Доставляем голос в мобильной сети: шаг 2 — Аналогово Цифровое Преобразование
В первой части цикла статей мы рассмотрели преобразование человеческого голоса в электрический сигнал. Теперь, казалось бы, самое время передать этот сигнал до местонахождения собеседника и начать разговор! Именно так первоначально и поступали. Однако чем более востребованной становилась услуга и чем на большие расстояния было необходимо передавать сигнал, тем понятнее становилось, что аналоговый сигнал для этого не годится.
Для того чтобы обеспечить передачу информации на любое расстояние без потери качества, нам потребуется произвести второе преобразование из Аналогового сигнала в Цифровой.
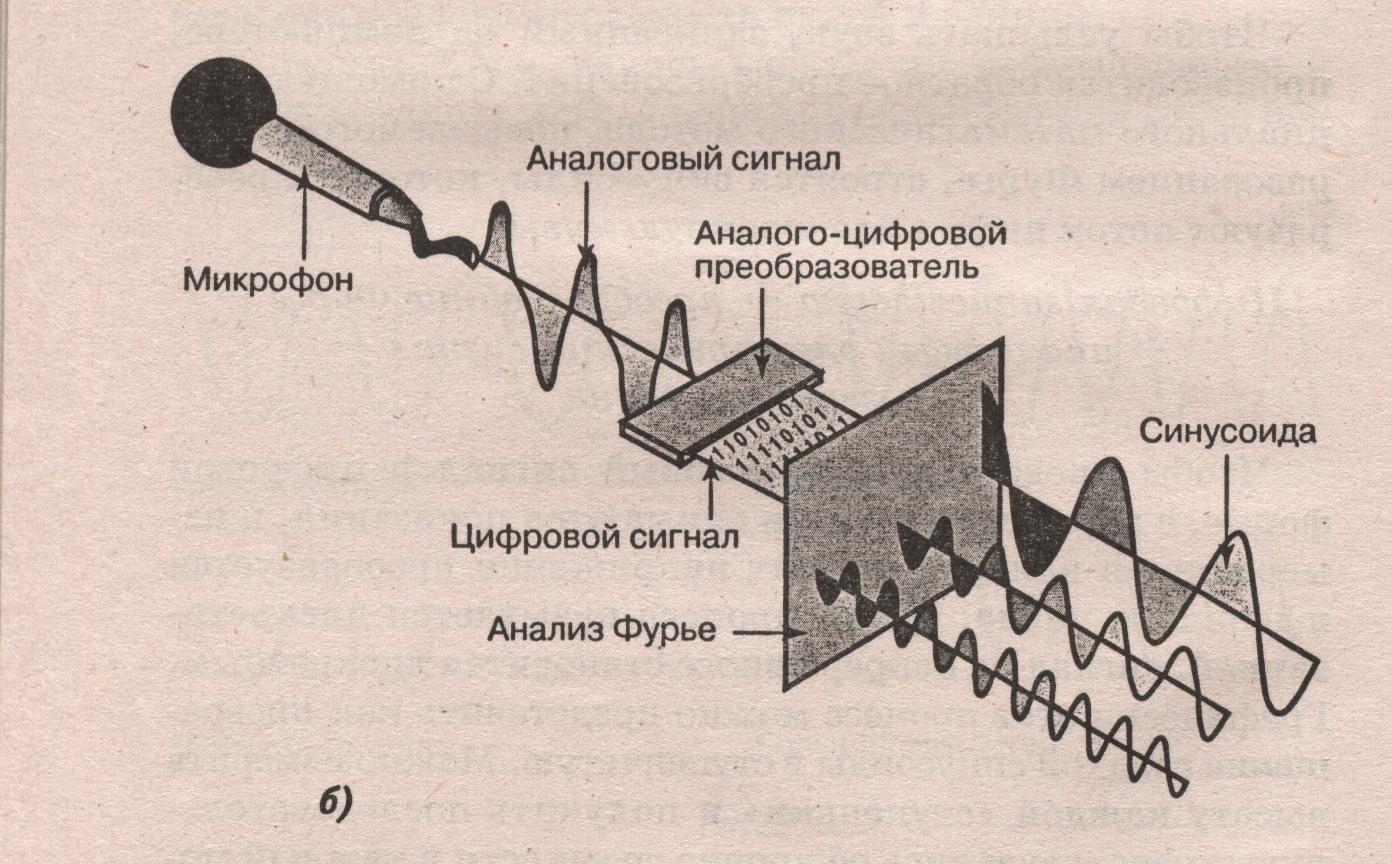
Эта картинка дает самое наглядное представление о том, что происходит при Аналогово Цифровом Преобразовании (АЦП), а далее мы рассмотрим зачем это нужно, как происходило развитие технологии, и какие требования накладываются на такое преобразование в мобильных сетях.
