Что такое GitOps и почему он (почти) бесполезен

Новый авиалайнер. Входит стюардесса в пассажирский салон: «Вы находитесь на нашем новом авиалайнере, в носовой части самолёта у нас находится кинозал, в хвостовой — зал игровых автоматов, на нижней палубе — бассейн, на верхней — сауна. А теперь, уважаемые господа, пристегните ремни, и со всей этой хреновиной мы попробуем взлететь».
Привет, меня зовут Олег! В ИТ-индустрии я работаю большую часть своей жизни. Мне очень интересно развитие инженерной мысли в области управления конфигурацией инфраструктуры, и последние шесть лет я занимаюсь тем, что называется DevOps.
Одна из свежих популярных тенденций — это концепция GitOps, которая была представлена в 2017 году на ставшем уже легендарным «Кубконе» Алексисом Ричардсоном — СЕО компании Weaveworks.
Weaveworks — это большая взрослая компания, которая в 2020 году привлекла больше 36 миллионов инвестиций под развитие своего GitOps.
Сейчас я попробую рассказать о тех неочевидных проблемах, которые могут вас ждать при принятии этой концепции. Если коротко, то GitOps не является «Серебряной пулей». Вполне вероятно, что спустя какое-то время вы закончите реорганизацию с ворохом велосипедов и костылей, которыми очень сложно управлять. Мы сами изрядно походили по этим граблям и хотим показать наиболее неприятные проблемы, которые не видны при чтении красивых статей.
Что такое GitOps и зачем он нужен
Stateless и Stateful
Самой перспективной и многообещающей концепцией построения инфраструктуры на сегодняшний день является immutable infrastructure.
Её ключевая идея — в разделении инфраструктуры на две принципиально разные части: Stateless и Statefull. Stateless-часть инфраструктуры иммутабельна и идемпотентна. То есть не накапливает в себе состояние (не сохраняет данных) и не меняет своей работы в зависимости от накопленного состояния. Инстансы этой части инфраструктуры могут содержать какие-то базовые артефакты, скрипты, ассеты. Как правило, мы создаём их из базовых образов в облачных/виртуализированных окружениях, они хрупки и эфемерны: новые версии приложений мы доставляем путём пересоздания инстансов с новых базовых образов.
Персистентные данные хранятся в Stateful-части. Она может быть реализована как по классической схеме с выделенными серверами, так и при помощи каких-то облачных механизмов (например, DBaaS, объектных или блочных хранилищ).
Для того чтобы заставить весь этот зоопарк быть управляемым и корректно работать, нам нужны коллаборация между engineering и ops team (сиречь DevOps), а также полностью автоматизированные пайплайны доставки.
CI-часть
Экстремальное программирование — одна из гибких методологий разработки. Отличается большим количеством петель обратной связи, что позволяет поддерживать синхронизацию с потребностями клиента.
Автоматизация пайплайнов доставки реализуется у нас при помощи CI/CD-систем. Сам термин CI — Continuous Integration — в 1994 году предложил Grady Booch, а в 1997-м Kent Beck и Ron Jeffries ввели его в дисциплину экстремального программирования. В рамках CI мы должны интегрировать наши изменения как можно чаще в основную рабочую ветку нашего проекта. Это требует, во-первых, более гранулярной декомпозиции задач: мелкие изменения более атомарны, их проще отследить, понять и интегрировать. Во-вторых, мы не можем просто взять и смержить свеженаписанный код. Перед слиянием веток нам нужно убедиться, что ничего из того, что работало раньше, не было сломано. Для этого приложение надо хотя бы собрать. А ещё неплохо было бы покрыть код тестами.

И именно вот эту задачу выполняют CI-системы, которые прошли долгий путь развития и где-то посередине этого пути превратились в CI/CD-системы.
CD-часть
Что такое CD? Тот же Martin Fowler различает сразу два CD:
- Continuous Delivery — это когда при помощи практик Continuous Integration и культуры DevOps вы держите основную ветку своего проекта постоянно готовым к деплою на продакшн.
- Continuous Deployment — это Continuous Delivery плюс всё, что попадает в основную ветку, выливается у вас в ваш кластер, в ваш продакшн. Соответственно Continuous Delivery включает в себя Continuous Integration.
Проблема инфраструктурных «снежинок»
К сожалению, immutable infrastructure имеет ряд проблем. Львиную часть она унаследовала от концепции «инфраструктура как код» — IaC.
Прежде всего это configuration drift. Этот термин родился в недрах puppet labs (авторов всем известной puppet scm) и констатирует тот факт, что не все изменения на целевых системах делаются при помощи систем управления конфигурацией (system configuration management — SCM). Некоторые делаются вручную, в обход.
