Git scraping: методика бесплатного хостинга не совсем статических сайтов
Ни для кого не секрет, что, используя GitHub Pages, вы можете бесплатно разместить свой статический веб-сайт в сети Интернет. 1 Гбайт доступного пространства, SSL-сертификат, возможность привязать собственный домен — разве не сказка? Но что делать, если вам необходимо, чтобы содержимое вашего статического ресурса периодически обновлялось? Допустим, несколько раз в час.
Пути решения уже существуют, и в этой статье я расскажу об одном из них. Вооружившись GitHub Actions в качестве среды выполнения и отдельной веткой Git-репозитория в качестве хранилища, мы организуем автоматизированный пайплайн получения, обработки и отображения малых неконфиденциальных данных, который будет ежемесячно нам обходиться в целых 0 рублей.
Давайте сразу расставим все точки над i: данная статья не будет повествовать о no-code решениях и визуальном программировании. Для реализации подобного пайплайна вам необходимо владеть хотя бы одним языком, имеющим инструменты для генерации статических страниц. Python, Java, JavaScript, C#, Go, Ruby — нет особой разницы, что вы используете. Мне по душе Python и Rust, поэтому я буду приводить примеры на этих двух языках.
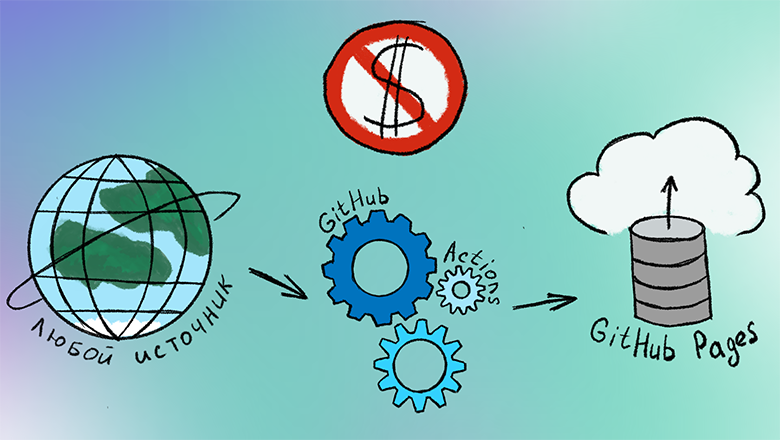 Процесс, который мы построим
Процесс, который мы построим
Также я не буду углубляться в парсинг и преобразование данных, потому что эта часть кода сильно зависит от вашей прикладной задачи, и разбор этих методов выходит за рамки моей статьи. Я буду отмечать подобные места в коде, как «not implemented». Приступим!
Git scraping как часть ETL
Вы наверняка слышали об ETL — это один из основополагающих процессов работы с данными. Аббревиатура расшифровывается как extract, transform, load — извлечение, преобразование и загрузка. Сначала мы откуда-то берём данные, затем обрабатываем, изменяя их форму, и после этого помещаем результат в определённое место.
Британский программист Саймон Виллисон, известный нам по Django Framework, в 2020 году предложил в качестве того-самого конечного определённого места использовать Git-репозиторий. Эту технику Саймон назвал Git scraping. В своей статье разработчик показывает, как можно использовать данную методику для периодического отслеживания изменений интересующих вас данных. По сути, это только «extract» и «load» из вышеупомянутой аббревиатуры.
Здесь же мы продвинемся немного дальше: добавим заготовку под «transform», а также позаботимся о том, чтобы наши данные было удобно просматривать конечному пользователю, то есть применим генерацию статических веб-страниц. Конечно же, сайт не будет полностью статичен, его содержимое будет меняться по расписанию, которое укажете вы. Никто не говорит о realtime, но несколько раз в час — без проблем.
 Виновники торжества
Виновники торжества
Заранее стоит обговорить ограничения GitHub Actions и GitHub Pages (актуальные на февраль 2023):
Время работы GitHub Actions ограничено для приватных репозиториев: не более 2000 минут в месяц, то есть ваш код может расходовать не более 33 часов в месяц на процессы генерации контента, если он не размещён публично
Также джобам, запущенным из приватных репо, доступно только 500 Мбайт свободного места в среде выполнения
GitHub Pages не следует использовать для онлайн-бизнеса, электронной коммерции и SaaS
Финальный размер сгенерированного веб-сайта не должен превышать 1 Гбайт
Трафик посещения веб-сайта также не должен превышать 100 Гбайт в месяц
Ещё в документации присутствует пункт об ограничении количества сборок веб-сайта на GitHub Pages: не более 10 в час, но это относится только к сборкам, проводимым после коммитов, сделанных вручную
Стоит отметить, что вы с лёгкостью можете спрятать все ваши секретные переменные в Action secrets: логины, пароли, токены, URL. Эта информация не будет видна даже в публичном репозитории. То есть вам не обязательно помещать код, генерирующий ваш контент, в приватный репо: все секретные данные можно получать из переменных окружения GitHub Actions. Используя этот способ, при желании можно избавиться от первых двух ограничений, указанных выше.
С ограничениями и сферой применения разобрались, идём дальше. Не будем витать в облаках: попробуем сразу применить эту технику в приложении, которое сможет принести реальную пользу людям.
Кейс
В предыдущей статье я рассказал, что внушительную часть жизни посвятил электронной музыке. Поэтому у меня иногда появляется желание сделать что-нибудь полезное для людей, связанных со звуком. Придумывая идею для очередного пет-проекта, я просто оглядываюсь назад на свою былую рутину музыканта, стараясь найти проблемы, которые было бы возможно решить путём автоматизации.
Подробное описание проблемы
Одна из таких проблем: правильный выбор скорости (BPM) и тональности (Key) для новой композиции. Этот вопрос каждый раз встаёт перед артистом при создании нового проекта в FL Studio или Cubase. Для электронной танцевальной музыки неверный выбор этих значений может вылиться даже в сложности с попаданием работы на лейбл или в микс. Подробнее об этом я рассказал здесь.
