Много-агентное планирование траекторий в децентрализованном режиме: эвристический поиск и обучение с подкреплением
Привет! Меня зовут Константин Яковлев, я научный работник и вот уже более 15 лет я занимаюсь методами планирования траектории. Когда речь идет о том, чтобы построить траекторию для одного агента, то задачу зачастую сводят к поиску пути на графе, а для этого в свою очередь обычно используют алгоритм A* или какие-то из его многочисленных модификаций. Если же агентов много, они перемещаются в рабочем пространстве одновременно, то задача (внезапно) становится несколько более сложной, и применить напрямую A* не получится. Вернее, получится, но лишь для небольшого числа агентов (проклятье размерности, куда деваться). Тем не менее для централизованного случая, т.е. для случая, когда есть один (мощный) вычислитель, с которым связаны все агенты и который всё про всех знает, решить задачу много-агентного планирования можно достаточно эффективно. Можно даже находить оптимальные решения для умеренного количества агентов за относительное приемлемое время (например, порядка 1 секунды на современном десктопном PC для 30–50 агентов).
Если же говорить о децентрализованном случае, т.е. о том случае, когда агентам необходимо действовать индивидуально (например, нет устойчивой связи с центральным контроллером), опираясь лишь на собственные (локальные) наблюдения и опыт, то с хорошими решениями задачи становится гораздо сложнее. Когда я говорю «хорошие решения», я имею в виду прежде всего такие алгоритмы, которые бы давали стройные теоретические гарантии в общем случае. Хотя бы гарантии того, что каждый агент дойдёт (за конечное время) до своей цели. Тем не менее, задача интересная и специалисты из индустрии и академии её пытаются решать.
В этом посте я расскажу о наших свежих наработках в этой области, а именно о гибридном методе, которые сочетает в себе принципы классического эвристического поиска (A*) и обучения с подкреплением (PPO). Метод получился неплохим, превосходящим многие современные аналоги по результатам экспериментов, а соответствующая статья была принята на The 38th AAAI Conference on Artificial Intelligence (пока доступен только препринт). Это одна из топовых академических конференций по искусственному интеллекту, которая в этом (2024) году проходила в Канаде (спойлер: я сам визу получить не успел, но моим коллегам и соавторам, кто имел ранее выданные канадские визы, удалось принять личное участие и достойно представить нашу науку на мировом уровне).
Итак, поехали!
Предварительные сведения. Централизованный MAPF.
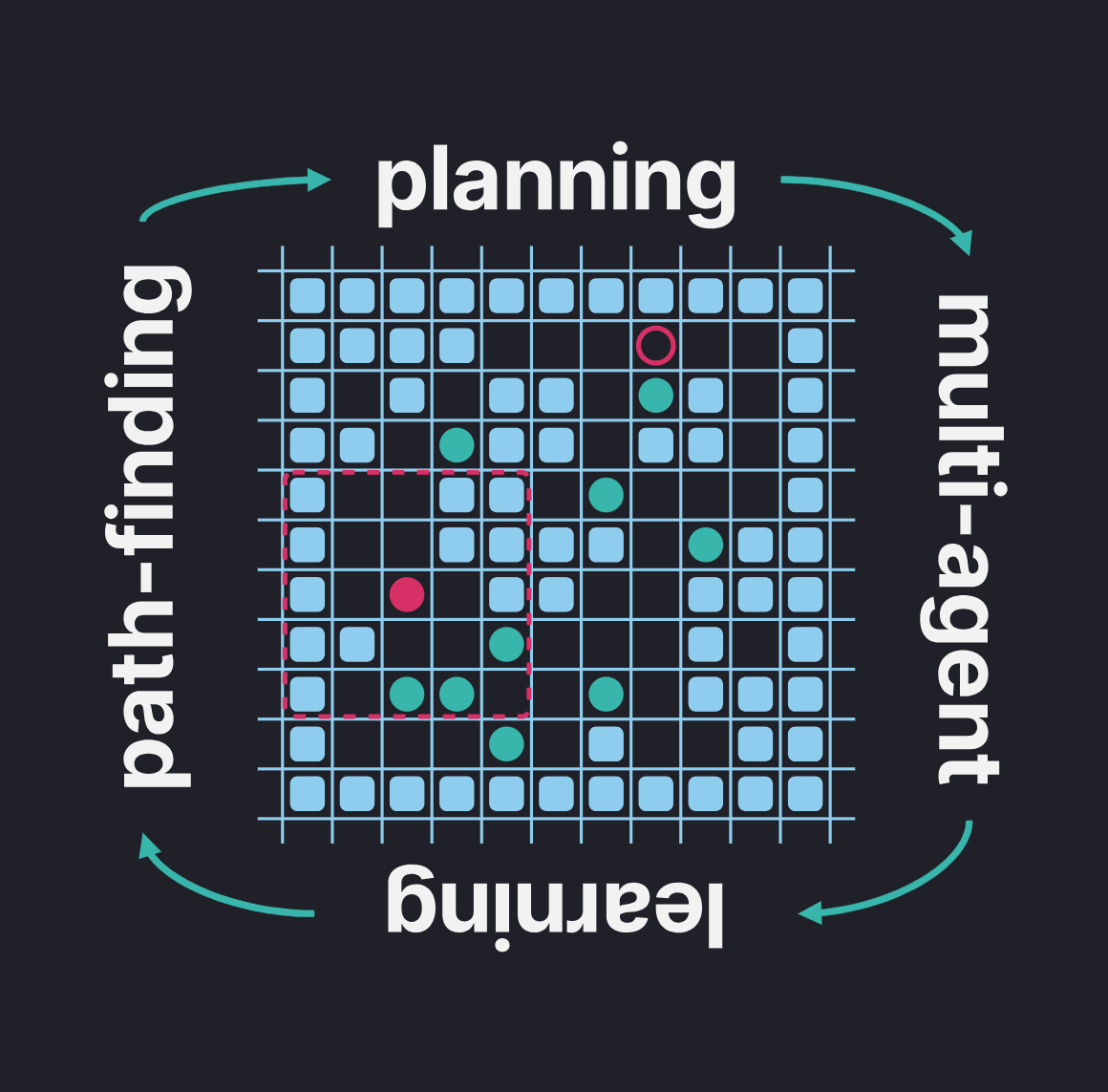
Задача, о которой пойдёт речь в посте, имеет устойчивое англо-язычное название — Multiagent Pathfinding. Сокращенно — MAPF. По‑русски мы будем её называть задачей планирования траекторий для множества агентов или же просто задачей много‑агентного планирования (подразумевая «путей» или «траекторий»). Эта задача состоит в следующем: в общем рабочем пространстве одновременно расположены n мобильных агентов, для каждого из которых известно уникальное целевое положение. Необходимо спланировать пути перемещения агентов к их целям таким образом, чтобы, во‑первых, каждый робот достигал своей цели как можно скорее, во‑вторых, чтобы запланированные пути не содержали конфликтов, т. е. агенты, следуя по ним, не сталкивались. В качестве наглядного примера, где решения такой задачи могут быть востребованы, обычно упоминают современные роботизированные склады крупных ритейлеров, логистические компании и др.


