Что под капотом у Leak Canary?

Утечка памяти пожалуй одна из самых незаметных ошибок, которую можно допустить в разработке. Такая ошибка никак не влияет на работу приложения, ее сложно отловить на этапе тестирования, однако может привести к лагам на устройстве и порой даже крэшу. Насколько бы вы внимательно не относились к коду из-за человеческого утечка рано или поздно всплывет. Причем утечка памяти довольно часто бывает и в сторонних библиотеках.
Разработчикам хотелось иметь инструмент, который позволял бы отслеживать утечки памяти автоматически, без ручного анализа Dump Heap или постоянного мониторинга потребления памяти с IDE на перевес. И ребята из небезызвестной Square сделали такой инструмент, лет эдак 7–8 назад.
LeakCanary — библиотека, позволяющая находить утечки памяти во работы приложения в фоновом режиме. При всем при этом, со стороны клиента ничего делать не нужно. Просто указал либу в зависимостях gradle, и она сама все сделает.
Естественно инженерное любопытство заставляет задаться вопросом, а как работает эта магия? Эта статья даст хоть и поверхностные, но ответы на эти вопросы. В статье постараюсь описать:
Как запускается LeakCanary?
Откуда берется ярлык?
Как вообще LeakCanary находит утечки и находит путь до утекшей ссылки?
Как запускается LeakCanary?
В каждом Android приложении есть файл AndroidManifest.xml. Этот файл нужен для того, чтобы показать системе какие компоненты у нас есть, какие события мы хотим отлавливать, какие разрешения нам нужны и еще дофига всего. Манифест показывает, что наше приложение умеет и какие данные может предоставить.
Приложение может состоять из многих Android модулей. И в каждом таком модуле будет определен свой AndroidManifest.xml, в котором будут описываться используемые компоненты: Activity, Service и т.д.

Установка приложения
Когда вы собираете приложение, компилятор мержит все эти манифесты в один большой. Потому как в конечном архиве (apk) система ожидает увидеть только один файл AndroidManifest.xml. И вот для чего это нужно.

Объединение манифестов в один
Посреди основных компонентов приложения есть один, используемый не часто, но позволяющий делать интересные штуки — Content Provider. В основном, компонент предназначается для обмена данными между приложениями. Передача данных нас сейчас не интересует, а интересует две его особенности:
Во-первых, метод onCreate у Content Provider вызывается перед onCreate у Application. Из-за этого Content Provider часто используют для какой-нибудь аналитики, которую нужно настроить еще до запуска самого приложения.
Во-вторых это единственный компонент приложения, который создается в момент старта приложение, без нашего участия. Другими словами, если мы указали Content Provider в манифесте, система его точно запустит.

Порядок запуска компонентов
Все это дает возможность отследить момент запуска приложения и даже получить контекст. При этом не нужно ничего нигде прописывать, система сама создаст Content Provider и дернет метод onCreate. Из этого получаем два вывода.

