Дружим Prometheus с Caché
Она достаточно проста в инсталляции и первоначальной настройке. Имеет встроенную графическую подсистему для отображения данных PromDash, однако сами же разработчики рекомендуют использовать бесплатный сторонний продукт Grafana. Prometheus умеет мониторить много чего («железо», контейнеры, различные СУБД), однако в данной статье хотелось бы остановиться на реализации мониторинга инстанса Caché (точнее, инстанс будет Ensemble, но метрики будем брать кашовые). Кому интересно — милости просим под кат.

В нашем простейшем случае Prometheus и Caché будут жить на одной машине (Fedora Workstation 24×86_64). Версия Caché:
%SYS>write $zv
Cache for UNIX (Red Hat Enterprise Linux for x86–64) 2016.1 (Build 656U) Fri Mar 11 2016 17:58:47 EST
Инсталляция и настройка
Качаем с офсайта подходящий дистрибутив Prometheus и сохраняем в каталог /opt/prometheus.
Распаковываем архив, правим имеющийся шаблонный конфиг согласно нашим нуждам и стартуем Prometheus. По умолчанию, Prometheus будет писать логи своей работы прямо в консоль, поэтому мы перенаправим записи о его активности в лог-файл.
/opt/prometheus
# ls
prometheus-1.4.1.linux-amd64.tar.gz
# tar -xzf prometheus-1.4.1.linux-amd64.tar.gz
# ls
prometheus-1.4.1.linux-amd64 prometheus-1.4.1.linux-amd64.tar.gz
# cd prometheus-1.4.1.linux-amd64/
# ls
console_libraries consoles LICENSE NOTICE prometheus prometheus.yml promtool
# cat prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
scrape_configs:
— job_name: 'isc_cache'
metrics_path: '/metrics/cache'
static_configs:
— targets: ['localhost:57772']
# ./prometheus > /var/log/prometheus.log 2>&1 &
[1] 7117
# head /var/log/prometheus.log
time=»2017–01–01T09:01:11+02:00» level=info msg=«Starting prometheus (version=1.4.1, branch=master, revision=2a89e8733f240d3cd57a6520b52c36ac4744ce12)» source=«main.go:77»
time=»2017–01–01T09:01:11+02:00» level=info msg=«Build context (go=go1.7.3, user=root@e685d23d8809, date=20161128–09:59:22)» source=«main.go:78»
time=»2017–01–01T09:01:11+02:00» level=info msg=«Loading configuration file prometheus.yml» source=«main.go:250»
