Двойной эксперимент: как студенты примеряли ML на услуги телеком-операторов

За чем стоит будущее IT-индустрии? Определить главный тренд совсем не сложно — искусственный интеллект и машинное обучение.
Nexign всегда смело смотрит в будущее, так в одном из проектов мы решили выйти за рамки привычных нам подходов: взяли новые технологии — ML, новых специалистов — студентов из профильных вузов, новый формат стажировки — самостоятельная команда из подкованных в теории ребят. Дальше всё решили перемешать, и посмотреть, что из этого получится.
В этой статье расскажем о том, каких успехов достигли в рамках небольшого ML-проекта и как удалось не только решить несколько кейсов, но и разработать полноценный движок для разработки, тестирования и анализа новых моделей машинного обучения.
Вводные
В отрасли давно сформировалась гипотеза о том, что в телеком-системах при помощи машинного обучения можно предсказывать поведение абонентов, бороться с их оттоком, рекомендовать оптимальные новые услуги. В Nexign уже велась работа в этом направлении, но без использования машинного обучения. Следующим логичным шагом стало развитие процесса при помощи ML-технологий.
Стажёров объединили в независимую группу, прикрепили к ним наставника, снабдили данными и постарались предоставить им свободу в работе. Так у нас родился небольшой проект CARP: classification — analysis — recommendation — prediction, который должен упростить и ускорить разработку кейсов с использованием машинного обучения.
В начале работы перед командой стояла задача решить три четких кейса, о которых дальше пойдёт речь:
построить модель предсказаний вероятности ухода абонентов (кейс №1);
разработать систему скоринга по отсроченным платежам (кейс №2);
создать рекомендательную систему для продуктовых предложений (кейс №3).
Экскурс: как работает машинное обучение
Многие соотносят термины «искусственный интеллект», «машинное обучение» и «нейросети», как будто это одно понятие. Но нейросети — это только один из подтипов машинного обучения и один из сотни алгоритмов, которые могут быть использованы.
А что же такое машинное обучение? Некоторая коллаборация линейной алгебры и магии? На самом деле, всё немного сложнее.
Машинное обучение (ML) — это подход, который позволяет модели автоматически самообучаться и принимать решения на основе данных и закономерностей. В основе лежат методы статистики, информатики, математики и искусственного интеллекта. ML подходит для анализа данных, распознавания образов, предсказания поведения и принятия решений в различных областях.
Реализация любого кейса на машинном обучении состоит из пяти этапов:
1 этап: аналитика данных. Для начала определяем, чего мы хотим и на основе каких данных это можно предсказать.
2 этап: сбор нужных данных. Формируем массив вводной информации, на котором в дальнейшем будет обучаться модель. Данные могут лежать в 1, 2 или 10 системах, поэтому даже просто собрать их в Excel — это уже человеко-дни, недели.
3 этап: обработка и преобразование данных. Настраиваем модель правильно понимать, какие перед ней данные, какой диапазон возможных значений. Например, есть весомая разница — обучаться на данных от 0 до 1 или от 0 до бесконечности.
4 этап: обучение и построение модели. На этом этапе скармливаем тестовые данные, смотрим метрики, и переобучаем модель, пока не добьемся нужной логики.
5 этап: предсказание результата — кульминационный момент. Приходим с конкретным запросом, происходит магия (анализ данных при помощи предиктивной модели), получаем тот самый результат.
Концепция ML-решения

Итак, у нас было три кейса по предсказанию поведения телеком-абонентов. Использовали массив данных из биллинговой системы: платежная информация, сведения о пользователях, о подключенных тарифах и опциях. Для их сбора реализовали отдельные коннекторы, которые подтягивали необходимую информацию.
Все эти данные складывались в Clickhouse — нашу базу данных. Это нужно для того, чтобы в дальнейшем на их основе просто и относительно недорого обучить модель.
По концепции решения эти данные используем только в момент создания модели. А заниматься её переобучением нужно только тогда, когда паттерн поведения пользователя меняется: раз в полгода, раз в год или при существенных изменениях бизнес-потребностей.
