Безопасность и СУБД: о чём надо помнить, подбирая средства защиты
Меня зовут Денис Рожков, я руководитель разработки ПО в компании «Газинформсервис», в команде продукта Jatoba. Законодательство и корпоративные нормы накладывают определенные требования к безопасности хранения данных. Никто не хочет, чтобы третьи лица получили доступ к конфиденциальной информации, поэтому для любого проекта важны следующие вопросы: идентификация и аутентификация, управление доступами к данным, обеспечение целостности информации в системе, регистрация событий безопасности. Поэтому я хочу рассказать о некоторых интересных моментах, касающихся безопасности СУБД.
Статья подготовлена по выступлению на @Databases Meetup, организованном Mail.ru Cloud Solutions. Если не хотите читать, можно посмотреть:
В статье будет три части:
- Как защищать подключения.
- Что такое аудит действий и как фиксировать, что происходит со стороны базы данных и подключения к ней.
- Как защищать данные в самой базе данных и какие для этого есть технологии.
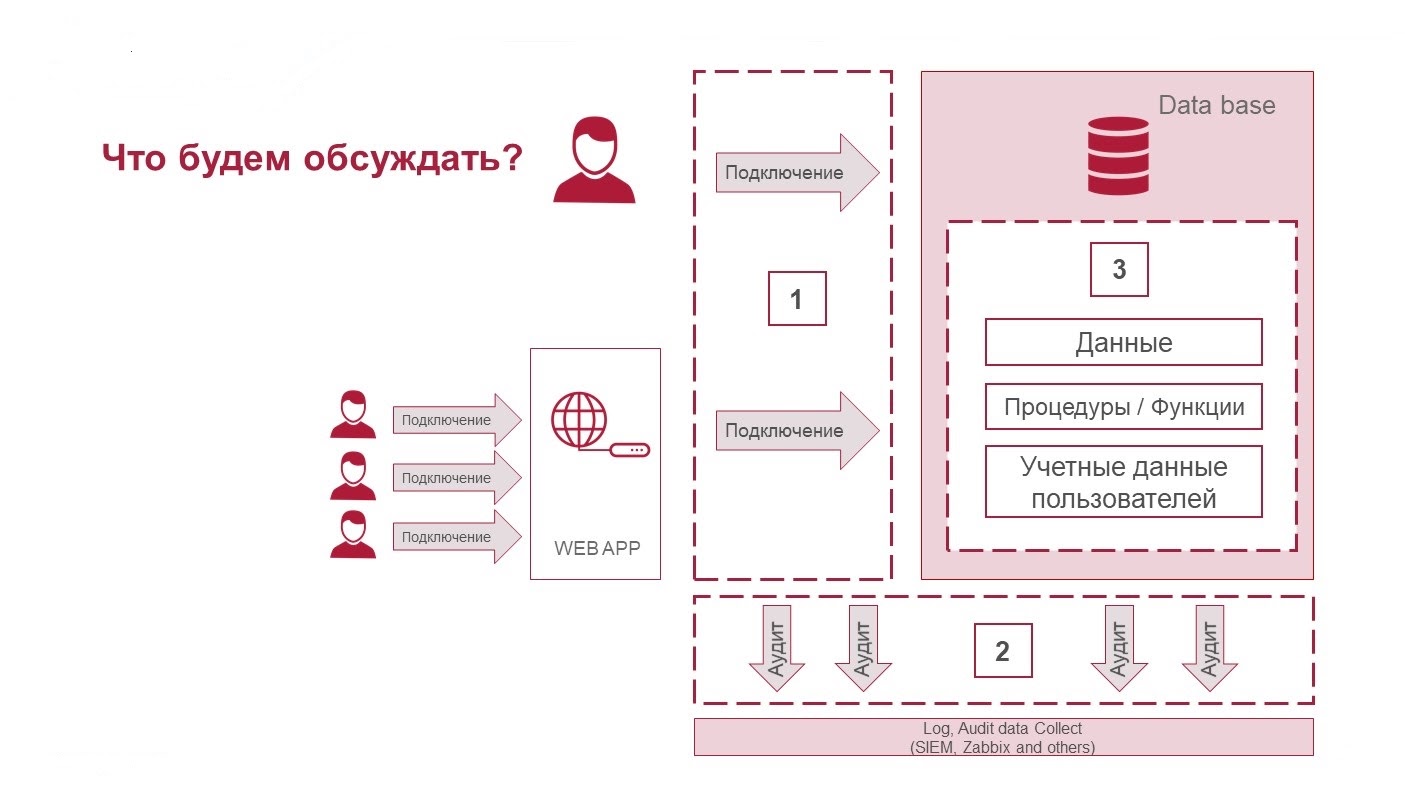
Три составляющих безопасности СУБД: защита подключений, аудит действий и защита данных
Защита подключений
Подключаться к базе данных можно как напрямую, так и опосредованно через веб-приложения. Как правило, пользователь со стороны бизнеса, то есть человек, который работает с СУБД, взаимодействует с ней не напрямую.