time=»2017–01–01T09:01:11+02:00» level=info msg=«Loading series map and head chunks…» source=«storage.go:354»
time=»2017–01–01T09:01:11+02:00» level=info msg=»23 series loaded.» source=«storage.go:359»
time=»2017–01–01T09:01:11+02:00» level=info msg=»Listening on:9090» source=«web.go:248»
Конфиг prometheus.yml описывается на языке YAML, не любящем табуляций, использовать нужно только пробелы. Выше мы указали, что метрики будем тянуть с адреса http://localhost:57772 и опрашивать будем приложение /metrics/cache (имя приложения выбрано произвольно), т.е. конечный адрес для сбора метрик будет http://localhost:57772/metrics/cache. К каждой метрике будет дописываться метка «job=isc_cache». Метка — очень грубо говоря, это аналог WHERE для SQL. В нашем случае использоваться она не будет, но для числа серверов, больше одного, очень даже сгодится. Например, имена серверов (и/или инстансов) можно сохранять в метках и в дальнейшем метками параметризировать запросы для отрисовки графиков. Проверим, что Prometheus заработал (выше в выводе мы видим порт, который он прослушивает — 9090):
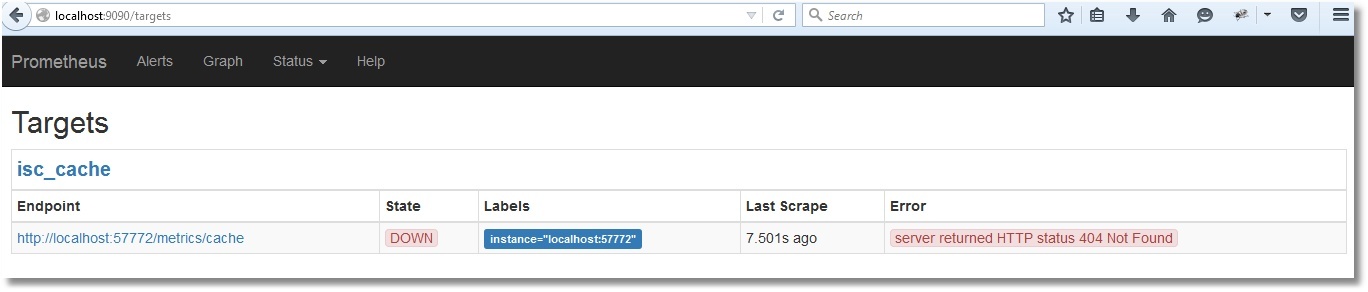
Открылся веб-интерфейс, стало быть, Prometheus работает. Однако метрик Caché он пока что, естественно, не видит (проверим, нажав Status → Targets):
Подготовка метрик
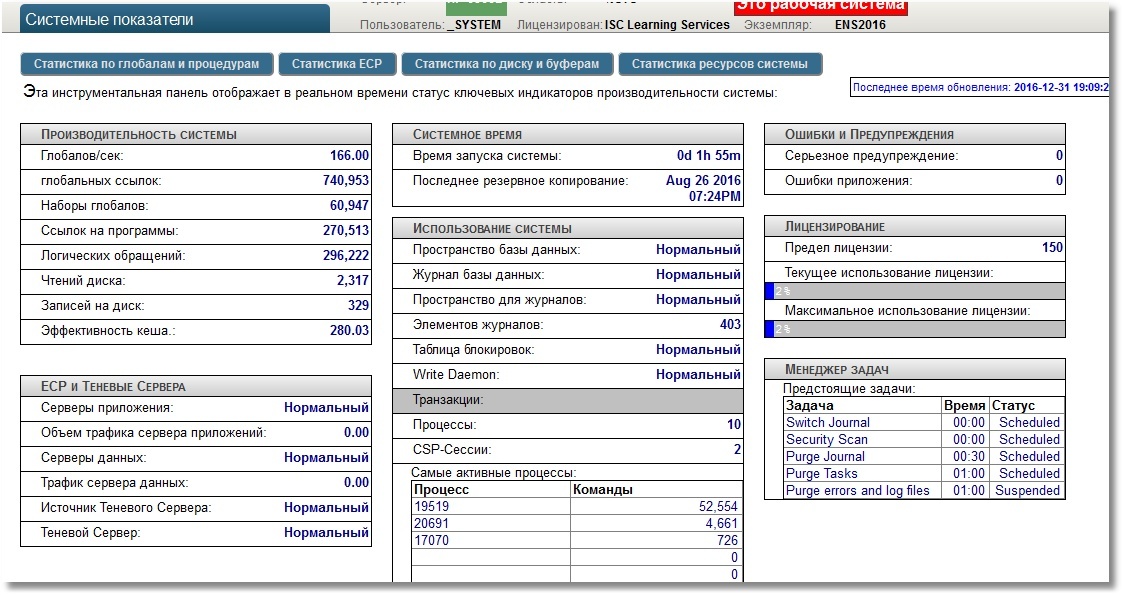
Наша задача — сделать так, чтобы по адресу http://localhost:57772/metrics/cache можно было стянуть метрики в понятном для Prometheus виде. Будем использовать REST-возможности Caché в силу их простоты. Сразу отметим, что Prometheus «понимает» только метрики числовые, так что строковые метрики экспортировать не будем. Для получения тестовых метрик будем использовать API класса SYS.Stats.Dashboard. Эти метрики используются самой Caché для отображения Системной панели инструментов:
%SYS>zwrite dashboard
dashboard=
Песочницей будет служить область USER. Для начала создадим REST веб-приложение /metrics. Для хоть какой-то безопасности укажем вход в приложение по паролю, также укажем, что соответствовать этому веб-приложению будет некий ресурс, назовем его PromResource. В ресурсе закроем публичный доступ. То есть сделаем следующее:
%SYS>write ##class (Security.Resources).Create («PromResource», «Resource for Metrics web page»,»)
1
Настройки нашего веб-приложения:
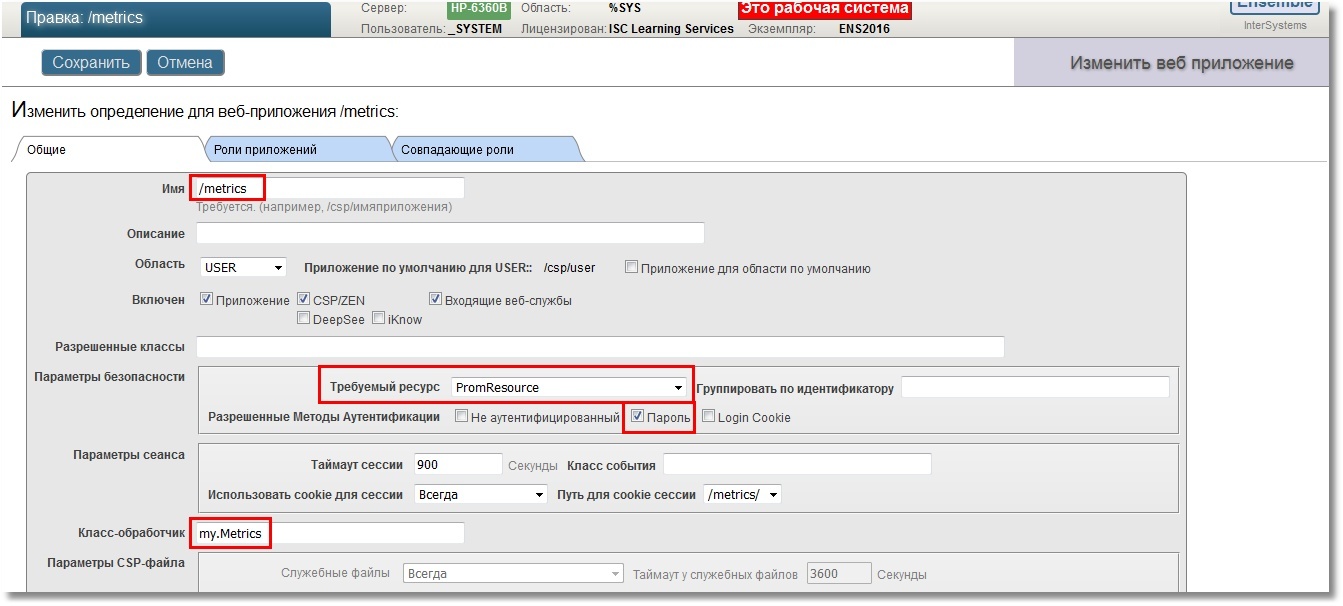
Нам нужен будет пользователь, имеющий возможность использовать этот ресурс. Также пользователь должен иметь права на чтение рабочей базы (в нашем случае, USER) и запись в нее. Помимо этого, ему понадобится право на чтение системной базы CACHESYS, поскольку ниже в коде реализации мы будем переходить в область %SYS. Будем следовать стандартной схеме, т.е. создадим роль PromRole c этими возможностями, после чего создадим пользователя PromUser с этой ролью. Пароль выберем, например, «Secret»:
%SYS>write ##class (Security.Roles).Create («PromRole», «Role for PromResource», «PromResource: U,%DB_USER: RW,%DB_CACHESYS: R»)
1
%SYS>write ##class (Security.Users).Create («PromUser», «PromRole», «Secret»)
1
Именно этого пользователя PromUser мы укажем для аутентификации в конфиге Prometheus. После чего перечитаем конфиг путем посылки процессу сервера сигнала SIGHUP.
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
scrape_configs:
— job_name: 'isc_cache'
metrics_path: '/metrics/cache'
static_configs:
— targets: ['localhost:57772']
basic_auth:
username: 'PromUser'
password: 'Secret'
#
# kill -SIGHUP $(pgrep prometheus) # or kill -1 $(pgrep prometheus)
Теперь Prometheus может успешно пройти аутентификацию для использования веб-приложения с метриками.
Метрики нам будет отдавать класс-обработчик REST-запросов my.Metrics.
Class my.Metrics Extends %CSP.REST
{
Parameter ISCPREFIX = "isc_cache";
Parameter DASHPREFIX = {..#ISCPREFIX_"_dashboard"};
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
}
/// Output should obey the Prometheus exposition formats. Docs:
/// https://prometheus.io/docs/instrumenting/exposition_formats/
///
/// The protocol is line-oriented. A line-feed character (\n) separates lines.