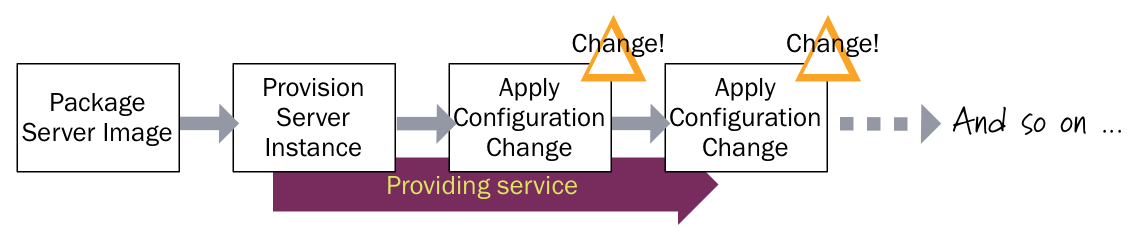
В процессе таких множественных изменений накапливается configuration drift — разница между описанной в SCM конфигурацией и реальным состоянием дел.
Это приводит к спирали страха автоматизации (Automation fear spiral).
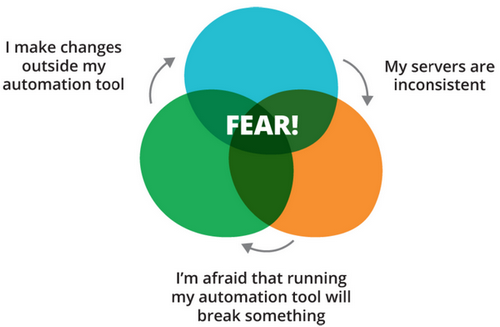
Спираль страха автоматизации
Чем больше сделано ручных изменений, тем больше вероятность, что запуск сценария SCM сломает неучтённые изменения, тем страшнее его запускать, тем больше вероятность новых ручных правок.

В конце концов эта порочная положительная обратная связь приводит к образованию так называемых серверов-«снежинок», которые стали настолько неконсистентными, что уже никто не понимает, что внутри. После ручных правок узел становится уникальным, как каждая отдельная снежинка в снегопад.
В рамках immutable infrastructure этот дрифт выходит из серверов на более высокие уровни: теперь мы можем говорить о GCP Project/AWS VPC/Kubernetes-кластер-«снежинках». Такое происходит из-за того, что на immutable infrastructure не регламентирована имплементация изменений. Более того, никто не знает, как это правильно делать.
GitOps — панацея от всех ваших проблем. Или нет
И вот тут появляется компания Weaveworks и говорит: «Ребята, у нас есть то, что вам нужно, — GitOps». Для пиара GitOps они привлекли такого тяжеловеса, как Kelsey Hightower, создавшего гайд «Kubernetes the hard way». В процессе пиара он усиленно транслирует мысль: «Будь мужиком, б…! Stop Scripting and Start Shipping». И выдаёт некоторое количество маркетингового bullshit bingo:
Key Benefits
- Increased Productivity
- Enhanced Developer Experience
- Improved Stability
- Higher Reliability
- Consistency and Standardization
- Stronger Security Guarantees
Why I should use GitOps
- Deploy Faster More Often
- Easy and Fast Error Recovery
- Easier Credential Management
- Self-documenting Deployments
- Shared Knowledge in Teams
На мой взгляд, наиболее интересные части — это:
- Улучшение консистентности и стандартизации деплоев.
- Улучшенная гарантия безопасности.
- Простое и быстрое восстановление после ошибок.
- Более простое управление доступами и секретами.
- Самодокументирующиеся деплои.
- Распределение знаний в команде.
И каждый, кто пытается разобраться, что такое GitOps, первым делом натыкается на этот хрестоматийный слайд:

GIT — единственный источник правды.
GIT — единственное место, где мы работаем с окружениями.
Все изменения верифицируемы и обозреваемы.
Далее находим принципы GitOps, которые напоминают чуть дополненные принципы IaC:
- Инфраструктура описана декларативно.
- Каноничное желаемое состояние версионировано в Git.
- Одобренные изменения автоматически разворачиваются в инфраструктуре.
- Программное обеспечение следит за корректностью развёртывания и оповещает, если есть расхождение с желаемым состоянием.
Тем не менее всё это — сферическое описание в вакууме, поэтому мы продолжаем наши исследования, находим сайт GitOps.tech и на нём — ряд важных уточнений.
Прежде всего мы узнаём, что GitOps — это инфраструктура, как код в git плюс CD-тулинг, который автоматически применяет это на инфраструктуру.

При этом в рамках GitOps мы должны иметь как минимум два репозитория:
- Репозиторий приложения — описывает исходный код приложения и манифесты, которые описывают деплой этого приложения.
- Инфраструктурный репозиторий — описывает манифесты инфраструктуры и deployment-окружение.
Также в GitOps-идеологии pull-ориентированный подход предпочтительнее, чем push-ориентированный (что идёт несколько вразрез с эволюцией SCM-систем, прошедших путь от тяжеловесных pull-монстров Puppet и Chef к легковесным push-основанным Ansible и Terraform).