Перед тем как говорить о защите соединений, нужно ответить на важные вопросы, от которых зависит, как будут выстраиваться мероприятия безопасности:
- эквивалентен ли один бизнес-пользователь одному пользователю СУБД;
- обеспечивается ли доступ к данным СУБД только через API, который вы контролируете, либо есть доступ к таблицам напрямую;
- выделена ли СУБД в отдельный защищенный сегмент, кто и как с ним взаимодействует;
- используется ли pooling/proxy и промежуточные слои, которые могут изменять информацию о том, как выстроено подключение и кто использует базу данных.
Теперь посмотрим, какие инструменты можно применить для защиты подключений:
- Используйте решения класса database firewall. Дополнительный слой защиты, как минимум, повысит прозрачность того, что происходит в СУБД, как максимум — вы сможете обеспечить дополнительную защиту данных.
- Используйте парольные политики. Их применение зависит от того, как выстроена ваша архитектура. В любом случае — одного пароля в конфигурационном файле веб-приложения, которое подключается к СУБД, мало для защиты. Есть ряд инструментов СУБД, позволяющих контролировать, что пользователь и пароль требуют актуализации.
Почитать подробнее про функции оценки пользователей можно здесь, так же про MS SQL Vulnerability Assessmen можно узнать тут.
- Обогащайте контекст сессии нужной информацией. Если сессия непрозрачная, вы не понимаете, кто в ее рамках работает в СУБД, можно в рамках выполняемой операции дополнить информацию о том, кто, что и зачем делает. Эту информацию можно увидеть в аудите.
- Настраивайте SSL, если у вас нет сетевого разграничения СУБД от конечных пользователей, она не в отдельном VLAN. В таких случаях обязательно защищать канал между потребителем и самой СУБД. Инструменты защиты есть в том числе и среди open source.
Как это повлияет на производительность СУБД?
Посмотрим на примере PostgreSQL, как SSL влияет на нагрузку CPU, увеличение таймингов и уменьшение TPS, не уйдет ли слишком много ресурсов, если его включить.
Нагружаем PostgreSQL, используя pgbench — это простая программа для запуска тестов производительности. Она многократно выполняет одну последовательность команд, возможно в параллельных сеансах базы данных, а затем вычисляет среднюю скорость транзакций.
Тест 1 без SSL и с использованием SSL — соединение устанавливается при каждой транзакции:
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"
vs
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"
Тест 2 без SSL и с использованием SSL — все транзакции выполняются в одно соединение:
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"
vs
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"
Остальные настройки:
scaling factor: 1
query mode: simple
number of clients: 10
number of threads: 1
number of transactions per client: 5000
number of transactions actually processed: 50000/50000
Результаты тестирования:
При небольших нагрузках влияние SSL сопоставимо с погрешностью измерения. Если объем передаваемых данных очень большой, ситуация может быть другая. Если мы устанавливаем одно соединение на каждую транзакцию (это бывает редко, обычно соединение делят между пользователями), у вас большое количество подключений/отключений, влияние может быть чуть больше. То есть риски снижения производительности могут быть, однако, разница не настолько большая, чтобы не использовать защиту.
Обратите внимание — сильное различие есть, если сравнивать режимы работы: в рамках одной сессии вы работаете или разных. Это понятно: на создание каждого соединения тратятся ресурсы.
