[Перевод] 5 уровней зрелости MLOps

Google и Microsoft представили свои уровни зрелости MLOps — они описывают развитие инфраструктуры ML на основе лучших практик в отрасли. Команда VK Cloud перевела статью, в которой описано лучшее из обоих фреймворков.
Короткое введение
Создание инфраструктуры для систем машинного обучения — это большая и тяжёлая задача, для выполнения которой нужно убедиться, что разработка и развёртывание приложений машинного обучения проходят организованно и слаженно. Проблема в том, что потребности в инфраструктуре в каждой компании разные: они зависят от количества ML-приложений, необходимой скорости их разворачивания и количества запросов, которые нужно обработать.
Например, если компания занимается разработкой одной модели, развёртывание может быть ручным. Однако большим компаниям, таким как Uber или Netflix, которые работают над сотнями моделей, нужна высокоспециализированная инфраструктура для их поддержки.
Для начала задайте себе вопрос: какое место занимает ваша компания в этой градации?
Google и Microsoft представили свои уровни зрелости MLOps — они описывают развитие инфраструктуры ML на основе лучших практик в отрасли. Цель этой статьи — обобщить и взять лучшее из обоих фреймворков. Сначала мы проанализируем пять уровней зрелости и покажем переход от ручных процессов к продвинутым автоматизированным инфраструктурам. Затем разберёмся, почему нужно не слепо следовать некоторым пунктам, представленным Microsoft и Google, а скорее адаптировать их к потребностям компании. Это поможет лучше определять, на каком этапе находится инфраструктура компании, и искать потенциальные области для улучшения.
Что такое MLOps
MLOps — это набор практик для создания стандартизированного и повторяемого процесса управления всем жизненным циклом модели машинного обучения: подготовкой данных, обучением, развёртыванием и мониторингом. Этот подход заимствован из широко распространённых DevOps-практик в области разработки программного обеспечения, которые подразумевают быстрое и итеративное создание приложений.
Однако DevOps-практики не всегда подходят для машинного обучения, потому что они отличаются:
- MLOps требует многопрофильной команды: инженеров по сбору и хранению данных, специалистов по обработке данных, специалистов по машинному обучению (MLE), которые смогут разворачивать модели, а также разработчиков, которые смогут интегрировать модель в продукт.
- Анализ данных постоянно совершенствуется благодаря изучению новых моделей и способам анализа данных, методов обучения и конфигураций гиперпараметров. Инфраструктура, поддерживающая MLOps, должна включать в себя отслеживание и оценку успешных и неуспешных подходов.
- Даже если модель уже работает в продакшене, она всё равно может выйти из строя из-за изменений в поступающих данных (data and concept drift) — это называется скрытым сбоем модели. Следовательно, инфраструктура машинного обучения требует системы мониторинга для постоянной проверки performance модели и данных.
Рассмотрим различные уровни зрелости инфраструктур MLOps.
Уровень №1 — ручной

Ручная инфраструктура машинного обучения. Дизайн, навеянный статьёй Google
На этом уровне процессы обработки данных, экспериментирования и развёртывания моделей выполняются полностью вручную. Microsoft называет этот уровень «без MLOps», потому что жизненный цикл модели машинного обучения трудно повторить и автоматизировать.
Весь процесс создания модели по большей части выполняют квалифицированные data-специалисты с помощью инженера по обработке данных, который готовит данные, и разработчика для интеграции модели с продуктом или бизнес-процессами.
В каких случаях этот подход уместен:
- Early-stage-стартапы. Там, где основное внимание уделяется экспериментам, а ресурсы ограничены. Разработка и развёртывание моделей машинного обучения является основной задачей до начала масштабирования операций.
- Маломасштабные приложения машинного обучения. Ручного подхода будет вполне достаточно для ML-приложений с ограниченной областью применения или маленькой аудиторией пользователей, например в небольших интернет-магазинах одежды. В этом случае модель будет минимально зависима от данных, и data-специалисты могут вручную управлять процессами обработки, экспериментирования и развёртывания.
- Специфичные задачи. В конкретных сценариях, таких как маркетинговые кампании, разовые задачи для ML или анализ данных, полное внедрение MLOps может не понадобиться.
По мнению Google и Microsoft, использование этого подхода связано с рядом ограничений, в том числе:
- Отсутствие системы мониторинга. Разработчики не получают никакой информации об эффективности модели. Если она ухудшится, это окажет негативное влияние на бизнес. Кроме того, важно анализировать данные уже после развёртывания модели, чтобы понять её поведение в рабочей среде.
