Flume — управляем потоками данных. Часть 3
- Как настроить мониторинг компонентов узла.
- Как написать собственную реализацию компонента Flume.
- Проектирование полноценной транспортной сети.

Мониторинг состояния компонентов узла
Итак, мы настроили и запустили все узлы, проверили их работоспособность — данные успешно доставляются до пункта назначения. Но проходит какое-то время, мы смотрим на результат работы нашей транспортной сети (например, папку с файлами, в которые упаковываются данные) и понимаем, что возникла проблема — начиная с какого-то момента новые файлы не появляются в нашей папке. Следующий шаг кажется очевидным — открываем логи, ищем причину. Беда только в том, что узлов в нашей транспортной сети может быть много, а значит необходимо вручную просматривать логи всех узлов, что, мягко говоря, не очень удобно. Когда подобные проблемы возникают, реагировать на них хотелось бы максимально оперативно, а еще лучше — вообще не допускать таких критичных ситуаций.
Компоненты Flume в процессе работы пишут метрики, которые позволяют оценить состояние узла. По значениям этих метрик довольно легко определить, что с узлом не всё в порядке.
Для хранения счетчиков и других атрибутов своих компонентов Flume использует java.lang.management.ManagementFactory, регистрируя собственные bean-классы для ведения метрик. Все эти классы унаследованы от MonitoredCounterGroup (для любопытных — ссылка на исходный код).
Если вы не планируете разрабатывать собственные компоненты Flume, то закапываться в механизм ведения метрик совершенно необязательно, достаточно разобраться, как их достать. Сделать это можно довольно просто с помощью утилитарного класса JMXPollUtil:
package ru.test.flume.monitoring;
import java.util.Map;
import org.apache.flume.instrumentation.util.JMXPollUtil;
public class FlumeMetrics {
public static Map> getMetrics() {
Map> metricsMap = JMXPollUtil.getAllMBeans();
return metricsMap;
}
} В результате вы получите метрики, сгруппированные по компонентам узла, которые выглядят примерно так:
{
"SOURCE.my-source": {
"EventReceivedCount": "567393607",
"AppendBatchAcceptedCount": "5689696",
"Type": "SOURCE",
"EventAcceptedCount": "567393607",
"AppendReceivedCount": "0",
"StartTime": "1467797931288",
"AppendAcceptedCount": "0",
"OpenConnectionCount": "1",
"AppendBatchReceivedCount": "5689696",
"StopTime": "0"
},
"CHANNEL.my-channel": {
"ChannelCapacity": "100000000",
"ChannelFillPercentage": "5.0E-4",
"Type": "CHANNEL",
"ChannelSize": "500",
"EventTakeSuccessCount": "567393374",
"StartTime": "1467797930967",
"EventTakeAttemptCount": "569291443",
"EventPutSuccessCount": "567393607",
"EventPutAttemptCount": "567393607",
"StopTime": "0"
},
"SINK.my-sink": {
"ConnectionCreatedCount": "1",
"ConnectionClosedCount": "0",
"Type": "SINK",
"BatchCompleteCount": "2",
"EventDrainAttemptCount": "567393374",
"BatchEmptyCount": "959650",
"StartTime": "1467797930968",
"EventDrainSuccessCount": "567393374",
"BatchUnderflowCount": "938419",
"StopTime": "0",
"ConnectionFailedCount": "0"
}
}
Метрики получили, теперь необходимо их куда-то отправить. Здесь можно пойти двумя путями.
- Использовать возможности Flume для предоставления метрик.
- Написать свою реализацию обработки метрик.
Flume предоставляет API, позволяющей задать способ мониторинга — для этого используются реализации интерфейса MonitorService. Для того, чтобы подключить мониторинг, необходимо указать класс, реализующий
MonitorService, в качестве системного свойства при запуске узла (или в коде).java -Dflume.monitoring.type=org.apache.flume.instrumentation.http.HTTPMetricsServer ...System.setProperty("flume.monitoring.type", "org.apache.flume.instrumentation.http.HTTPMetricsServer");Класс
HTTPMetricsServer предлагает стандартный способ отслеживания состояния узла. Он представляет собой небольшой web-сервер, который по запросу отдает полный список метрик узла в виде JSON (как в примере выше). Чтобы указать порт, на котором этот сервер будет слушать запросы, достаточно добавить в конфигурацию Flume параметр (по умолчанию использует порт 41414): flume.monitoring.port = 61509Запрос к этому серверу выглядит так:
localhost:61509/metrics.Если же такого способа следить за метриками недостаточно, то придется пойти вторым путём и написать собственную реализацию MonitorService. Именно так мы и поступили, чтобы наблюдать за состоянием наших узлов с помощью Graphite. Ниже приведен простой пример такой реализации.