Дальше — когда нужно предсказать поведение пользователя, мы по ID выбираем актуальные данные, подаем на вход модели и получаем наше предсказание.
Мы выбрали stateless-подход, то есть не храним данные абонентов внутри своего решения. Наши backend-сервисы абсолютно изолированы друг от друга, при этом позволяют горизонтально масштабироваться. За счёт этого можно легко обрабатывать большие объемы данных с минимальными затратами на железо.
Рассмотрим каждый кейс подробнее и на примерах разберем: какая была задача, что делали, и какой результат получили. Двигаться будем от самого простого к сложному.
Кейс №1 «Уход абонентов»

Цель — разработать модель, предсказывающую вероятность ухода абонентов. Владея этим прогнозом, оператор связи может предпринять попытку удержания. Например, с помощью предложения нового тарифного плана или новых услуг.
Реализация. База данных для кейса состояла из 32 000 абонентов, 80% из них стали обучающей выборкой, 20% — тестовой. Массив представлял собой исторические данные абонентов и данные по потреблению услуг. На основе массива данных обучили модель, выделили ключевые признаки, определили взаимосвязи. Пример данного кейса — большое количество отправляемых СМС может стать одним из ключевых признаков и говорить о лояльности абонента.
Результат. Общая точность на тестовой выборке, то есть на данных, которые модель не видела во время обучения, составила 94%. То есть в 94% случаев модель правильно предсказывает поведение пользователя.
Кейс №2 «Система скоринга»

Цель — разработать систему, позволяющую предсказать, какую часть отсроченного платежа абонент вернет в срок.