Варианты инструментария с официального сайта gitops.tech
И если GitOps — это в первую очередь история про инструментарий, то вполне разумно взять и разобрать концепцию на базе Flux от самой компании Weaveworks. Уж, наверное, авторы идеи должны были сделать эталонную реализацию.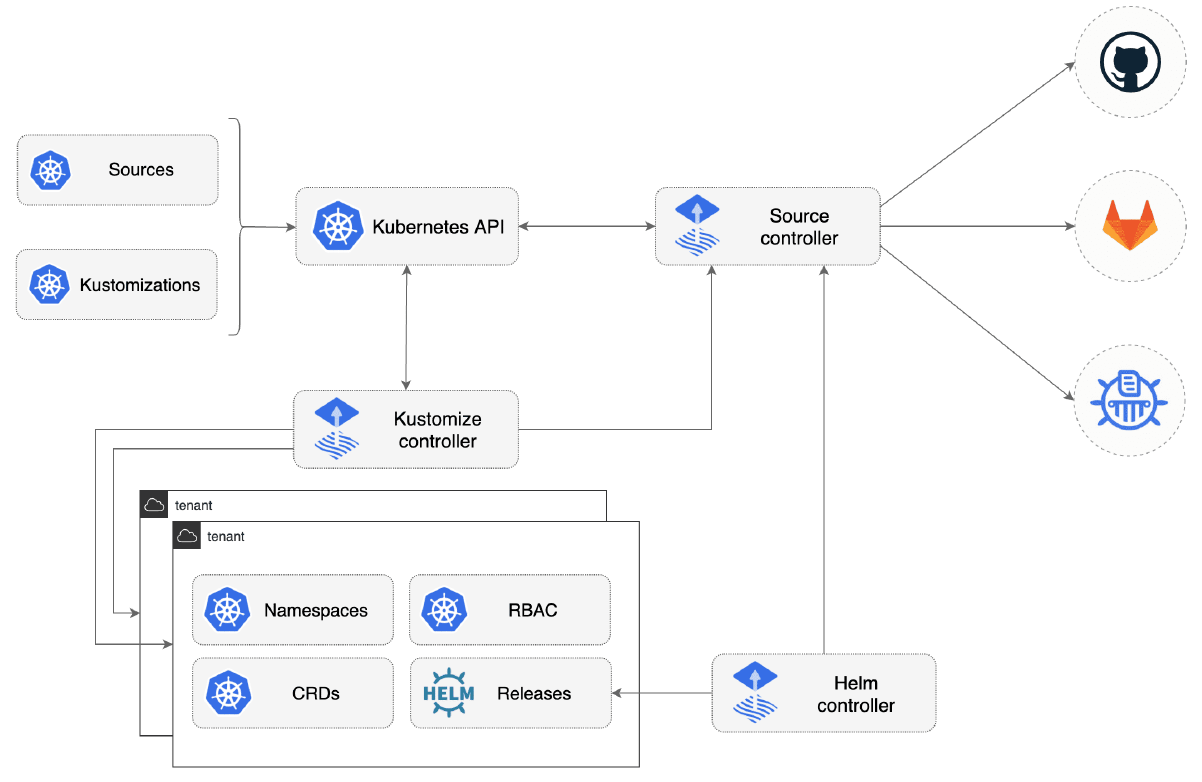
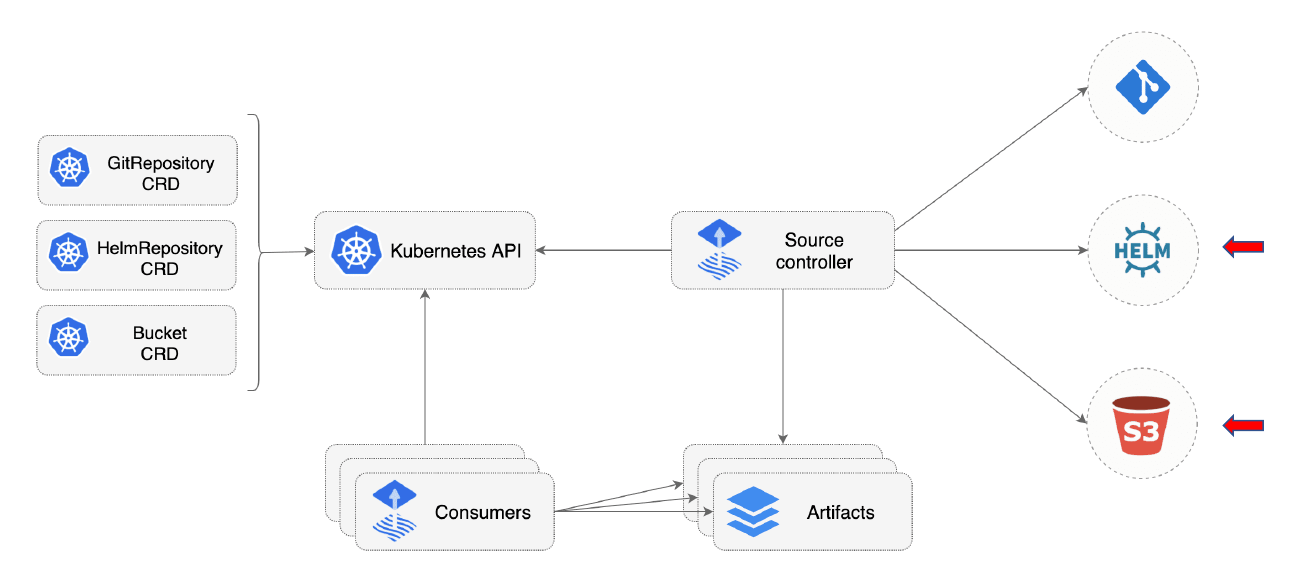
Flux сейчас дорос уже до второй версии и архитектурно состоит из контроллеров, которые работают внутри кластера:
- Source controller.
