Дорогая цена стилей. Доклад Яндекса
Загрузка CSS на страницу — блокирующая операция. Если асинхронная загрузка JavaScript может быть незаметна пользователю, то медленное появление стилей может прогнать нетерпеливого гостя с сайта. Как загружать CSS максимально производительно и незаметно для пользователей? Разобраться пробует Никита Дубко DarkMeFoDy из группы поисковых интерфейсов Яндекса в Минске.
— Всем привет. Расскажу про стили. Все сегодня говорят про TypeScript да TypeScript. А я про Cascade style script буду рассказывать.
Коротко о себе. Я белорусский разработчик — после фильма Дудя буду везде так говорить. Возможно, вы слышали мой голос в подкасте «Веб-стандарты», и если увидите опечатки в ленте новостей «Веб-стандартов», это тоже, скорее всего, я.
Маленький дисклеймер. В докладе будет несколько безумств — относитесь ко всему, что я говорю, с большой критикой. Придумывайте, зачем вы можете использовать такие приемы, а зачем они вам не нужны. Некоторые вещи будут действительно безумные. Поехали.
Зачем?
Для начала — зачем вообще говорить про оптимизацию CSS?
Если начать искать в поисковиках про быструю загрузку JS, результатов очень много. Если искать быструю загрузку CSS, то в топе выдается даже не совсем тот CSS, который нужен.
Если посмотреть в Google, есть 111 млн результатов про JS, а про CSS всего 26 млн.
Так, может, это просто неважно? Зачем про это говорить? Если поискать доклады о перформансе JS, вы найдете их очень много. Есть про React, про всякие другие фреймворки, про Vanilla и т. д. А про CSS я нашел всего один доклад. Гарри Робертс в 2018 году читал классный доклад про CSS performance. Я думал, что нашел второй доклад от Ромы Дворнова, «Парсим CSS: performance tips & tricks». Но оказалось, это доклад про JS, который парсит CSS. Не совсем то, что нам надо.
Получается, что про CSS особо не задумываются. Обидно.
Но когда я захожу в веб, то обычно вижу HTML. И еще я вижу CSS, который стилизует страницу. Но я не вижу JS. JS — штука, которая двигает CSS и HTML на страничке, чтобы все выглядело красиво. Это скрипт. И если JS не загрузится, это не так страшно, как если не загрузится CSS.
Ошибки в JS падают в консоль молча. И среднестатистический пользователь вряд ли полезет в DevTools смотреть: «Ой, у вас там это, ошибочка в консоли». Но если CSS не загрузится, то вы можете вообще не увидеть все, что вам нужно.
Кстати, есть исследования про то, что главное — произвести первое впечатление. 38% процентов пользователей могут зайти на сайт, и если они увидят, что он прямо отвратительный, — они тут же уйдут. А 88% потерпят, один раз попользуются, а потом уже никогда не вернутся и вряд ли посоветуют ваш сайт.
Сейчас, когда мы все сидим по домам, интернет-трафик особенно вырос. И нам надо задуматься о том, чтобы производительно доставлять любые ресурсы пользователям.
Давайте попробуем посчитать с точки зрения Яндекса. Если мы сможем оптимизировать каждую выдачу Яндекса на 100 мс и отдадим, скажем, 200 млн страниц в день (я не знаю точную цифру), то за этот день мы сэкономим 0,1 с * 200 млн = 232 человеко-дня. Просто оптимизировав выдачу на 100 миллисекунд. И CSS это тоже позволяет сделать.
Давайте немного поиграем в сыщиков и выясним, как выжать из загрузки стилей максимум.
Замеряйте!
Самый первый совет — всегда всё замеряйте. Нет никакого смысла делать оптимизации теоретически. Вы можете предположить, что в вашем случае оптимизация работает, но реальные замеры покажут, что ничего подобного. Это самое важное правило любых оптимизаций. Про то, как это делаем мы, очень хорошо рассказал Андрей Прокопюк из команды Скорости SERP на HolyJS, я повторяться не буду.
Какие есть инструменты для замеров?
— Если вы хотите замерять на более-менее реальных устройствах, медленных, не таких крутых, как у вас, используйте WebPageTest. Я обычно делаю замеры там.
— У вас есть Lighthouse, если вы пользуетесь браузерами на основе Chromium. Он, как и локальные замеры, показывает достаточно хорошие вещи.
— Если вы уверены, что сможете сделать все самостоятельно, идите в DevTools, во вкладку Performance. В ней очень много подробностей, вы можете заводить собственные метрики и анализировать их.

Естественно, в Performance нужно выставлять именно реальные условия. Вы сидите на своем крутом ноутбуке с крутым интернетом в офисе, у вас все прямо потрясающе, но к вам приходят и говорят: «У меня медленно». А вы говорите: «У меня все работает». Не надо так.
Всегда старайтесь проверить, как пользователь в условиях метро или еще где-то будет пользоваться вашим сайтом. Для этого вам нужно выставлять очень медленный интернет. Желательно еще замедлять CPU, потому что кто-то может к вам зайти с какой-нибудь Nokia 3110. Ему тоже надо показать сайт.
Самое важное: замеряйте на реальных пользователях. Есть такая метрика, точнее, целый набор метрик — RUM, Real User Monitoring. Это когда вы замеряете не то, что синтетически происходит у вас в коде, а метрики на реальных пользователях в продакшене. Например — от загрузки страницы до действия. Действие — это, например, нечто срабатывающее в браузере или даже клик в какой-то важный элемент.
Помните, что вы разрабатываете не для роботов. Соточка в Lighthouse — это здорово, это правда хорошо. Значит, вы выполняете хотя бы те требования, которые выставляет Lighthouse. Но есть реальные пользователи, и если при соточке в Lighthouse пользователь не может увидеть страницу, то вы что-то делаете не так.
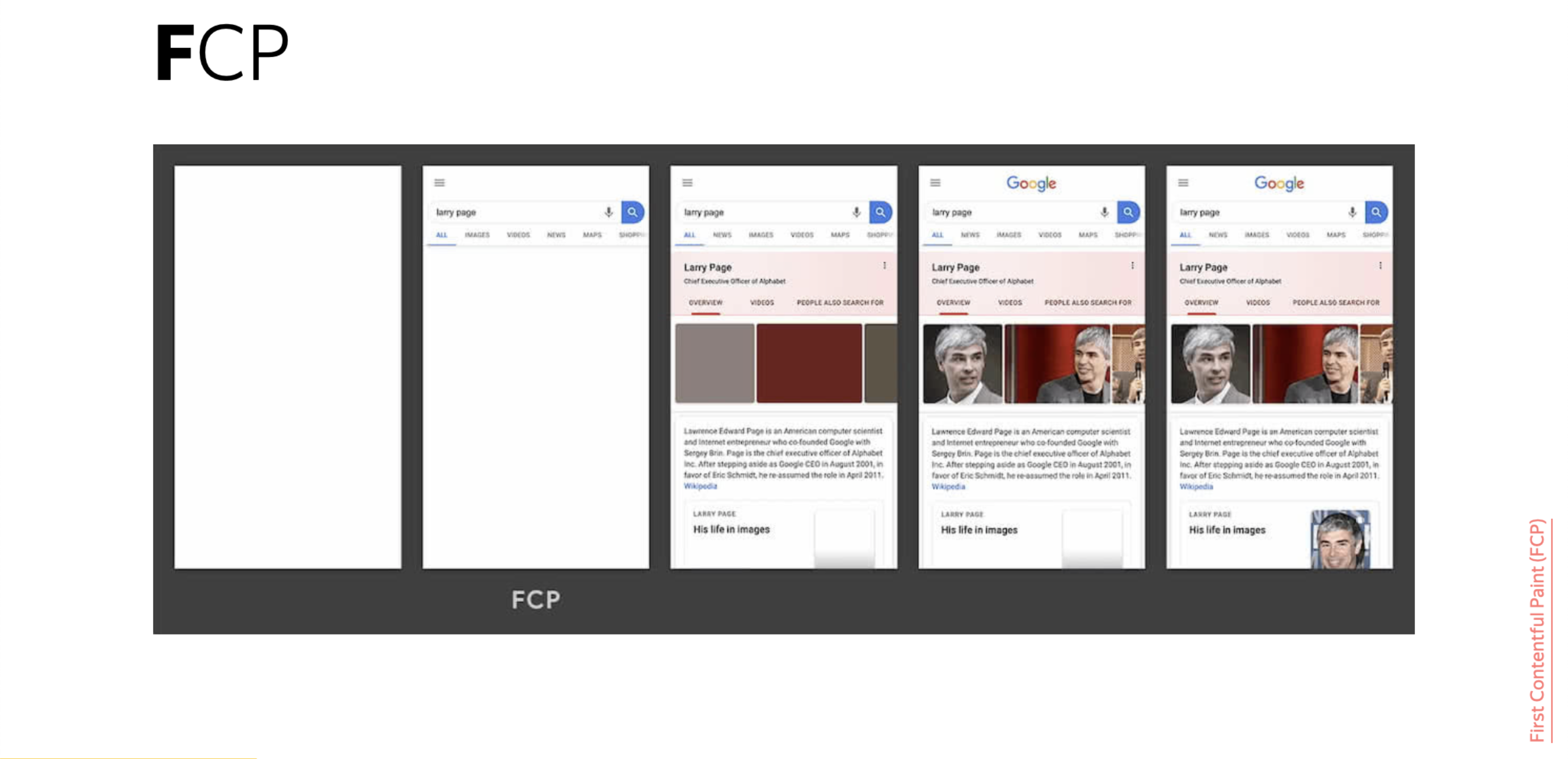
Есть метрики, на которые важно ориентироваться. Это First Contentful Paint, когда у вас на странице появляется первый контент, с которым можно что-то делать, читать. Эта метрика отправляется в Chromium-браузерах, вы можете ее получить.