/// The last line must end with a line-feed character. Empty lines are ignored.
ClassMethod getMetrics() As %Status
{
set nl = $c(10)
do ..getDashboardSample(.dashboard)
do ..getClassProperties(dashboard.%ClassName(1), .propList, .descrList)
for i=1:1:$ll(propList) {
set descr = $lg(descrList,i)
set propertyName = $lg(propList,i)
set propertyValue = $property(dashboard, propertyName)
// Prometheus supports time series database
// so if we get empty (for example, backup metrics) or non-digital metrics
// we just omit them.
if ((propertyValue '= "") && ('$match(propertyValue, ".*[-A-Za-z ]+.*"))) {
set metricsName = ..#DASHPREFIX_..camelCase2Underscore(propertyName)
set metricsValue = propertyValue
// Write description (help) for each metrics.
// Format is that the Prometheus requires.
// Multiline descriptions we have to join in one string.
write "# HELP "_metricsName_" "_$replace(descr,nl," ")_nl
write metricsName_" "_metricsValue_nl
}
}
write nl
quit $$$OK
}
ClassMethod getDashboardSample(Output dashboard)
{
new $namespace
set $namespace = "%SYS"
set dashboard = ##class(SYS.Stats.Dashboard).Sample()
}
ClassMethod getClassProperties(className As %String, Output propList As %List, Output descrList As %List)
{
new $namespace
set $namespace = "%SYS"
set propList = "", descrList = ""
set properties = ##class(%Dictionary.ClassDefinition).%OpenId(className).Properties
for i=1:1:properties.Count() {
set property = properties.GetAt(i)
set propList = propList_$lb(property.Name)
set descrList = descrList_$lb(property.Description)
}
}
/// Converts metrics name in camel case to underscore name with lower case
/// Sample: input = WriteDaemon, output = _write_daemon
ClassMethod camelCase2Underscore(metrics As %String) As %String
{
set result = metrics
set regexp = "([A-Z])"
set matcher = ##class(%Regex.Matcher).%New(regexp, metrics)
while (matcher.Locate()) {
set result = matcher.ReplaceAll("_"_"$1")
}
// To lower case
set result = $zcvt(result, "l")
// _e_c_p (_c_s_p) to _ecp (_csp)
set result = $replace(result, "_e_c_p", "_ecp")
set result = $replace(result, "_c_s_p", "_csp")
quit result
}
}В консоли проверим, что наши труды не прошли зря (добавлен ключ --silent, чтобы curl не мешал своим прогресс-баром):
# HELP isc_cache_dashboard_application_errors Number of application errors that have been logged.
isc_cache_dashboard_application_errors 0
# HELP isc_cache_dashboard_csp_sessions Most recent number of CSP sessions.
isc_cache_dashboard_csp_sessions 2
# HELP isc_cache_dashboard_cache_efficiency Most recently measured cache efficiency (Global references / (physical reads + writes))