package ru.dmp.flume.monitoring;
import com.google.common.base.CaseFormat;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import org.apache.flume.Context;
import org.apache.flume.instrumentation.MonitorService;
import org.apache.flume.instrumentation.util.JMXPollUtil;
public class FlumeGraphiteMonitor implements MonitorService {
// нормализованные имена метрик, которые не нужно отправлять в Graphite
private static final Set EXCLUDED_METRICS = new HashSet() {{
add("start-time");
add("stop-time");
}};
private volatile long period = 60 * 1000; // интервал отправки, 1 минута
private volatile boolean switcher = true;
private Thread scheduler = new Thread(this::schedule);
@Override
public void configure(Context context) {
// Здесь можно достать какие-нибудь настройки из файла конфигурации
}
private void schedule() {
while (switcher) {
send();
synchronized (this) {
try {
wait(period);
} catch (InterruptedException ex) {}
}
}
}
@Override
public void start() {
scheduler.start();
}
@Override
public void stop() {
switcher = false;
synchronized (this) {
notifyAll();
}
try {
scheduler.join();
} catch (InterruptedException ex) {}
}
private void send() {
Map> metricsMap = JMXPollUtil.getAllMBeans();
for (Map.Entry> e: metricsMap.entrySet()) {
if (e.getValue() != null) {
// все метрики от узлов Flume начинаем с префикса "flume"
String group = "flume." + normalize(e.getKey().toLowerCase()) + ".";
for (Map.Entry metric : e.getValue().entrySet()) {
try {
Double value = Double.valueOf(metric.getValue());
String metricName = normalize(metric.getKey());
if (!EXCLUDED_METRICS.contains(metricName)) {
String fullName = group + normalize(metric.getKey());
// Отправляем данные в графит или куда-то еще
// Graphite.send(metricName, value);
}
} catch (NumberFormatException ex) {
// так отсеиваем значения, не являющиеся числом
}
}
}
}
}
// приводим к виду EventReceivedCount -> event-received-count (необязательно)
private static String normalize(String str) {
return CaseFormat.UPPER_CAMEL.to(CaseFormat.LOWER_UNDERSCORE, str).replaceAll("_", "-");
}
В итоге получаем аккуратную ветку Graphite со всеми метриками узла.

Ниже приведены описания графиков и метрик, которые мы используем для одного из наших сервисов.
- Интенсивность отправки сервисом сообщений на узел Flume. График строится не по метрикам узла — эти значения в Graphite отправляют сервисы, которые генерируют данные и являются отправной точкой нашей транспортной системы. Если ваши источники данных не позволяют отслеживать отправку данных во Flume, то похожие графики можно снять с источника (-ов) узла.
Если значение на этом графике падает до нуля, значит клиент по каким-то причинам не может отправить сообщения во Flume. Чтобы диагностировать, кто виноват в таких ситуациях, мы отдельно отображаем график ошибок, возникающих на стороне клиента. Соответственно, если он отличен от нуля — проблема на узле Flume, источник не может принять данные. Если же падение интенсивности не влечет роста числа ошибок — значит проблема на стороне сервиса, он перестал отправлять сообщения.

- Заполненность каналов узла. С этим графиком всё просто — он всегда должен быть очень близок к нулевому значению. Если канал не успевает опустошаться, значит где-то в нашей транспортной сети возникло узкое место и необходимо искать узлы, которые не успевают справляться с нагрузкой. Метрика на графике:
flume.channel.{CHANNEL-NAME}.channel-fill-percentage
- Интенсивность работы стоков узла. Ожидаемые показатели стоков на этом узле — «сколько получили, столько и отправили», поскольку события от сервисов не дублируются в каналы. Таким образом, интенсивность опустошения стоков должна быть такой же, как и интенсивность отправки данных клиентами. Метрика на графике:
flume.sink.{SINK-NAME}.event-drain-success-countПадение интенсивности любого из стоков до нуля говорит о потенциальной проблеме на следующем, принимающем, узле. Как следствие, канал, опустошаемый «поломанным» стоком, начнет заполняться. Также возможна ситуация, при которой принимающие узлы работают нормально, но просто не успевают обрабатывать входные данные — в этом случае графики стоков будут ненулевыми, но каналы будут постепенно заполняться.