В последнее время еще можно посмотреть на Largest Contentful Paint. Часто бывает, что у вас медийная страница, и на ней важно, например, фотографию посмотреть. Тогда вам нужна именно эта метрика.
Загрузка CSS
Давайте наконец перейдем к CSS, к тому, как CSS загружается. Приемы давно известные. Есть Critical Rendering Path, критический путь рендеринга. Он про то, что браузер делает от момента отправки запроса за ресурсом и до момента, как на экране у пользователя отрисуются пиксели. Про это тоже есть куча статей и доклады. Но давайте коротко посмотрим, как это браузер это делает.

Он начинает скачивать HTML, видит теги. Он постепенно их парсит, понимает, что с ними делать. Грузит. Наткнулся на link. Надо его использовать. Но как? Для начала нужно его загрузить. Загрузка — штука медленная. Когда он загрузил, то начинает парсить страничку дальше.

Если наткнется еще на один link — снова блокируется и не дает выполняться. Блокирует JS, блокирует парсинг. И до тех пор, пока не загрузится, он ничего не делает. Но после начинает дальше работать.
Давайте копнем глубже — что происходит в момент обращения к link?

Запись, куда мы ходим, стандартная. Есть style CSS, который где-то лежит. Сейчас модно класть всю статику на CDN.
Куда идти?
Для начала браузеру нужно понять, куда идти.

Он видит URL, и ему нужно понять, этот URL — он про что? Мы привыкли, что URL — идентификатор сайта.
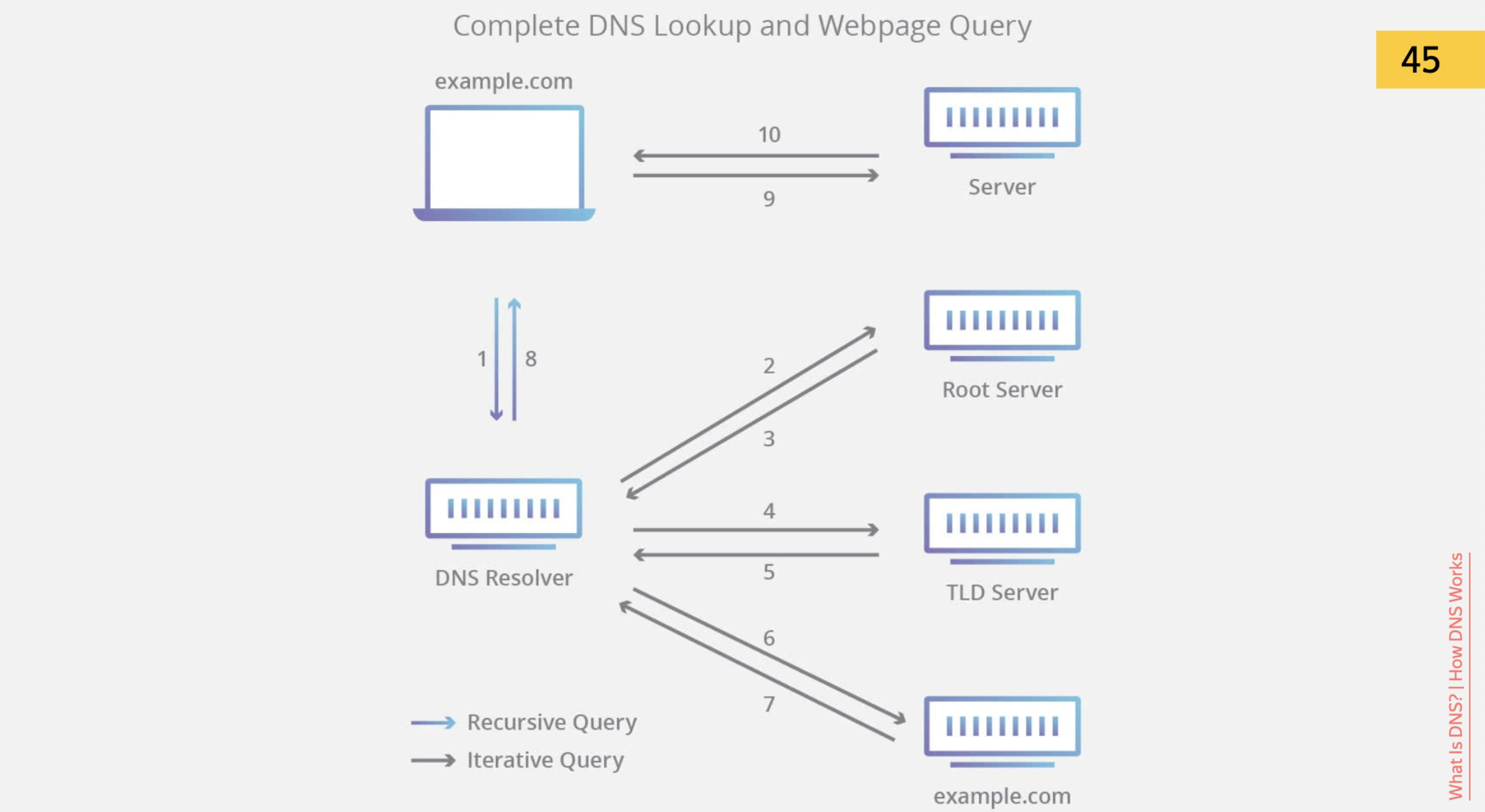
Но физически нам нужно получить IP-адрес этого URL и сходить на реальную физическую машинку по IP-адресу.
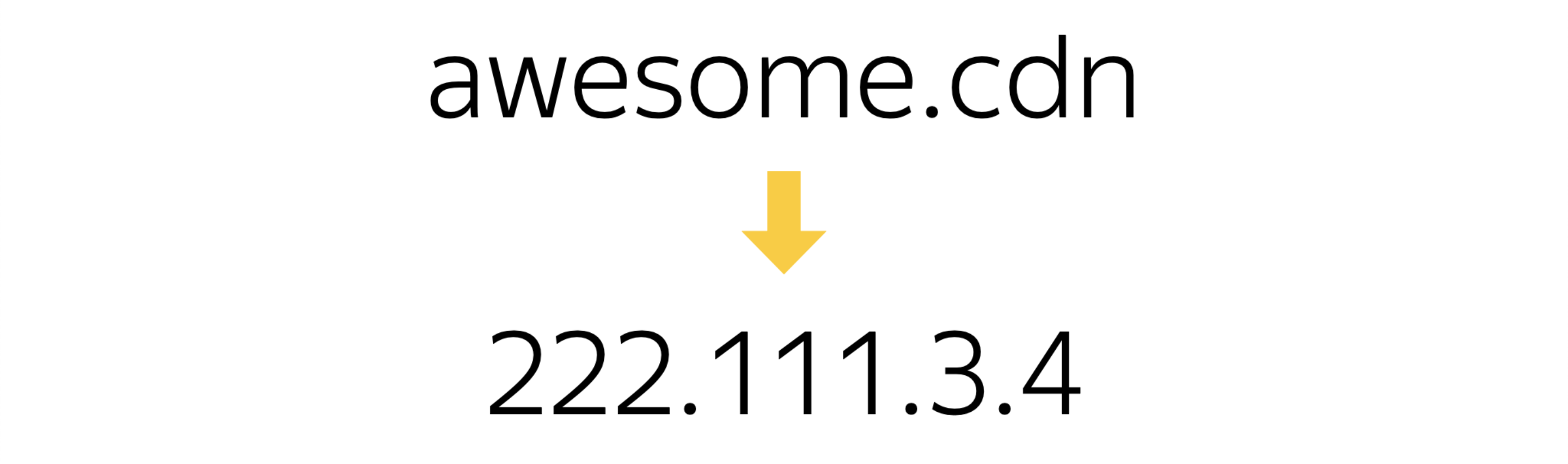
Для вашего CDN он получит запись в DNS и фактически будет ходить уже напрямую по IP-адресу. Как в этом случае можно ускориться?