Вывод номер 1️⃣. Нужно проверять код незнакомых библиотек. В одной из них может оказаться вот такой Content Provider который безнаказанно стырит данные пользователя и отправит их на левый сервер.
Вывод номер 2️⃣. Можно прикрутить функциональность ничего не прописывая в коде. Именно этот механизм и использует LeakCanary. Библиотека просто подсовывает свой Content Provider, тем самым отлавливает момент запуска приложения.
Далее, получив доступ к Context, LeakCanary получает доступ практически ко всему приложению. Она навешивает кучу листнеров которые позволяют отслеживать все Activity, Fragment, Service и т.д. По этой же схеме работают некоторые библиотеки гугла, вроде Firebase.
Откуда берется отдельный ярлык?
С этим пунктом в LeakCanary все еще проще. Как вообще мы указываем системе какую Activity нужно запустить первой? Опять-таки через AndroidManifest.xml и специальные intent-filter которые указываем у Activity.
В intent-filter мы прописываем Action показывающий на какие действия система должна предлагать эту Activity и Category, показывающая системе дополнительную инфу о том, где располагать эту Activity.
Для главной Activity Action = android.intent.action.MAIN, Category = android.intent.category.LAUNCHER. Система читает Manifest и исходя из этих Action и Category понимает, что данную Activity нужно отобразить в лаунчере.
Интересный момент заключается в том, что таких Activity может быть много. У вас есть возможность сделать хоть 3 разных точек входа в приложения причем с разными иконками и разными названиями.
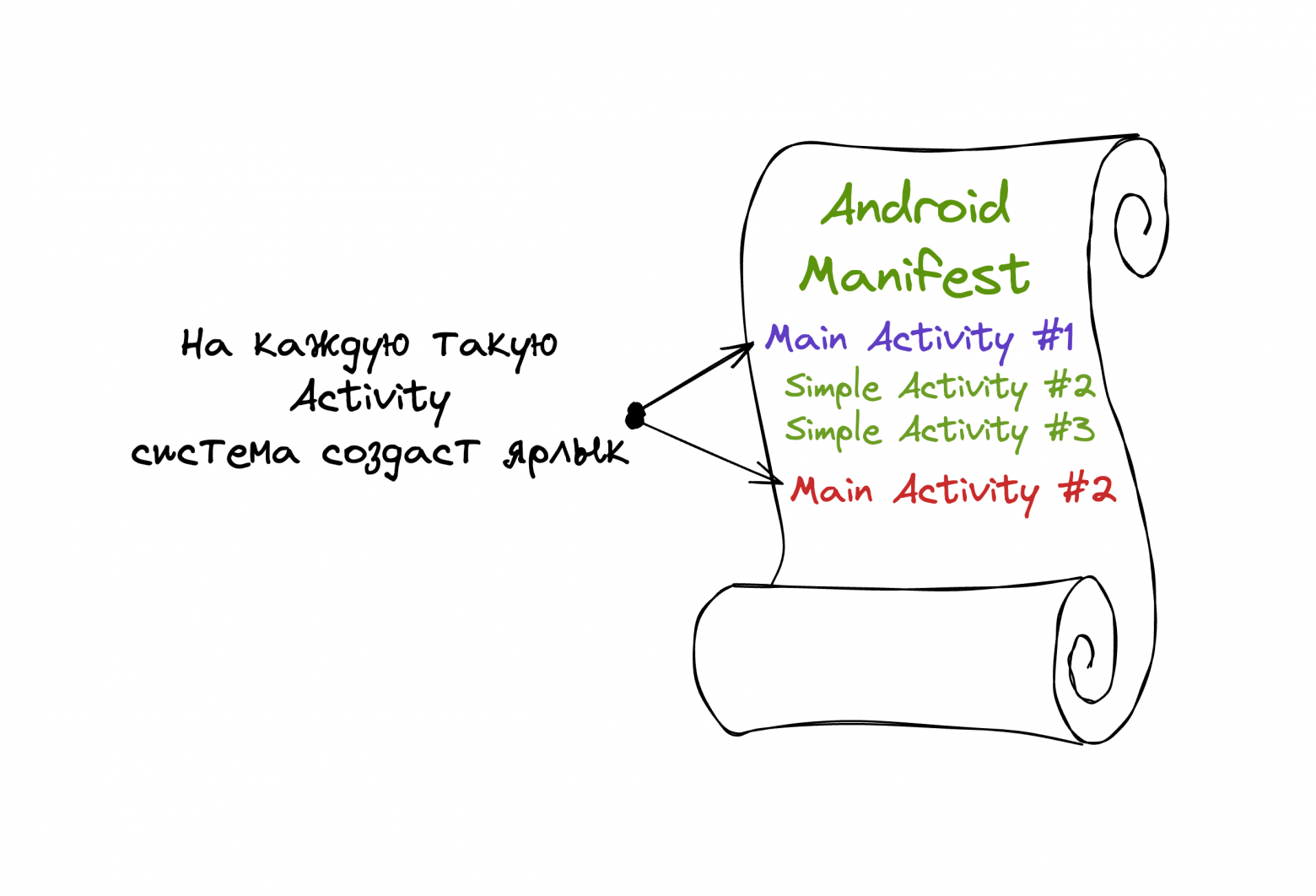
