Гексагональная архитектура и DDD на опыте интернет-магазина Спортмастер. Пробуем новое
Привет! Продолжим тему гексагональной архитектуры и DDD, первый пост — здесь.
Под катом — вспомним, что из себя представляет гексагональная архитектура, какие основные концепции содержит DDD и как теория, проявляясь в структуре проекта, помогает решить некоторые из описанных в первой части проблем.
Гексагональная архитектура
Одна из самых исчерпывающих статей по гексагональной архитектуре подробно и с примерами раскрывает назначение этой архитектуры.
Я приведу основные мысли.
Гексагональная архитектура имеет три фундаментальных блока:

1. Взаимодействие с приложением.
2. Логика или ядро приложения.
3. Взаимодействие с инфраструктурой.
И несколько уровней:
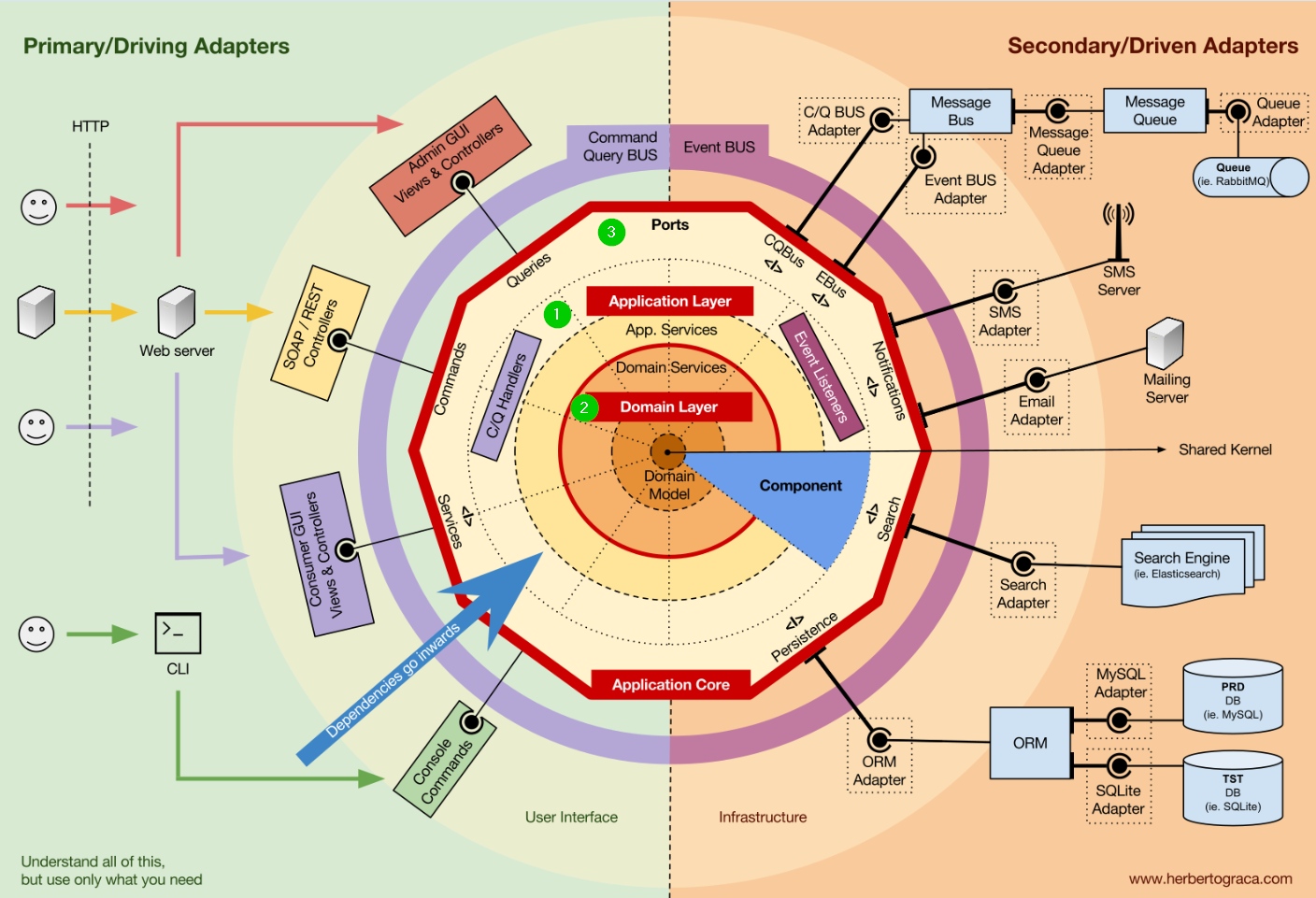
Уровень приложения (прикладной уровень). На этом уровне определяются варианты использования нашего приложения.