Безумная идея — сократить расстояние от пользователя до DNS-сервера. Взять и пересадить пользователя. Например, выдать сообщение: «Пересядь поближе» или «Переедь поближе».
Можно сразу указывать в ссылке IP-адрес. Зачем нам искать DNS, резолвить домены, если можно сразу по айпишнику выдавать результат? Безумный способ, но в случае DDoS глобальных DNS-серверов это даже может вас спасти.
И мы можем избавиться от получения IP-адреса.

Обращаясь к вашему index.html или к другому файлу, вы уже знаете адрес домена, куда вы ходите. Тут как раз тот случай, когда вы вместо хранения статики на отдельном домене или поддомене можете положить статику поближе к вашему домену, именно на сам этот домен. Тогда уже DNS резолвить не надо, он уже есть.

Мы выяснили, куда идти. Но мы можем сделать такие вещи для браузера заранее. Если, например, ваша стилевая таблица загружается гораздо позже по DOM-дереву, вы можете браузеру подсказать при помощи , что «я пока туда не хожу, но ты прогрей ресурсы, мне они потом точно понадобятся».
Такой записью вы говорите браузеру сходить и получить этот DNS. Когда link появится в коде, браузер уже будет знать IP-адрес этого домена. Можно делать такие предварительные штуки. То же самое, например, перед заходом на следующую страницу, куда вы точно зайдете.
Окей, браузер знает, куда идти. Ему нужно понять, как идти.
Как идти?
Мы смотрим протокол. Сейчас, понятное дело, https — это прямо требование. В том числе поисковики пометят ваши сайты не на https с формами как не совсем безопасные.
Я нашел потрясающую серию комиксов о том, как работает https. Но мы же айтишники, любим классные сложные диаграммки, а веселые комиксы — это слишком просто.

Я тут своими словами сформулировал, как работает https. Сначала вы получаете SSL-сертификат с вашего сервера. Затем вы должны проверить сертификат в центре сертификации. Это специальные сервера, которые знают, что валидно, а что нет, и могут браузерам подсказывать: «да, тут все нормально, пользуйся этим сертификатом».
Дальше происходит генерация ключей для общения между сервером и клиентом, шифрование, дешифровка при помощи разных ключей. Процесс интересный, если разобраться с точки зрения криптографии. Но мы хотим ускориться. Как?