Мобильные роботы в больших количествах уже используются на крупных складах, чтобы капиталисты могли зарабатывать больше избавить человека от монотонного физического труда. GIFки нагуглены.
Тут надо сказать, что задача построения складских роботизированных систем, функционирующих 24/7, намного сложнее, чем задача MAPF. Ведь последняя является достаточно абстрактной, например, она оставляет за скобками вопрос о том, как мобильные агенты будут выполнять построенный план (нам нужно просто построить план, но не проехать по нему), почему надо двигаться именно к этим целям, а не другим и т.д. Но в общем и целом идея состоит в том, что если мы научимся хорошо решать MAPF, то и эффективные роботизированные склады (или другие роботизированные много-агентные системы) нам станет разрабатывать проще.
В академических кругах часто изучают так называемый классический MAPF (кому интересно, можно почитать соответствующую статью). Это когда рабочее пространство агентов представлено в виде неориентированного графа, время дискретно и все действия агентов синхронизированы. За один такт каждый агент может совершить действие одного из двух типов: ожидание или перемещение. Другими словами агент может либо остаться в текущей вершине графа, либо переместиться в смежную. Продолжительность и, соответственно, стоимость (вес) любого действия считается одинаковой и составляет один такт. Индивидуальный план для агента — это последовательность действий, которая переводит этого агента из начальной вершины в целевую.
Наша задача — построить общий план (т.е. по одному плану на каждого агента), который бы не содержал конфликтов. Конфликты, которых нужно избегать, бывают, как минимум, двух типов: вершинные и реберные. Название говорят сами за себя. Вершинный конфликт случается тогда, когда два (или более) агента согласно планам оказываются в одной и той же вершине в один и тот же момент времени, рёберный — когда они пытаются пройти по одному и тому же ребру в один и тот же такт. Иногда ещё накладывают дополнительные ограничения из серии «агенты не могут ходить паровозиком», но обычно всё‑таки ограничиваются вершинными и реберными конфликтами.
Качество решений задачи MAPF, т.е. качество общего плана, обычно измеряют либо как сумму времен достижений целями по всем агентам (если её поделить на число агентов, то получится такое «среднее время достижения цели»), либо как максимум по этим временам (это показывает, когда последний из агентов доехал до цели). Естественно, чем меньше, тем лучше.