Те, кто пропустил или подзабыл, о чем шла речь в первой части, могут вспомнить Как мы получили из звуковых колебаний электрический сигнал, а мы продолжим описание преобразований, перемещаясь по картинке, на которой обозначена новая область, интересующая нас в данный момент:
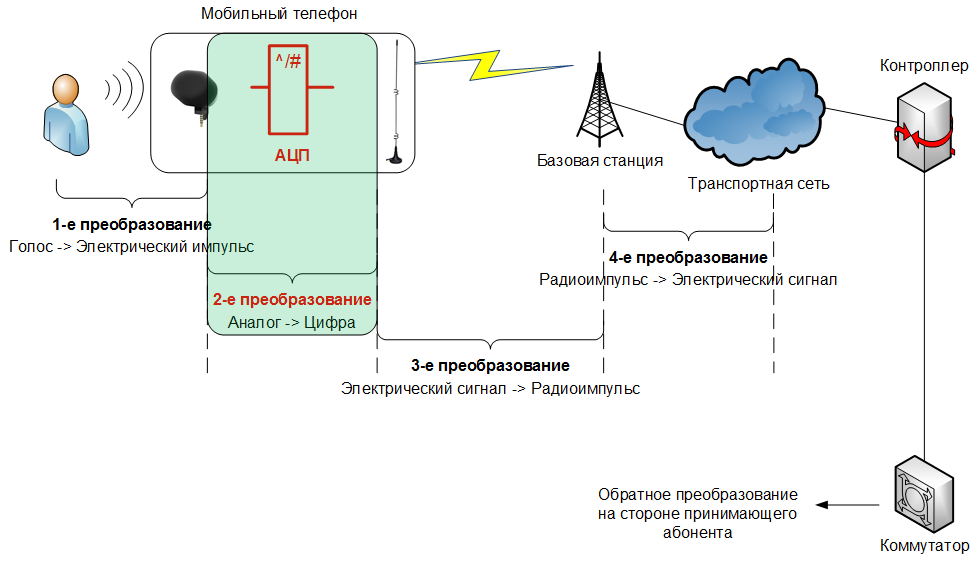
Сначала давайте поймем, зачем вообще нужно преобразовывать аналоговый сигнал, в какие-то последовательности нолей и единичек, которые без специальных знаний и математических преобразований и услышать невозможно.
После микрофона у нас есть аналоговый электрический сигнал, который можно с помощью динамика легко «озвучить», что, собственно, и производилось в первых опытах с телефонами: обратное преобразование «электрический сигнал — звуковая волна» выполняли в том же помещении или на минимальном расстоянии.
Только для чего нужен такой телефон? В соседнее помещение можно донести звуковую информацию без всяких преобразований — просто повысив голос. Поэтому появляется задача — услышать собеседника на максимальном расстоянии от инициатора разговора.
И вот тут в силу вступают неумолимые законы природы: чем больше расстояния, тем сильнее электрический сигнал в проводах затухает, и через какое-то количество метров/километров восстановить из него звук будет невозможно.
Те, кто застал городские проводные телефоны, работающие с декадно-шаговыми АТС (аналоговыми телефонными станциями), прекрасно помнят, какое качество голоса порой предоставлялось с помощью этих аппаратов. А кто-то может вспомнить и такие всеми забытые экзотические включения «через блокиратор» / «параллельный телефон», когда два телефона в одном доме включались на одну телефонную линию, при этом, когда один абонент занимал линию, второй был вынужден ждать окончания его разговора. Поверьте — это было нелегко!