Создание собственных компонентов Flume
Несмотря на то, что набор стандартных компонентов Flume довольно обширен, довольно часто возникают ситуации, разрешить которые этим стандартными компонентами невозможно. В этом случае можно написать свой компонент Flume и задействовать его в узлах. Свою реализацию можно написать для любого из компонентов Flume — sink, source, channel, interceptor и т.п.
Первое, что бросилось в глаза при изучении стоков Flume — это отсутствие гибкого стока для файловой системы. Да, есть File-Roll Sink, возможности которого описывались во 2й части цикла. Но этот сток полностью лишен возможности как-либо влиять на имя файла, что не очень удобно.
Мы решили разработать свой сток, позволяющий формировать файлы в локальной файловой системе. При разработке руководствовались следующими соображениями.
- У нас довольно много сервисов со сравнительно небольшой нагрузкой. Это значит, что в итоге у нас будет довольно много разнородных файлов — не хотелось бы под каждый из них настраивать отдельный сток.
- Файлы должны ротироваться по времени. Причем, для различных данных период ротации может отличаться (под ротацией имеется ввиду «нарезка данных» на файлы по времени — 15 минут, час и т.п.).
- Данные от каждого сервиса должны складироваться в отдельную папку. Причем, один сервис может генерировать данные для нескольких подпапок.
Исходя из этих тезисов, мы пришли к выводу, что задачу формирования имени файла лучше оставить клиенту (т.е. сервисам, генерирующим данные), иначе конфигурация стока будет слишком громоздкой, а для каждого нового «клиента» придется добавлять отдельный сток с индивидуальными настройками.
Примечание. Здесь уместно сравнение с HDFS-стоком, о котором мы говорили в предыдущей статье. Этот сток позволяет выполнить очень тонкую настройку ротации и именования файлов. Но эта гибкость настройки имеет и обратную сторону — например, для файлов, ротирующихся раз в 15 и раз в 30 минут приходится делать различные стоки, даже если во всем остальном параметры идентичны.
Итого, решение по функциональности файлового стока было принято следующее:
- Имя файла, в который должны быть записаны данные, определяет клиент и передает его в заголовке вместе с событием.
- В имени файла могут быть указаны подпапки.
- Файлы, в которые ведется запись стоком, закрываются по некоторому таймауту, когда для них перестают приходить события.
Схематично процесс обработки данных этим стоком выглядит так:

Что это дало в итоге:
- Не требуется добавлять сток для каждого нового сервиса или типа данных.
- Сток лишен издержек на формирование имени файла (в предыдущей части мы рассматривали эти издержки на примере HDFS-стока)
- Поскольку имя файла однозначно идентифицируется одним заголовком, мы можем пользоваться группировкой событий на стороне клиента (этот прием также описан во второй части цикла).
Исходный код файлового стока и пример его конфигурации выложены на GitHub. Подробно разбирать процесс разработки этого стока, я думаю, смысла нет, ограничусь несколькими тезисами:
- За основу компонента берется либо абстрактный класс, либо интерфейс компонента (в зависимости от того, что вы разрабатываете — сток, перехватчик или что-то еще).
- Делаем собственную реализацию — проще всего взять что-нибудь из готовых Flume-компонентов в качестве примера, благо все исходники доступны.
- При конфигурации указываем не зарезервированный псевдоним компонента (типа 'avro' или 'logger'), а имя класса целиком.
Проектируем транспортную сеть
Общие приемы управления данными мы рассмотрели в предыдущих частях цикла — события можно делить между узлами, дублировать, выбирать «направление движения», используя заголовки и т.п. Попробуем теперь использовать все эти приемы для того, чтобы построить надежную транспортную сеть. Предположим, задача выглядит следующим образом.
- Поставщик данных — некий сервис, работающий на нескольких машинах (имеет несколько одинаковых инстансов).
- Данные, генерируемые сервисом, разнородны — часть из них нужно доставить в HDFS, часть — в файловую систему на некий лог-сервер.
- Необходимо в режиме реального времени вести некоторые неатомарные вычисления, связанные с данными.
