ClickHouse как бэкенд для Prometheus
Привет! Меня зовут Михаил Кажемский, я Lead DevOps в IT-интеграторе Hilbert Team. В последнее время к нам часто обращаются заказчики, которым нужна помощь с организацией хранения долгосрочных метрик в российских облаках. Так как для многих эта задача сейчас актуальная, в данной статье мы с моим коллегой Денисом Бабичевым решили рассказать, как мы используем мощные возможности ClickHouse для эффективного долгосрочного хранения метрик Prometheus.
В статье вы найдете рекомендации по использованию инструмента и описание альтернативных решений, таких как Thanos, Grafana Mimir и Victoria Metrics.
Prometheus и проблемы с LTS
Prometheus — это система мониторинга с открытым исходным кодом для сбора и хранения метрик в базах данных временных рядов (TSDB). Сервис использует достаточно простой язык запросов PromQL, который удобен как разработчикам, так и DevOps/SRE-инженерам. Prometheus уже стал отраслевым стандартом и обладает огромным комьюнити.
К Prometheus по PromQL обращаются такие сервисы, как Grafana или различные API по http-интерфейсу. Чаще всего в системе мониторинга присутствует Alertmanager — сервис отправки алертов на PagerDuty, Email, Telegram и прочие каналы.

Схема работы Prometheus
Несмотря на все преимущества, один инстанс Prometheus сможет безотказно работать только с небольшими предприятиями, которые не сталкиваются с огромными объемами данных. При повышенных нагрузках в Prometheus могут начаться сбои — из-за этого, например, Grafana может перестать показывать метрики или алерты могут потеряться.
Это происходит по следующим причинам:
TSDB Prometheus не оптимизирован для долгосрочного хранения метрик.
Отсутствие горизонтального масштабирования компонентов Prometheus.
Несмотря на то, что PromQL является достаточно простым языком запросов, он имеет ограниченные возможности по сравнению с другими языками запросов, например, SQL.
Однако LTS в Prometheus можно оптимизировать. Например, сделать несколько независимых Prometheus для каждой логической группы таргетов. Это разгрузит Prometheus и Grafana… правда, в Grafana будет показано уже несколько метрик, склейка которых окажется целой задачей. Зато после этого метрики смогут накапливаться более длительный срок и не удаляться.
Но это лишь временное решение проблемы. Поскольку Prometheus не предназначен для долгосрочного хранения данных, сервис снова может начать сбоить или потреблять слишком много ресурсов.
К сожалению, с подобной проблемой могут столкнуться все крупные предприятия. Поэтому для ее решения можно применить специальные продукты, способные без проблем хранить неограниченное число метрик Prometheus — к ним относятся Thanos, Grafana Mimir, Victoria Metrics и т.д. Кратко рассмотрим, как выглядят схемы работы с данными решениями.
Thanos
Thanos — проект с открытым исходным кодом от компании Improbable. Он предназначен для бесшовной трансформации существующих кластеров Prometheus в единую систему мониторинга с неограниченным хранилищем исторических данных.
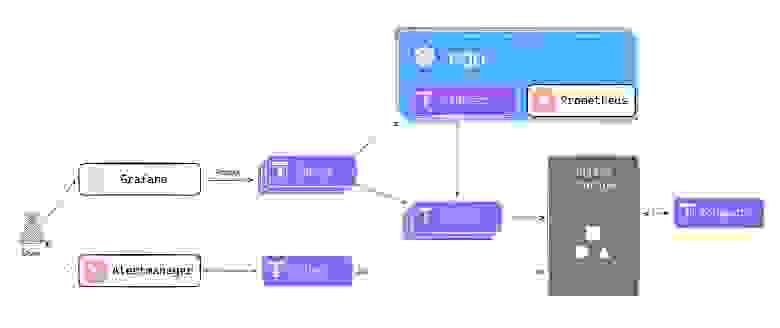
Схема работы Thanos
Рассмотрим, как устроена схема работы Thanos.
В данной схеме
Prometheusнаходится вKubernetes.В поде к
PrometheusподключаетсяSidecar-контейнерсThanos.Sidecarпишет в компонентStore, который может быть масштабируемым.Storeпишет вObject Storageпо протоколу S3.CompactоколоStorageпозволяет оптимально хранить метрики.Кроме того, есть компоненты
Queryдля получения метрик иRulerдля оценки алертов.