Роль этого уровня:
Проявить сценарии использования;
Использование уровня домена для выполнения бизнес логики;
Диспетчеризация событий приложения.
Уровень домена.
На этом уровне располагается доменная модель, а также бизнес правила, которые являются основной бизнес ценностью.Уровень инфраструктуры.
Отмечу, что явно проявленное направление зависимостей в данной архитектуре снаружи вовнутрь играет важную роль и позволяет сформировать структуру проекта с жестко фиксированными правилами.

Именно направление зависимостей является одной из концепций, которую мы реализовали в структуре проекта.
DDD
DDD — это предметно-ориентированное проектирование, набор принципов и схем, направленных на создание оптимальных систем объектов. Сводится к созданию программных абстракций, которые называются моделями предметных областей, — как раз то, что было в центре гексагональной архитектуры. В эти модели входит бизнес-логика, устанавливающая связь между реальными условиями области применения продукта и кодом. Последние несколько слов достаточно интересны и говорят о том, что DDD — это про отражение в коде того, что есть на самом деле, то есть названия методов, объектов, сущностей и всего остального именно так, как об этом говорят аналитики, бизнес и прочие заинтересованные лица.
DDD — это в первую очередь про единый язык, коммуникации и отражение бизнес-правил в коде в том виде, в котором они есть.
Для нас DDD интересно тем, что оно стандартизирует зоны ответственности и обязанности объектов, а также вводит четкое понимание слоев.
Мы взяли:
Единый язык. Стараемся разговаривать на нем с аналитиками, выражать в коде именно то, что говорят аналитики.
Ограниченные контексты. Стараемся делить сценарии использования функциональности в рамках контекста.
Сущности, объекты значений, агрегаты и подход к валидации, что немаловажно.
Шаблоны
DDD предоставляет стратегическими и тактическими шаблоны.

Стратегические шаблоны
Единый язык. Это базовая концепция борьбы со сложностями. Если предметная область и так требует изучения, то предполагается, что мы не будем делать вещи еще сложнее, заставлять людей разбираться еще и в нашей модели предметной области. Стараемся отображать в коде то, что говорят наши аналитики и бизнес и наоборот — понятия, которые вводятся в коде, мы транслируем аналитикам.
Например, аналитики не говорят wrapper, sender и тому подобное. Поэтому мы тоже стараемся не использовать такие технические наименования и всегда пытаемся от аналитиков узнать, что это такое на самом деле, как оно выглядит, что аналитик имел в виду, и реализовать это в коде. Зачастую, если к нам в ИМСМ на бэкенд приходит аналитик и говорит, что сервис отправки сбоит, мы так и ищем: «NotificationService» или «Какие бизнес-правила у нас для идентификатора корзины?», — мы набираем «CardId», наши бизнес-правила располагаются там.
Ограниченные контексты. Это явная граница, внутри которой существует модель предметной области, которая отображает единый язык, модель программного обеспечения. Это второе по значимости свойство DDD после единого языка. Оба эти понятия взаимосвязаны, не могут существовать друг без друга, то есть мы не можем создавать какие-то ограниченные контексты без единого языка и наоборот.
Тактические шаблоны
Данные шаблоны предлагаются DDD в качестве реализации.
Сущность — уникальное понятие предметной области. Если какое-то понятие предметной области является уникальным и отличным от всех других объектов в системе, то для его моделирования используется сущность.