На условии 3 остановлюсь подробнее. Предположим, что задача состоит в подсчете уникальных пользователей сайта за последний час. В этом случае мы не можем позволить себе распараллелить поток данных с машин или вычислять это значение отдельно на каждом веб-сервисе — вести подсчет уникальных пользователей по их кукам необходимо на едином потоке данных со всех машин. В противном случае каждый инстанс будет иметь свой набор уникальных пользователей, которые нельзя «взять и сложить» для получения конечного результата.
Примечание. Разумеется, пример немного надуман — эту задачу можно решить и другими, более эффективными способами. Суть примера сводится к ситуации, когда вам необходимо пропускать некоторый поток данных централизовано через один обработчик и разделить нагрузку невозможно из-за особенностей задачи.
Итак, для начала подготовим клиентские и конечные узлы:

Для каждого из веб-сервисов ставим свой, индивидуальный узел — на той же машине, что и веб-сервис. Делается это по следующим причинам:
- Эти узлы играют роль буфера — если по какой-то причине доставка событий на другие машины станет невозможна, эти узлы позволят некоторое время «продержаться» без потерь данных за счет толстого файлового канала.
- Уменьшается время отклика. Разумеется, отправка данных во Flume должна выполняться асинхронно —, но при пиковых нагрузках или забитой сети может возникнуть ситуация, когда фоновый поток не будет успевать отправлять новые события. В этом случае очередь на отправку может сильно вырасти, безжалостно поглощая память сервиса, что не очень хорошо. В случае, когда узел расположен на той же машине, что и сервис, эти издержки значительно снижаются.
- Если дальнейшая логика обработки данных изменится и вы решите перестроить транспортную сеть, то изменения нужно будет внести только в конфигурацию клиентского узла, а не веб-сервиса. Для него все останется по-прежнему — «я отправляю данные на свой узел, дальше пусть сам решает, как быть».
Остается вопрос — как доставить данные так, чтобы ничего не потерять, если что-то сломается? Ряд мер мы уже предприняли — данные для HDFS и для FS пишутся на несколько машин. При этом данные не дублируются, а делятся. Таким образом, если одна из конечных машин выходит из строя, вся нагрузка пойдет на оставшуюся в живых. Следствием такой поломки будет дизбаланс по записанному объему данных на различных машинах, но с этим вполне можно жить.
Чтобы обеспечить бОльшую стабильность, добавим несколько промежуточных узлов Flume, которые будут заниматься непосредственно распределением данных:
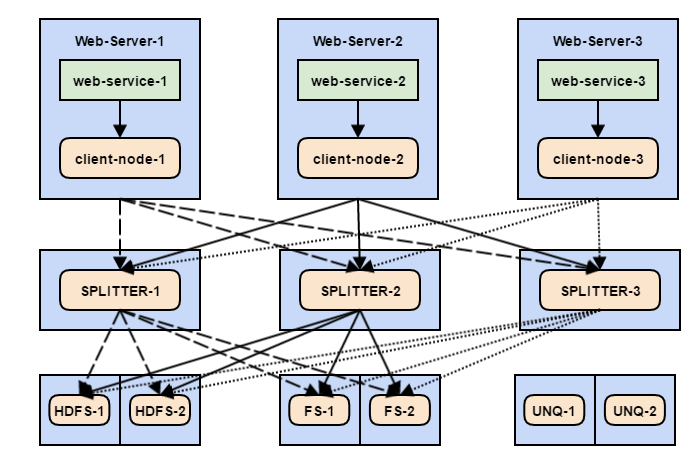
Получилась довольно жуткая паутина. Что здесь происходит:
- Веб-сервис отправляет события на клиентский узел.
- Каждое событие имеет заголовок, который указывает «пункт назначения» (например dist=FS или dist=HDFS), а также заголовок uniq с возможными значениями 1 или 0.
- Каждый клиентский узел имеет по 3 стока, которые равноправно опустошают канал и равномерно распределяют события между тремя промежуточными узлами — Splitter’ами (пока что без оглядки на заголовок dist).
- Каждый Splitter имеет несколько каналов — для HDFS, FS и счетчика уникальных пользователей. Необходимый канал выбирается по заголовкам dist и uniq.
- Каждый из этих каналов на Splitter’e имеет несколько стоков, которые равномерно распределяют события между конечными машинами (FS, HDFS или UNQ).