Grafana Mimir
Grafana Mimir — достаточно производительный, набирающий популярность инструмент от Grafana Labs. Это решение устроено немного сложнее, чем Thanos. Стоит отметить, что в Grafana Mimir почти каждый элемент горизонтально масштабируем.
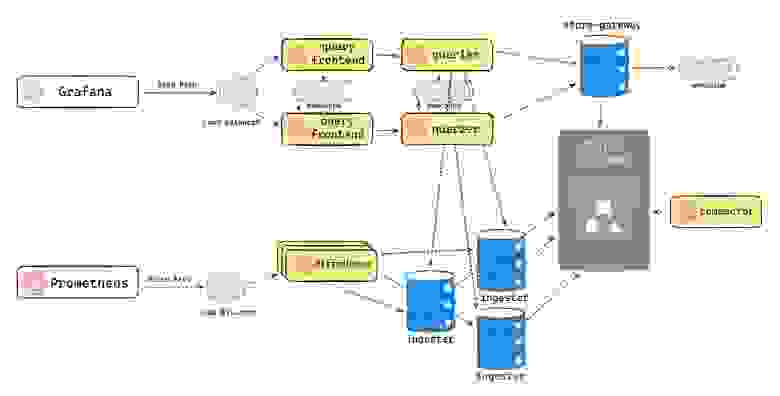
Схема работы Grafana Mimir
Рассмотрим схему по пути записи метрик:
Запросы от
Prometheusприходят наdistributors.Distributors распределяют метрики среди
ingesters.Далее
ingestersпишут метрики в Long-Term хранилище вОbject Storage.compactorоптимизирует хранение.
Чтение происходит другим каналом:
Запросы поступают через
query frontendи идут кquerier. Эти сервисы позволяют склеивать метрики от разных источников.Затем запросы попадают в
store-gateway, через который данные считываются с LT-хранилища.
Важно отметить, что queriers также обращаются и к ingesters, т.к. те отправляют свои данные в LT лишь через пару часов.
Victoria Metrics
Victoria Metrics — пожалуй, самый популярный на данный момент инструмент. Его архитектура устроена проще Mimir, при этом он не уступает по производительности и выигрывает по потреблению ресурсов.
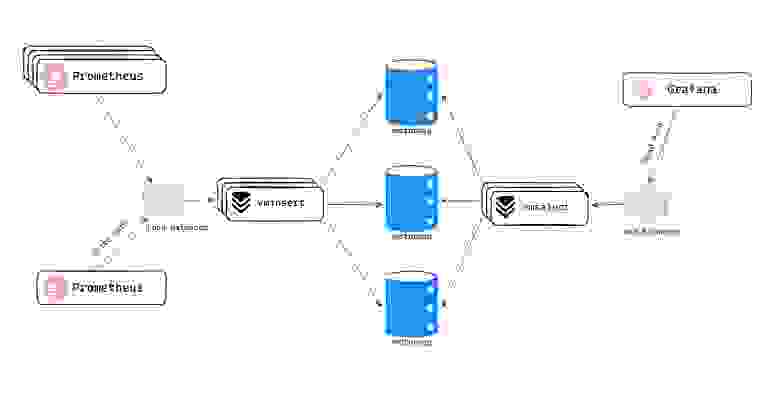
Схема работы Victoria Metrics
Victoria Metrics состоит из 3 основных компонентов:
Масштабируемый
vminsertдля записи метрик.Масштабируемый
vmstorage— оптимизированное TSDB-хранилище для долгосрочного хранения.Масштабируемый
vmselectдля получения данных из хранилища.
В этом случае используются схожие с Prometheus компоненты, однако они более масштабируемые и оптимизированные для долгосрочного хранения.
Каждый из описанных инструментов — Thanos, Grafana Mimir, Victoria Metrics — по-своему хорошо выполняет свои функции. Но в некоторых случаях для хранения долгосрочных метрик Prometheus мы используем ClickHouse. Например, если у заказчика уже есть дата-платформа, созданная на основе ClickHouse, и он хочет обогатить свои данные метриками мониторинга.
Рассмотрим подробнее, как использовать ClickHouse для этой задачи.
ClickHouse как бэкенд
ClickHouse — популярная аналитическая система управления базами данных с открытым исходным кодом. Она работает в режиме реального времени и отличается высокой производительностью. Это хорошее решение для приложений, которые используют большие объемы структурированных наборов данных. Как масштабируемая система, она поддерживает распределенную обработку запросов, разделение данных и репликацию, а также сегментирование, что делает ее способной обрабатывать терабайты информации.