Мы вновь можем пересадить пользователя поближе к серверам. У нас уже есть DNS, теперь можно посадить ближе к центру сертификации. И между этими серверами посадить, будет идеально.
Можно отказаться от https, зачем он нам? Мы тратим время на получение сертификата, шифруем, дешифруем. На самом деле нет. Это самый вредный совет в докладе, не делайте так. https — защита пользовательских данных, и без https не будет работать http/2, а http/2 — еще один способ ускориться.
Есть еще технология OCSP Stapling. Вы можете проверять сертификат без центра сертификации. Это, наверное, ближе к DevOps. Вам нужно определенным образом свой сервер настроить так, что он сможет кэшировать ответ Центра сертификации и выдавать пользователю: «поверь мне, мой сертификат правда настоящий». Тем самым мы можем сэкономить хотя бы тот шаг, на котором мы ходим в Центр сертификации.
Но тут нюанс — в Chrome это не работает, и достаточно давно. Но для пользователя других браузеров вы можете этот процесс ускорить.
Я уже дважды говорил, что надо пользователя пересадить, и в воздухе витает идея — переносить сервера ближе к пользователю. Ничего нового для вас я не открыл. Это CDN, распределенная сеть доставки контента. Идея в том, что вы можете использовать готовые сидиэнки, самостоятельно создать свою инфраструктуру и поставить кучу серверов по всему миру, насколько вам позволяют деньги и возможности. Но нужно расставить сервера так, чтобы пользователь из Австралии ходил к австралийским серверам. Тут на вас играет скорость света, чем меньше расстояние, тем быстрее его проходят электроны.
Давайте копнем глубже. Что еще происходит в запросе? На самом деле, https — просто обертка над http. Не просто, а клевая обертка. А если еще глубже, то http — такой запрос из семейства TCP/IP.
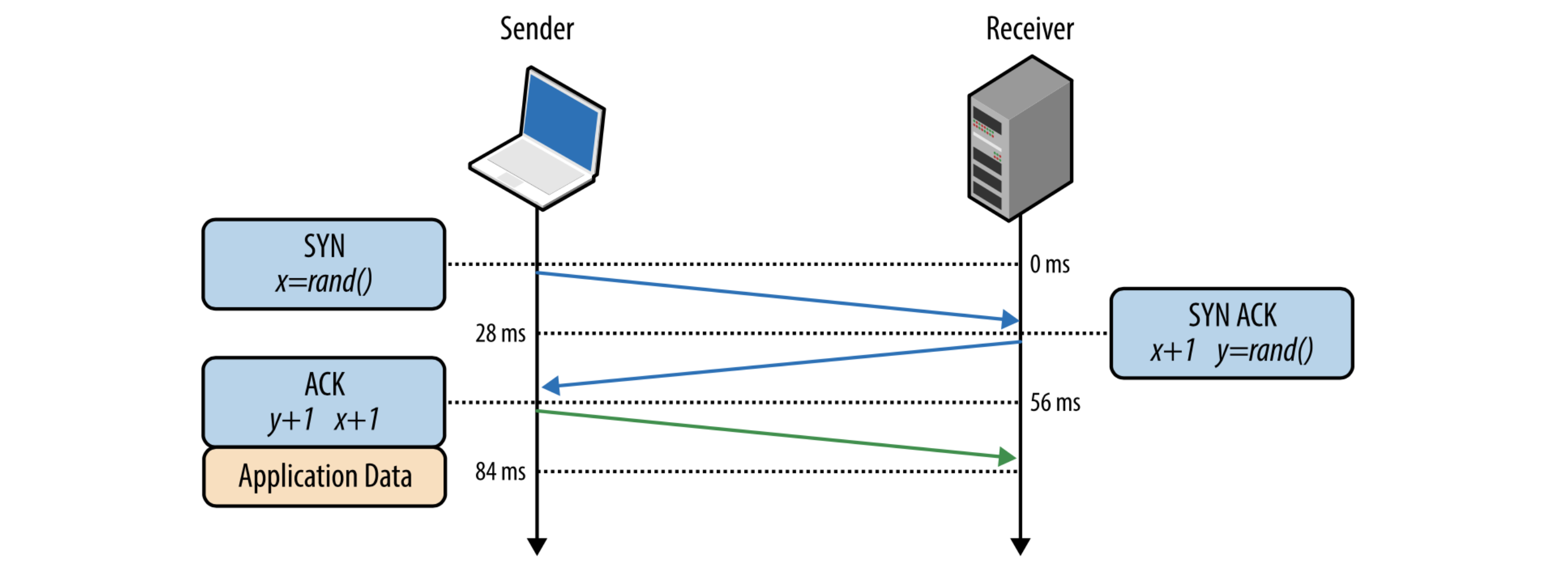
Как происходит пересылка пакетиков, байтиков в сети, чтобы все браузеры, клиенты и сервера друг с другом общались? Первое, что делает по TCP/IP-соединению клиент-сервер, — это рукопожатие.
Но в 2020 году ВОЗ рекомендует избегать рукопожатий. Есть такая классная технология TCP Fast Open. Вы можете в момент рукопожатия избежать всей цепочки «Привет, я клиент» — «Привет, я сервер» — «Я тебе верю» — «И я тебе верю. Поехали». Можно уже в этот момент отправлять полезные данные. И если рукопожатие прошло успешно, то часть полезных данных прошла. Это и есть TCP Fast Open.
Что забирать?
Разберемся, что клиент должен забрать у сервера. Главное — не клиент забирает что-то у сервера, а сервер отдает данные клиенту. Тогда можно подумать: User-Agent. Я с клиента могу получить User-Agent, узнать, из какого браузера пользователь зашел. Узнать приблизительно, если он меня не обманывает, этот браузер.

Допустим, он зашел из Firefox. У меня, как обычно, сборка, в которой autoprefixer банально подключен, он мне кучу кода нагенерил. Да, это классный подход, что везде все будет работать. Но ведь я уже знаю, что пользователь зашел из Firefox.
Почему бы не выключить все лишнее? Согласитесь, строчек становится гораздо меньше, мы отправляем меньше байтов, это классно.
У нас есть облегченная версия SERP, «Бабуля». Про нее рассказывал Виталий Харисов vithar, классный доклад на Web Standards Days. Там используется именно такой подход. Мы можем сгенерировать несколько бандлов и отдавать их на разные клиенты по-разному. Они весят гораздо меньше, поскольку Firefox получает свое, WebKit — свое, и это работает, проверено.
Далее. Мы, скорее всего, обрабатываем пользовательские запросы, знаем, что человек авторизован и используем для него какую-то персональную информацию. Логично, что мы что-то должны получать из базы. Но не все! Есть статические вещи, которые ни для кого из пользователей не отличаются, они абсолютно одинаковые.
Джеймс Аквух про это читал классный доклад «Server-Side Rendering. Сделай сам». В чем суть? Вы уже знаете, что у вас есть HTML и какой-то CSS, который абсолютно для всех пользователей одинаковый. Прежде чем ходить за любыми данными, можно генерировать выдачу из этих статических данных, сразу в потоке с сервера отправлять самое полезное. А уже после этого — ходить за данными, быстро их получать, преобразовывать в шаблоны и отдавать клиенту. И пользователь уже увидит нечто полезное.
Your browser does not support HTML5 video.
Мы это давно реализовали. У нас есть на SERP, на главной странице поиска, две фазы — presearch и postsearch. Presearch — это когда мы отправляем все штуки, для которых не нужно знание о том, какой пользователь зашел. Мы ему уже можем отдать, например, шапку.
То есть у нас есть поисковая строка, которой пользователь может начать пользоваться еще до того, как все остальное загрузится. Это же полезно на медленном соединении. Мы так делаем, работает.
И еще я говорил про http/2. Это вполне поддерживается современными браузерами, поэтому если у вас на сервере он еще не настроен — хотя бы разберитесь, как его настроить.
Server Push — классная технология, которая говорит: «Браузер, я еще не отдал тебе знание о том, что тебе понадобится какой-то CSS. Но я точно знаю, что понадобится. Поэтому держи, предзагрузи его».

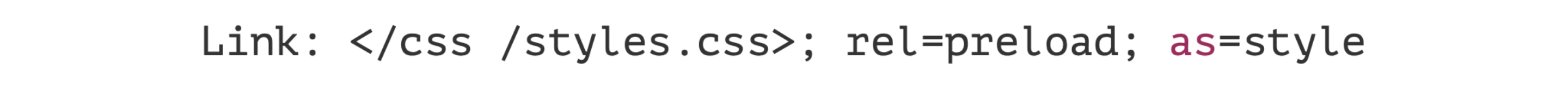
Это не сложно. Вам нужно пару заголовков настроить на сервере, и все начнет работать. Если браузер не знает этого заголовка — ничего не сломается, это самое прекрасное. Давайте копнем еще дальше. TCP. Мы про это уже говорили: рукопожатие, байтики пересылаются.