С первого взгляда кажется, что это должно решаться классическим «загугливанием»: просто введи в поиск «tech house bpm» и получи результат, но это не совсем так. Значения скоростей и тональностей являются трендами. А тренды имеют свойство меняться. Поисковая выдача довольно часто может становиться неактуальной в этом случае.
В своё время я нашёл такой способ решения этой проблемы:
Найти список свежих наилучших треков жанра, в котором я работаю. Для меня авторитетным всегда был чарт Beatport Top 100
Получить значения скоростей и тональностей для каждой композиции чарта. Такие ресурсы, как Beatport и Spotify, предоставляют подобную информацию бесплатно
Подсчитав полученные значения, составить отчёт, который бы показывал список скоростей и тональностей, отсортированный по популярности
Выбрать одно из топовых значений для своей следующей композиции
Именно эту последовательность действий я и собираюсь автоматизировать в данной статье, но не для одного, а для всех жанров, представленных на Beatport.
Итак, делаем анализатор чартов Beatport Top 100.
На входе: более 30 веб-страниц со списками топ-100 новых композиций для каждого представленного жанра электронной танцевальной музыки.
На выходе: ежедневно обновляемая статистика по наиболее часто используемым значениям скоростей (BPM) и тональностей (Key), оформленная в виде веб-сайта на GitHub Pages.
 Незамысловатая схема процесса
Незамысловатая схема процесса
На самом деле, выбор кейса не так важен, главное здесь — понять принцип: вы можете на регулярной основе автоматически брать данные из любых источников, обрабатывать их и отображать результат, используя бесплатные возможности GitHub Actions и GitHub Pages.
Указанный здесь код было бы нетрудно доработать под вашу конкретную задачу, не связанную с Beatport. При желании отредактируйте источники данных, порядок действий, модель выходных данных или HTML-шаблоны. Главное, чтобы для выполнения вашего кода хватало ресурсов окружения, а на выходе генерировался статический веб-сайт. Хотя последнее также необязательно: вы вправе, например, загружать результат обработки в Telegram в виде обычного текста, или отправлять JSON во внешний REST API. В таком случае можно было бы отказаться от загрузки данных в GitHub Pages. Но в моём примере результатом ETL-процесса будет именно регулярно обновляемый веб-сайт.
Подготовка
Первым делом создадим репозиторий на GitHub. Я сделаю его публичным.
Также я инициализирую репо с README.md и .gitignore для моего языка. Я буду приводить примеры на Python и Rust. Примеры на двух языках будут равнозначны, можно выбирать любой.
Клонируем репозиторий локально: для подобных задач мне нравится использовать GitHub Desktop. Этот клиент имеет довольно удобный интерфейс и позволяет сфокусироваться на разработке, давая возможность не тратить время на повторяющиеся команды git.

Мы не собираемся хранить сгенерированные веб-страницы в главной ветке репозитория, поэтому отредактируем файл .gitignore, добавив папку build.
...
# Сгенерированный контент
/build/Теперь подготовим окружение для разработки. Откроем терминал. Я пользуюсь Windows, на других ОС команды могут немного отличаться. Находясь в папке с проектом, выполним несколько действий.
Python: подготовка
Создадим новое виртуальное окружение:
python -m venv venvАктивируем его:
venv\Scripts\activateДобавим зависимости, создав requirements.txt:
# Асинхронные HTTP-запросы
aiohttp>=3
# Генерация статических веб-страниц
Jinja2>=3Загрузим зависимости:
python -m pip install -r requirements.txtRust: подготовка
Инициализируем наш пакет в Cargo:
cargo initДобавим зависимости, отредактировав Cargo.toml:
...
[dependencies]
# Среда выполнения асинхронного кода
tokio = { version = "1", features = ["full"] }
# Асинхронные HTTP-запросы
reqwest = { version = "0.11", features = ["json"] }
# Генерация статических веб-страниц
tera = "1"
# Сериализация
serde = { version = "1", features = ["derive"] }
# Обработка ошибок
anyhow = "1"Загрузим зависимости и убедимся, что подготовка пройдена успешно:
cargo runПлан
Используем нисходящий подход к разработке. Сначала опишем высокоуровневые шаги нашей программы и только после этого приступим к реализации отдельных компонентов. Я буду давать им названия, которые будут указывать на их роль в ETL-процессе:
К модулю Extract будут относиться функции извлечения данных из внешних источников. Так как в моём кейсе требуется получать немалое количество страниц, я буду пользоваться асинхронным программированием, чтобы извлекать данные конкурентно
Модуль Transform будет отвечать за парсинг и преобразование данных. Как я указал выше, здесь я оставлю только заготовку под ваш будущий код без конкретной реализации
Функции Load будут отвечать за загрузку данных. В данном контексте это будет означать создание статических билдов веб-сайта, которые будут коммититься в отдельную ветку репо посредством GitHub Actions, а после этого будут размещаться на GitHub Pages
Также я подготовлю компонент Model, в котором будет находиться модель выходных данных
Python: высокоуровневые шаги — main.py
import asyncio
from typing import List
import extract
import load
import model
import transform
BEATPORT_URL = "https://www.beatport.com"
async def main():
# Получаем главную страницу Beatport
main_page: str = await extract.page(BEATPORT_URL)
# Достаём из неё ссылки на Top 100 страницы для каждого жанра
genre_top_100_urls: List[str] = transform.main_page_to_genre_top_100_urls(main_page)
# Конкурентно получаем содержимое Top 100 страниц для каждого жанра
genre_top_100_pages: List[str] = await extract.multiple_pages(genre_top_100_urls)
# Анализируем Top 100 страницы, составляя отчёты для каждого музыкального жанра
genre_reports: List[model.Report] = transform.genre_top_100_pages_to_reports(
genre_top_100_pages
)
# Отображаем наши отчёты в виде статической веб-страницы
load.build(genre_reports)
if __name__ == "__main__":
asyncio.run(main())Rust: высокоуровневые шаги — src/main.rs
mod extract;
mod load;
mod model;
mod transform;
use anyhow::Result;
const BEATPORT_URL: &str = "https://www.beatport.com";
#[tokio::main]
async fn main() -> Result<()> {
// Получаем главную страницу Beatport
let main_page: String = extract::page(BEATPORT_URL).await?;
// Достаём из неё ссылки на Top 100 страницы для каждого жанра
let genre_top_100_urls: Vec<&str> = transform::main_page_to_genre_top_100_urls(&main_page)?;
// Конкурентно получаем содержимое Top 100 страниц для каждого жанра
let genre_top_100_pages: Vec = extract::multiple_pages(&genre_top_100_urls).await?;
// Анализируем Top 100 страницы, составляя отчёты для каждого музыкального жанра
let genre_reports: model::ReportVec =
transform::genre_top_100_pages_to_reports(&genre_top_100_pages)?;
// Отображаем наши отчёты в виде статической веб-страницы
load::build(genre_reports).await
} Далее — модель данных. Её стоит описать заранее, потому что от неё будут зависеть конкретные реализации остальных компонентов. В полноценном решении у вас может быть несколько промежуточных моделей для каждого из подэтапов преобразования, но, так как в этой статье мы опустим реализацию Transform, в нашем случае будет одна-единственная модель — для выходных данных. Она будет описывать тот объект, который будет передаваться в генератор статических веб-страниц.