То есть для увеличения количества одновременных вызовов между двумя точками, с использованием аналоговых линий нам требуется прокладывать все больше и больше проводов. К чему это может привести, можно оценить по городским пейзажам начала прошлого века:


Поэтому сразу после изобретения телефона, лучшие инженеры взялись за решение задачи: как передать голос на большие расстояния с максимальным сохранением качества и минимальными затратами на оборудование.
Что же нам необходимо для того, чтобы непрерывный аналоговый электрический сигнал превратился в дискретный, закодированный последовательностями нолей и единиц, и при этом передавал информацию максимально приближенную к оригиналу?
Немного теории.
Чтобы преобразовать любой аналоговый сигнал в цифровой, необходимо через определенные промежутки времени (шаг дискретизации на картинке ниже) зафиксировать амплитуду сигнала с определенной точностью (шагом квантования).
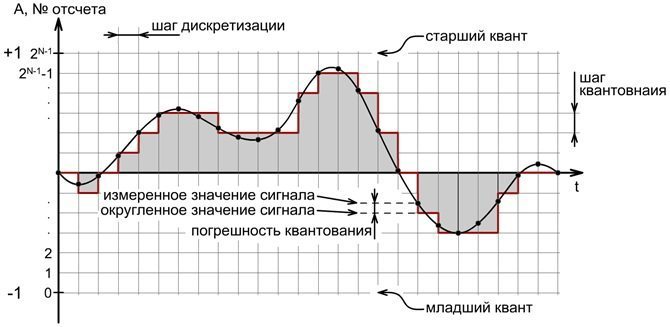
После оцифровки получится ступенчатый график, показанный на рисунке. Для максимального приближения оцифрованного сигнала к аналоговому необходимо шаг дискретизации и шаг квантования выбирать как можно меньше, при бесконечных значениях мы получим идеально оцифрованную запись.
На практике бесконечная точность оцифровки не требуется, и нужно выбрать, какая точность может считать достаточной для передачи голоса с требуемым качеством?
Здесь нам на помощь придут знания о чувствительности человеческих органов слуха: принято считать, что человек может различать звуки с частотой от 20Гц до 22.000Гц. Это граничные значения для дискретизации, которые позволят передать любой звук, воспринимаемый человеком. Если перевести Гц в более привычные секунды — получим 0,000045 секунды, то есть измерения необходимо производить каждые 4,5 сто-тысячных секунды! Более того — и этого оказывается недостаточно. О причинах и требуемых значениях частоты дискретизации расскажем чуть ниже.
Теперь определимся с шагом квантования: шаг квантования позволяет присвоить в каждый момент времени определенное значение амплитуды измеряемому сигналу.
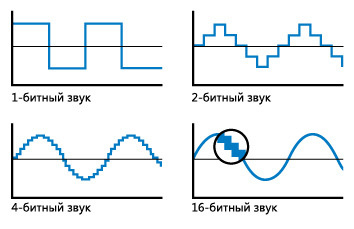
В первом приближении можно просто проверять наличие или отсутствие сигнала, для описания такого количества вариантов нам будет достаточно всего двух значений: 0 и 1. В информатике это соответствует количеству информации: 1 бит и битность записи будет равна 1. Если оцифровать любой звук с такой битностью, на выходе мы получим прерывистую запись, состоящую из пауз и звука одного тона, вряд ли это можно назвать записью голоса.
Поэтому придется увеличить количество измеряемых вариантов амплитуды, например, до 4 (то есть до 2 бит — 2 в степени 2): 0 — 0,25 мА — 0,5 мА — 0,75 мА.
С такими значениями уже можно будет различить некоторые изменения звука после оцифровки, а не только его наличие или отсутствие. Иллюстрация прекрасно показывающая, что дает нам увеличение битности (квантования) при оцифровке звука, приведена на этом рисунке:
Теперь, увидев в свойствах музыкального файла цифры 44 кГц/16 бит, вы можете сразу понять, что Аналогово-Цифровое Преобразование производилось с дискретизацией 1/44кГц = 0,000023 секунды и с глубиной квантования 2 в 16 степени — 65.536 вариантов значений.