- Kustomize controller.
- HELM controller.
- Notification controller.
- Image automation controllers.
Логика работы Flux с Helm
Дальнейшее повествование я буду вести на примере деплоя приложения при помощи Helm package manager в Flux 2.
Почему так? Согласно CNCF Survey 2021 HELM package manager был самым популярным Packaging application с долей более 50%.
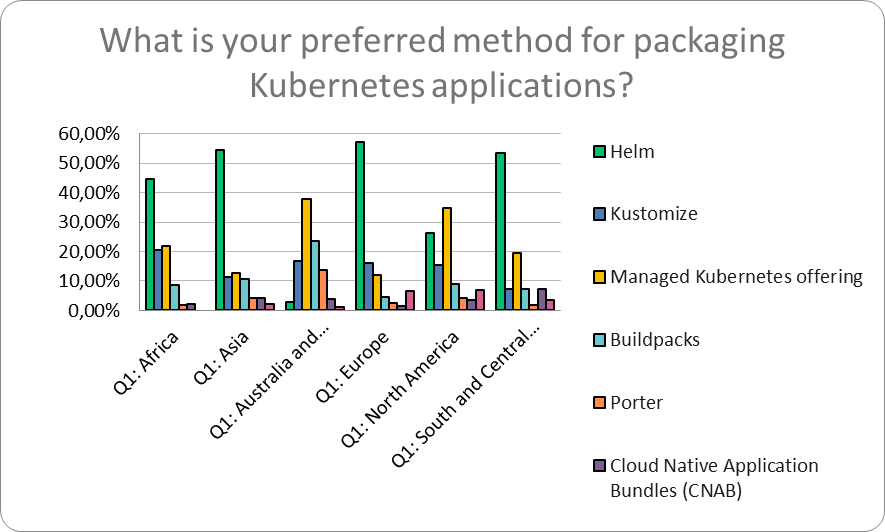
К сожалению, более актуальных данных я не нашёл, но не думаю, что с тех пор что-то сильно изменилось.
Итак, давайте пройдёмся с по основной логике работы Flux 2 с Helm. У нас есть два репозитория: приложения и инфраструктуры.

Из репозитория приложения мы делаем HELM-чарт, docker image и пушим их в репозиторий чартов и docker registry соответственно.

Далее у нас есть Kubernetes-кластер, в котором работают контроллеры flux: 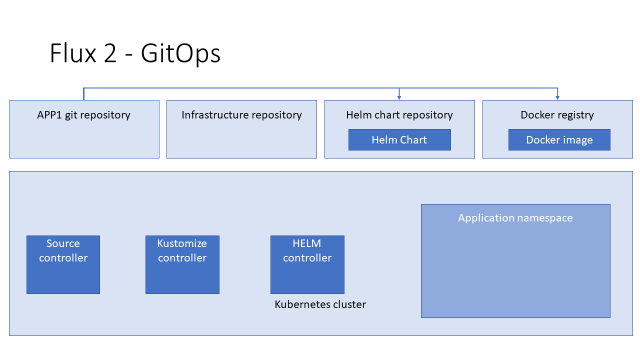
Чтобы выкатить наше приложение, мы подготавливаем YAML с описанием custom resource (CR) HelmRelease и пушим его в инфраструктурный репозиторий.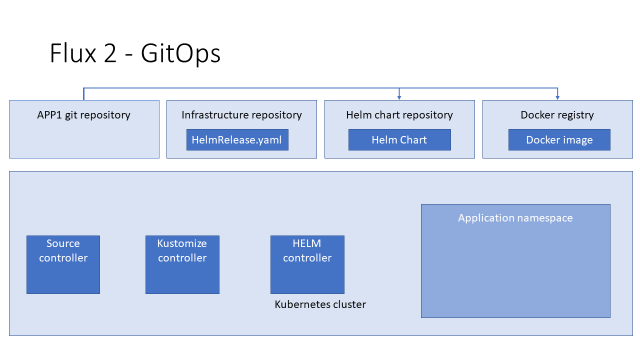
Чтобы flux мог его получить, мы создаём CR GitRepository в кластере Kubernetes. Source-контроллер видит его, идёт в git и скачивает.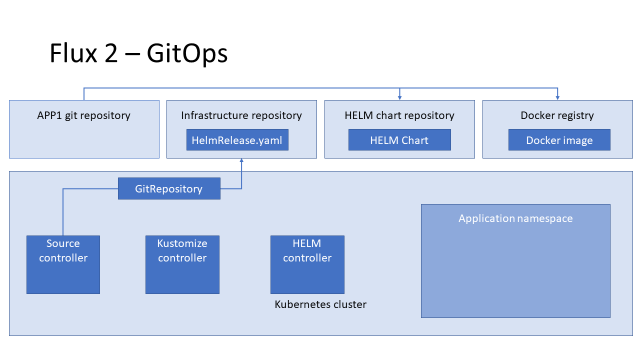