Python: модель данных — model.py
from dataclasses import dataclass
from typing import List, Tuple
# Аналитика по музыкальному жанру
@dataclass
class Report:
# Название музыкального жанра
genre: str
# Наиболее популярные значения скоростей (BPM): (количество, значение)
bpm_chart: List[Tuple[int, int]]
# Наиболее популярные значения тональностей (Key): (количество, значение)
# Вместо str следует использовать Enum, но это бы усложнило пример
key_chart: List[Tuple[int, str]]Rust: модель данных — src/model.rs
use serde::Serialize;
// Аналитика по музыкальному жанру
#[derive(Serialize)]
pub struct Report {
// Название музыкального жанра
pub genre: String,
// Наиболее популярные значения скоростей (BPM): (количество, значение)
pub bpm_chart: Vec<(usize, u16)>,
// Наиболее популярные значения тональностей (Key): (количество, значение)
// Вместо String следует использовать Enum, но это бы усложнило пример
pub key_chart: Vec<(usize, String)>,
}
// Tera будет выдавать ошибку, если мы не обернём вектор отчетов
#[derive(Serialize)]
pub struct ReportVec {
pub reports: Vec,
} С основными этапами программы и моделью разобрались, следуем дальше. От модуля к модулю.
Извлечение
Существует великое множество источников данных: файлы, веб-страницы, БД, различные API и так далее. Для работы с некоторыми из них имеются удобные библиотеки, которые полностью освобождают нас, разработчиков, от всей боли десериализации байт, парсинга строк и прочего. Думаю, никто не станет спорить, что, например, для работы с тем же Telegram проще пользоваться такими готовыми библиотеками, как aiogram на Python или teloxide на Rust.
Но не везде всё так гладко: многие источники данных лишены подобных удобных «батареек», и без своего «велосипеда» не обойтись. Ситуация усугубляется тем, что не каждый владелец публично доступных данных одобряет автоматизированную работу с ними. Например, ранее, когда на Авито ещё публиковались телефонные номера продавцов, они должны были быть легко доступны только рядовым покупателям, но не злостным ботам-скрейперам.
Взглянем на источник данных нашего кейса — платформу Beatport.
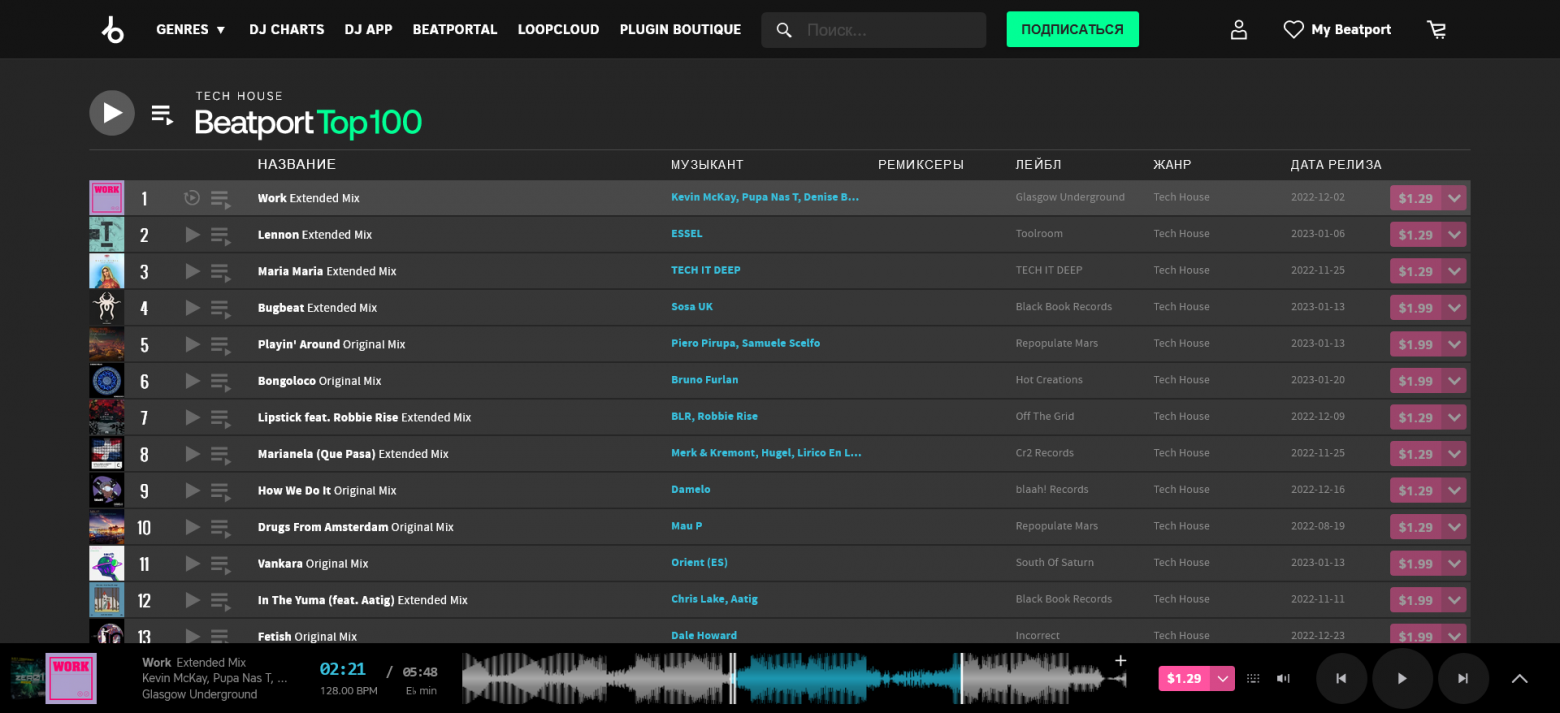 Чарт Beatport Top 100 для одного из 32 представленных жанров
Чарт Beatport Top 100 для одного из 32 представленных жанров
В нашем приложении мы бы хотели оперировать данными, доступными на подобных страницах сервиса. Да, у платформы есть API, но получить к нему доступ мне так и не удалось.