Если с клиентскими узлами всё относительно просто — они просто делят события между Splitter’ами, то структуру отдельно взятого Splitter’a стоит рассмотреть более детально.

Здесь видно, что конечный пункт для данных определяется с помощью заголовка dist. При этом, события, по которым считаются уникальные пользователи, не зависят от заголовка dist — они ориентируются на заголовок uniq. Это значит, что некоторые события могут быть продублированы в несколько каналов, например HDFS и UNQ.
Ранее я специально не указал направления от Splitter’ов к узлам UNQ. Дело в том, что эти узлы не принимают распределенные данные, как HDFS или FS. Учитывая специфику задачи подсчета уникальных пользователей, весь поток данных должен проходить только через одну машину. Закономерный вопрос — зачем нам тогда 2 узла для подсчета уникальных пользователей? Ответ — потому что если один узел сломается, его будет некому заменить. Как здесь быть — делить события между узлами мы не можем, оставить один — тоже нельзя?
Здесь нам может помочь еще один инструмент Flume, позволяющий работать стокам в группе по принципу «Если сток 1 сломался, используй сток 2». Этот компонент называется Failover Sink Processor. Его конфигурация выглядит следующим образом:
# Сами по себе стоки описываются как обычно
agent.sinks.sink-unq-1.type = avro
agent.sinks.sink-unq-1.batch-size = 5000
agent.sinks.sink-unq-1.channel = memchannel
agent.sinks.sink-unq-1.hostname = unq-counter-1.my-company.com
agent.sinks.sink-unq-1.port = 50001
agent.sinks.sink-unq-2.type = avro
agent.sinks.sink-unq-2.batch-size = 5000
agent.sinks.sink-unq-2.channel = memchannel
agent.sinks.sink-unq-2.hostname = unq-counter-2.my-company.com
agent.sinks.sink-unq-2.port = 50001
# Объединяем их в группу
agent.sinkgroups = failover-group
agent.sinkgroups.failover-group.sinks = sink-unq-1 sink-unq-2
# Тип процессинга указываем как failover
agent.sinkgroups.failover-group.processor.type = failover
# Приоритеты для стоков - сток с высоким значением будет задействован первым
agent.sinkgroups.failover-group.processor.priority.sink-unq-1 = 10
agent.sinkgroups.failover-group.processor.priority.sink-unq-2 = 1
# Как часто проверять - вернулся ли сток в строй (мс)
agent.sinkgroups.failover-group.processor.maxpenalty = 10000Приведенная выше настройка группы потоков позволяет использовать только один сток, но при этом иметь «запасной» на случай аварии. Т.е. покуда сток с высоким приоритетом исправно работает, стоки с низким приоритетом будут простаивать.
Таким образом, поставленная задача выполнена — данные распределяются между HDFS и FS, счетчики уникальных пользователей работают корректно. При этом выход из строя любой машины не приведет к потере данных:
- Если ломается машина c Web-сервисом, то эта проблема решается балансером.
- Если из строя вышел один из Splitter’ов, нагрузка будет распределена между остальными.
- Конечные узлы также задублированы, поломка одного из них не приведет к застою или потере данных.
- Узел для подсчета уникальных пользователей имеет «дублёра» и в случае поломки будет заменен им без нарушения логики обработки данных.
Для такой схемы задачи масштабирования сводятся к простому изменению конфигурации узлов Flume для соответствующего уровня узлов (Client, Splitter или Final):
- Новый инстанс Web-сервиса — не требуется изменения конфигурации, он просто устанавливается вместе с клиентским узлом Flume.
- Новый Splitter — требуется изменить только конфигурацию клиентских узлов, добавив новый сток.
- Новый конечный узел — требуется изменить только конфигурацию Splitter’a, добавив новый сток.
Заключение
На этом мы завершаем цикл статей про Apache Flume. Мы осветили все самые ходовые его компоненты, разобрались как управлять потоком данных и рассмотрели пример полноценной транспортной сети. Тем не менее, возможности Flume не исчерпываются всем этим — в стандартном пакете есть еще довольно много не рассмотренных нами компонентов, которые могут значительно облегчить жизнь при решении определенных задач. Надеемся, что этот цикл статей помог вам познакомиться с Flume и получить достаточно полное представление о нём.
Спасибо за внимание!