Первые схемотехнические решения для выполнения АЦП-ЦАП преобразований были как всегда большими и медленными:

Сейчас эти задачи выполняются в основном процессоре мобильного телефона, который одновременно справляется с огромным количеством других задач:

Если провести оцифровку без дополнительной оптимизации полученной цифровой модели, объем полученных данных будет очень велик, достаточно вспомнить, сколько места на вашем диске может занять звуковой файл в несжатом виде. Стандартный CD, для примера, это 780 мегабайт информации и всего 74 минуты звука!
После обработки такого файла с применением алгоритмов оптимизации и сжатия с потерями данных (например, mp3) объем файла можно снизить в 10 и более раз.
Для наших целей объем получаемых данных имеет принципиальное значение, поскольку их еще необходимо передать до вашего собеседника, и ресурс транспортного канала очень ограничен.
Вновь задача для инженеров — максимальная оптимизация объема передаваемых данных с сохранением требуемого качества.
В разговорной речи, которая звучит во время телефонного диалога, спектр частот существенно ниже доступного для восприятия, поэтому для передачи телефонного разговора можно ограничиться более узким спектром: например 50…7000Гц. Про это мы достаточно подробно писали в материале о голосовых кодеках в мобильных сетях.
Теперь у нас есть исходные данные для начала преобразования — электрический аналоговый сигнал, в спектре 50–7000Гц, и нам необходимо провести преобразование А-ЦП, таким образом, чтобы искажение сигнала при преобразовании (те самые ступеньки на графике выше) не повлияло на качество записи. Для этого нужно выбрать значения шага дискретизации и шага квантования, достаточные для полного описания имеющегося аналогового сигнала.
Здесь нам на помощь придет одна из основополагающих теорем в области цифровой обработки сигналов — Теорема Котельникова.
В ней наш соотечественник математически обосновал, с какой частотой необходимо проводить измерения значений функции для её точного числового представления. Для нас важнейшее следствие данной теоремы заключается в следующем — измерения нужно проводить в два раза чаще самой высокой частоты, которую нам необходимо перевести в цифровой вид.
Поэтому шаг дискретизации для оцифровки разговора, будет достаточно взять на уровне 14 кГц, а для качественной оцифровки музыки — 2×22кГц, здесь мы и получаем стандартные 44кГц, с которыми сейчас, как правило, создаются музыкальные файлы.
Существует большое количество самых разнообразных голосовых кодеков, которые могут применяться в проводных и беспроводных сетях, причем кодеки для проводных сетей, в общем случае, кодируют голос с лучшим качеством, а кодеки для беспроводных сетей (сетей мобильных операторов) — с немного худшим качеством.
Зато эти кодеки генерируют дополнительные данные, для восстановления получаемого сигнала в случае неуспешной доставки из-за сложных радиоусловий. Эта особенность называется помехозащищенностью, и развитие кодеков для мобильных сетей происходит в направлении улучшения качества передаваемого сигнала с одновременным увеличением его помехозащищенности.
В мобильных сетях используются целые классы голосовых кодеков, которые включают в себя набор динамически выбираемых скоростей кодирования, в зависимости от текущего положения абонента и качества радиопокрытия в этой точке:
| Кодек | Стандарт | Год создания | Диапазон сжимаемых частот | Создаваемый битрейт |
|---|---|---|---|---|
| Full Rate — FR | GSM 06.10 | 1990 | 200–3400 Hz | FR 13 kbit/s |