- Модель не переобучают и не адаптируют к последним тенденциям или паттернам.
- Релизы проходят болезненно и нерегулярно. Поскольку это делается вручную, обновления выпускают всего пару раз в год.
- Отсутствие централизованного отслеживания эффективности моделей. Это затрудняет сравнение эффективности, повторяемость или возможность обновления.
- Ограниченная документация и отсутствие контроля версий. Это создаёт несколько проблем с точки зрения риска внесения непреднамеренных изменений в код, роллбэка и воспроизводимости.
Уровень №2 — повторяемый

Повторяемая модель с дополнительными системами хранения и мониторинга
Далее мы добавляем DevOps в инфраструктуру, конвертируя эксперименты в исходный код и сохраняя их в репозитории с использованием системы контроля версий, такой как Git.
Microsoft предлагает внести изменения в сбор данных, добавив:
- Пайплайн данных. Он позволяет извлекать данные из разных источников и объединять. Затем данные очищают, агрегируют или фильтруют. Это делает инфраструктуру более масштабируемой, эффективной и точной, нежели при использовании её вручную.
- Каталог данных. Централизованный репозиторий, включающий в себя источник данных, тип, формат, владельца, использование и происхождение. Это помогает организовывать, управлять и поддерживать большие объёмы данных масштабируемым и эффективным образом.
Чтобы повысить уровень инфраструктуры, необходимо внедрить автоматизированное тестирование наряду с контролем версий: юнит-тестирование, интеграционные или регрессионные тесты. Это поможет ускорить развёртывание и повысить уверенность, что изменения в коде не приведут к багам.
После внесения всех этих изменений мы можем повторить сбор данных и деплоймент, однако для этого по-прежнему нужна система мониторинга. Microsoft упоминает об этом, не вдаваясь в подробности, говоря, что есть «ограниченное количество отзывов о том, насколько хорошо модель работает на продакшене».
Уровень №3 — воспроизводимый
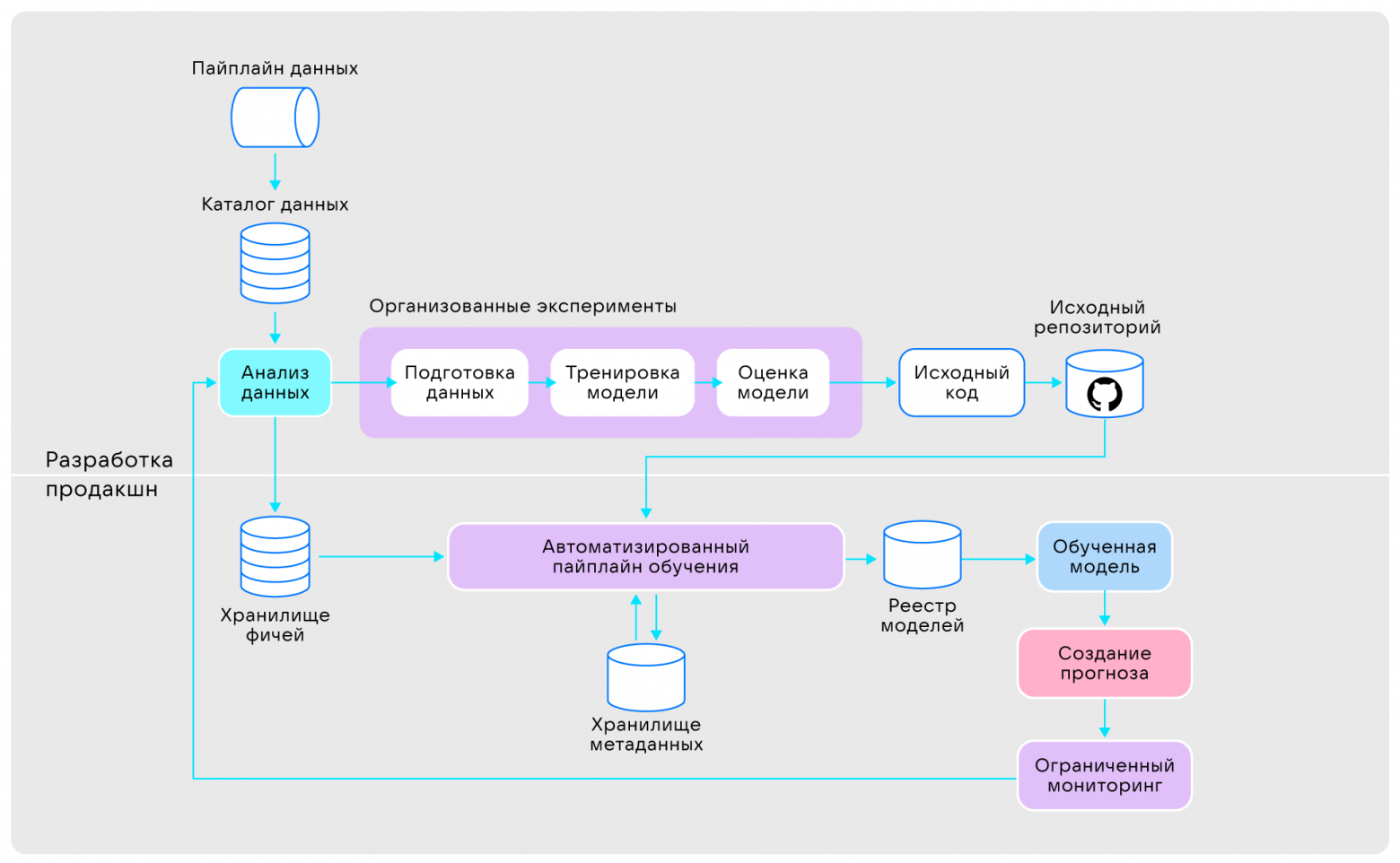
Воспроизводимая инфраструктура модели машинного обучения с автоматизированным обучением и организованными экспериментами
Есть две ключевые причины, почему воспроизводимость модели важна: возможность устранения багов и возможность совместной работы. Если эффективность модели ухудшится, её прогнозы станут неточными — придётся вести учёт предыдущих версий данных и модели, чтобы выполнить роллбэк версию модели до тех пор, пока вы не найдёте причину.