isc_cache_dashboard_cache_efficiency 439.56
# HELP isc_cache_dashboard_disk_reads Number of physical block read operations since system startup.
isc_cache_dashboard_disk_reads 2605
# HELP isc_cache_dashboard_disk_writes Number of physical block write operations since system startup
isc_cache_dashboard_disk_writes 1021
# HELP isc_cache_dashboard_ecp_app_srv_rate Most recently measured ECP application server traffic in bytes/second.
isc_cache_dashboard_ecp_app_srv_rate 0
# HELP isc_cache_dashboard_ecp_data_srv_rate Most recently measured ECP data server traffic in bytes/second.
isc_cache_dashboard_ecp_data_srv_rate 0
# HELP isc_cache_dashboard_glo_refs Number of Global references since system startup.
isc_cache_dashboard_glo_refs 1593830
# HELP isc_cache_dashboard_glo_refs_per_sec Most recently measured number of Global references per second.
isc_cache_dashboard_glo_refs_per_sec 131.00
# HELP isc_cache_dashboard_glo_sets Number of Global Sets and Kills since system startup.
isc_cache_dashboard_glo_sets 132003
Теперь можно проверить и в интерфейсе Prometheus:
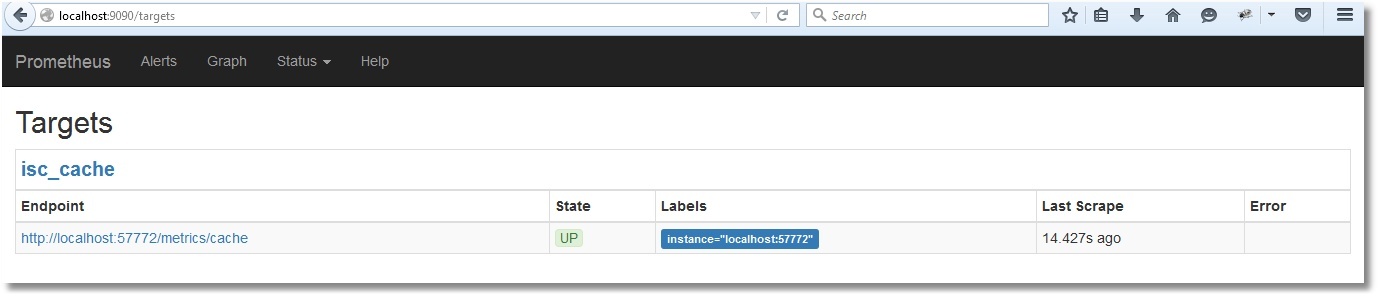
Вот и список наших метрик:
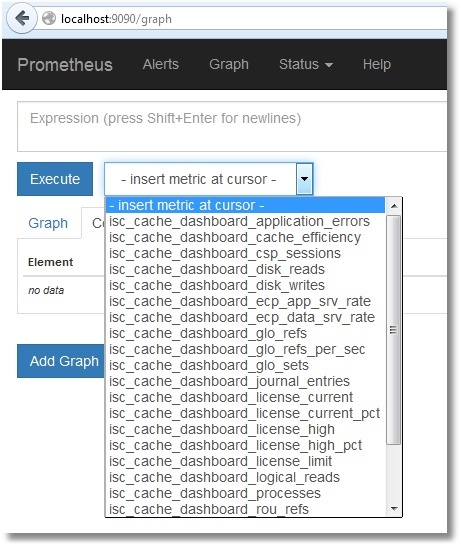
Не будем останавливаться на их просмотре в самом Prometheus. Желающие могут выбрать нужную метрику и нажать кнопку «Execute». Выбрав вкладку «Graph», можно увидеть и график (показана эффективность кэша):