Для того чтобы задеплоить этот YAML в кластер, мы описываем ресурс Kustomization. 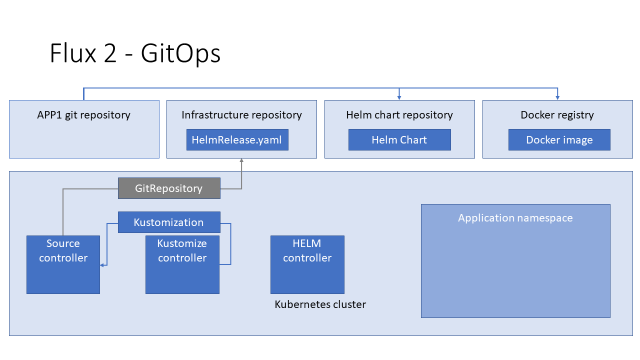
Kustomize-контролер видит его, идёт к Source-контроллеру, получает YAML и деплоит в кластер.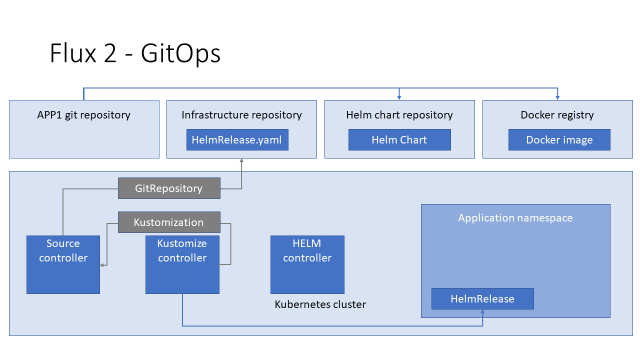
Helm-контроллер видит, что в кластере появился CR HelmRelease, и идёт к Source-контроллеру, чтобы получить HELM-чарт, который в нём описан.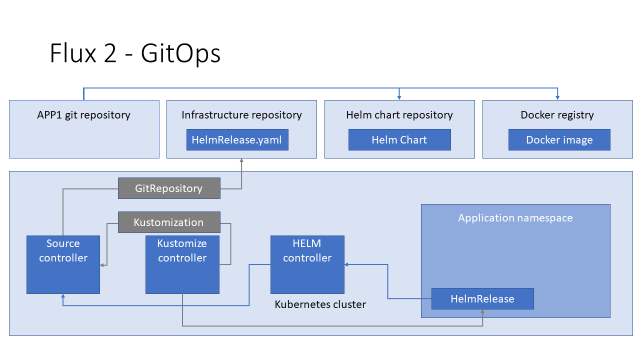
Для того чтобы Source-контроллер мог дать HELM-контроллеру запрашиваемый чарт, мы должны создать в кластере CR HelmRepository.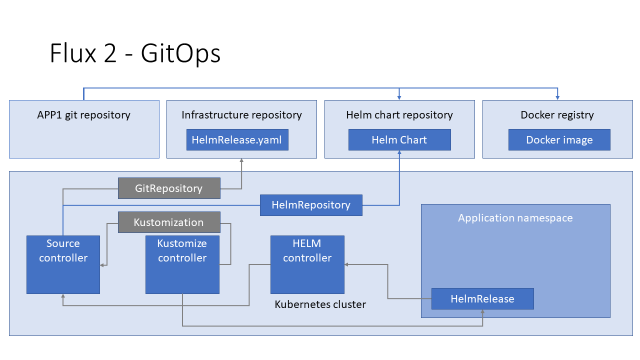
Helm-контроллер получает чарт от Source-контроллера, создаёт релиз и деплоит его в кластер, а дальше Kubernetes создаёт нужные pod`ы, идёт в docker registry и скачивает соответствующие имиджи.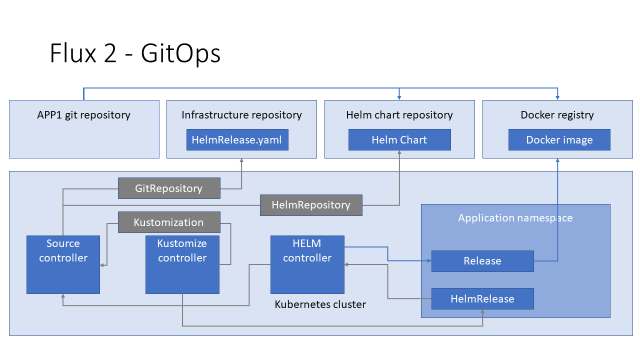
Соответственно, чтобы выкатить новую версию нашего приложения, мы должны сделать новый имидж, новый файл с HelmRelease и, возможно, новый HELM chart, разложить их по соответствующим хранилищам и дождаться, когда контроллеры Flux повторят работу по описанной выше цепочке.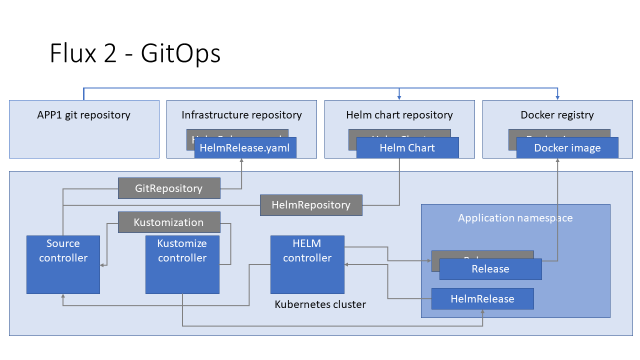
И, чтобы картина была законченной, мы ставим где-то Notification-контроллер, который извещает нас о том, что вообще могло пойти не так в нашей схеме.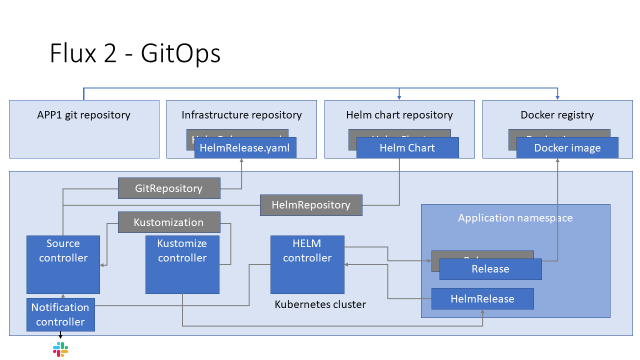