Кроме того, воспроизводимость позволяет другим членам команды понимать ход работы друг друга. Такой совместный подход и обмен знаниями способствует более быстрым инновациям и совершенствованию моделей.
Есть четыре способа совершенствования архитектуры для воспроизводимости модели:
- Пайплайн автоматизированного обучения. Управляет end-to-end-процессом обучения моделей — от подготовки данных до оценки модели.
- Хранилище метаданных. Необходимо для отслеживания метаданных и управления ими, включая источники, конфигурации моделей, гиперпараметры, тренировочные прогоны, метрики и все данные для экспериментов.
- Хранилище моделей (Model registry). Это репозиторий для хранения моделей машинного обучения, их предыдущих версий и артефактов, необходимых для развёртывания, чтобы при необходимости извлечь определённую версию.
- Feature store («магазин» фич). Нужен для того, чтобы помочь специалистам по обработке данных и инженерам по машинному обучению эффективнее разрабатывать, тестировать и развёртывать модели машинного обучения, предоставляя централизованный «магазин» для хранения, управления и фич. С его помощью можно отслеживать улучшения фич с течением времени, а также обрабатывать и преобразовывать их по мере необходимости.
На этом этапе можно начинать использовать службу мониторинга, предоставляющую обратную связь об эффективности модели в режиме реального времени. Однако, помимо подтверждения её наличия, ни Microsoft, ни Google не предоставляют никакой дополнительной информации.
Уровень №4 — автоматизированный

Автоматизированная инфраструктура модели машинного обучения с CI/CD
Этот уровень автоматизации помогает специалистам по обработке данных эффективнее проверять новые идеи по разработке фич, архитектуре моделей и гиперпараметров. Это позволяет автоматизировать пайплайн машинного обучения, в том числе создание, тестирование и развёртывание. Для достижения этой цели Microsoft предлагает включить два дополнительных компонента:
- CI/CD. Непрерывная интеграция (CI) обеспечивает объединение изменений кода от разных членов команды в общем репозитории, в то время как непрерывное развёртывание (CD) автоматизирует развёртывание проверенного кода в продакшене. Это позволяет быстро внедрять обновления модели, улучшения и исправления багов.
- A/B-тестирование моделей. Включает в себя сравнение прогнозов между существующей моделью и моделью-кандидатом для определения лучшей из них.