Итак, что такое классическая MAPF задача нам более менее понятно. При этом, на мой взгляд, и сама задача и методы ее решения достойны отдельной статьи (или даже нескольких) на Хабре, но сегодня мы говорим немного про другое, поэтому двигаемся дальше — к lifelong варианту и децентрализованной постановке.
Децентрализованный MAPF. Lifelong вариант. Явные и неявные допущения.
Lifelong MAPF — это MAPF, в котором каждому агенту, после того как он достиг цели, сразу же назначается следующая, и теперь он должен двигаться к ней. Очевидно, что в таком режиме агенты могут перемещаться без конца и края, поэтому целесообразно ввести понятие эпизода. Другими словами мы задаем ограничение по времени tmax и после этого шага эпизод прекращается (где-бы ни находились агенты).
Что касается оценки качества решения, то в lifelong MAPF обычно считают пропускную способность (англ. throughput), т.е. среднее число достигаемых целей за такт времени. Формально это записывается как: Ngoals/tmax, т.е. мы делим общее число достигнутых целей (по всем агентам) на длину эпизода. Чем больше, чем лучше.
Заметим, что для нас как для исследователей неважно (как и раньше) откуда берутся цели. Для простоты и повторяемости экспериментов мы считаем, что для каждого агента случайным образом до начала эпизода сгенерирована последовательность целей. При этом в ходе эпизода каждую следующую цель агент узнает только тогда, когда достигает текущую.

Мини-пример того, как выглядит Lifelong MAPF. После достижения цели агенту сразу выдается новая.
Переходим теперь к самой интересной части — децентрализации. Если раньше мы полагали, что у нас есть некий центральный вычислитель, который в каждый момент знает всё про всех агентов (их положения, цели, спланированные траектории и т.д.), то теперь будем считать, что его нет. Остались только агенты и надо определиться, что они знают об окружающем мире.
Предположение 1. Каждый агент знает всю карту статических препятствий (например, мы загрузили в каждого робота план складских помещений), знает свое положение в ней и свою (текущую) цель.
Предположение 2. Каждый агент имеет ограниченный радиус видимости, внутри которого он может видеть других агентов (=знать их положение). За пределами этого радиуса видимости других агентов «наш» агент не видит. На практике, агенты обычно перемещаются по клетчатому полю, и их радиус видимости это область nxn клеток вокруг агента (например, 5×5 или 11×11).

Агент с близорукостью ограниченной областью наблюдения.
Предположение 3. Агенты кооперативны и гомогенны. То есть каждый агент вправе считать, что другие агенты, во-первых, не имеют своей целью помешать ему, во-вторых, действуют по тем же алгоритмам, что и он сам.
Часто также предполагают, что агенты могут локально обмениваться информацией, например о том, кто к какой цели идёт. У нас в работе нет такого предположения (и это не мешает нам успешно справляться с задачей).
Задача теперь ставится следующим образом: необходимо сконструировать стратегию выбора действий агентом, которая на каждом шаге будет говорить, что делать (ждать на месте, идти, если идти, то куда). Формально, стратегию можно определить как функцию:

Здесь τ — это история взаимодействия агента со средой в текущем эпизоде (т. е., что он уже видел, какие действия уже совершал и т. д.), а P (a) — это распределение вероятности на действиях. То есть на выходе мы хотим получить не столько полностью однозначный ответ типа «иди влево», сколько оценку вероятности для каждого действия: «иди влево — 0.6», «стой на месте — 0.3» и т. д. Тогда на каждом шаге агент будет семплировать из этого распределения и уже это действие совершать в среде.
Если вы подумали сейчас, что это всё очень похоже на (частично-наблюдаемые) марковские процессы принятия решение (в англ. варианте — (PO)MDP), то вы абсолютно правы, это оно и есть, но в этом посте не хочется грузить терминологией.
Важно заметить, что поскольку у нас есть допущение 3 (которое обычно подразумевается в MAPF задачах «по умолчанию» и явно даже не проговаривается в статьях), то нам достаточно одной стратегии на всех. То есть, после того как стратегия нами как-то сконструирована, мы загружаем копию этой стратегии в каждого из агентов и весь коллектив оживает.