Кастом-ресурсы Flux
А сейчас пройдёмся по custom resources, которыми оперирует Flux.
Первое — это Git-репозиторий. Здесь мы можем указать адрес Git-репозитория (строка 14) и ветку, куда он смотрит (строка 10).
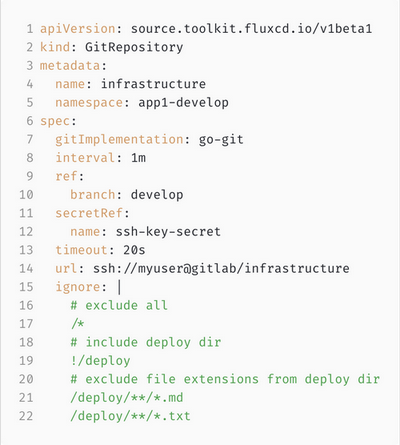
Таким образом, мы выкачиваем только отдельную ветку, а не весь репозиторий целиком. Но! Так как мы ответственные инженеры и стараемся придерживаться концепции Zero Trust, то закрываем доступ к репозиторию, создаём в Kubernetes-кластере секрет с ключом и даём его Flux«у, чтобы он мог туда ходить (строка 12).

Далее — Kustomization. Тут я сразу хочу обратить ваше внимание, что Kustomize-контроллер от Flux и Kustomize от авторов Kubernetes-деплой-системы — это две разные вещи. Я не знаю, почему был выбран такой странный дезориентирующий нейминг, но их важно не путать.

Kustomization — это способ задеплоить YAML (любой) из Git-репозитория в кластер. Здесь мы должны указать source, откуда мы это ставим (строка 12 — название описанного выше CR GitRepository), каталог, из которого мы берём YAML (строка 8), и можем указать target namespace, куда их деплоить (строка 13).
Следующее — Helm-релиз.