Уровень №5 — непрерывно совершенствующийся
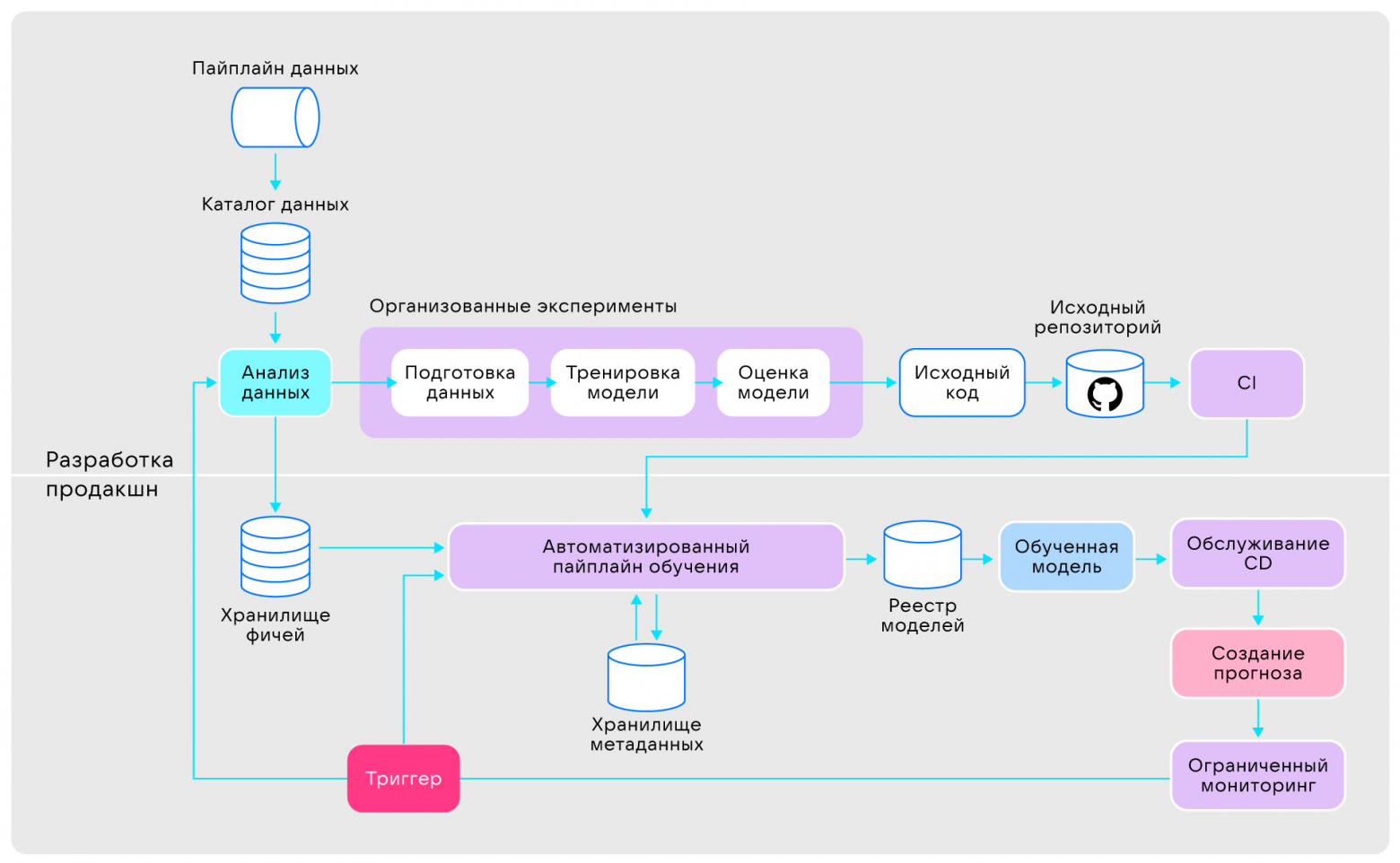
Постоянно улучшающаяся модель машинного обучения с автоматизированным повторным обучением
На этом этапе модель автоматически обучается на основе триггера из системы мониторинга. Цели:
- Борьба с возможными внезапными дрейфами данных (data drift), что гарантирует сохранение эффективности модели даже при неожиданных изменениях в данных.
- Адаптация к редким событиям (rare events), таким как «чёрная пятница», когда закономерности и тенденции в данных могут значительно отклоняться от нормы.