 Попытка сделать Request API Access на Beatport
Попытка сделать Request API Access на Beatport
Можно было бы направить тикет в их Help Desk с просьбой предоставить доступ к API, но, скажу по опыту, ответ в данном случае может не прийти. В 2018 году я столкнулся с похожей проблемой Beatport API, и в тот момент заветные CLIENT_ID и CLIENT_SECRET мне получить так и не удалось. Ну что же, не будем надеяться на других, пойдём в лоб.
Именно в данном случае можно без проблем использовать веб-скрейпинг, то есть просто скачивать веб-страницы с необходимым содержимым и доставать заветные данные из них, используя методы HTML-парсинга. Beatport не вносит никаких технических ограничений на этот счёт. Конечно, наш Transform стал бы сложнее из-за этого, но, как мы уже договорились ранее, мы не будем сосредотачиваться на методах преобразования в этой статье.
Итак, извлекаем HTML-код интересующих нас страниц.
Python: извлечение — extract.py
import asyncio
from typing import List, Optional
import aiohttp
async def page(url: str) -> Optional[str]:
# Для повторяющихся запросов рекомендуется переиспользовать одну сессию aiohttp.ClientSession
# Подробнее: https://docs.aiohttp.org/en/stable/client_quickstart.html
# Но это бы усложнило пример
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
return await resp.text()
# Чтобы понять, что здесь происходит, вы можете ознакомиться с документацией asyncio:
# https://docs.python.org/3/library/asyncio.html
async def multiple_pages(urls: List[str]) -> Optional[List[str]]:
# Конкурентно вызываем page() для каждой входящей ссылки
handles = list(map(lambda x: asyncio.create_task(page(x)), urls))
pages = []
# Получаем результаты в список
for handle in handles:
pages.append(await handle)
return pagesRust: извлечение — src/extract.rs
 Веб-скрейпинг на Rust наглядно
Веб-скрейпинг на Rust наглядноuse anyhow::Result;
pub async fn page(url: &str) -> Result {
// Для повторяющихся запросов рекомендуется переиспользовать один клиент reqwest::Client
// Подробнее: https://docs.rs/reqwest/latest/reqwest/
// Конкурентный GET можно было бы реализовать через Client.clone(), но это бы усложнило пример
// https://users.rust-lang.org/t/reqwest-http-client-fails-when-too-much-concurrency/55644
let response = reqwest::get(url).await?.text().await?;
Ok(response)
}
// Чтобы понять, что здесь происходит, вы можете ознакомиться с Tokio Tutorial:
// https://tokio.rs/tokio/tutorial
pub async fn multiple_pages(urls: &[&str]) -> Result> {
// Конкурентно вызываем page() для каждой входящей ссылки
let handles: Vec<_> = urls
.iter()
// Передача данных в асинхронные треды требует владения
// Это может быть решено использованием крейта async-scoped, но это выходит за рамки статьи
.map(|url| url.to_string())
.map(|url| tokio::spawn(async move { page(&url).await }))
.collect();
let mut pages = Vec::with_capacity(handles.len());
// Получаем результаты в вектор
for handle in handles {
pages.push(handle.await??);
}
Ok(pages)
} Преобразование
Все существующие варианты преобразования данных также вряд ли удастся сосчитать. Здесь мы ограничены лишь возможностями языка, ресурсами окружения и собственным воображением. Маппинг, фильтрация, агрегация — лишь верхушка айсберга.
Я намеренно оставляю данную часть примера нереализованной, так как эта логика будет сильно зависеть от вашей прикладной задачи. Зачем углубляться в HTML-парсинг, если вы, например, будете получать данные напрямую через REST API или ODBC? Зачем подробно описывать анализ музыкальных характеристик, если в вашем кейсе будут совсем другие сущности?
Поэтому в данном коде я оставляю эти заготовки нереализованными, в качестве интерфейса. Принцип инверсии зависимостей: в этом примере нам не важно, как именно функция достаёт URL отдельных страниц из HTML-кода страницы или проводит аналитику музыкального жанра по распарсенному содержимому.
