Генерация картинок на любом железе без Midjourney
Для генерации изображений сегодня существует множество сервисов. Некоторые из них платные, другие нет. И даже в большинстве бесплатных сервисов вы можете столкнуться с ограничениями, например, на количество бесплатных картинок за единицу времени, разрешение изображений и прочее. Это обстоятельство объясняется просто. Несмотря на доступность технологии, железо, которое требуется для генерации, остается дорогим. И бесплатно отдавать ресурсы GPU мало кому хочется. Однако, тягу к бесплатному трудно победить. Поэтому в этой статье мы узнаем, как, всё же, генерировать изображения только при помощи браузера и нескольких строк кода.
Требования к аппаратной части
Их особо и нет. Необходимо, чтобы на вашем компьютере или планшете был современный браузер. Скорее всего, это уже так. Нужен будет аккаунт в Google для подключения к сервису Google Disk. Этого будет достаточно.
Colab
Нам нужен будет бесплатный GPU. Первым делом идем в Колабу по ссылке https://colab.research.google.com В меню «Файл» создаем блокнот.
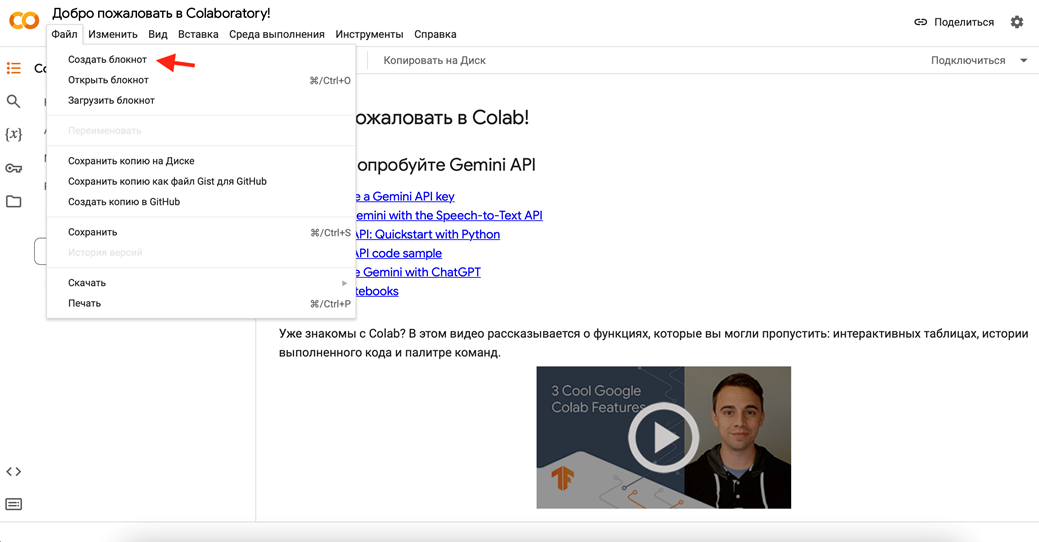
Далее подключаем GPU. Идем в меню «Среда выполнения» и выбираем «Сменить среду выполнения». Выбираем, что доступно, кроме CPU. Скорей всего, T4 GPU будет свободно, нам этого хватит.
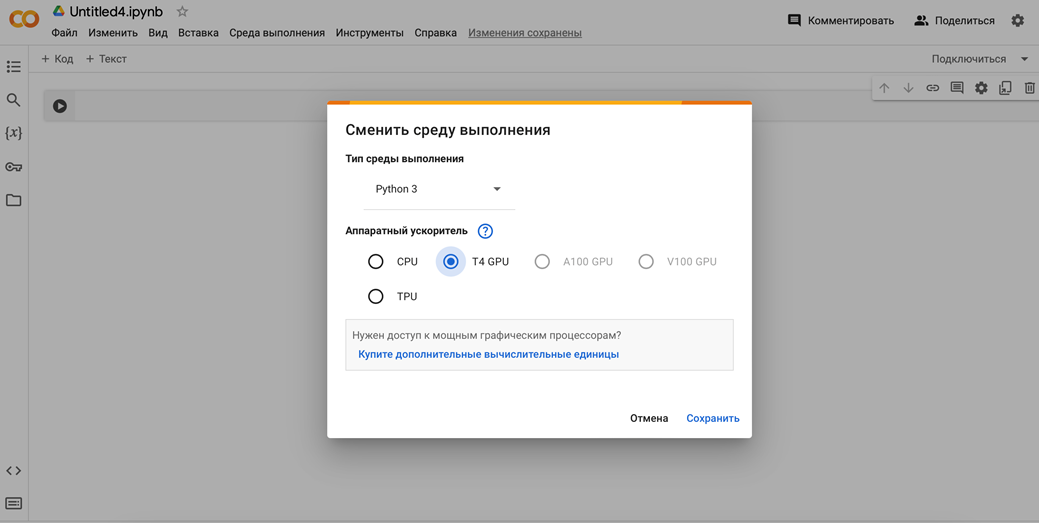
В правом углу блокнота находим «Подключиться» и подключаемся.
Install
В первой ячейке блокнота устанавливаем необходимые зависимости:
!pip -q install git+https://github.com/huggingface/diffusers transformers accelerate -q
Запускаем выполнение кода. Жмем на кнопку запуска слева ячейки с кодом или наводим курсор на код и жмем CTRL+ENTER, или, для маков, СOMMAND+ENTER. Ждем выполнения.
Импорты
В следующую ячейку копируем следующий код:
from diffusers import StableDiffusionXLPipeline
from diffusers.utils import make_image_grid
import torch
Запускаем.
Инициализация
Далее, копируем код в следующую ячейку:
pipe = StableDiffusionXLPipeline.from_pretrained("segmind/SSD-1B", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
Запускаем. Мы будем использовать не самую большую модель. Конечно, модели есть и побольше, чем эта, но у нас ограничения всё же остались. Бесплатно у нас ограничен размер памяти в Колабе. Его можно посмотреть, если ткнуть на место в верхнем правом углу, где написано ОЗУ и Диск.
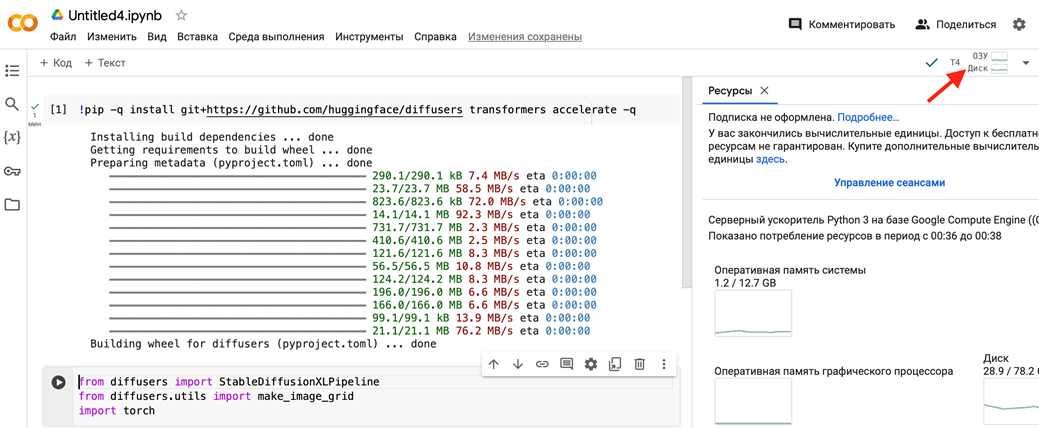
Видим, что нам предоставляют только 15Гб. Но этой модели бесплатной памяти вполне хватит.
Теперь магия!
Промты
Для того, чтобы получить изображения, нам потребуется промт. В данной реализации их нужно будет два. Один позитивный Промт, т.е. описание задания модели в формате того, что мы от нее ждем. Второй Промт негативный, т.е. то, чего мы от модели не хотели бы получить.
prompt = "Fish plays the guitar" # Positive prompt
neg_prompt = "ugly, blurry, poor quality" # Negative prompt
Да, и составлять промты лучше на английском языке. Модель училась на английском, поэтому русский она поймет, но не так хорошо, как свой родной. Ничего сложного тут нет. Берем GoogleПереводчик и вперед.
В текущем примере мы будем ждать от модели картинку рыбы, которая играет на гитаре.
В негативном промте мы указали, что не хотелось бы, чтобы картинка была некрасивой, размытой и плохого качества. Звучит разумно.
Генерация
Нам потребуется следующий код в новой ячейке:
images = pipe(prompt=prompt, negative_prompt=neg_prompt, width=512, height=512, num_images_per_prompt=4).images
make_image_grid(images, rows=2, cols=2)
Давайте не сразу запускать этот код, а немного разберемся, что есть что. В объекте pipe мы видим несколько параметров. Prompt и negative_prompt: с ними все понятно, говорили о них ранее.
width — ширина картинки
height — высота картинки
Значения этих параметров должны быть кратны 8. Лучше их не ставить больше 1024. Для 4-х картинок за один проход разрешение 512 оптимально. Все, что будет больше, приведет к росту потребления памяти, и система скажет OutOfMemoryError и уйдет в трейс. Надо будет идти снова в «Среду выполнения», перезапускать среду и заново все запускать в блокноте по очереди.
Если нужна картинка с разрешением 1024, то лучше не запускать больше 2-х за один проход. Чем больше будет разрешение, тем детализированнее будет картинка. Экспериментируйте.
num_images_per_prompt — количество изображений, которые будут генериться за один запуск этого кода.
В результате исполнения первой строчки кода мы получим список объектов картинок. В данном случае их будет 4 штуки. Чтобы было нагляднее, мы эти картинки расположим вместе с помощью метода make_image_grid, который расположит картинки в таблице 2×2.
Запускаем.