Реализация. Собрали большое количество данных об абонентах, среди которых есть исторические данные о том, как они раньше пользовались подобными услугами, персональные данные. На основе массива данных обучили модель, выделили ключевые признаки, определили взаимосвязи. На примере второго кейса поняли, что для прогноза погашения задолженности нам важно учитывать историчность выплат за предыдущие периоды.
Результат. Обученная модель в среднем ошибается на 70 рублей или на 10% от суммы платежа. На графике представлена зависимости ошибки предсказания от суммы платежа. Чем ниже точка находится к 0, тем меньше ошибка.
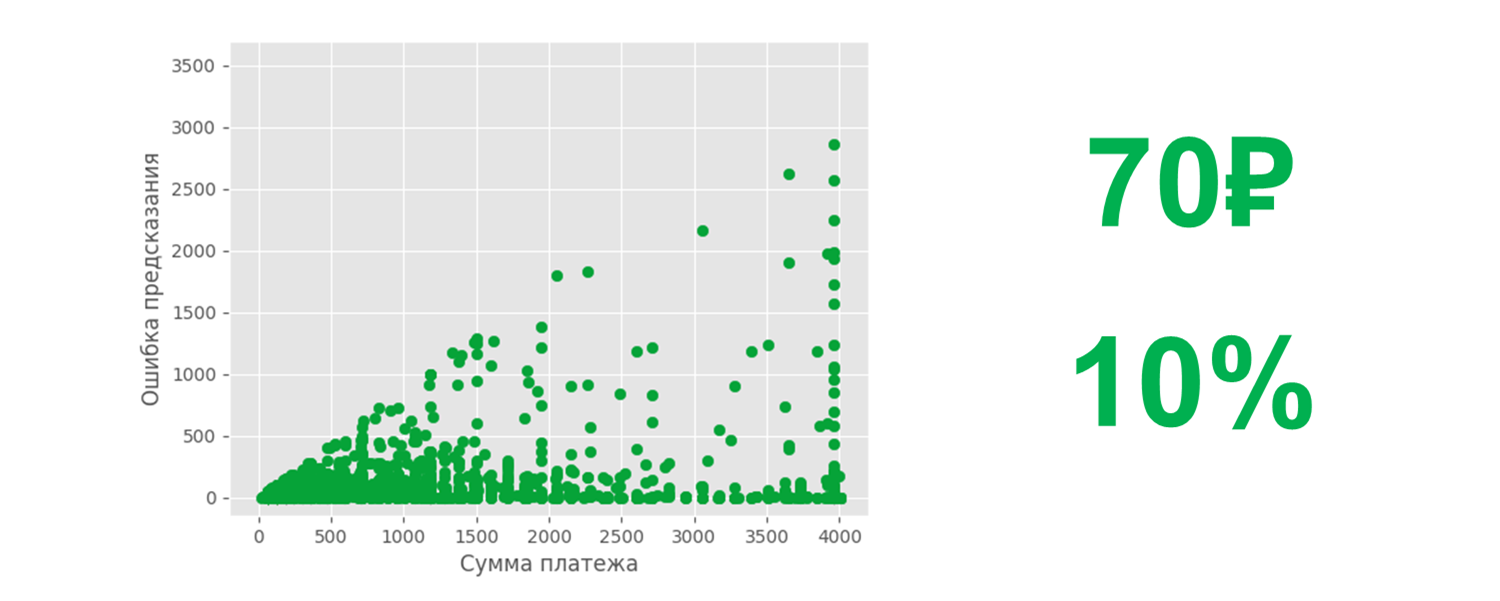
Полученный результат нас не устроил, и мы решили проанализировать работу нашей модели, чтобы увеличить точность. В процессе заметили интересную особенность поведения, которую можно назвать внезапной невыплатой. Встречаются девиантные кейсы, когда абонент долгое время пользуется услугой отсрочки платежа, регулярно закрывает задолженность, но вдруг в какой-то момент не выплачивает совсем. Такие кейсы составляют примерно 13% от всей выборки. В остальных же 87% процентах мы предсказываем довольно точно, ошибаемся в среднем на 20 рублей или же на 2,5% от суммы платежа.
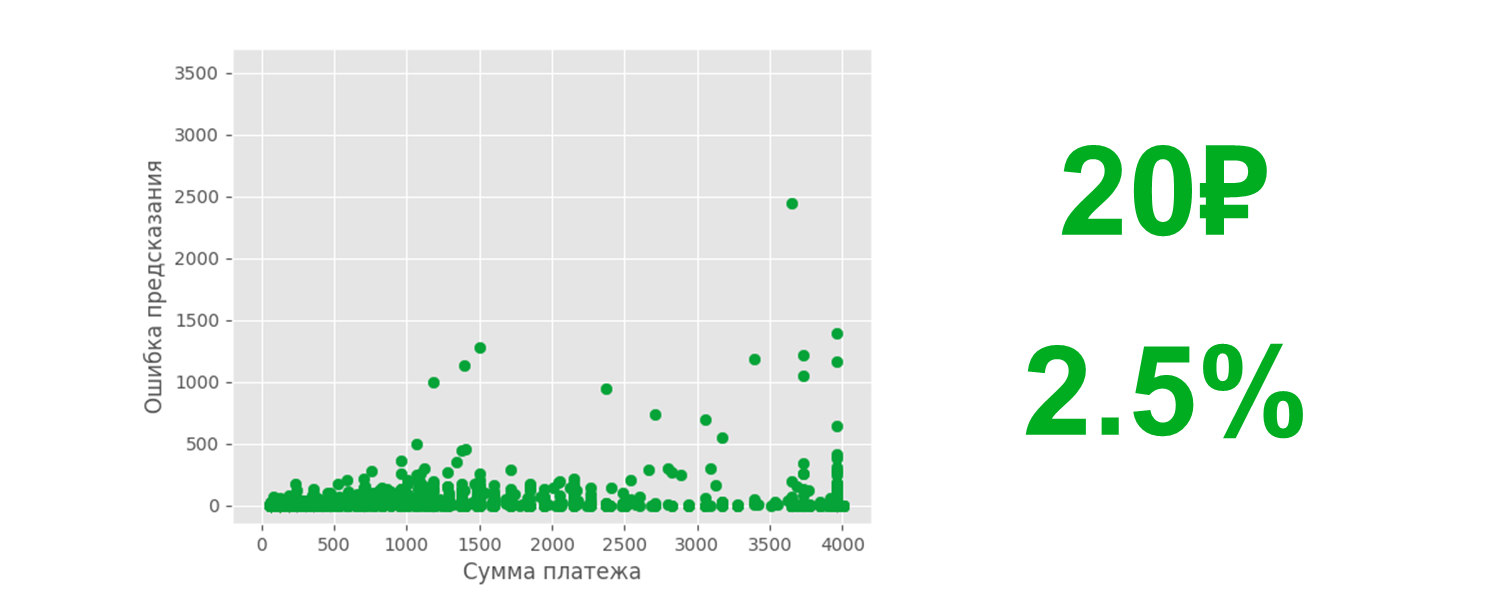
Планы. Наш следующий шаг в рамках данного кейса — взять больше данных, обучить на них модель, найти тот самый индикатор риска, который мог бы нам предсказывать вероятность внезапной невыплаты абонентом платежа, и сделать так, чтобы подобный результат получался в 100% случаев.