После рукопожатия мойте руки. Но в терминах TCP мы начинаем пересылать байты, причем алгоритмы достаточно оптимизированы, чтобы сервер-клиент не простаивали в ожидании.
Поэтому сначала отправляется некий сегмент данных. По умолчанию, (это вы можете менять в настройках) это 1460 байт. Сервер не отправляет информацию по одному сегменту. Он отправляет окнами.
Первое окно — 14600 байт, десять сегментов. Потом, если соединение хорошее, он начинает увеличивать окна. Если соединение плохое — может уменьшить окно. Что важно понимать? Есть первое окно из десяти сегментов, в которое вы должны уместить весь сайт, если хотите. И тогда будет максимальная скорость появления контента. Про это тоже читал доклад Виталий Харисов. И да, это возможно — уместить в одно окно сайт со всем необходимым, если выключить, например, JS.
Важный нюанс. Когда вы целиком сегмент заполняете, это один сегмент. Но если вы всего один лишний байт присылаете, сервер все равно отправит целый лишний сегмент.
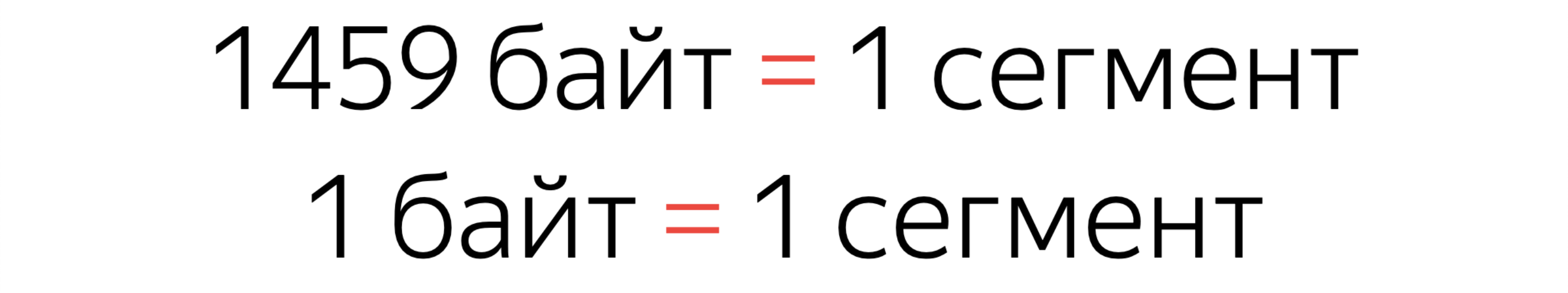
Вы можете сделать классную оптимизацию, на целый килобайт уменьшить выдачу, но на своих замерах ничего не увидите — возможно, именно из-за этого. Старайтесь делать оптимизацию нормально на несколько сегментов.
Странно: я верстальщик, а рассказываю такие сложные серверные штуки. Давайте еще ближе к настоящему CSS.
Отправляем меньше
Итак, мы меньше отправляем пользователю, меньше сегментов, быстрее приходит, пользователь радуется.

Минификация. Ее все у себя на проектах настроили. Есть куча классных инструментов, webpack-плагинов, gulp-настройки — в общем, разберетесь сами. Можно настраивать руками, но, кажется, только когда вы точно уверены, что сможете сжать ваш CSS круче какого-нибудь CSSO.
Не забудьте включить сжатие. Если у вас в 2020-м как минимум не включен gzip, вы точно делаете что-то не так, потому что это древняя техника сжатия. А вообще, в 2020-м пора использовать brotli. Это хороший способ на сколько-то сократить выдачу в Chromium-браузерах. Или, если вы не хотите поддерживать brotli, то как минимум можете попробовать zopfli.
Это достаточно медленный алгоритм сжатия для gzip, который просто дает лучшие результаты сжатия и распаковывается так же быстро, как и обычный gzip. Поэтому zopfli нужно настраивать с умом и использовать только тогда, когда вам не нужно выдавать данные на лету. Вы можете настроить, чтобы gzip-архивчики собирались при сборке с помощью алгоритма zopfli, а отправлялись уже статически, по факту, не собираясь на лету. Это может вам помочь. Но тоже замеряйте результаты.

Все эти алгоритмы используют какие-то словари: на основе повторяющихся фрагментов кода строится словарь. Но иногда говорят: надо инлайнить, если мы инлайним, то избавляемся от запроса. Заинлайним весь CSS в HTML, будет очень быстро. Прикол в том, что gzip работает немного эффективнее, когда вы разбиваете стили и HTML, потому что словари получаются разные, более эффективные.
В моем случае я просто взял страничку с bootstrap, заинлайнил туда bootstrap и сравнил две версии. Gzip над отдельными ресурсами меньше на 150 байт. Да, выигрыш очень маленький. Тут тоже надо все замерять. Но в вашем случае это может, например, снизить число сегментов на один.
Как оптимизировать код? Я говорю не про минификацию. Уберите то, что вы не используете в проекте. Скорее всего, у вас есть код, который никогда не выполнится на клиенте. Зачем?
Чтобы вы могли это автоматизировать, в браузер встроены специальные вкладки, например в Chrome DevTools это Coverage, который подсказывает: «этот CSS или этот JS я не использовал, можешь его выпилить».
Но у вас может быть hover, focus, active, что-то устанавливаемое при помощи JS. Вам нужно сымитировать все возможные действия на сайте, только тогда вы будете уверены, что этот CSS можно выпилить. У Криса Койера есть хорошая обзорная статья про автоматические инструменты, которые пытаются делать всякое с hover и focus. Но он пришел к мнению, что невозможно это автоматизировать. Пока не получается.
Есть хороший доклад Антона Холкина из Booking.com, где они тоже пытались убрать кучи legacy-кода. Но у них была особенность: legacy-код, который приходил из внешних проектов. Нужно было его убрать. Посмотрите, с какими интересными решениями они столкнулись.
Вы у себя можете попробовать поиграться с тем же самым Puppeteer, который как бы Chrome. Можете сделать тесты, которые автоматически проходятся по всему, пытаются делать hover, focus. И использовать этот самый Coverage.
Мой коллега Витя Хомяков victor-homyakov сделал свой скрипт, как, например, находить на странице дубликаты и стили. Просто берете, копипастите и используете. Он вам в консоли напишет: «этот селектор, кажется, вам не нужен». Вплоть до того, что просто в DevTools вводите. Классно же.
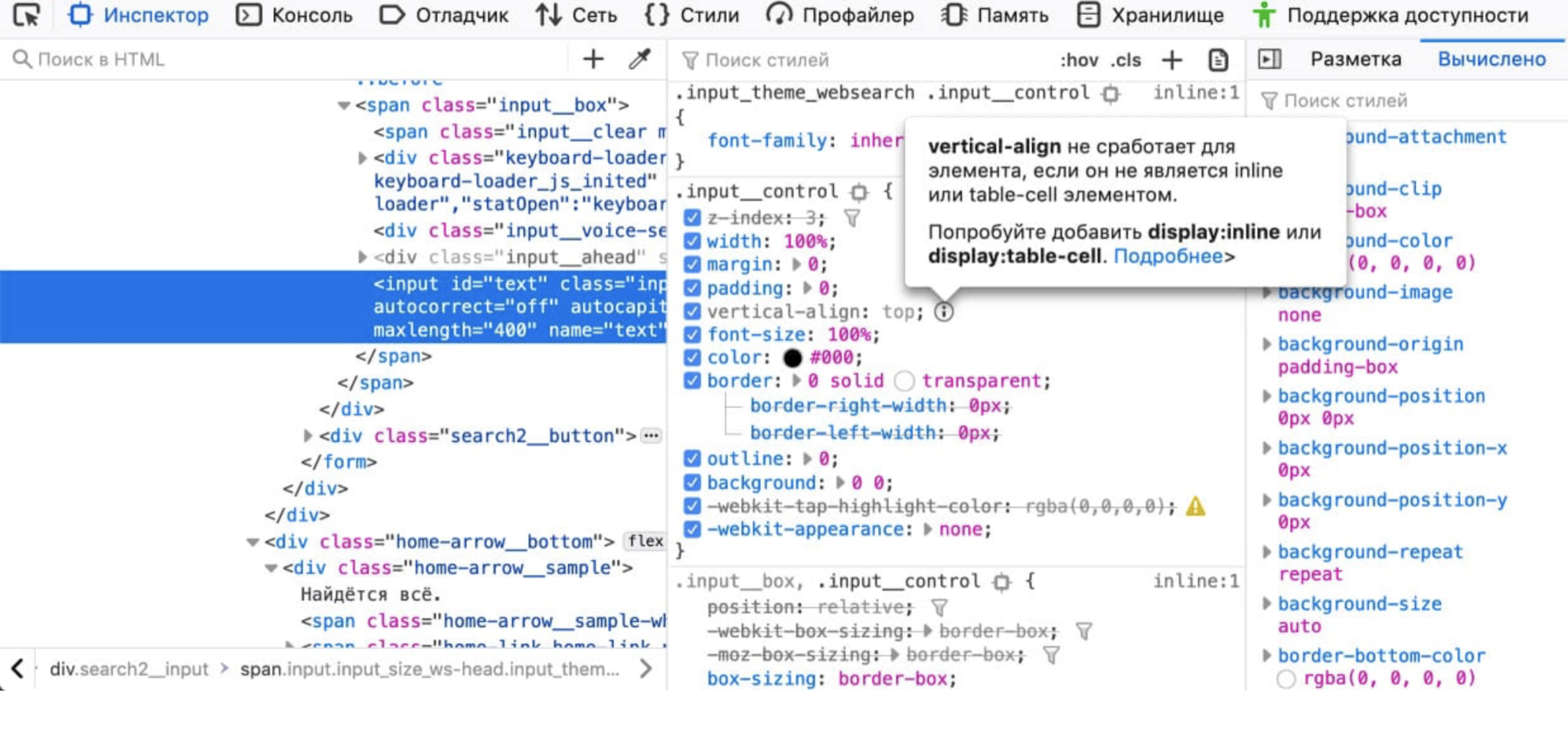
Фича, которая мне очень нравится в инструментах разработчиков Firefox: появилась возможность посмотреть стили, которые вроде бы используются, но на самом деле браузер их не применяет.
Например, вы можете выставить display: inline, и кажется, что у этого display: inline задавать размеры нет смысла. Или vertical-align, он работает только для inline или table-cell. Пока что я видел только в Firefox, что он может подсвечивать: «эта строчка тебе не нужна».
Здесь тоже нужно осторожно: возможно, вы используете этот стиль, чтобы потом подклеить класс. Но по-моему, классная фича.
Задайте себе прямо сейчас вопрос: вам на проекте нужен весь Bootstrap? Поставьте вместо Bootstrap любой CSS-фреймворк, который вы используете. Скорее всего, вы используете Bootstrap для сеток и более-менее распространенных элементов, и половина Bootstrap вам не нужна.
Попробуйте использовать сборку правильно. Почти все современные CSS-фреймворки позволяют использовать исходники для сборки и выбрать только то, что вам нужно. Это может радикально уменьшить размер бандла с CSS.
Не отдавайте неиспользуемое. Вместо того чтобы искать, что у меня legacy, вы можете использовать на уровне сборки понимание, что на страничке не будет использоваться этот CSS.
Например, полный БЭМ-стек позволяет сделать сборку так, что вы, уже отдавая страницу, можете построить дерево всех компонентов БЭМ-блоков, которые будут на странице. БЭМ позволяет определить, что, если этого блока нет на странице, незачем грузить этот CSS. Грузите только необходимое.
Даже ребята из Google говорят: используйте БЭМ, вам это реально может помочь для оптимизации.
Я не верю, что говорю это вслух, но в данном случае CSS-in-JS кажется хорошим подходом. Когда вы пишете независимые самостоятельные компоненты и аккуратно настраиваете сборку или в рантайме определяете, какие блоки используются, а какие нет, вы можете избавиться от проблемы поиска legacy-кода, просто не отправляя этот код на клиент. Звучит легко, но нужна дисциплина. Заранее продумайте это в начале проекта.