Яркий пример — паспорт. Если бы мы работали с какой-то паспортной системой, то такое понятие, как паспорт, содержит номер, серию и прочее и является сущностью.
Объект значения. Если для объекта не важна индивидуальность, если он полностью определяется своими атрибутами, его следует считать объектом значения. Чтобы выяснить, является ли какое-то понятие значением, необходимо выяснить, обладает ли оно большинством следующих характеристик:
оно измеряет, оценивает или описывает объект предметной области;
его можно считать неизменяемым;
оно моделирует нечто концептуально целостное, объединяет связанные атрибуты в одно целое, при изменении способа измерения или описания его можно полностью заменить;
его можно сравнивать с другими объектами с помощью отношений равенства значений;
представляет связанным с ним объектам функцию без побочных эффектов.
Яркий пример — имя человека в паспорте.
Агрегат. По сути, агрегат является самым сложным из всех тактических инструментов. Агрегатом называется кластер из объектов сущностей или значений, то есть объекты можно рассматривать как единое целое с точки зрения изменения данных. У каждого агрегата есть корень и граница, внутри которой всегда должны быть удовлетворены инварианты.
В интернете можно найти большое количество разных мнений о том, что такое агрегат и как с ним работать. В целом, для того, чтобы поставить небольшую точку, агрегат — это сущность, но зачастую у агрегата есть вложенные сущности, вложенный список каких-то объектов значений, которые должны изменяться атомарно.
Как пример — продуктовая корзина. Да, это и агрегат и сущность, но в этой корзине есть продукты, которые могут быть представлены, например, списком. И для того, чтобы убрать ненужные продукты или пересчитать сумму у нас есть два варианта:
мы могли бы сделать getter, который возвращает этот список и уже в отдельном сервисе сделать все необходимые действия;
расположить логику удаления или пересчёта в самой корзине.
Агрегат как раз отвечает за то, чтобы в таких сценариях не было возможности получить список объектов, а был метод, который называется в соответствии с тем, что необходимо сделать со списком внутри агрегата. То есть, если аналитик говорит, что в корзине нужно пересчитать стоимость продуктов, у нашего агрегата «корзина» должен быть метод, который называется recalculate.
А вот тут происходит самое интересное: когда мы начинаем говорить на уровне агрегата и об агрегате, у нас получается так, что агрегат содержит в себе бизнес-логику того, что нам нужно сделать. Именно поэтому в DDD, например, нет такого понятия, как расположение бизнес-логики на уровне бизнесового сервиса, потому что для DDD нет бизнесовых сервисов (ну только если чуть-чуть :)), вся логика у нас находится в агрегатах. Так что правильное разделение доменной логики и доменных понятий позволяет легко инкапсулировать логику в одном месте для всего приложения.
Если мы захотим пересчитать что-либо где-либо, нам достаточно запросить этот агрегат, вызвать единый метод, и он будет одинаков везде. В случае стандартных подходов, когда у нас сервис является реализацией какого-то интерфейса или еще чего-то, нам придется везде таскать его с собой, смотреть за тем, та ли логика и та ли реализация используются. Это добавляет свой оверхед.
Кричащая архитектура
Также мы позаимствовали немного понятий из концепции »кричащей архитектуры». Данный термин ввел Роберт Мартин в своей книге «Чистая архитектура» в главе 21.
Какая основная концепция? Рассматривая чертежи коттеджа и библиотеки, вы никогда не ошибетесь, что есть что. Так же и в архитектуре ПО — вы не должны ошибиться в назначении приложения, глядя на верхнеуровневые пакеты онлайн-магазина и сервиса по обмену валюты.
Увы, часто в современных приложениях архитектура говорит о том, что приложение работает с каким-то сервисом, использует какие-то хранилища и кидает какие-то исключения. Под капотом этих пакетов раскрывается дивный мир взаимосвязей: какое-то большое количество сервисов и классов использует хаотично интерфейс репозиториев и прочее.