У нас был кейс, когда мы подключали Zabbix в режиме trust, то есть md5 не проверяли, в аутентификации не было необходимости. Потом заказчик попросил включить режим md5-аутентификации. Это дало большую нагрузку на CPU, производительность просела. Стали искать пути оптимизации. Одно из возможных решений проблемы — реализовать сетевое ограничение, сделать для СУБД отдельные VLAN, добавить настройки, чтобы было понятно, кто и откуда подключается и убрать аутентификацию.Также можно оптимизировать настройки аутентификации, чтобы снизить издержки при включении аутентификации, но в целом применение различных методов аутентификации влияет на производительность и требует учитывать эти факторы при проектировании вычислительных мощностей серверов (железа) для СУБД.
Вывод: в ряде решений даже небольшие нюансы на аутентификации могут сильно сказаться на проекте и плохо, когда это становится понятно только при внедрении в продуктив.
Аудит действий
Аудит может быть не только СУБД. Аудит — это получение информации о том, что происходит на разных сегментах. Это может быть и database firewall, и операционная система, на которой строится СУБД.
В коммерческих СУБД уровня Enterprise с аудитом все хорошо, в open source — не всегда. Вот, что есть в PostgreSQL:
- default log — встроенное логирование;
- extensions: pgaudit — если вам не хватает дефолтного логирования, можно воспользоваться отдельными настройками, которые решают часть задач.
Дополнение к докладу в видео:
«Базовая регистрация операторов может быть обеспечена стандартным средством ведения журнала с log_statement = all.
Это приемлемо для мониторинга и других видов использования, но не обеспечивает уровень детализации, обычно необходимый для аудита.
Недостаточно иметь список всех операций, выполняемых с базой данных.
Также должна быть возможность найти конкретные утверждения, которые представляют интерес для аудитора.
Стандартное средство ведения журнала показывает то, что запросил пользователь, в то время как pgAudit фокусируется на деталях того, что произошло, когда база данных выполняла запрос.
Например, аудитор может захотеть убедиться, что конкретная таблица была создана в задокументированном окне обслуживания.
Это может показаться простой задачей для базового аудита и grep, но что, если вам представится что-то вроде этого (намеренно запутанного) примера:
DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;
Стандартное ведение журнала даст вам это:
LOG: statement: DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;
Похоже, что для поиска интересующей таблицы может потребоваться некоторое знание кода в тех случаях, когда таблицы создаются динамически.
Это не идеально, так как было бы предпочтительнее просто искать по имени таблицы.
Вот где будет полезен pgAudit.
Для того же самого ввода он выдаст этот вывод в журнале:
AUDIT: SESSION,33,1, FUNCTION, DO,,, «DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;»
AUDIT: SESSION,33,2, DDL, CREATE TABLE, TABLE, public.important_table, CREATE TABLE important_table (id INT)
Регистрируется не только блок DO, но и полный текст CREATE TABLE с типом оператора, типом объекта и полным именем, что облегчает поиск.
При ведении журнала операторов SELECT и DML pgAudit можно настроить для регистрации отдельной записи для каждого отношения, на которое есть ссылка в операторе.
Не требуется синтаксический анализ, чтобы найти все операторы, которые касаются конкретной таблицы (*)».
Как это повлияет на производительность СУБД?
Давайте проведем тесты с включением полного аудита и посмотрим, что будет с производительностью PostgreSQL. Включим максимальное логирование БД по всем параметрам.
В конфигурационном файле почти ничего не меняем, из важного — включаем режим debug5, чтобы получить максимум информации.
postgresql.conf
На СУБД PostgreSQL с параметрами 1 CPU, 2,8 ГГц, 2 Гб ОЗУ, 40 Гб HDD проводим три нагрузочных теста, используя команды:
$ pgbench -p 3389 -U postgres -i -s 150 benchmark
$ pgbench -p 3389 -U postgres -c 50 -j 2 -P 60 -T 600 benchmark
$ pgbench -p 3389 -U postgres -c 150 -j 2 -P 60 -T 600 benchmark
Результаты тестирования:
В итоге: полный аудит — это не очень хорошо. Данных от аудита получится по объему, как данных в самой базе данных, а то и больше. Такой объем журналирования, который генерится при работе с СУБД, — обычная проблема на продуктиве.
Смотрим другие параметры:
- Скорость сильно не меняется: без логирования — 43,74 сек, с логированием — 53,23 сек.
- Производительность по ОЗУ и CPU будет проседать, так как нужно сформировать файл с аудитом. Это также заметно на продуктиве.
При увеличении числа коннектов, естественно, показатели будут немного ухудшаться.