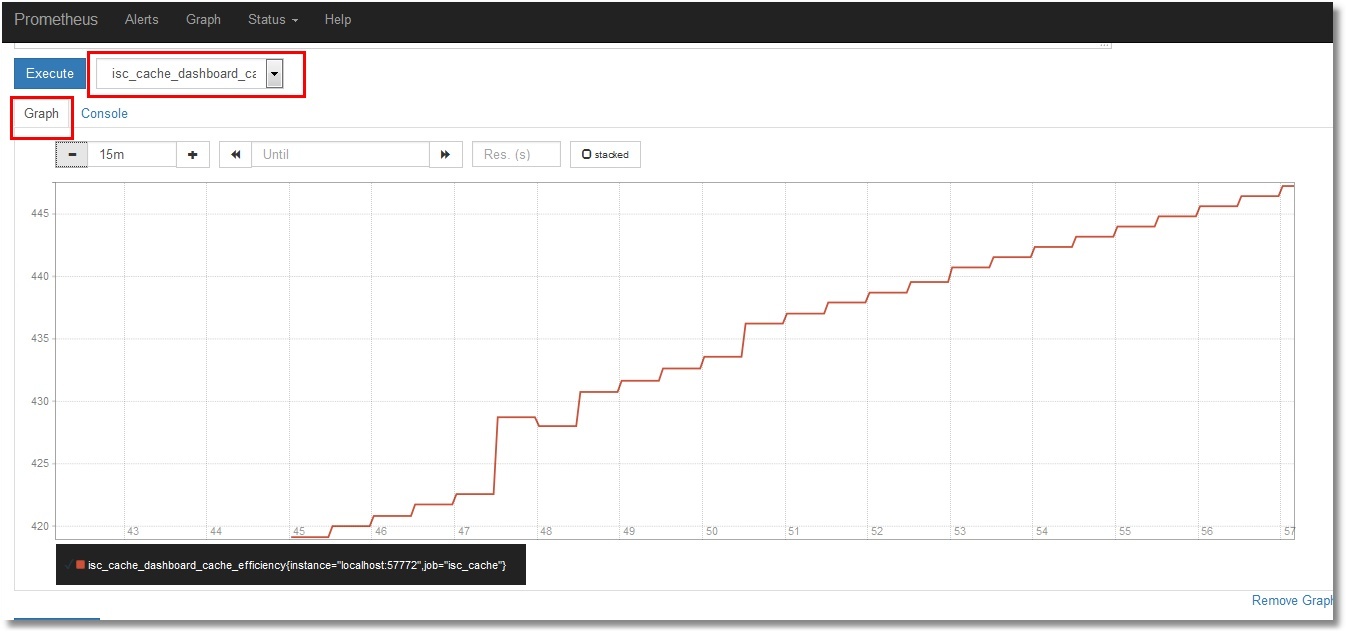
Визуализация метрик
Для графического отображения поставим себе Grafana. Для данной статьи была выбрана инсталляция из тарболла. Но вариантов инсталляции много, от пакетов до контейнера. Проделаем указанные шаги (предварительно только создадим каталог /opt/grafana и перейдем в него):
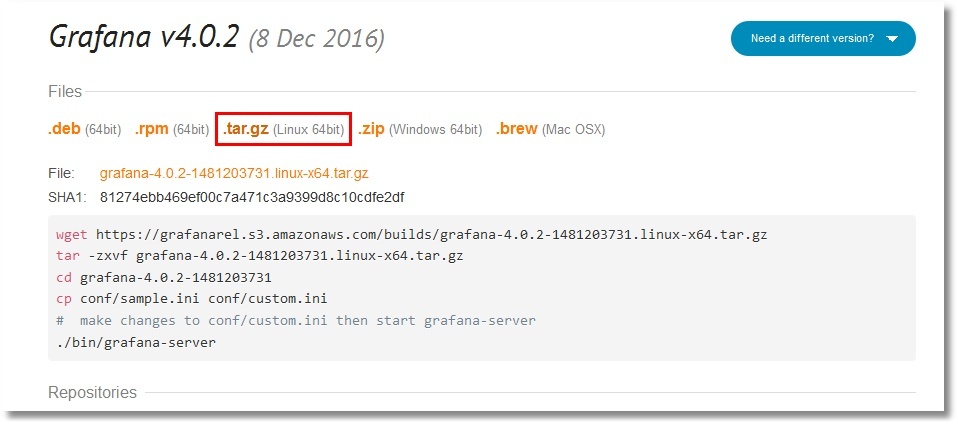
Конфиг пока оставим как есть. И в последнем шаге мы стартуем Grafana в фоновом режиме. Лог работы Grafana перенаправим в файл, как и в случае с Prometheus:
# ./bin/grafana-server > /var/log/grafana.log 2>&1 &
Веб-интерфейс Grafana по умолчанию доступен на порту 3000. Логин/пароль: admin/admin.

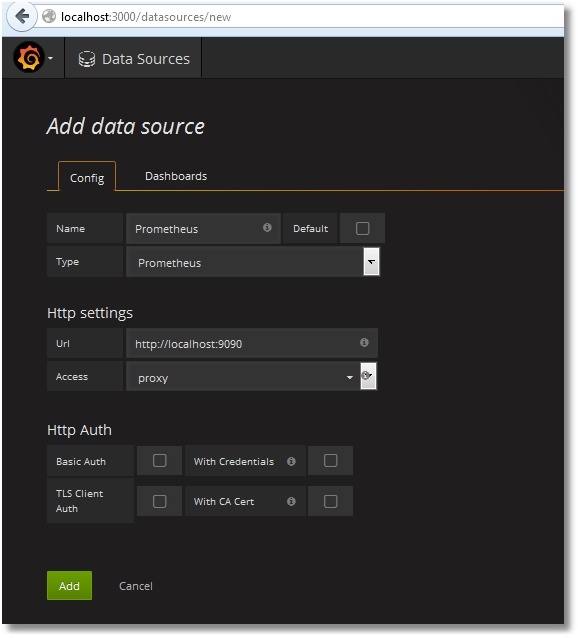
Как подружить Prometheus с Grafana описано здесь. Если своими словами, то — добавляем новый Data Source с типом Prometheus. В качестве доступа direct/proxy выбираете свой вариант:
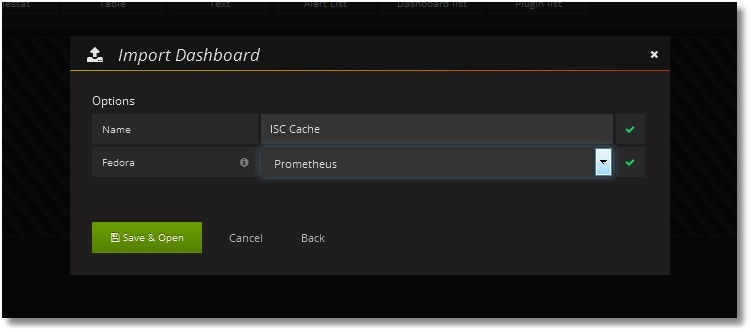
Затем добавляем Дашбоард с нужными нам панелями. Тестовая заготовка Дашбоарда имеется в общем доступе. Там же лежит и код класса для сбора метрик. Дашбоард можно просто импортировать в свою Grafana (Dashboards → Import):
После импорта получим вот такую картину:
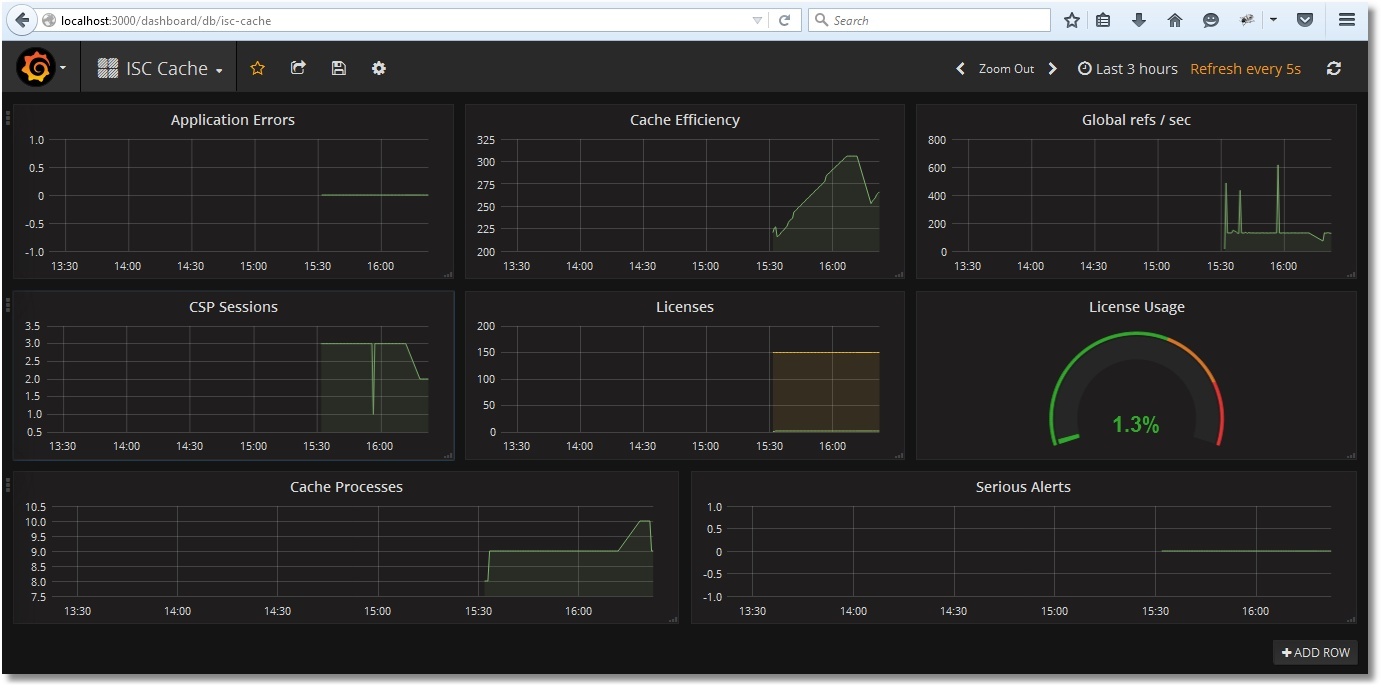
Сохраним Дашбоард:
Выбор временного диапазона и период обновления выбираются вверху справа:
Примеры работы мониторинга