Кейс №3 «Рекомендательная система»

Цель — подбор оптимального тарифа и опций с целью предупреждения/профилактики снижения лояльности абонента.
Реализация. Разработали модель, которая прогнозирует потребления пользователя в последующие периоды, и на этом основании подбирает оптимальные услуги и тарифный план.
Для предобработки мы использовали логарифмирование, агрегацию данных по временным промежуткам и объединение сильно коррелирующих показателей тарифа. Это всё помогло нашей модели предсказывать ту же самую информацию, но значительно точнее.
Объединили два подхода: решающие деревья и метод градиентной оптимизации — получился градиентный бустинг. Так получилась одна из самых сильных архитектур модели для предсказания на табличных данных. В частности, взяли модель CatBoost, которая является open source архитектурой от Яндекса.
Результат. Модель была выбрана правильно. При предсказании потребления ошибка получилась в среднем меньше, чем на 1,5 рубля, 3 СМС и 5,5 МБ интернета. При этом полученные данные позволяют подбирать оптимальные пакеты услуг.
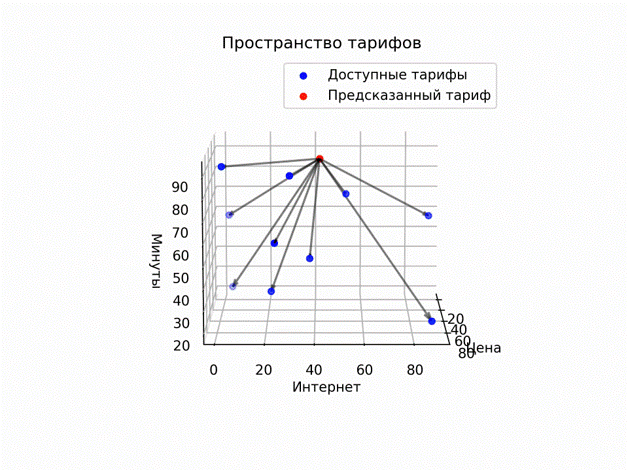
Так как у нас у оператора есть только определенный перечень тарифа для подключения — решили выводить ТОП-5 вариантов, близких к оптимальному. Для этого мы представили тариф как некую точку в пространстве и в этом же пространстве представили доступные тарифы. На рисунке красная точка — это предсказанный нами тариф, а синие точки это тарифы, которые доступны пользователю. Решили предлагать пользователю именно ближайший к этой красной точке тариф. Сравниваем тарифы так же, как точки в пространстве. В конечном счёте у нас получилось 17 моделей CatBoost, а в обучении фигурировало больше 90 различных показателей о пользователе и услугах.