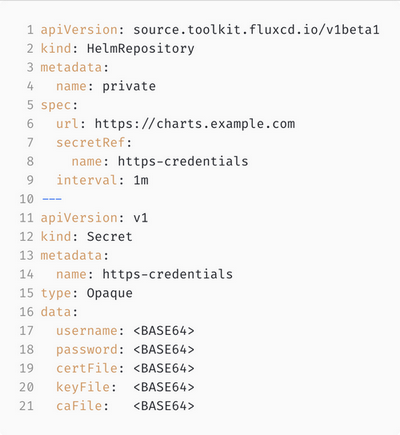
Здесь мы можем указать имя, версию chartа (строки 10,11). Тут вы указываете значения переменных для того, чтобы Helm мог кастомизировать релиз от окружения к окружению (строки 15–19). Это крайне важная и нужная функция, так как окружения у вас могут значительно отличаться. Также вы указываете source, из которого нужно брать на Helm chart (строки 12, 13, 14). В данном случае это Helm-репозиторий.
Но! Так как мы всё ещё ответственные инженеры, то также закрываем доступ в Helm-репозиторий и даём Flux«у секрет для того, чтобы он мог туда попасть (строки 7, 8).
Чек-лист для GitOps
Итак, сделаем небольшой чек-лист для того, чтобы зафиксировать то, что мы сейчас проговорили. Для того чтобы начать делать GitOps, мы должны внезапно написать кучу скриптов (мы ведь помним, что Immutable infrastructure — это полностью автоматизированные пайплайны доставки). Поэтому прежде всего мы должны создать:
- Скрипт для сборки и пуша имиджей в Docker registry.
- Инфраструктурный Git-репозиторий.
- Аккаунт для доступа CI-системы в инфраструктурный GIT-репозиторий.
- Скрипт для генерации и пуша HelmRelease-файла.
- Репозиторий Helm.
- Аккаунт для доступа CI-системы в репозиторий Helm.
- Скрипт для сборки и публикации Helm chart`а.
- Акаунт Flux для инфраструктурного репозитория.
- Акаунт Flux для репозитория Helm-чартов.
Нарушение концепции единого источника правды
Единого источника не получается
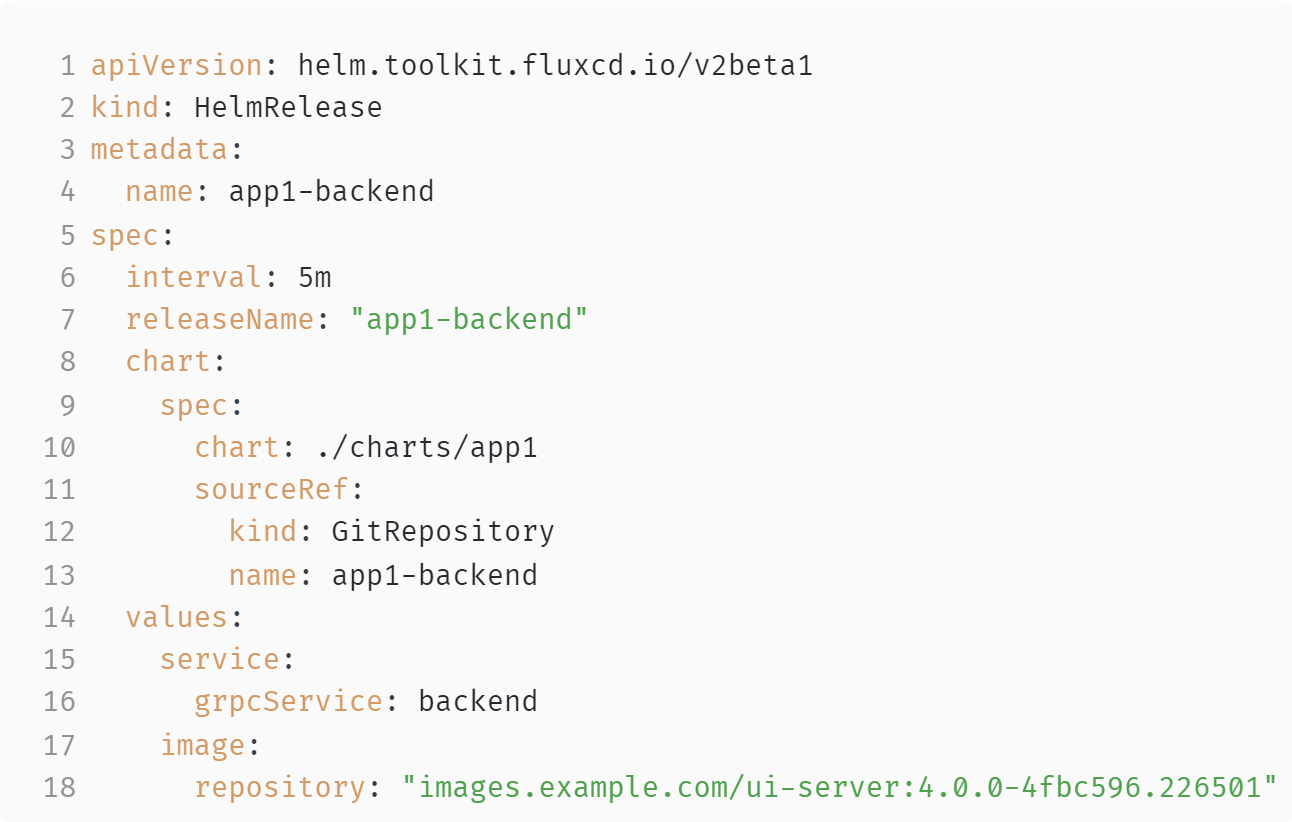
Посмотрим, что вообще у нас получается с нашим Helm-релизом. Вполне очевидно, что Git в данном конкретном случае не может быть единственным источником правды. У нас есть по крайней мере два ресурса — два артефакта вне git, от которых этот Helm-релиз зависит:
- Helm chart (строки 8–14).