- Преодоление проблемы холодного запуска. Она возникает, когда модели необходимо делать прогнозы для новых пользователей, у которых отсутствуют исторические данные
Стремление к полной автоматизации
Microsoft и Google являются крупными игроками на рынке облачных вычислений: доля Azure на рынке составляет 22%, а Google — 10%. Они предлагают широкий спектр услуг, включая вычисление, хранение данных и средства разработки, которые являются необходимыми компонентами для создания продвинутой инфраструктуры моделей машинного обучения. Как и в любом бизнесе, их главной целью является получение дохода с помощью продажи этих услуг. Отчасти именно поэтому в их блогах особое внимание уделяется продвижению и автоматизации. Однако более высокий уровень зрелости не гарантирует лучших результатов для вашего бизнеса. Оптимальное решение — это то, которое соответствует потребностям вашей компании в данный момент и текущему технологическому стеку.
Несмотря на то что уровни зрелости действительно могут помочь определить вашу текущую продвинутость в разработке инфраструктуры машинного обучения, им не следует доверять вслепую, поскольку основными стимулами Microsoft и Google являются продажа своих услуг. Примером может служить, в частности, их стремление к автоматизированному повторному обучению модели: этот процесс требует большого количества вычислений, но часто он не нужен или даже вреден. Повторное обучение следует проводить только при необходимости — для вашей инфраструктуры гораздо важнее надёжная система мониторинга и эффективный анализ первопричин багов.
Мониторинг должен начинаться с ручного уровня
Во фреймворках сервис мониторинга появляется на втором уровне зрелости MLOps, однако лучше начать мониторить корректность работы своей модели, как только на основе её результатов начнут приниматься бизнес-решения, независимо от уровня её зрелости. Это позволит вам снизить риск сбоя и увидеть, как модель работает в соответствии с вашими бизнес-целями.
Первым шагом в запуске мониторинга может быть простое сравнение прогнозов модели с фактическими значениями. Это является базовой оценкой эффективности модели и хорошей отправной точкой для дальнейшего анализа. Кроме того, важно учитывать возврат инвестиций (ROI) — оценку ценности для бизнеса, которую приносят методы и алгоритмы обработки данных.
Оценка возврата инвестиций даёт инсайты, которые помогут принимать более взвешенные решения по распределению ресурсов и планированию будущих инвестиций. По мере развития инфраструктуры система мониторинга может усложняться с помощью дополнительных фич и возможностей, однако в любом случае следует обратить внимание на настройку базового мониторинга инфраструктуры уже на первом уровне зрелости.
Риски повторного обучения
В описании уровня №5 мы перечислили преимущества автоматического повторного обучения. Однако, прежде чем добавлять его в свою инфраструктуру, помните про риски, связанные с ним:
1. Повторное обучение на основе отложенных данных
В некоторых реальных сценариях, таких как прогнозирование дефолта, labels могут быть отложены на месяцы или даже годы. Вы рискуете перестраивать свою модель, используя старые данные, которые могут плохо отражать текущую реальность.
2. Неспособность определить первопричину проблемы
Если эффективность модели падает, это не всегда означает, что ей требуется больше данных. Сбой модели может быть вызван различными причинами, такими как изменения в последующих бизнес-процессах, ошибка в обучении или утечка данных. Сначала вам следует провести небольшое расследование, чтобы найти основную проблему, а затем при необходимости повторно обучить модель.
3. Более высокий риск неудачи
Помимо того, что повторное обучение усложняет инфраструктуру, чем чаще вы её обновляете, тем больше вероятность сбоя модели. Любая необнаруженная проблема, возникающая при сборе данных или предварительной обработке, «размножится» в модели, что приведёт к повторному обучению на основе ошибочных данных.
4. Более высокие затраты
Повторное обучение само по себе не является бесплатным, оно подразумевает расходы на такие цели, как:
- хранение и проверка данных для повторного обучения;
- вычислительные ресурсы для повторного обучения модели;
- тестирование новой модели, чтобы определить, работает ли она лучше, чем текущая.
Резюме
Системы ML сложны. Создавать и разворачивать повторяемые и устойчивые модели непросто. Мы рассмотрели пять уровней зрелости MLOps, основанных на лучших практиках Google и Microsoft, обсудили эволюцию от ручного развёртывания до автоматизированных инфраструктур, подчеркнув преимущества, которые приносит каждый уровень. Однако крайне важно понимать, что этим практикам не следует слепо доверять — их адаптация должна основываться на конкретных потребностях и требованиях вашей компании.