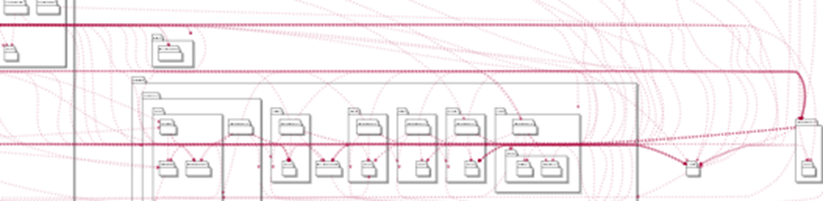
Выше пример того, как выглядела структура пакетов нашего приложения, когда всё могло использовать всё, мы работали с какими-то сервисами, использовали какие-то репозитории, у нас был пакет Exception, если не ошибаюсь, который кидал какие-то исключения.
Что получилось-то?

У вас может возникнуть резонный вопрос:, а что же в итоге получилось? Неужели архитектура бэкенда ИМСМ похожа на такого чудо-зверя? Попробуем разобраться.
Направление зависимостей
Если ранее у нас на схеме
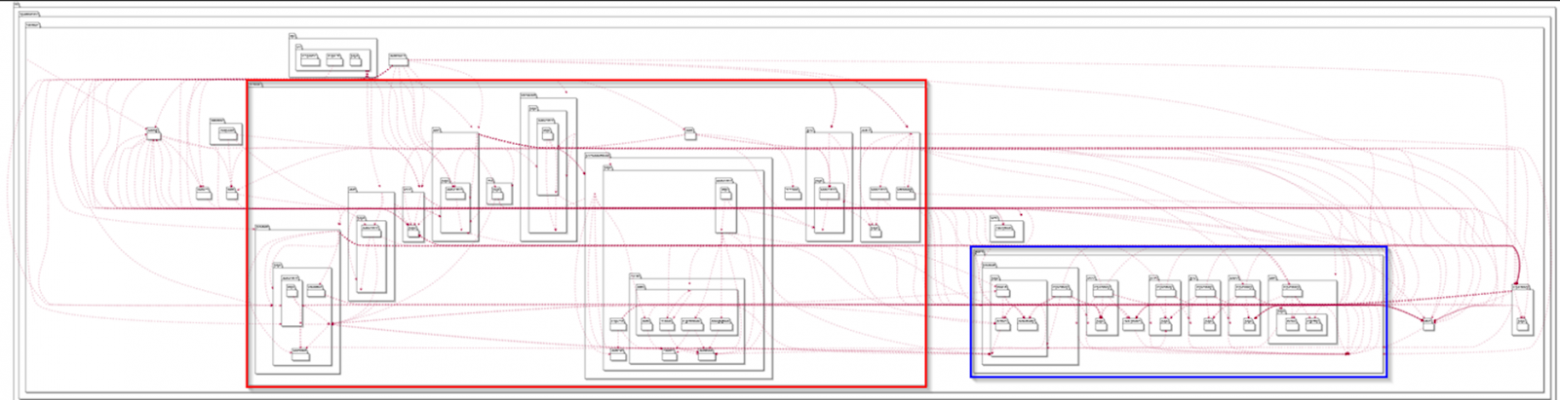
не было понятно, что от чего зависит, то с переходом на новую архитектуру у нас появилась фиксированная структура пакетов с понятными правилами.

Основные моменты:
Уровень представления зависит от уровня приложения.
Уровень приложения зависит от домена.
Инфраструктура зависит от домена.
Обратите внимание, что интерфейс хранилища располагается в модели и является её частью, а реализация уже находится в инфраструктуре.
Как вы помните направление зависимости должно идти снаружи вовнутрь. То есть предметная область, которая в данном случае представлена пакетом домена, не должна зависеть от уровня представлений или инфраструктуры. В данном случае уровень инфраструктуры представлен пакетом infrastructure, уровень представления — пакетом presentation.
Уровень приложения знает о том, какие существуют модели, как их создавать и прочее, и взаимодействует с нашим доменным уровнем, а инфраструктура зависит от домена. Обратите внимание на то, что интерфейс хранилища, тот самый репозиторий, располагается в домене и является его частью, а реализация уже находится в инфраструктуре.