Итоги проекта и перспективы
Чтобы оценить полученные решения и их масштабируемость решили провести небольшое нагрузочное тестирование. Для этого сгенерировали выборку 1 млн, 10 млн и 80 млн абонентов. Для 80 млн абонентов нам потребовалось 16Гб SSD. Время обучения в среднем составляет порядка 30 часов на 1 модель. Это совсем немного с учётом того, что модель нужно обучать раз в квартал, раз в полгода или когда паттерн поведения поменялся. Стоит отметить, что обучение модели производилось на CPU. При использовании GPU — время было бы значительно ниже.

В процессе реализации кейса мы пришли к выводу, что CARP — это платформа, на которой можно быстро и качественно реализовывать различные кейсы с машинным обучением: надо лишь предоставить данные для обучения и выбрать оптимальную из предложенных архитектур моделей. Среди возможных вариантов применения: предсказание нагрузки/трафика, отслеживание подозрительной активности, поиск оптимального времени для нотификации и многое другое.
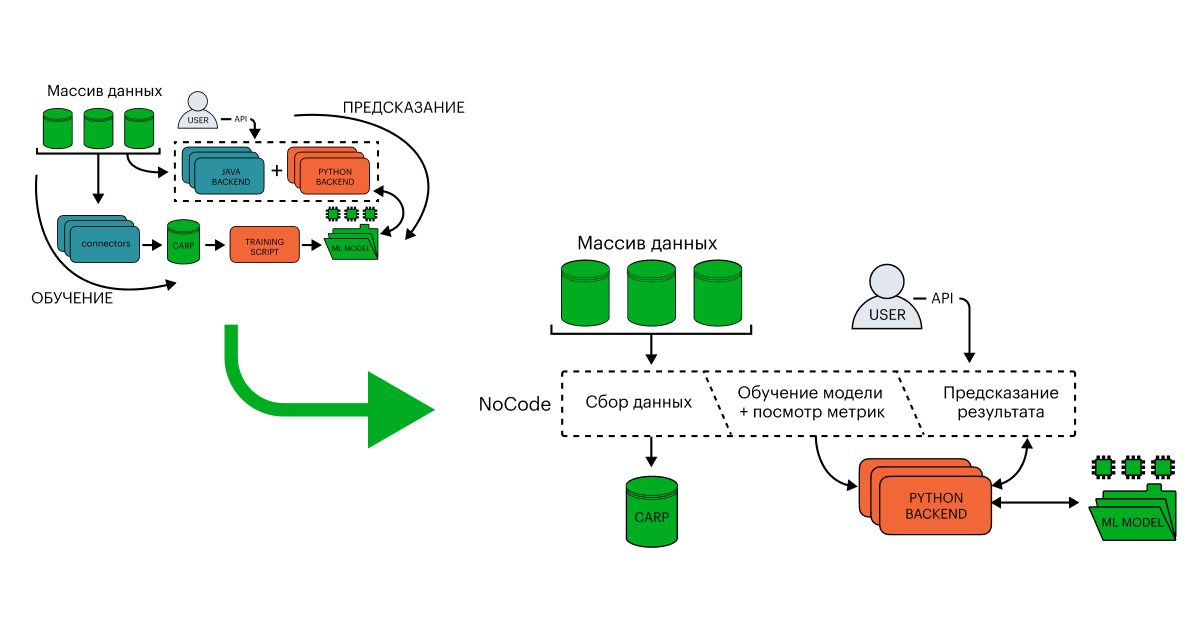
Наш следующий шаг — небольшая переработка архитектуры и добавление в решение no-code интерфейса, где с помощью обычных блоков администратор, бизнес-аналитик, специалист эксплуатации смогут использовать существующие кейсы как шаблоны или создавать абсолютно новые при помощи нескольких кликов мыши.
Резюмируем итоги двойного эксперимента. Во-первых, стажеры отлично справились с поставленной задачей, проявили самостоятельность и разработали полноценный ML-движок. Во-вторых, мы получили подтверждение, что машинное обучение может быть не только применимо, но и востребовано в телеком-секторе. Благодарим всех участников проекта и желаем им успеха: Андрея Ефремова — гуру SQL, Павла Авраменко — backend-профессионала, Михаила Степановского — специалиста по ML, Марию Антонову — мастера по координации.