Какой еще вариант есть? Немножко безумный. В этом коде, кажется, style не нужен, потому что мы используем div — по умолчанию уже display: block. А давайте удалим все значения по умолчанию? Если в вашем проекте вы точно знаете, что HTML-разметка больше никогда меняться не будет — пройдитесь по дефолтным значениям, которые браузер уже предоставляет и уберите их.
Меньше стилей — классно! Но это опять безумная идея. CSS не должен знать про HTML, потому что это стиль. Он достаточно независимый, вы должны его подключить в другой проект, там должно заработать. И да, это тяжело поддерживать. Меняете тег — все ломается. Безумная идея, как обещал.
Используйте переменные. В CSS есть очень старые переменные, например currentColor.

Часто бывает паттерн: вы хотите, например, сделать кнопочку, у которой текст и граница одинаковые по цвету. А по hover мы меняем их обе. Зачем?

Есть переменная currentColor, которая берет значение из color, и вы ставите ее, например, в границе, проксируете это свойство и меняете всего одну строчку по hover, по focus, по active, по чему хотите. Это, кажется, удобно, и кода стало на строчку меньше. Можно оптимизировать. К слову, в этом примере можно вообще не использовать задание border-color, потому что по умолчанию он уже берет значение из свойства color.
Иногда очень грустно смотреть, как используется base64. В CSS его раньше активно рекомендовали: используйте base64, чтобы заинжектить маленькие иконки. Если это умещается у вас в один сегмент по TCP — на здоровье.

Но Гарри Робертс тоже провел классное исследование про то, как base64 влияет на загрузку страницы. Да, запросов становится меньше, но парсятся такие стили в разы медленнее.
Ладно, парсинг — очень быстрая операция, пользователь, скорее всего, не заметит. Но у нас важная метрика — первая отрисовка, чтобы пользователь что-то увидел на странице. На мобилках первая отрисовка, по исследованию Гарри Робертса, происходит в десять раз позже. Задумайтесь, нужен ли вам base64? Да, запросов стало меньше, но дало ли это эффект?
И пожалуйста, не используйте base64 для SVG. Потому что SVG отлично инкодится при помощи URL-encoder. У Юлии Бухваловой есть классный инструмент: заходите, вставляете ваш SVG, и он выдаст CSS в готовом для вставки виде. Можно заметить, что там нет base64, а экранируются какие-то вещи, которые в CSS могут восприняться не так. Это гораздо эффективнее.
В среднем base64 дает плюс 30% к размеру того, что вы сжимаете. Зачем?
Используйте современные технологии. Мы, возможно, должны поддерживать Internet Explorer — обычные аргументы, когда говоришь про гриды.

Но задумайтесь: если у вас нет поддержки IE, а вы все еще верстаете на float или таблицах, гридами можно сделать трехколоночную разметку с 20-пиксельным gap — вот это расстояние между колонками. Три строчки. Ну пять, если учитывать само объявление.
Попробуйте такое сделать на float. Причем я имею в виду, что мы меняем три строчки, в том числе название классов, если трогать HTML. Я не нашел способа так же классно сделать на float. Скидывайте ваши решения. Но используйте современные технологии. Они позволяют более компактно указывать разметку.

Вы можете попробовать Atomic CSS. Что это? Вы пишете вот такие слегка безумные имена классов. И через какое-то время начинаете понимать, что это вы задаете background-color или просто color. Это «функции» для CSS. Но у вас есть зафиксированный набор CSS, который вы затем используете в HTML как указание стиля. И CSS внезапно становится меньше. Для больших проектов он действительно станет меньше, потому что уникальных стилей меньше. Но у вас растет HTML.