LeakCanary в своем манифесте подсовывает такую Activity со свой иконкой. При нажатии на эту икону открывается не главная Activity вашего приложения, а Activity библиотеки, с информацией об утечках.
Однако остается не очень удобное поведение, когда мы сначала запустили Activity LeakCanary, а затем запустили Activity уже нашего приложения. Неудобство тут в том, что не понятно что делать с навигацией, т.к это вроде две отдельные части приложения, которые не должны быть вместе.
Чтобы убрать это неудобство, используется taskAffinity. Activity у нас запускаются в стеке, который чем-то напоминает стек фрагментов (хотя скорее наоборот, стек фрагментов делали как копию стека Activity). Этих стеков у приложения может быть несколько. По умолчанию все Activity запускаются в одном стандартном, однако, используя атрибут taskAffinity, можно указать другой.
Прописываем какую-то уникальную строку в taskAffinity, желательно чтобы в этой строке был ваш applicationId, дабы не было путаницы с другими приложениями. После этого Activity будут запускаться не в стандартном стеке, а в указанном вами. В лаунчере со списком запущенных приложений эти стеки будут разными, будто два отдельных приложения.
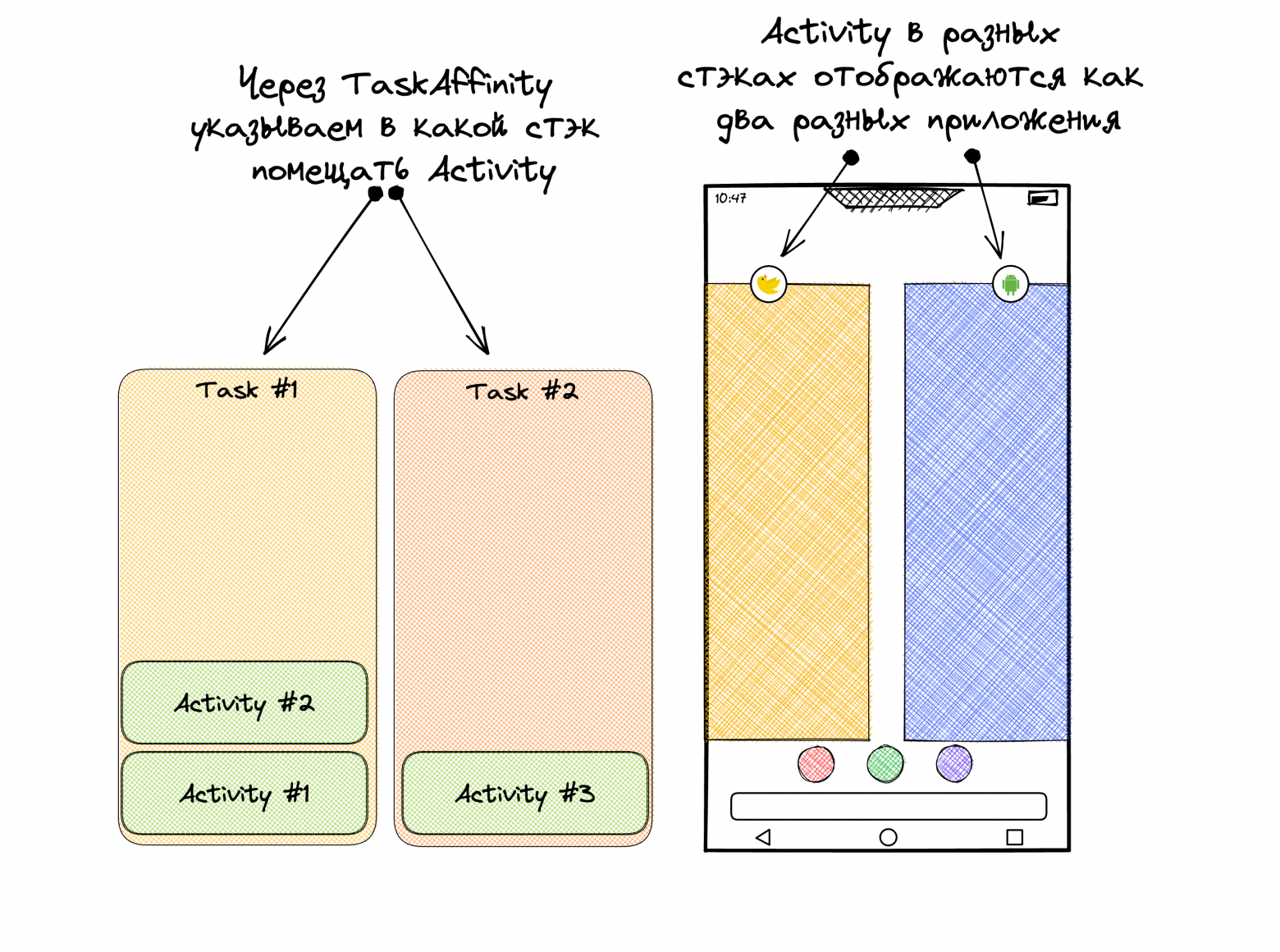
LeakCanary так и работает, тупо делает отдельный стек для своих Activity. Это позволяет сделать полную видимость того, что у вас в одном приложении два. Первое основное и второе которое связано исключительно с информацией про утечки.
Как LeakCanary вообще находит утечки?
В основе механизма лежит простая идея. Чтобы понять эту идею, достаточно знать типы ссылок. Те самые типы, которые в большинстве случаев упоминаются или на собесе или когда нужно быстро пофиксить утечку памяти о которой мы знаем.