В корпорациях с аудитом еще сложнее:
- данных много;
- аудит нужен не только через syslog в SIEM, но и в файлы: вдруг с syslog что-то произойдет, должен быть близко к базе файл, в котором сохранятся данные;
- для аудита нужна отдельная полка, чтобы не просесть по I/O дисков, так как он занимает много места;
- бывает, что сотрудникам ИБ нужны везде ГОСТы, они требуют гостовую идентификацию.
Ограничение доступа к данным
Посмотрим на технологии, которые используют для защиты данных и доступа к ним в коммерческих СУБД и open source.
Что в целом можно использовать:
- Шифрование и обфускация процедур и функций (Wrapping) — то есть отдельные инструменты и утилиты, которые из читаемого кода делают нечитаемый. Правда, потом его нельзя ни поменять, ни зарефакторить обратно. Такой подход иногда требуется как минимум на стороне СУБД — логика лицензионных ограничений или логика авторизации шифруется именно на уровне процедуры и функции.
- Ограничение видимости данных по строкам (RLS) — это когда разные пользователи видят одну таблицу, но разный состав строк в ней, то есть кому-то что-то нельзя показывать на уровне строк.
- Редактирование отображаемых данных (Masking) — это когда пользователи в одной колонке таблицы видят или данные, или только звездочки, то есть для каких-то пользователей информация будет закрыта. Технология определяет, какому пользователю что показывать с учетом уровня доступа.
- Разграничение доступа Security DBA/Application DBA/DBA — это, скорее, про ограничение доступа к самой СУБД, то есть сотрудников ИБ можно отделить от database-администраторов и application-администраторов. В open source таких технологий немного, в коммерческих СУБД их хватает. Они нужны, когда много пользователей с доступом к самим серверам.
- Ограничение доступа к файлам на уровне файловой системы. Можно выдавать права, привилегии доступа к каталогам, чтобы каждый администратор получал доступ только к нужным данным.
- Мандатный доступ и очистка памяти — эти технологии применяют редко.
- End-to-end encryption непосредственно СУБД — это client-side шифрование с управлением ключами на серверной стороне.
- Шифрование данных. Например, колоночное шифрование — когда вы используете механизм, который шифрует отдельную колонку базы.
Как это влияет на производительность СУБД?
Посмотрим на примере колоночного шифрования в PostgreSQL. Там есть модуль pgcrypto, он позволяет в зашифрованном виде хранить избранные поля. Это полезно, когда ценность представляют только некоторые данные. Чтобы прочитать зашифрованные поля, клиент передает дешифрующий ключ, сервер расшифровывает данные и выдает их клиенту. Без ключа с вашими данными никто ничего не сможет сделать.
Проведем тест c pgcrypto. Создадим таблицу с зашифрованными данными и с обычными данными. Ниже команды для создания таблиц, в самой первой строке полезная команда — создание самого extension с регистрацией СУБД:
CREATE EXTENSION pgcrypto;
CREATE TABLE t1 (id integer, text1 text, text2 text);
CREATE TABLE t2 (id integer, text1 bytea, text2 bytea);
INSERT INTO t1 (id, text1, text2)
VALUES (generate_series(1,10000000), generate_series(1,10000000)::text, generate_series(1,10000000)::text);
INSERT INTO t2 (id, text1, text2) VALUES (
generate_series(1,10000000),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'));
Дальше попробуем сделать из каждой таблицы выборку данных и посмотрим на тайминги выполнения.
Выборка из таблицы без функции шифрования:
psql -c "\timing" -c "select * from t1 limit 1000;" "host=192.168.220.129 dbname=taskdb
user=postgres sslmode=disable" > 1.txt
Секундомер включен.
id | text1 | text2
------±------±------
1×1 | 1
2×2 | 2
3×3 | 3
…
997×997 | 997
998×998 | 998
999×999 | 999
1000×1000 | 1000
(1000 строк)
Время: 1,386 мс
Выборка из таблицы с функцией шифрования:
psql -c "\timing" -c "select id, decrypt(text1, 'key'::bytea, 'bf'),
decrypt(text2, 'key'::bytea, 'bf') from t2 limit 1000;"
"host=192.168.220.129 dbname=taskdb user=postgres sslmode=disable" > 2.txt
Секундомер включен.
id | decrypt | decrypt
-----±-------------±-----------
1 | \x31 | \x31
2 | \x32 | \x32
3 | \x33 | \x33
…
999 | \x393939 | \x393939
1000 | \x31303030 | \x31303030
(1000 строк)
Время: 50,203 мс
Результаты тестирования:
Шифрование сильно влияет на производительность. Видно, что вырос тайминг, так как операции дешифрации зашифрованных данных (а дешифрация обычно еще обернута в вашу логику) требуют значительных ресурсов. То есть идея зашифровать все колонки, содержащие какие-то данные, чревата снижением производительности.