Можете посмотреть в сторону Tailwind CSS, который сейчас набирает популярность. Он не Atomic CSS, он про утилитарные классы, похоже на Bootstrap, только более утилитарное. Вы можете использовать определенный набор. Кажется, вам хватит. Набор классов, которые выполняют свои функции. Тоже можете попробовать, но сильно не переусердствуйте.
Еще одна безумная идея — зачем нам целые имена классов на клиенте? Да, для разработки и отладки это удобно, но возьмем и все имена классов сделаем однобуквенными. Меньше же будет.
Вот статья, как это сделать. Вы можете настроить webpack или другой плагин при сборке. Но у нас это не взлетело. Мы пробовали.
Оказалось, gzip настолько классный, что у нас все было достаточно хорошо оптимизировано, а БЭМ с gzip офигенно дружат. Потому что повторяются текстовые конструкции для описания блоков и элементов в коде.
В общем, нам это не дало почти никакого профита. Но если у вас, например, не БЭМ и куча разнородных классов, можете попробовать.
Важно: замеряйте. Замеряйте все подобные экспериментальные штуки. Возможно, сейчас оно у вас работает, а потом вы слегка поменяли архитектуру проекта, оно начало собираться по-другому и все замедлилось.
Скачали!
До сих пор я рассказывал только о том, как скачать файл. Мы его скачали. Что все это время видел пользователь?

Он видел вот такой потрясающий экран. Пока мы скачивали, экран был пустой. Мы скачали, и браузер начинает еще шесть этапов. Потерпите немножко, я про них расскажу чуть быстрее, чем про загрузку.

Начнем с парсинга. Парсинг — это когда браузер скачал поток байтов, и начинает разбивать его на сущности, которые он понимает.

Например, он наткнулся на import. Это опять надо качать. Еще раз прочитать первый кусок доклада? import — блокирующая операция. Но браузеры умные. У них есть Preload Scanner. Я говорил, что там блочится все, это неправда. Браузеры знают, что, например, если стоят три подряд тега link, которые ходят за стилем, то когда я качаю первый, можно начать качать второй и третий. Парсить он не может, потому что ломается вся структура парсинга. Но скачать заранее — может.
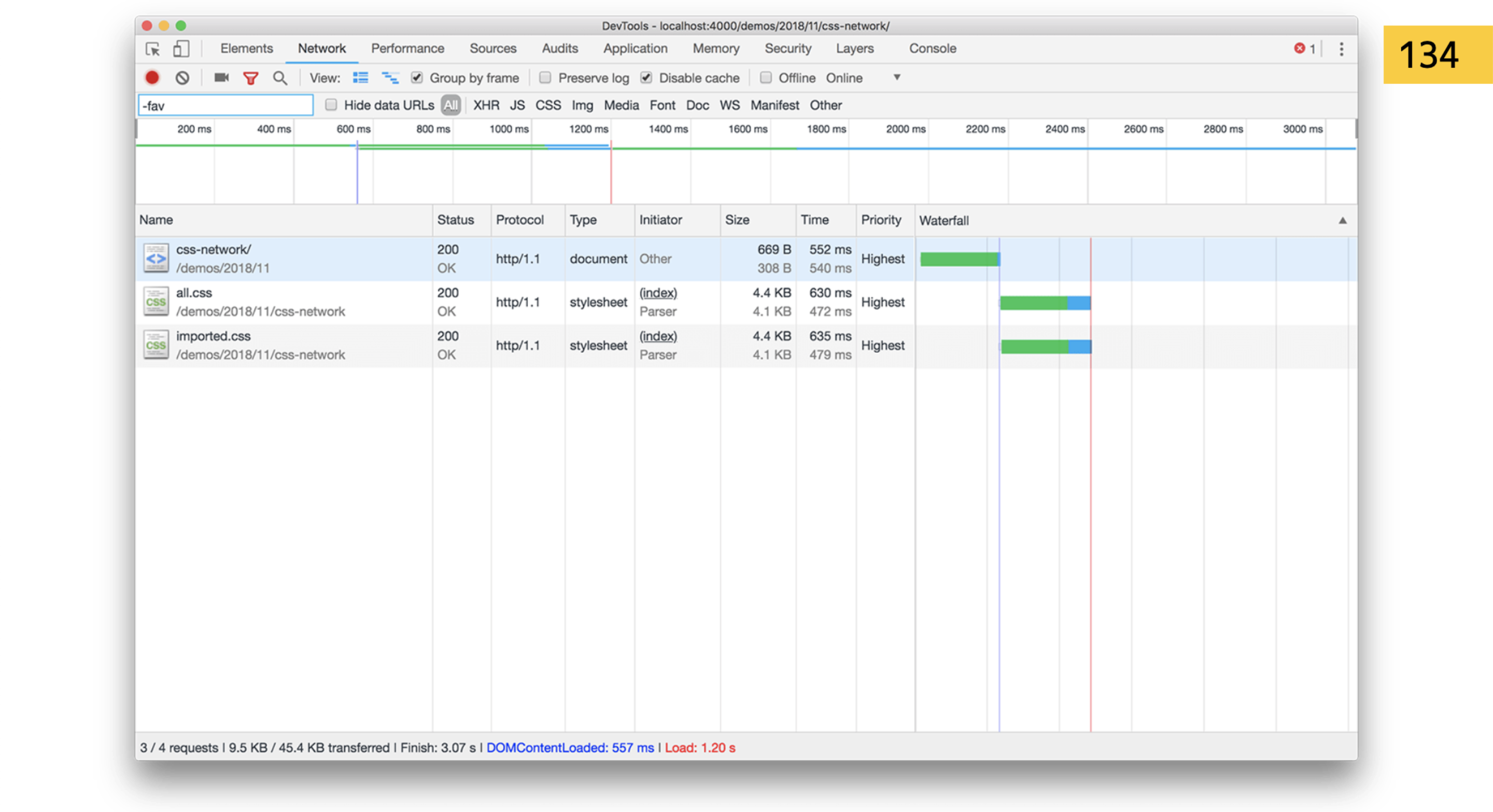
Так вот, import — плохая штука. Если в HTML стили идут подряд, браузер увидит, что мы дальше пойдем за другим файлом.
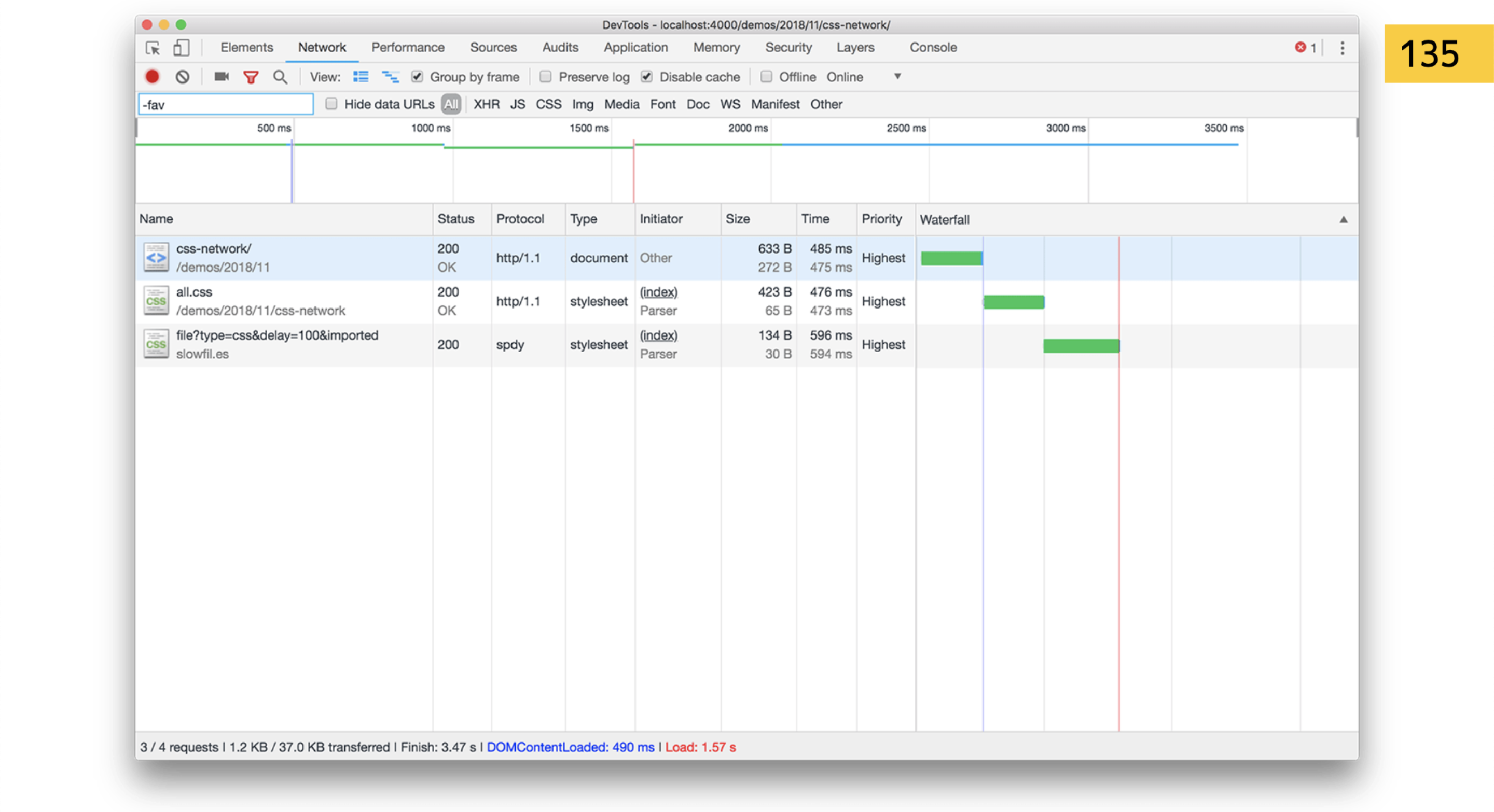
А если вы вставляете это прямо в import, он должен сначала скачать ваш style.css, потом увидеть в нем import. Он начинает парсить этот CSS… Ага, блочим все по новой и идем за файлом! Так вы можете сделать классный водопад с деоптимизацией на сайте.
Забудьте про import, либо настройте так, чтобы не было import уже после сборки. Для dev-окружения — окей, а для пользователя не надо.