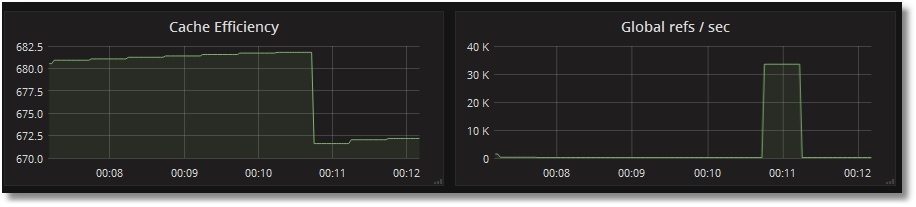
Протестируем мониторинг обращения к глобалам:
USER>for i=1:1:1000000 {set ^prometheus (i) = i}
USER>kill ^prometheus
Видим, что число ссылок на глобалы в секунду возросло, тогда как эффективность кэша упала (глобала ^prometheus в кэше еще не было):
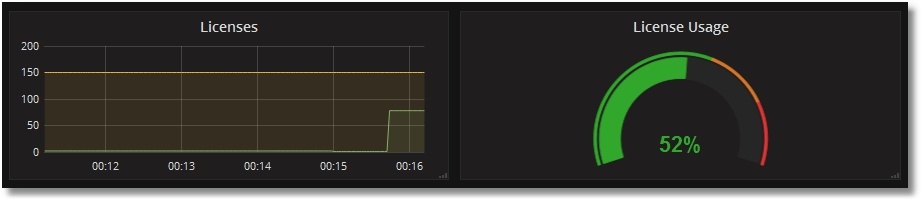
Проверим использование лицензий. Создадим примитивную CSP-страницу PromTest.csp в области USER:
Prometheus Test Page
Monitoring works fine!
И посетим ее энное число раз (приложение /csp/user предполагаем незапароленным):
# ab -n77 http://localhost:57772/csp/user/PromTest.csp
Увидим такую картину с лицензиями:
Краткие выводы
Как видим, внедрение подобного мониторинга не составляет большого труда. Уже на начальном этапе мы можем получить важные сведения о работе системы, как то: использование лицензий, эффективность кэша глобалов, наличие ошибок приложений. Для примера был взят класс SYS.Stats.Dashboard, однако не меньшего внимания достойны и другие классы пакетов SYS, %SYSTEM, %SYS. Также никто не ограничивает в фантазии и возможности написания своего класса, выдающего по запросу метрики именно вашего приложения, например, число документов того или иного типа. Некоторые полезные метрики планируется вынести в отдельный шаблон для Grafana.
To be continued
Если данная тема интересна, продолжение будет следовать. Что в планах:
- Подготовка шаблона для Grafana с метриками работы демона записи. Неплохо бы сделать некий графический аналог утилиты ^mgstat, во всяком случае, для части ее метрик.
- Пароль на веб-приложение — это хорошо, но хотелось бы проверить возможность использования сертификатов.
- Использование Prometheus, Grafana и некоторых экспортеров для Prometheus уже в виде Docker-контейнеров.
- Использование сервисов обнаружения для автоматического добавления новых инстансов Caché в мониторинг Prometheus. Тут также хотелось бы показать на практике такую удобную вещь Grafana, как шаблоны. Это что-то вроде динамических панелей, когда в зависимости от выбранного сервера показываются только его метрики, но все это на одном и том же Дашбоарде.
- Alert Manager Prometheus.
- Конфигурационные настройки Prometheus, касающиеся времени хранения данных, а также возможности по оптимизации для систем с большим числом метрик и малым интервалом их сбора.
- Разные нюансы, которые всплывут по ходу дела.
Ссылки
В процессе подготовки данной статьи был посещен ряд полезных мест и просмотрено некоторое количество видео:
- Сайт проекта Prometheus
- Сайт проекта Grafana
- Блог компании Selectel
- Блог одного из разработчиков Prometheus по имени Brian Brazil
- Туториал на сайте DigitalOcean
- Немного видео от компании Robust Perception
- Много видео с конференции, посвященной Prometheus
Спасибо дочитавшим до этой строки!