| Half Rate — HR | GSM 06.20 | 1990 | 200–3400 Hz | HR 5.6 kbit/s |
| Enhanced Full Rate — EFR | GSM 06.60 | 1995 | 200–3400 Hz | FR 12.2 kbit/s |
| Adaptive Multi Rate — AMR | 3GPP TS 26.071 | 1999 | 200–3400 Hz | FR 12,20 |
| Adaptive Multi Rate — AMR | 3GPP TS 26.071 | 1999 | 200–3400 Hz | FR 10,20 |
| Adaptive Multi Rate — AMR | 3GPP TS 26.071 | 1999 | 200–3400 Hz | FR/HR 7,95 |
| Adaptive Multi Rate — AMR | 3GPP TS 26.071 | 1999 | 200–3400 Hz | FR/HR 7,40 |
| Adaptive Multi Rate — AMR | 3GPP TS 26.071 | 1999 | 200–3400 Hz | FR/HR 6,70 |
| Adaptive Multi Rate — AMR | 3GPP TS 26.071 | 1999 | 200–3400 Hz | FR/HR 5,90 |
| Adaptive Multi Rate — AMR | 3GPP TS 26.071 | 1999 | 200–3400 Hz | FR/HR 5,15 |
| Adaptive Multi Rate — AMR | 3GPP TS 26.071 | 1999 | 200–3400 Hz | FR/HR 4.75 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 23.85 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 23.05 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 19.85 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 18.25 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 15.85 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 14.25 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 12.65 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 8.85 |
| Adaptive Multi Rate — WideBand, AMR-WB | 3GPP TS 26.190 | 2001 | 50–7000 Hz | FR 6.60 |
| Adaptive Multi Rate-WideBand+, AMR-WB+ | 3GPP TS 26.290 | 2004 | 50–7000 Hz | 6 — 36 kbit/s (mono) |
| Adaptive Multi Rate-WideBand+, AMR-WB+ | 3GPP TS 26.290 | 2004 | 50–7000 Hz | 7 — 48 kbit/s (stereo) |
В таблице перечислены все кодеки, используемые в современных мобильных сетях, из них кодеки с динамическим битрейтом (в которых меняется соотношение полезных данных и избыточных для восстановления данных) имеют название AMR — Adaptive Multi Rate. Кодеки FR/HR/EFR используются только в сетях GSM.
Чтобы наглядно представить насколько больше данных кодируется в высокоскоростных кодеках, взгляните на следующую картинку:
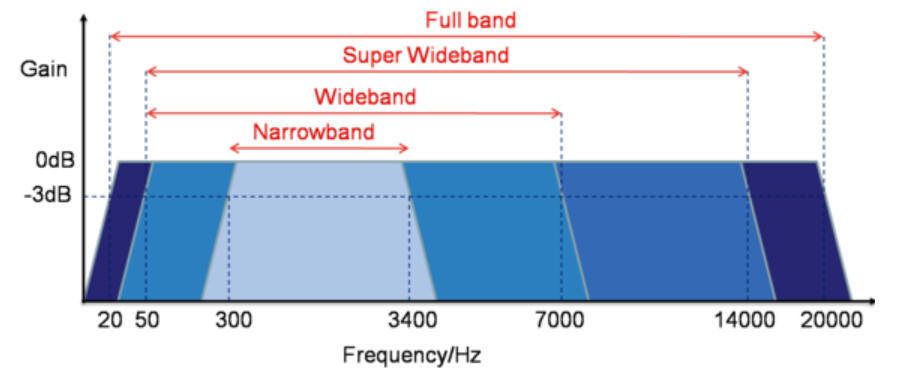
Переход от кодеков класса AMR к AMR-WB почти удваивает количество данных, а AMR-WB+ требует еще на 40–50% больше ширины транспортного канала!
Именно поэтому в мобильных сетях широкополосные кодеки в мобильных сетях еще не нашли широкого применения, но в будущем возможен переход на Super Wide Band (AMR-WB+) и даже на Full Band полосу, к примеру для онлайн трансляций концертов.
Итак — после выполнения второй стадии преобразования голоса, мы вместо звуковых колебаний получаем поток цифровых данных, готовых к передаче через транспортную сеть.
До момента обратного преобразования цифр в аналоговый сигнал эти данные сохраняются почти без изменений (иногда в процессе доставки голоса может происходить перекодировка из одного кодека в другой), и дальнейшие преобразования происходящие с нашим голосом, будут касаться физической среды через которую передается вызов.
В следующем материале мы рассмотрим, что происходит между телефоном и базовой станцией и каким чудесным образом сформированный нами поток данных без проводов доставляется до оборудования оператора.
P.S. Всем кому интересна тема цифровой связи и история её развития, крайне рекомендую книгу «И мир загадочный за занавесом цифр» авторы Б.И. Крук, Г.Н. Попов. С точки зрения современных стандартов и технологий она немного устарела, но теоретическую и историческую часть авторы описывают прекрасно, разбавляя сухую теорию живыми примерами и иллюстрациями.