- Docker image (строка 19).
Причём мы можем ещё больше усложнить ситуацию и указать диапазон версий Helm chart`а.

При этом Flux будет следить и устанавливать новые Helm chart`ы, которые появляются в рамках этого диапазона. Кроме того, Source-контроллер у нас может использовать в качестве источника YAML, в том числе S3-бакеты.
Оттуда мы можем оставить и YAML, и Helm chart`ы.
Кроме того, у нас есть Image automation-контроллеры, которые могут следить за появлением новых образов в Docker registry и править инфраструктурный репозиторий.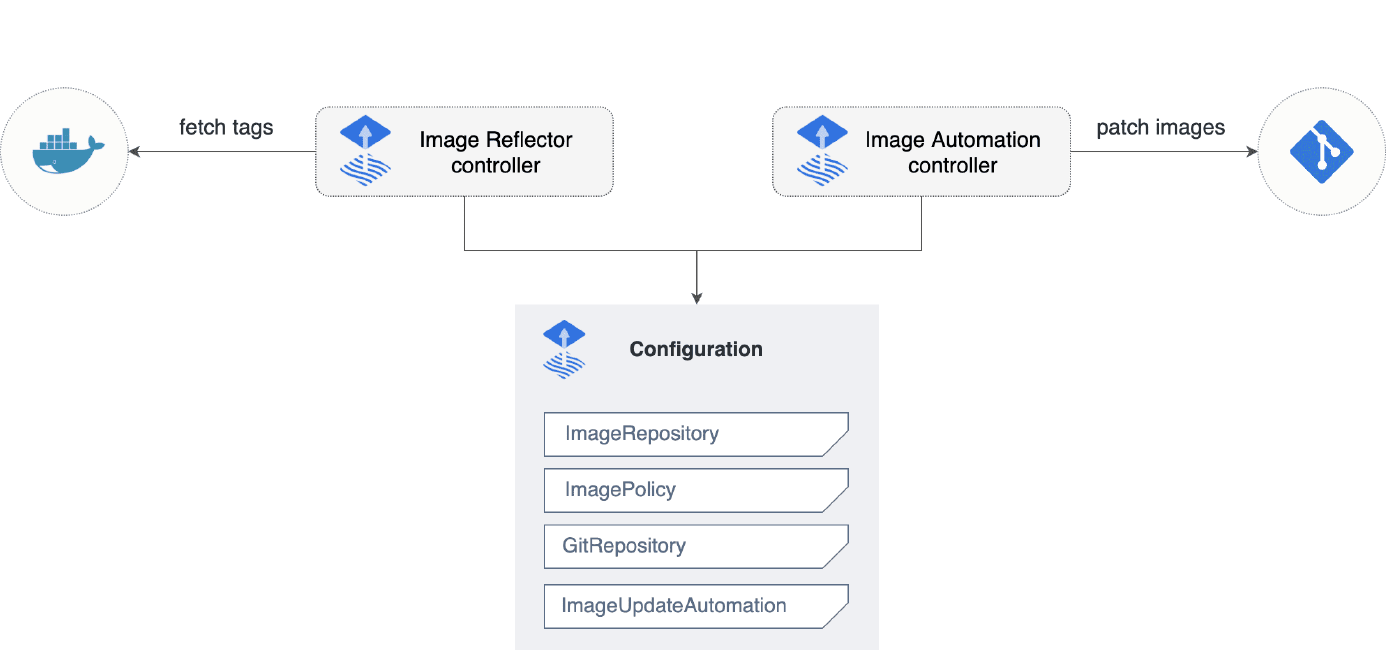
Но мы не хотим HELM Chart repo-Ops или Docker registry-Ops, мы хотим быть как можно более GitOps. Поэтому смотрим документацию и правим процессы так, чтобы деплоить наш Helm chart из GIT-репозитория (для его хранения мы выбираем репозиторий приложения).
Это заставляет нас сделать ещё один CR GitRepository для репозитория приложения, аккаунт для доступа к нему Flux и создать секрет с ключами.

При этом мы никак не решаем проблему очень непростой зависимости от Docker image.
Полагаю, что на сегодня будет достаточно. В следующем посте расскажу, какие у этого добра проблемы.