Вот примерно так один агент загружает копию своей стратегии другому агенту.
Окей. Задача более менее ясна, давайте теперь её решать.
Ищем пути решения
Давайте подумаем, как вообще можно решить нашу задачу. Ну во-первых, можно, наверное, прописать какую-то систему правил, по которой каждый агент будет двигаться. Что-то в духе «делай шаг по кратчайшему пути к цели, но если видишь, что на тебя движется другой агент, то отойди в сторону и подожди один такт». Проблема с таким подходом очевидна. Стройную систему правил будет придумать непросто, скорее всего правил будет много, почти всегда будут какие-то исключения и так далее. С другой стороны, можно зайти так: у нас же XXI век на дворе, дип лёнинг, биг дата и все дела. Давайте обучим нейросеть, и она будет говорить, что делать в той или иной ситуации. Тот тип задач, что мы решаем, когда агент интерактивно взаимодействует со средой (перемещается в ней, достигает целей и прочее), вполне замечательно укладывается в то, что зовется обучением с подкреплением (reinforcement learning, RL). Именно этот тип обучения обычно используется, когда хочется научить компьютер играть в шахматы, го, старкрафт и прочее. И мы (современная наука и программная инженерия) умеем решать указанные игровые задачи весьма неплохо, а иногда даже очень и очень хорошо (даже лучше человека).

Однако и с обучаемыми подходами, тоже есть проблемы, когда мы говорим именно о задаче MAPF. Во-первых, у нас нестационарная с точки зрения агента среда, т.е. на то, какой получится результат (дойдёт ли агент до цели или застрянет в каком-то закутке карты) влияют другие агенты, которые частью собственно среды не являются, а имеют собственные цели, которые им надо достигать. Во-вторых, у современных методов глубокого обучения с подкреплением (deep reinforcement learning, DRL) не всё гладко с генерализацией. То есть они обычно хорошо решают задачи, которые похожи на те, что встречались на этапе обучения, но если попадается какая-то непохожая задача, то результат может быть так себе. В нашем случае мы хотим, чтобы агенты (как по отдельности, так и в совокупности) хорошо себя вели на картах разного размера, с разным расположением статических препятствий, разным количеством агентов и др. В общем нам нужна стратегия, которая хорошо генерализуется. Не то, чтобы указанные проблемы прямо совсем не решались современным DRL, просто обучать «в лоб» нам придется мучительно и долго. Поэтому возникает мысль пойти несколько другим путём.

Когда увидел, сколько времени и ресурсов потребуется, чтобы обучить «в лоб»
Другой путь — это комбинация классических эвристических подходов и подходов обучаемых. Не мы первые придумали применять такой гибридный подход для решения сложных задач и задач MAPF в частности, но мы сделали это по-своему, и у нас получилось весьма неплохо (по крайней мере, на фоне известных мировых аналогов, с которыми мы сравнивались).
Кстати раньше на Хабре я уже рассказывал, как комбинация машинного обучения и эвристического поиска помогает решать задачу в классической одно-агентной постановке. Кому и эта тема тоже интересна — можно посмотреть тут.
Наш подход: учись следовать
Первый ингредиент нашего подхода — классический алгоритм эвристического поиска (кратчайшего) пути A*. Второй — обучаемая стратегия следования вдоль этого пути и кооперативного избегания столкновений. Поэтому мы и назвали наш метод «Учись следовать», «Learn to Follow» или, сокращенно, просто Follower. По‑русски получается «Следователь», но мы наш подход называли между собой просто Фоловер) (с одной «л» и ударением на второй слог).
Работает Фоловер следующим образом. Агент с помощью A* строит путь до цели, игнорируя других агентов. Затем локальный фрагмент этого пути, а также дополнительная локальная информация (положение препятствий и других агентов) передаются на вход обучаемой стратегии, которая, собственно, и определяет как следует действовать агенту. Схематично это выглядит так.