Дальше идем по этапам построения деревьев, применения Cascade.
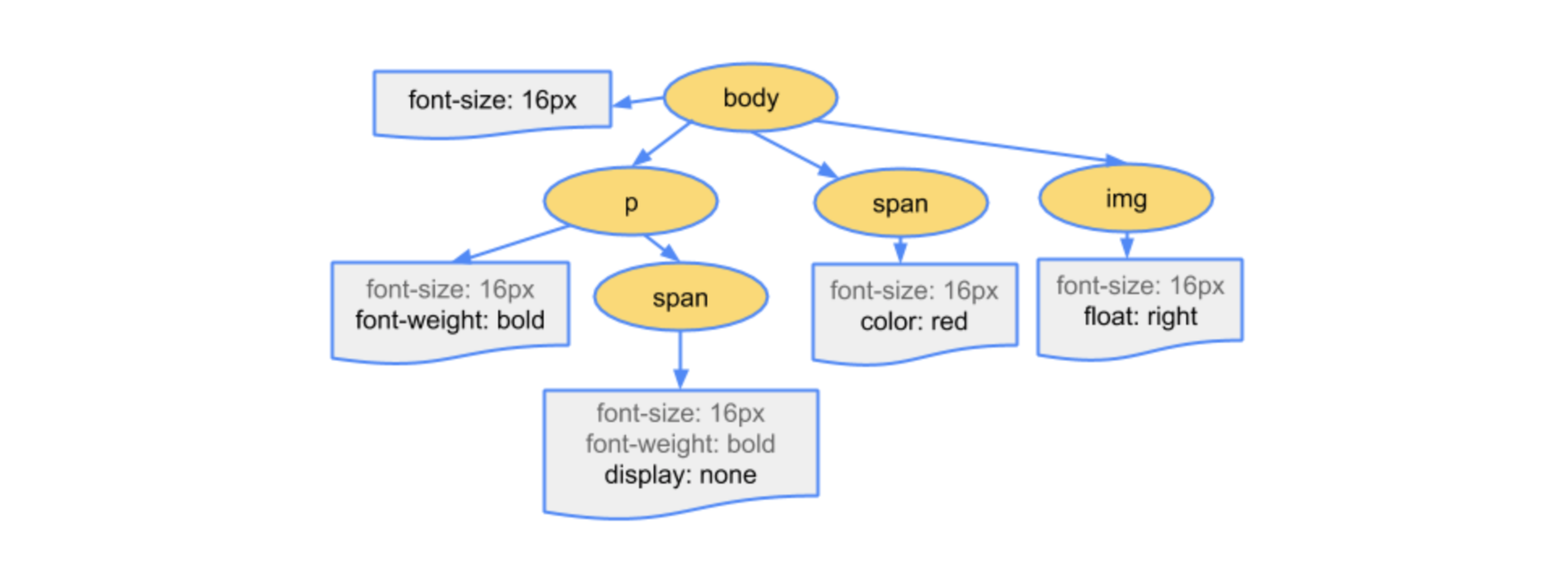
Все это тоже давно описано. Строится CSS Object Model — специальное дерево того, как браузер сопоставляет теги, классы со стилями. Он прилинковывает все это к DOM и делает эти связи очень быстро. Когда вы что-то меняете, ему достаточно поменять это внутри дерева.

Чем больше селектор, тем сложнее браузеру нарисовать дерево. Ему нужно распарсить селектор, преобразовать в древовидные конструкции. А если вы еще! important там вставили, то ему и это надо учитывать.

Кажется, снова пора поговорить про БЭМ. Но не обязательно БЭМ, если вы умеете использовать утилитарные классы, если один класс отвечает за одну функциональность и они друг другу не мешают. Тогда строить дерево очень просто. У вас достаточно плоская структура и браузер потом должен это правильно слинковать с DOM.

Если вы так делаете, то, говорят, такие селекторы замедляют парсинг CSS. Но это давным-давно легенды, разница настолько маленькая для браузера, что в среднестатистическом проекте вы ее не заметите, если оптимизируете селекторы со звездочками. Но вам было бы приятно такой код разрабатывать и поддерживать?

Раньше я слышал советы: попробуйте все помещать в шорткат. background — это шорткат для большого количества других свойств. Мы же помещаем все в одно свойство, и оно становится оптимальным.
По байтам да, оно становится меньше. Но если вы хотите оптимизировать именно составление CSS OM, то браузер все равно сделает из background все эти свойства. Браузеры для каждого DOM-элемента строят таблицу всех свойств, которые у него могут быть. Когда вы смотрите в DevTools computed values, они там есть не потому, что браузер их рассчитал по вашему требованию. Он хранит это в памяти, потому что так гораздо проще переписать одно свойство и все работает.
Тоже очень странный совет, но если вы хотите сделать CSS OM быстрее, то можете сразу задавать все свойства по одному. Это может сработать. Но размер бандла сильно вырастет. Вам нужно замерять. Я сомневаюсь, что это даст профит, но вдруг!
Когда строится CSS OM, JS в этот момент тоже заблокирован. Если построение CSS OM занимает две секунды, JS не выполняется. Хотя я не представляю, как вы умудрились столько написать на CSS, что дерево строится две секунды.

Дальше браузер делает Layout. Это расположение всех DOM-элементов, применение позиций. Он понимает, где элемент должен находиться и с какими размерами. Кажется, на этом этапе пользователь уже должен ув