Изначально ClickHouse создавался под задачи Яндекс Метрики — в основном для онлайн-отчётов по неагрегированным данным. Но благодаря своей масштабируемости, скорости и доступу к SQL, сервис отлично справляется и с задачами долгосрочного хранения метрик.
Он обладает следующими преимуществами:
ClickHouse «не тормозит».
Сам может быть ML Data Storage и создан для больших аналитических запросов.
Имеет высокую производительность и нативное горизонтальное масштабирование.
Доступен в managed-исполнении у многих облачных провайдеров.
Для решения проблемы долгосрочного хранения мониторинговых метрик Prometheus ClickHouse может предложить следующие возможности:
Шардирование. Это стратегия горизонтального масштабирования кластера, при которой части одной базы данных ClickHouse размещаются на разных группах хостов.
Распределительные таблицы. Чтобы разнести данные по разным шардам, нужно создать распределенную таблицу на движке Distributed.
Integration/Configuration
По умолчанию ClickHouse плохо интегрируется с Prometheus, поэтому для организации процесса можно использовать внешние инструменты, такие как QRYN или Carbon-Graphite.
QRYN
Отлично работает с огромным количеством метрик и прочих данных, а также успешно переносит их в ClickhHouse.

QRYN предлагает следующие возможности:
● Принимает данные в формате Prometheus, Loki, Tempo, InfluxDB, Elastic и др.
● Совместим с PromQL, LogQL, Tempo APIs.
● Использует ClickHouse как бэкенд для хранения.
QRYN настраивается достаточно просто — выбираем для него путь до ClickHouse, и он самостоятельно создает там базу данных с нужными таблицами. После этого настраиваем Prometheus на запись метрик.
Настройка сервера QRYN
# Настройка сервера QRYN
spec:
containers:
- env:
- name: CLICKHOUSE_AUTH
value:”demo:demo”
- name: CLICKHOUSE_PORT
value: ”8123"
- name: CLICKHOUSE_SERVER
value: ”clickhouse-svc”
# Настройка сервера Prometheus
remote_write:
- url: "http://qryn:3100/api/v1/remote/write"
Схема чтения и записи метрик выглядит следующим образом: Prometheus и Grafana ходят в горизонтально масштабируемый сервис QRYN, а QRYN — в ClickHouse.

Схема работы QRYN
Плюсы QRYN | Минусы QRYN |
Простая установка. | Бесплатная версия имеет ограниченную поддержку Query Range. |
Carbon-Graphite
Carbon-Graphite — это отдельная система мониторинга, отличная от Prometheus — метрики в формате Graphite имеют другой формат. Graphite используется для чтения, а Carbon — для записи метрик.

Схема работы Carbon-Graphite
Для интеграции с ClickHouse используются:
Оба инструмента написаны на Go и поддерживают вставку и чтение по формату Prometheus.
При этом для работы с Carbon нужно предварительно создать 3 таблицы, необходимые для его работы:
Первая использует движок для метрик от Graphite, который уже есть в Clickhouse.
Вторая и третья применяются для индекса и тегов (ускоряет поиск).
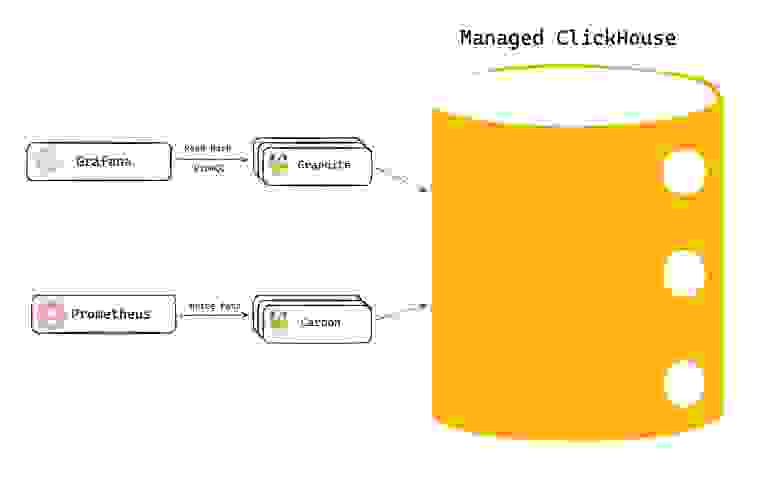
Схема работы Carbon-Graphite-ClickHouse
В итоге, выходит следующая структура:
Prometheusобращается кCarbon.Carbonпишет вClickHouse Managed.Grafanaчитает сGraphiteпо PromQL и также обращается вClickHouseза метриками.