Python: заготовка под преобразование — transform.py
from typing import List, Optional
import model
# В данном модуле будет находиться код, специфичный для вашего приложения
def main_page_to_genre_top_100_urls(_page: str) -> Optional[List[str]]:
raise NotImplementedError
def genre_top_100_pages_to_reports(_pages: List[str]) -> Optional[List[model.Report]]:
raise NotImplementedErrorRust: заготовка под преобразование — src/transform.rs
use crate::model;
use anyhow::Result;
// В данном модуле будет находиться код, специфичный для вашего приложения
// Для подобных конверсий в Rust следует реализовывать трейты From, TryFrom, FromStr,
// Но это бы сильно усложнило пример в данном случае
pub fn main_page_to_genre_top_100_urls(_page: &str) -> Result> {
unimplemented!()
}
// Подробнее про тип аргумента _pages можно почитать здесь:
// https://stackoverflow.com/a/41180422/12510636
pub fn genre_top_100_pages_to_reports(_pages: &[impl AsRef]) -> Result> {
unimplemented!()
} Подробнее про HTML-парсинг
Если вам всё же интересна тема HTML-парсинга, советую изучить эти библиотеки:
Для работы с подобными инструментами вам потребуются знания CSS-селекторов. Хороший материал по этой теме на русском языке доступен здесь.
Простыми словами, в CSS-файлах селекторы используются для стилизации документа, а в парсинге — для выборки данных из HTML-разметки. Например, если нужные вам данные хранятся в первом элементе с тегом Если вам интересно узнать, как реализован парсинг именно в моём кейсе анализа Beatport, то вы можете ознакомиться с полноценным решением на Rust. В предыдущих этапах мы извлекли все необходимые нам данные и преобразовали их к той форме, в которой они могут быть переданы в шаблонизатор — библиотеку, которая будет периодически генерировать наш не совсем статический веб-сайт. Кто-то может возразить, сказав, что генерация HTML-страниц также относится к этапу преобразования данных, и будет прав. Но мне удобнее ограничивать «transform» собственной программной логикой. Своеобразный mindset shift: всё, что ушло в шаблонизатор, уже относится к «load». Да и, как по мне, структура приложения при таком разграничении становится более естественной. Создадим наш первый и единственный шаблон Шаблон — templates/index.html Теперь взглянем на код, который будет передавать нашу финальную структуру данных в шаблонизатор, а также сохранять результат в файл. Python: генерация веб-страницы — load.py Rust: генерация веб-страницы — src/load.rs Результатом выполнения скрипта станет папка Всё, что остаётся, это «доставить» нашу сборку до пользователей, воспользовавшись средствами GitHub. Где же будет выполняться наш код? Где будет генерироваться наш Как я уже указал выше, вам следует учитывать ограничения GitHub Actions, если вы используете их в приватных репозиториях. Но есть еще один момент, про который стоит упомянуть — минуты ОС имеют разную стоимость: Linux — бесплатно 2000 минут (33 часа 20 минут) в месяц Windows — множитель x2 — бесплатно 1000 минут (16 часов 40 минут) в месяц macOS — множитель х10 (!!!) — бесплатно 200 минут (3 часа 20 минут) в месяц Но, повторюсь, эти ограничения не относятся ко времени доступности вашего веб-сайта, он будет доступен постоянно. Данные значения влияют только на время, доступное вашему коду на генерацию содержимого. И, опять же, только в приватных репозиториях. Теперь давайте определимся, какие шаги должен регулярно выполнять наш «раннер»: Загрузить код репозитория в окружение Установить средства языка для компиляции / интерпретации кода Подтянуть необходимые библиотеки и зависимости (По желанию) проверить код линтером и прогнать тесты Исполнить код нашего приложения, получив на выходе папку Запушить билд в отдельную ветку текущего или стороннего репозитория Эти действия должны быть декларативно описаны в YAML-файле, который будет помещён в каталог Внутри каждого рабочего процесса вы также можете задавать произвольное количество заданий (jobs), каждое из которых обычно выполняется параллельно на отдельных виртуальных машинах. В нашем примере будет один файл рабочего процесса с одним заданием. Задания, в свою очередь, состоят из шагов (steps). Шагами могут быть классические команды терминала, а также действия (actions), то есть часто используемые операции, которые были размещены на GitHub Marketplace. Проще всего думать о действиях как об удобных внешних функциях, которые мы можем вызывать из нашего YAML-кода. Рабочие процессы для Python и Rust будут отличаться, но некоторые шаги будут оставаться общими: Загрузка кода репозитория (1-й пункт) будет проводиться через официальный actions/checkout А деплой билда в отдельную ветку репо (6-й пункт) — через peaceiris/actions-gh-pages Сначала разрешим нашему будущему рабочему процессу вносить изменения в наш репозиторий. Для этого зайдём на GitHub в Settings > Actions > General > Workflow Permissions и изменим значение на Read and write permissions. Далее создадим папку Python: рабочий процесс — .github/workflows/main.yml Rust: рабочий процесс — .github/workflows/main.yml Сохраняем Если всё было сделано верно, то на GitHub напротив нашего коммита появится оранжевый кружок, который даст сигнал, что рабочий процесс был запущен. Через некоторое время на его месте должна появиться зелёная галочка. Если во время процесса возникнут ошибки, то их можно будет изучить в разделе Actions. Также обратим внимание на новое предупреждение. Оно связано с тем, что в репозитории была создана ветка Жмём Protect this branch, а затем Require a pull request before merging и Create. При желании вы можете изучить правила защиты ветвей здесь. Остаётся сделать последний шаг, после которого ваш веб-сайт станет доступен для всех. Взглянув на список веток репозитория, вы можете убедиться, что рабочий процесс самостоятельно создал ветку Внесём последнее изменение, которое разместит содержимое ветки Подождём пару минут и проверим, что наша страничка стала доступна для всех. Попробуем пройти по этой ссылке: Обратите внимание, что на конце домена стоит Используя этот метод, мы получили веб-сервис, способный обновлять представленную на нём информацию с допустимым заданным интервалом. Да, эту страницу нельзя назвать динамической, но, как по мне, совершенно статической она также не является. Содержимое отображает релевантную информацию, исполняя бизнес-требования. В вышеуказанном кейсе это означает, что EDM продюсеры могут использовать аналитику с этой страницы для обдуманного выбора скорости (BPM) и тональности (Key) своих будущих композиций. Учитывая характер данных, мы смогли немного пренебречь актуальностью. Для музыкантов не так важно основывается ли эта аналитика на данных в реальном времени, или присутствует задержка не более суток. При необходимости мы могли бы уменьшить эту задержку до нескольких минут. Если потребуется, к страничке на GitHub Pages можно привязать свой домен. Подробная инструкция на эту тему находится здесь. Также, если вы не хотите публиковать код генерации сайта, вы можете воспользоваться тем, что peaceiris/actions-gh-pages позволяет размещать сгенерированное содержимое в отдельном репозитории. В таком случае у вас могло бы быть два репозитория: приватный для генерации контента на GitHub Actions, публичный для его отображения на GitHub Pages. Но в случае с приватным репо у вас есть только 33 часа бесплатного времени GitHub Actions в месяц. Решение кейса, описанного в статье, представляет собой stateless-приложение. Но что делать, если у подобного веб-сайта должно быть собственное состояние? Так как в данном случае не требуется транзакционность, можно было бы обойтись хранением стейта в отдельном файле ветки Всё это, конечно, выглядит не так просто, как хотелось бы. Что делать, если всего лишь хочется перенести свой WordPress-блог на бесплатный GitHub Pages? В данном случае я бы посмотрел в сторону Jekyll и Hugo. Но здесь также стоит учитывать ограничение размера сайта на GitHub Pages в 1 Гбайт. Альтернативный способ решения задачи — на клиенте Есть ещё один способ, как можно было бы реализовать подо
mycontent, то получить текстовое содержимое этого элемента можно было бы одной командой Beautiful Soup: soup.select_one("div.mycontent").textЗагрузка
index.html в новой папке templates. Удобство здесь состоит в том, что мы можем переиспользовать одни и те же шаблоны в разных языках программирования. Наш index.html будет понятен как и Jinja на Python, так и Tera на Rust. Также помимо разметки применим здесь один из classless CSS-фреймворков, чтобы наша страничка выглядела хоть немного приятно.
Аналитика {{ report.genre }} Top 100 Tracks :: Beatport
Скорость (BPM)
{% for pair in report.bpm_chart -%}
Позиция
Значение
Количество композиций
{% endfor %}
{{ loop.index }}
{{ pair[1] }}
{{ pair[0] }}
Тональность (Key)
{% for pair in report.key_chart -%}
Позиция
Значение
Количество композиций
{% endfor %}
{{ loop.index }}
{{ pair[1] }}
{{ pair[0] }}
import os
from typing import List
from jinja2 import Environment, FileSystemLoader
import model
TEMPLATE_PATH = "templates"
INDEX_NAME = "index.html"
BUILD_PATH = "build"
# Чтобы понять, что здесь происходит, вы можете ознакомиться с Jinja Documentation:
# https://jinja.palletsprojects.com/
def build(reports: List[model.Report]):
# Создаём папку для билда
os.makedirs(BUILD_PATH, exist_ok=True)
# Инициализируем движок шаблонов Jinja
# Этот этап рекомендуется выполнять только один раз
jinja = Environment(loader=FileSystemLoader(TEMPLATE_PATH))
# Рендерим содержимое
content = jinja.get_template(INDEX_NAME).render(reports=reports)
# Открываем файл на чтение
with open(os.path.join(BUILD_PATH, INDEX_NAME), "w", encoding="utf-8") as f:
# Заполняем файл содержимым
f.write(content)use crate::model;
use anyhow::Result;
use std::path::Path;
use tera::{Context, Tera};
use tokio::fs;
use tokio::io::AsyncWriteExt;
const TEMPLATE_PATH: &str = "templates/**/*.html";
const INDEX_NAME: &str = "index.html";
const BUILD_PATH: &str = "build";
// Чтобы понять, что здесь происходит, вы можете ознакомиться с Tera Documentation:
// https://tera.netlify.app/docs/
pub async fn build(reports: model::ReportVec) -> Result<()> {
// Создаём папку для билда
fs::create_dir_all(BUILD_PATH).await?;
// Инициализируем движок шаблонов Tera
// Этот этап рекомендуется выполнять только один раз
let tera = match Tera::new(TEMPLATE_PATH) {
Ok(t) => t,
Err(e) => {
println!("Parsing error(s): {e}");
::std::process::exit(1);
}
};
// Рендерим содержимое
let content = tera.render(INDEX_NAME, &Context::from_serialize(reports)?)?;
// Определяем путь конечного файла
let index_path = Path::new(BUILD_PATH).join(INDEX_NAME);
// Открываем файл на чтение
let mut file = fs::File::create(index_path).await?;
// Заполняем файл содержимым
file.write_all(content.as_bytes()).await?;
Ok(())
}build с содержимым вашего веб-сайта. В моём кейсе это будет единственный index.html, но ничто не мешает добавлять контент по вашему разумению. Вы вправе генерировать столько HTML-страниц, сколько вам необходимо, а также добавлять соответствующую статику: CSS, JavaScript и тому подобное. И, конечно же, если вы используете Node.js, вы без проблем можете собирать ваш ресурс, используя npm run build.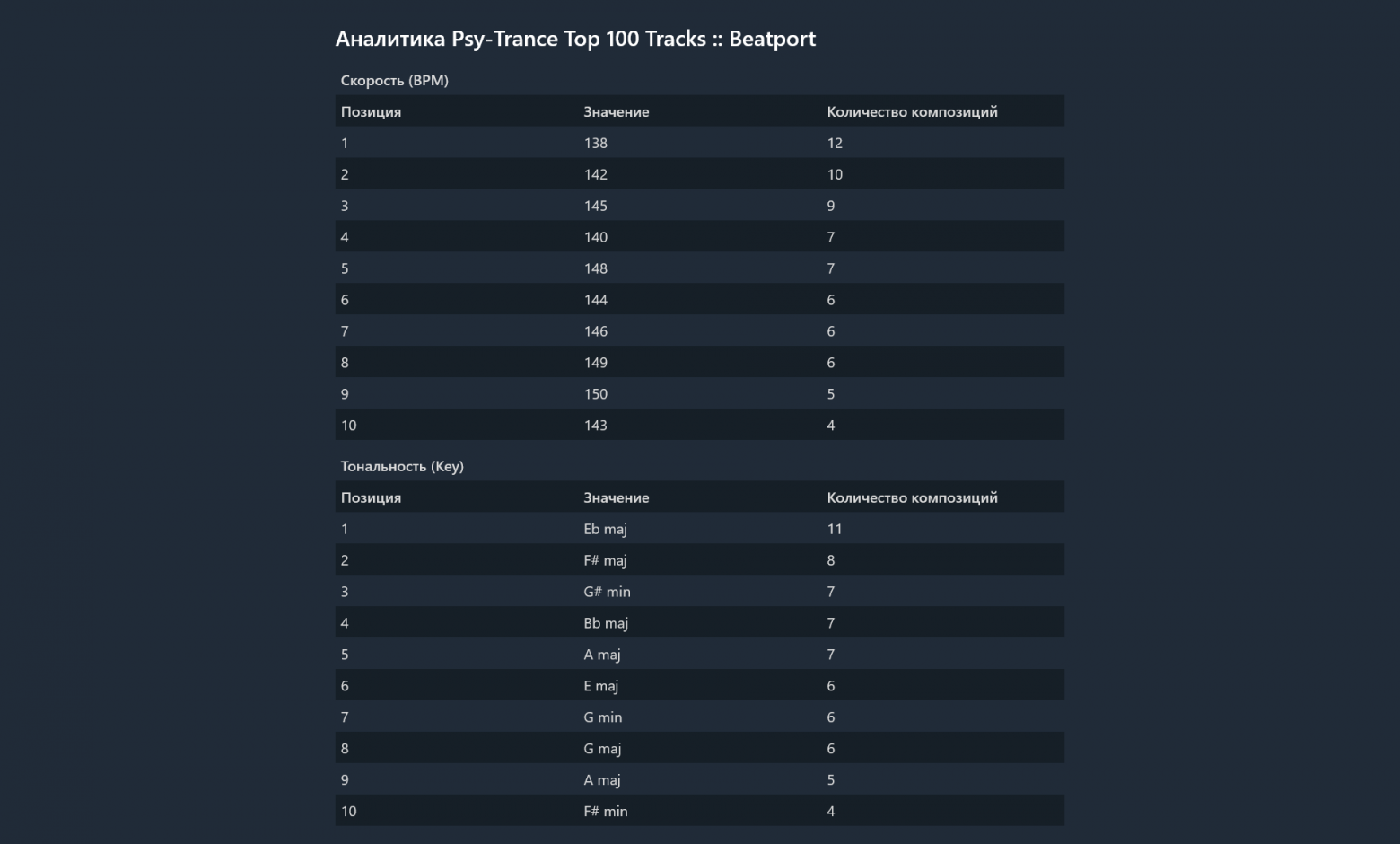 Шаблон, заполненный данными
Шаблон, заполненный даннымиActions
build? В «раннере» GitHub Actions — виртуальной машине, которая будет существовать только на момент сборки веб-сайта. Мы будем использовать «раннер» с Ubuntu Linux, хотя при желании можно использовать и Windows, и macOS.build с актуальным содержимым.github/workflows текущего репозитория. Такие файлы называются рабочими процессами (workflows), и при желании их может быть несколько. Внутри файла рабочего процесса необходимо указать, какие события (events) будут запускать его. Типов событий довольно много, но чаще всего используется обычный git push. Мы также добавим событие schedule, позволяющее запускать процессы по расписанию.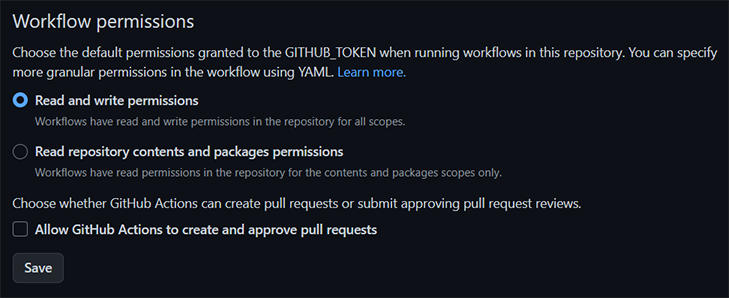
.github/workflows, а в ней файл main.yml. Так как в моём кейсе не требуется частое обновление данных, я укажу, чтобы веб-сайт обновлялся один раз в сутки.# Название рабочего процесса
name: Main Workflow (Python)
# События, запускающие процесс
on:
# Git push в ветку main
push:
branches:
- main
# По расписанию: каждый день в 0:00 UTC
# https://crontab.guru/every-day
schedule:
- cron: '0 0 * * *'
# Задания
jobs:
# Название задания
Main-Job-Python:
# Запускать на последней версии Ubuntu
runs-on: ubuntu-latest
# Шаги
steps:
# Загрузить код репозитория в окружение
- name: Checkout repository
uses: actions/checkout@v3
# Установить Python 3.10
- name: Install Python
uses: actions/setup-python@v4
with:
python-version: '3.10'
# Установить зависимости
- name: Install Dependencies
run: pip install -r requirements.txt
# Запустить нашу программу на Python
# Этот шаг генерирует папку ./build
- name: Run
run: python main.py
# Разместить содержимое ./build в корень ветки gh-pages текущего репо
- name: Deploy
uses: peaceiris/actions-gh-pages@v3
with:
# Передача токена рабочего прицесса во внешнее действие
# Не требует отдельной настройки секретов, токен передаётся автоматически
github_token: ${{ secrets.GITHUB_TOKEN }}
# Выбор папки билда
publish_dir: ./build# Название рабочего процесса
name: Main Workflow (Rust)
# События, запускающие процесс
on:
# Git push в ветку main
push:
branches:
- main
# По расписанию: каждый день в 0:00 UTC
# https://crontab.guru/every-day
schedule:
- cron: '0 0 * * *'
# Задания
jobs:
# Название задания
Main-Job-Rust:
# Запускать на последней версии Ubuntu
runs-on: ubuntu-latest
# Шаги
steps:
# Загрузить код репозитория в окружение
- name: Checkout repository
uses: actions/checkout@v3
# Установить последний стабильный Rust
- name: Install Rust toolchain
uses: dtolnay/rust-toolchain@stable
# Использовать кэш между рабочими процессами при компилировании Rust-библиотек
# ЗНАЧИТЕЛЬНО ускоряет выполнение рабочего процесса в случае с Rust
- name: Rust Cache
uses: Swatinem/rust-cache@v2
# Запустить нашу программу на Rust
# Этот шаг генерирует папку ./build
- name: Run
run: cargo run --release
# Разместить содержимое ./build в корень ветки gh-pages текущего репо
- name: Deploy
uses: peaceiris/actions-gh-pages@v3
with:
# Передача токена рабочего прицесса во внешнее действие
# Не требует отдельной настройки секретов, токен передаётся автоматически
github_token: ${{ secrets.GITHUB_TOKEN }}
# Выбор папки билда
publish_dir: ./buildmain.yml и пробуем сделать коммит.