Большая и страшная красивая схема нашего подхода. Агент (тот, за которого мы сейчас решаем) отмечен красным кружком на карте слева. Его глобальный путь до цели показан маленькими пустыми кружочками. Этот путь + положение статических препятствий в области видимости образуют первый канал локального наблюдения (левая матрица 5×5 в центре картинки). Второй канал (правая матрица) кодирует текущее положение самого агента и тех агентов, что он видит. Такое двухканальное наблюдение передается на вход нейросети, одна голова которой (актор) говорит, что агенту делать, а другая — критикует его за это (критик используется только на этапе обучения, чтобы помочь актору научиться вести себя правильно). В верхней части по центру изображен модуль планирования, который строит глобальный путь до цели с использованием специальной тепловой карты, которая помогает прокладывать маршрут по менее загруженным частям карты.
Более детальное академическое описание этой схемы и подхода в целом можно найти собственно в статье, здесь я постараюсь объяснить (насколько возможно просто) лишь самые важные моменты.
Строим путь до цели мы с помощью A*, но при этом используем модифицированную карту стоимости переходов (на рисунке выше она показана в виде тепловой карты: чем краснее клетка, тем выше стоимость перехода в соответствующую клетку). Это нам нужно для того, чтобы лучше рассеять агентов по карте и уменьшить вероятность заторов, из которых весьма сложно выпутываться в децентрализованном режиме. Делаем мы это следующим образом. Тем клеткам, в которых мы часто видели других агентов мы добавляем некоторый штраф. Также штраф добавляем тем клеткам, которые чисто статистически чаще других встречаются в кратчайших путях (для этого мы пре-процессим карту, рассчитывая пути между всеми парами вершин). В итоге наш агент ищет не кратчайший в геометрическом смысле путь, а такой путь, который бы снижал вероятность встречи с толпой других агентов (как показали наши эксперименты подобная техника «разведения агентов по карте» вносит весьма существенный вклад в практическую эффективность нашего подхода).