Почему так? Интерфейс репозитория является частью контракта предметной области, который описывает то, что нужно уметь делать предметной области — получить какие-то данные, сохранить какие-то данные, создать какой-то агрегат и прочее. Поэтому интерфейс является частью домена, а уже реализация, будь то любая новая БД, файл, JSON и прочее находится в инфраструктуре.
В инфраструктуре мы показываем, какой является реализация. В данном случае репозиторием рекомендаций является интеграционный репозиторий с сервисом продуктов. Возможно, будут вопросы о том, что у нас есть в application интерфейс и есть реализация «Impl». В целом «Impl»- достаточно плохая практика, есть большое количество статей об этом, но у нас есть практика описания интерфейсов для удобства тестирования, удобной замены и прочего. Ожидается, что логика на уровне application и на уровне домена всегда едина и зависит только от бизнес-требований, которые для нашего приложения всегда единичны. То есть нет требований, которые бы могли меняться в зависимости от чего-то.
Сценарии использования
Кроме этого, у нас появились (и стали понятны) сценарии использования — то, что могут делать клиенты с нашим приложением. На нашем бэкенде сценарий использования должен:
быть проявлен;
не затрагивать другие сценарии использования;
иметь возможность использования любым клиентом (Rest, CLI, очереди, брокеры и прочее).
Все сценарии использования у нас реализуются на уровне application, то есть если контекст взаимодействует с клиентом, например, Rest API, то данное взаимодействие обязано быть через слой application.

При этом верно и обратное. Если контекст не взаимодействует с внешним клиентом, у него может отсутствовать уровень application.
В примере: у нас есть верхнеуровневый контекст аутентификации и контекст logout, явно есть уровень application, что может делать Rest API с нашим приложением, в данном случае это делает logout. Существует и другой контекст — баннер, у которого также есть application, который также содержит сервис и который также может легко показать, что можно делать с нашим приложением. Это очень удобно, потому что по пакетам ты всегда можешь узнать, смотрит ли этот контекст наружу или это внутренний какой-то контекст неспецифической подобласти и прочее.
Ошибки
Согласно третьей обязанности BFF, наше приложение должно отдавать клиенту ошибки, понятные пользователю.

Для этого у нас каждый сценарий использует специфичные для него ошибки, что надежно отделяет один используемый сценарий от другого.

Обратите внимание на то, что у нас на уровне application для каждого контекста есть свои ошибки, которые отражают весь набор ошибок, которые могут произойти в данном сценарии.
Пусть вас не смущает то, что у нас называется LogoutServiceException, одно-единственное исключение. На бэкенде мы используем Kotlin, и в исключениях достаточно активно применяем Sealed-классы, что позволяет нам определять какое-то базовое исключение и уже внутри реализовывать некоторое количество исключений согласно сценариям, которые принимают, возможно, разные параметры, начиная от таймера, сколько осталось времени до другой попытки, и заканчивая всем, что можно придумать.
Зависимость от фреймворка
Гексагональная архитектура показывает, что интерфейсы у нас должны быть на уровне бизнес-логики, а уже реализации должны быть где-то в инфраструктурных пакетах. Эту же идею полностью поддерживает и Роберт Мартин в книге «Чистая архитектура» в главе 32, в которой говорит, что фреймворк — это деталь, предметная область обязана быть чистой от зависимостей фреймворка.
В нашем случае домен полностью чист от фреймворков. Это важно, потому что никто не может дать гарантий, что в современном мире та или иная технология с нами надолго. Если завтра окажется, что Quarkus или Micronaut будут больше отвечать требованиям по холодному запуску, по быстроте развертывания и прочее, не будет стоить больших усилий перейти на их использование при подходе с гексагональной архитектуре.
Сейчас у нас работа с транзакциями и инфраструктурными зависимостями находится на application, работа с персистентностью — на инфраструктуре, работа с контроллерами — на уровне представления. То есть, если мы захотим перейти на Micronaut, мы просто поменяем три аннотации, которые точно существуют в другом фреймворке. И нам это ничего не будет стоить.
В посте мы затронули тему как гексагональная архитектура и DDD повлияли на структуру проекта, в следующем посте посмотрим какие изменения произошли в коде.