gh-pages.
Pages
gh-pages и поместил туда сгенерированное содержимое. Начиная с этого момента каждый коммит в main будет обновлять gh-pages. Также ранее мы настроили событие schedule, которое будет ежедневно обновлять gh-pages независимо от коммитов. Снизу появилась новая ветка
Снизу появилась новая веткаgh-pages на бесплатном хостинге GitHub Pages. Проследуем в Settings > Pages. Изменим Branch на gh-pages и нажмём Save.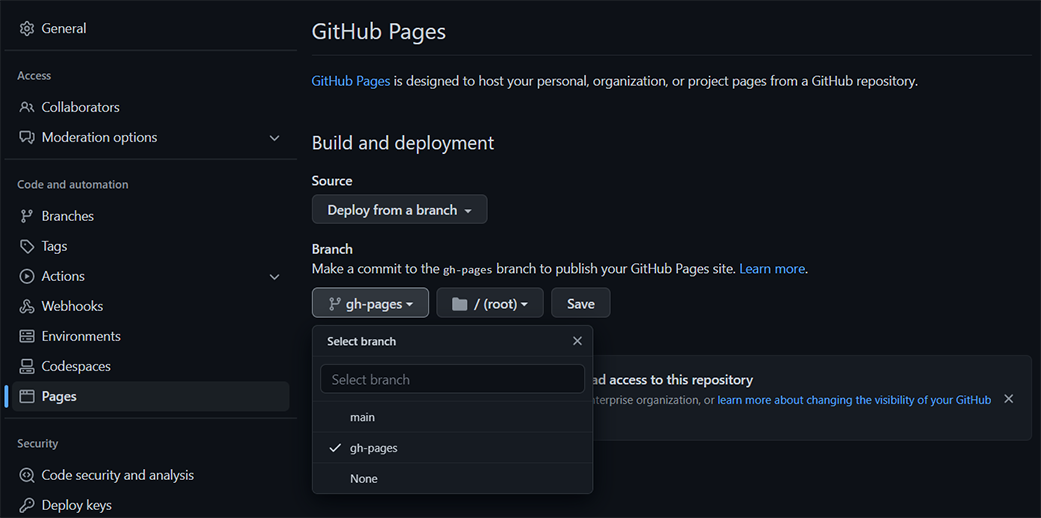
https://ваш_логин.github.io/имя_репозитория/.io, а не .com. В моём случае (после внушительной доработки и полировки решения кейса) ссылка получилась такой: https://sergree.github.io/whatbpm/Итог
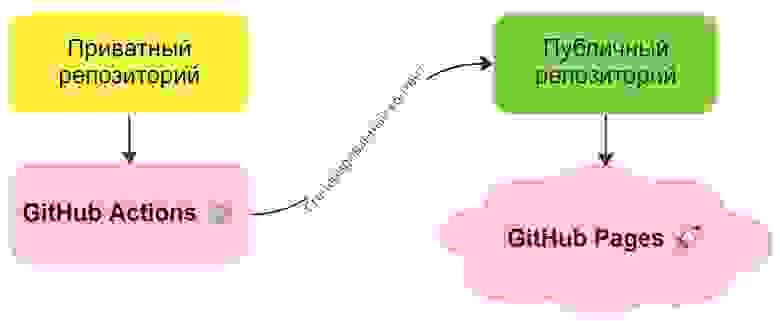 Вариант с приватным репо мог бы выглядеть так
Вариант с приватным репо мог бы выглядеть такgh-pages. Это мог бы быть простой CSV или JSON. Либо вы могли бы воспользоваться бесплатным DBaaS из этого списка. Способ #1 — хранение состояния в Git-репозитории
Способ #1 — хранение состояния в Git-репозитории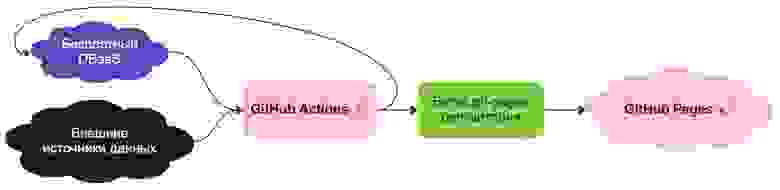 Способ #2 — хранение состояния в DBaaS
Способ #2 — хранение состояния в DBaaS