Избегание встречи с другими агентами 80 lvl
Ок. Путь у нас есть, давайте учится следовать вдоль него, избегая при этом столкновений с другими агентами. В качестве обучаемого метода движения мы выбрали весьма известный в мире обучения с подкреплением нейросетевой метод Proximal Policy Optimization (PPO), который был впервые предложен коллегами из OpenAI. Это метод типа актор‑критик, т. е. на этапе обучения одна часть стратегии, актор, учится выбирать действия, другая часть, критик, учится оценивать состояния среды (т. е. учится «критиковать» первую часть за то, что она завела в нас в то или иное состояние). Реализуется это всё естественно на нейросетях, т. е. у нас есть некоторые общие входные слои, которые ответственны за агрегацию и обработку входных данных и затем две головы: актор и критик. После обучения сеть критика предсказуемо не используется. Стоит также заметить, что изначально PPO подразумевает полную наблюдаемость среды агентом. В нашем случае это не так (у нас только частичная наблюдаемость), поэтому мы также задействует RNN‑блоки, которые расположены между блоками обработки наблюдений и блоками актора/критика. RNN‑блоки призваны наделить нашего агента «памятью» и способностью аппроксимировать состояние среды по истории локальных наблюдений.
Обучается наш PPO с использованием техники policy sharing, т. е. все агенты, задействованные в обучении, используют (и обновляют) одни и те же веса нейросети. Так можно делать, потому что у нас есть предположение о том, что агенты гомогенны и кооперативны, о чём упоминалось выше. Награда при обучении дается агенту при достижении точки на пути к глобальной цели. Мы экспериментировали с разными вариантами того, как далеко должна находиться подцель от агента. В результате экспериментов, лучше всего себя показала стратегия, которая училась достигать первую (ближайшую) клетку на пути к цели. Как говорится, всё эффективное — просто. Тут важно сделать оговорку, что мы (как и многие другие исследователи) предполагаем, что если два агента хотят сходить в одну клетку или поменяться местами, то у них ничего не выйдет. Поэтому просто «жадно идти по своему пути» зачастую невыгодно — не получишь награды. Из‑за этого агенты вынуждены учиться кооперации и они таки ей учатся — см. например следующую гифку:
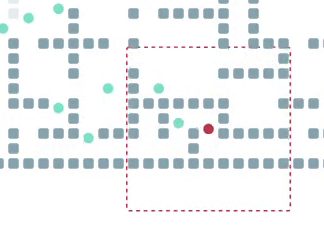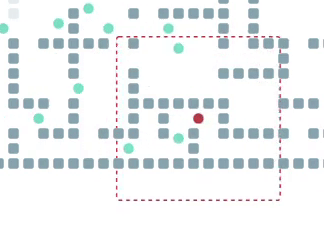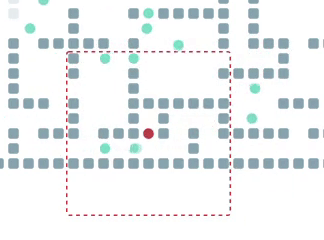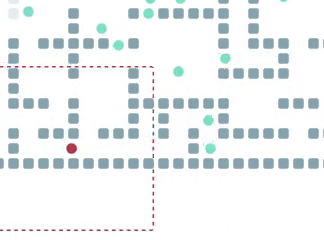
Обратите внимание на то, как агенты внизу используют пространство, чтобы разойтись (пусть и не сразу) в узком коридоре. Достичь такой кооперативности в децентрализованном режиме (да ещё и без обмена информацией) весьма непросто, но наш Фоловер, как видно, справляется.
Эксперименты
Для экспериментального исследования методов обучения с подкреплением (чистых или гибридных, как у нас, не столь важно) нужна программная модель среды. Желательно, чтобы она была совместима с некоторым общепризнанным в мире обучения с подкреплением API (Gym, Gymnasium и вот это вот всё, если вам это о чём‑то говорит). Мы в качестве такой среды использовали среду POGEMA, которую сами ранее и разработали, потому что других эффективных и удобных сред, заточенных под MAPF задачи просто не существовало. Благодаря POGEMA у нас эффективно работал из коробки весь цикл обучения и валидации (плюс сбор статистики и визуализация), что существенно ускорило процесс получения собственно результатов. Кому интересно заниматься подобными задачам всячески рекомендую нашу POGEMA — заходите на гитхаб, клоньте, форкайте, ставьте звездочки и так далее.
Для экспериментов в POGEMA мы подготовили две версии нашего Фоловера: стандартную и легкую. Легкая отличается тем, что в ней существенно урезана нейросеть (например, полностью опущены RNN‑блоки и не только): меньше 4 тысяч параметров (совсем мизер по текущим меркам) против 5 миллионов (тоже немного на самом деле) у стандартного Фоловера. Также легкий Фоловер для пущей эффективности был полностью реализован на С++, в то время как стандартный — на смеси C++ (для вещей не связанных с нейросетями) и Python (для нейросетей).
Сравнивались мы в первую очередь с современными обучаемыми методами, заточенными на решение задачи децентрализованного много‑агентного планирования, в том числе с такими широко‑известными в узком сообществе методами, как Primal2 (2021), PICO (2022), SCRIMP (2023). И сравнение оказалось в нашу пользу — у нас лучше пропускная способность (т. е. достигается больше целей в единицу времени) и выше способность к генерализации, т. е. Фоловер лучше работает на картах, отличных от тех, что видел на этапе обучения. На графиках это выглядит примерно вот так.

Слева и справа показаны карты, на которых мы проводили тестирование (на самом деле не только на них, но не суть). По центру — графики показывающие эффективность метода. По оси OY отложены значения пропускной способности (чем выше тем лучше), по оси OX — число агентов на карте. Каждая линия на карте — это сравниваемый метод. Звездочка в легенде — это отметка о том, что обучение этого метода проходило на этом типе карт (например наш Фоловер при обучении видел только карты типа лабиринтов, как справа, но не случайные карты, как слева). Эти графики наглядно показывают, что наш метод лучше конкурентов.
В статье у нас больше картинок и деталей. Если они вам интересны рекомендую заглянуть в публикацию.
Мы также ради спортивного интереса сравнились с централизованными подходами к MAPF, которые видят всех агентов и планируют централизованно за всех. У одного из наиболее распространенных современных централизованных планировщиков, RHCR (2021), предсказуемо получается более высокое качество решений (частота достижения целей выше). Однако у него наблюдаются заметные проблемы с масштабированием. Если агентов много, а время на планирование ограничено (порядка 1 секунды в наших экспериментах), то он начинает заваливаться. Это наглядно показывает, что децентрализованные подходы имеют свою нишу. Тут надо честно заметить, что есть и более простые централизованные методы, например PIBT (с ним мы тоже сравнивались), которые отрабатывают очень быстро, но качество их решений, хуже чем у Фоловера. т. е., опять же, децентрализованные подходы зачастую могут обыгрывать централизованные (у которых априори больше информации об окружающей среде и всех агентах).
Ещё у нас были т. н. ablation studies, это когда мы не сравниваем наш метод с другими, а отключаем какие‑то компоненты нашего подхода и смотрим на результат. Эти эксперименты показали, что если отключить метод распределения агентов по карте (модификация стоимостей перехода в A*), то также качество падает. Если выкинуть из Фоловера обучаемую стратегию (т. е. сказать агентам — идите просто по A* путям), то качество также существенно просаживается — см. график ниже.