Плюсы Carbon-Graphite | Минусы Carbon-Graphite |
Более полная поддержка PromQL и Prometheus API. | Более сложная настройка. |
Результаты тестирования Carbon-Graphite-ClickHouse
В качестве инструмента тестирования мы использовали prometheus-benchmark от Victoria Metrics и непосредственно managed кластер ClickHouse, разделенный на фронт и бэк.
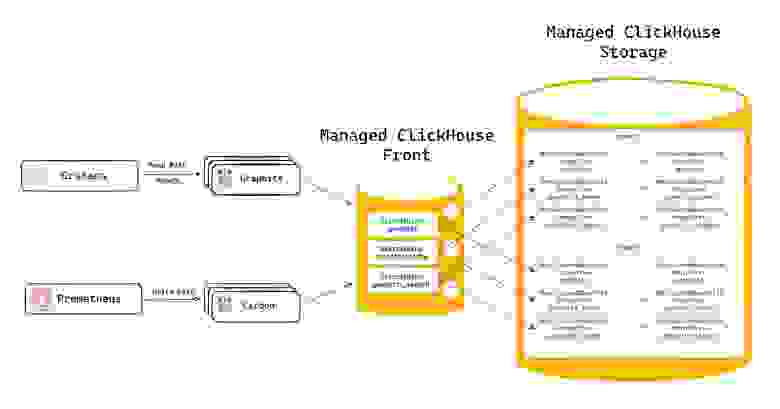
Схема Carbon-Graphite-ClickHouse для проведения тестов
Спецификации следующие:
Кластер1 (данные): 2 шарда по 2 хоста, для Replicated MergeTree таблиц.
Кластер2 (фронт-прокси): 1 хост для для Distributed MergeTree таблиц.
Каждый хост имеет по 2 RAM и 4 ГБ RAM.
Параметры бенчмарка определены как:
TargetCount — количество «виртуальных» площадок, откуда данные шлют node — экспортеры,
WriteReplicas — количество инстансов, отправляющих данные с «виртуальных» площадок. Горизонтальное масштабирование TargetCount,
WriteConcurrency — количество одновременных TCP-соединений для отправки метрик.
Результаты тестирования при разных параметрах.
Тест 1
Параметры Бенчмарка | |
TargetCount | 1000 |
WhiteReplicas | 1 |
WriteConcurrency | 8 |
Результаты на вставку | |||
CPU | RAM | Failed queries | |
Шарды | 10–13% | 25% | 0 |
Фронт | 16% | 25% | 0 |
Ingest Rate — 116k wr/s
Результаты на выборку | |||||
Запрос PromQL | |||||
node_cpu_seconds_total [10h] | sum_over_time (node_cpu_seconds_total [10h]) | ||||
CPU | RAM | Количество серий | Время выполнения | CPU | |
Шарды | Прирост 20% | Прирост 30% | 5524320 | 65 sec | Без изменений |
Фронт | Прирост 20% | Прирост 25% | Без изменений |
Тест 2
Параметры Бенчмарка | |
TargetCount | 8000 |
WhiteReplicas | 1 |
WriteConcurrency | 10 |
Результаты на вставку | |||
CPU | RAM | Failed queries | |
Шарды | Скачки До 100%. Среднее значение — 75% | В среднем — 40% на шард | В пиках до 5% |
Фронт | 45% | 35% | В пиках до 5% |
Ingest Rate — 400k wr/s
Выводы по тестам:
Высокий Ingest Rate при небольших ресурсах,
Время выборки не самое быстрое,
Компоненты Graphite-Carbon довольно ресурсоемки.
С аналогичными тестами по Victoria Metrics и Grafana Mimir вы можете ознакомиться по ссылке.
Таким образом, ClickHouse может быть неплохим вариантом для организации хранения долгосрочных метрик Prometheus. ClickHouse доступен в managed-решениях в облаках, поддерживает SQL и распределение метрик по разным шардам, что обеспечивает удобную работу с Prometheus. Все это делает ClickHouse хорошим решением для компаний, которые уже используют его в качестве основы своей аналитической инфраструктуры и хотят обогатить свою аналитику метриками Prometheus.
Полезные ссылки