Каждый раз, когда вы будете исполнять этот код, вы получите разные изображения. Можете сами в этом убедиться.
Чтобы дальше было проще изменять промт и запускать все из одной ячейки, объединим код следующим образом в новой ячейке:
prompt = "Fish plays the guitar" # Positive prompt
neg_prompt = "ugly, blurry, poor quality" # Negative prompt
images = pipe (prompt=prompt, negative_prompt=neg_prompt, width=512, height=512, num_images_per_prompt=4).images
make_image_grid (images, rows=2, cols=2)
Сохранение результата
Помним, что images — это список картинок. В нашем случае их 4. Поэтому, чтобы получить конкретную картинку из списка, нужно в следующей ячейке выполнить:
images[i]
, где i это номер картинки в списке, начиная с 0. Т.е., чтобы получить первую картинку из списка, нужно выполнить код
images[0]

Стили
Стиль, кадр и другие параметры картинок определяются с помощью промта. Можете попробовать такой промт:
prompt = "A brave cat protects the Galaxy from aliens. Anime style. Close up." # Positive prompt
neg_prompt = "ugly, blurry, poor quality" # Negative prompt
images = pipe (prompt=prompt, negative_prompt=neg_prompt, width=512, height=512, num_images_per_prompt=4).images
make_image_grid (images, rows=2, cols=2)
Запускаем.

Дальше, все зависит только от вашей фантазии. Экспериментируйте с промтами и генерируйте, генерируйте, генерируйте.