Результаты тестирования Фоловера с выключением различных функциональных блоков (на карте складского типа). Синий график — Фоловер. Красным и зеленым показано, что будет если отключить нашу технику распределения агентов по карте при построении маршрута (становится хуже — пропускная способность падает). Фиолетовый график — это Фоловер без обучаемой стратегии, т. е. агенты просто планируют пути и всегда идут по ним (пока не упрутся в других таких агентов‑эгоистов). Как видно, этот вариант вообще аховый, пропускная способность сильно хуже, да ещё и падает с числом агентов.
В общем, эксперименты подтвердили, что у нас получился отличный гибридный метод децентрализованного много‑агентного планирования (в lifelong постановке), который превосходит по эффективности решения задач многих современных мировых конкурентов и даже может тягаться по соотношению «цена‑качество» с централизованными подходами.
А как оно было в Канаде
Новость о том, что статья по описанному методу принята на конференцию AAAI»24 пришла в середине ноября 2023. Сама конференция — в конце февраля 2024, в Канаде. Готовой визы в Канаду у меня не было, я начал ее оформлять, но не успел. Хорошо, что у двух из пяти соавторов нашей статьи уже были канадские визы, полученные ранее (они в 2019 году ездили на NeurIPS). Поэтому голос Российской Науки на конференцию звучал. Причем в прямом смысле. Дело в том, что на AAAI»24 было подано около 12 тысяч докладов а, принято около 2300 докладов. Это с одной стороны мало относительно первоначального количества, с другой стороны — это слишком много, чтобы выделить каждому докладу время на устную презентацию, с учетом того, что основной научный трек конференции идет всего 3 дня. Поэтому обычно на таких масштабных конференциях выбирают небольшое число работ (порядка 10%) для устных докладов, а остальные представляются в виде постеров. Наша статья попала в эти самые 10%, и по ней был сделан устный доклад. Ура!
Прикреплю в завершении некоторые фотографии (с комментариями) с конференции.

Первый соавтор статьи Алексей Скрынник делает доклад по нашей работе в одном из залов конгресс-центра Ванкувера. Слева, за стеклянной стеной видно залив, куда периодически приводняются небольшие гидросамолеты. Их хорошо слышно, и слушатели обычно отвлекаются в этот момент.

Тот самый гидросамолет (один из многих).

Вот в таком конгресс-центре проходила конференция.

А вот так выглядит постерная сессия. Это когда на стенку вешает эдакая статическая оффлайн мини-презентация статьи (постер), автор стоит рядом и общается с коллегами, объясняя интересующимся, что деньги налогоплательщиков мы потратили на решение вот такой вот интересной головоломки наша разработка — это передовой край современной науки. Если кто-то внимательный заметил, что название постера не совпадает с названием статьи, про которую собственно и написан пост, то объяснение этому — чуть ниже.
Вместо PS: (интересно, дочитал ли кто-то до этого места?)
Вообще на AAAI»24 у нас была принята не одна, а целых три работы по много-агентному планированию. Две про децентрализованную постановку (про одну я рассказал в этом посте, про другую — уже не хватило места), и одна про централизованную, но интересную, когда агенты могут меняться местами, т.е. нам не важно какой агент какую цель достигнет (главное, чтобы все цели были покрыты). Когда и если у меня будет очередной прилив графоманского настроения (и время), то и про эти работы я расскажу на Хабре. Пока же просто оставлю ссылки на сами статьи для интересующихся: раз и два.
