от обычного B-дерева, в нем будут храниться не составные ключи, а по-прежнему отдельные элементы, но только с указанием номера столбца.
Свойства индекса:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | f
bitmap_scan | t
backward_scan | f
Обратите внимание на то, что выдача результатов по одному (index scan) не поддерживается, возможно только построение битовой карты (bitmap scan).
Сканирование в обратную сторону (backward scan) не поддерживается: эта возможность актуальна только для индексного сканирования, но не для сканирования по битовой карте.
И свойства уровня столбца:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | f
Тут ничего не доступно: ни сортировка (что понятно), ни использование индекса в качестве покрывающего (сам документ не хранится в индексе), ни работа с неопределенными значениями (не имеет смысла для элементов сложносоставного типа).
Другие типы данных
Вот еще еще несколько расширений, добавляющих поддержку GIN для некоторых типов данных.
- pg_trgm позволяет определять «похожесть» слов, сравнивая количество совпадающих последовательностей из трех букв (триграмм). Добавляются два класса операторов, gist_trgm_ops и gin_trgm_ops, поддерживающих разные операторы, в том числе сравнение с помощью LIKE и регулярных выражений. Это расширение можно использовать вместе с полнотекстовым поиском для того, чтобы предлагать варианты слов при опечатках.
- hstore реализует хранилище «ключ-значение». Для этого типа данных существуют классы операторов для разных методов доступа, в том числе и для GIN. Хотя, с появлением типа данных jsonb, использовать hstore уже нет особых причин.
- intarray расширяет функциональность целочисленных массивов. Индексная поддержка включает как GiST, так и GIN (класс операторов gin__int_ops).
И два расширения уже упоминались в тексте:
- btree_gin добавляет GIN-поддержку для обычных типов данных, чтобы использовать их в многоколоночном индексе вместе со сложносоставными типами.
- jsquery определяет язык запросов к JSON и класс операторов для его индексной поддержки. Это расширение не входит в стандартную поставку PostgreSQL.
Продолжение следует.