При этом шифрование не серебряная пуля, решающая все вопросы. Расшифрованные данные и ключ дешифрования в процессе расшифровывания и передачи данных находятся на сервере. Поэтому ключи могут быть перехвачены тем, кто имеет полный доступ к серверу баз данных, например системным администратором.
Когда на всю колонку для всех пользователей один ключ (даже если не для всех, а для клиентов ограниченного набора), — это не всегда хорошо и правильно. Именно поэтому начали делать end-to-end шифрование, в СУБД стали рассматривать варианты шифрования данных со стороны клиента и сервера, появились те самые key-vault хранилища — отдельные продукты, которые обеспечивают управление ключами на стороне СУБД.
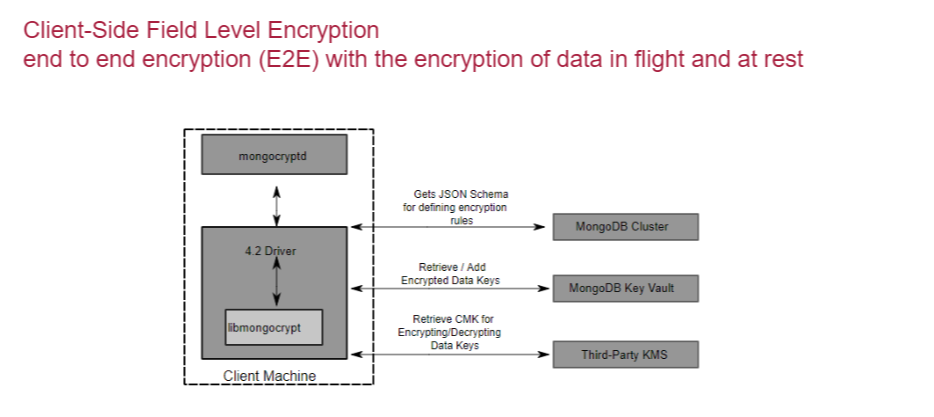
Пример такого шифрования в MongoDB
Средства безопасности в коммерческих и open source СУБД
Таблица далеко не полная, но ситуация такая: в коммерческих продуктах задачи безопасности решаются давно, в open source, как правило, для безопасности используют какие-то надстройки, многих функций не хватает, иногда приходится что-то дописывать. Например, парольные политики — в PostgreSQL много разных расширений (1, 2, 3, 4, 5), которые реализуют парольные политики, но все потребности отечественного корпоративного сегмента, на мой взгляд, ни одно не покрывает.
Что делать, если нигде нет того, что нужно? Например, хочется использовать определенную СУБД, в которой нет функций, которые требует заказчик.
Тогда можно использовать сторонние решения, которые работают с разными СУБД, например, «Крипто БД» или «Гарда БД». Если речь о решениях из отечественного сегмента, то там про ГОСТы знают лучше, чем в open source.
Второй вариант — самостоятельно написать, что нужно, реализовать на уровне процедур доступ к данным и шифрование в приложении. Правда, с ГОСТом будет сложнее. Но в целом — вы можете скрыть данные, как нужно, сложить в СУБД, потом достать и расшифровать как надо, прямо на уровне application. При этом сразу думайте, как вы будете эти алгоритмы на application защищать. На наш взгляд, это нужно делать на уровне СУБД, потому что так будет работать быстрее.
Этот доклад впервые прозвучал на @Databases Meetup by Mail.ru Cloud Solutions. Смотрите видео других выступлений и подписывайтесь на анонсы мероприятий в Telegram Вокруг Kubernetes в Mail.ru Group.
Что еще почитать по теме:
- Больше чем Ceph: блочное хранилище облака MCS.
- Как выбрать базу данных для проекта, чтобы не выбирать снова.