Есть 4 типа ссылок в Java, нас сейчас интересует только 2: сильные (Strong Reference) и слабые (Weak Reference). С сильными ссылками все просто, пока эта ссылка существует где-то, GC точно не удалит этот объект, который к этой ссылке привязан.
Слабые ссылки в таком кейсе не гарантируют сохранение объекта. Другими словами вы создали объект, положили его в слабую ссылку, теперь у вас только слабая ссылка. Когда вам понадобится это объект, в ссылке может оказаться просто null. Если GC решит, что памяти мало он просто удалит объекты привязанные к слабым ссылкам.

Однако, если у нас есть одновременно и слабая и сильная ссылки на объект, то GC не будет удалять этот объект при нехватке памяти, и соответственно не разорвет связь между слабой ссылкой и объектом.
Возвращаясь к работе LeakCanary, библиотека получает context приложения и вешает специальный листенер, который позволяет отслеживать момент, когда любая Activity умирает. Перехватив момент когда Activity умирает, LeakCanary оборачивает эту Activity в слабую ссылку и сохраняет у себя. Затем сразу запускает GC, точнее сказать рекомендует JVM запустить GC:
// System.gc() does not garbage collect every time. Runtime.gc() is
// more likely to perform a gc.
Runtime.getRuntime().gc()
Thread.sleep(100)
System.runFinalization()После какого-то времени, библиотека смотрит обнулилась ли ссылка. Если обнулилась значит все ок, никакой утечки не было. Если ссылка по-прежнему не null, значит где-то еще есть сильная ссылка, что означает утечку.
Аналогичный принцип библиотека использует и для View, Fragment и Service. Для последнего правда используется невероятно сложный костыль с рефлексией, чтобы перехватить момент смерти.
После установления факта утечки, LeakCanary начинает поиск пути к ссылке из-за которой произошла утечка. Единственный способ это сделать, это получить dump памяти.
Любая JVM предоставляет функционал получения копии всех объектов памяти в удобном формате, чтобы можно было проводить анализ. Чтобы получить копию памяти в Android достаточно вызвать функцию Debug.dumpHprofData(file). В эту функцию передаем путь к файлу, а дальше система все сделает за нас.
Итак мы получили файл, в котором лежит информация о всех объектах JVM в определенный момент времени. Дальше нужно как-то начать поиск утечки. У нас куча объектов и не особо понятно с чего вообще нужно начинать поиск. LeakCanary решает эту проблему самым простым способом.
В библиотеке используются не обычные WeakReferece, а подкласс KeyedWeakReference. В нем есть дополнительная инфа о том, ссылается ли эта ссылка на утекший объект, или нет. Это нужно, чтобы различать какие ссылки ссылаются на утечку, а какие просто висели в этот момент в памяти.
А дальше вспомним что такое GC root. GC root это корни (да, объяснение через перевод, я тот еще писатель) от которых тянутся все ссылки в heap. В частности это потоки (а точнее стеки), вся статика, сlassloaders, JNI ссылки, тут я думаю суть понятна.

Анализатор утечек в полученной копии памяти ищет объекты класса KeyedWeakReference. Затем просто по ссылке смотрит на какой объект они ссылаются. Таким образом мы находим утекший объект, это может быть Activity, View и т.д все что можно утечь.
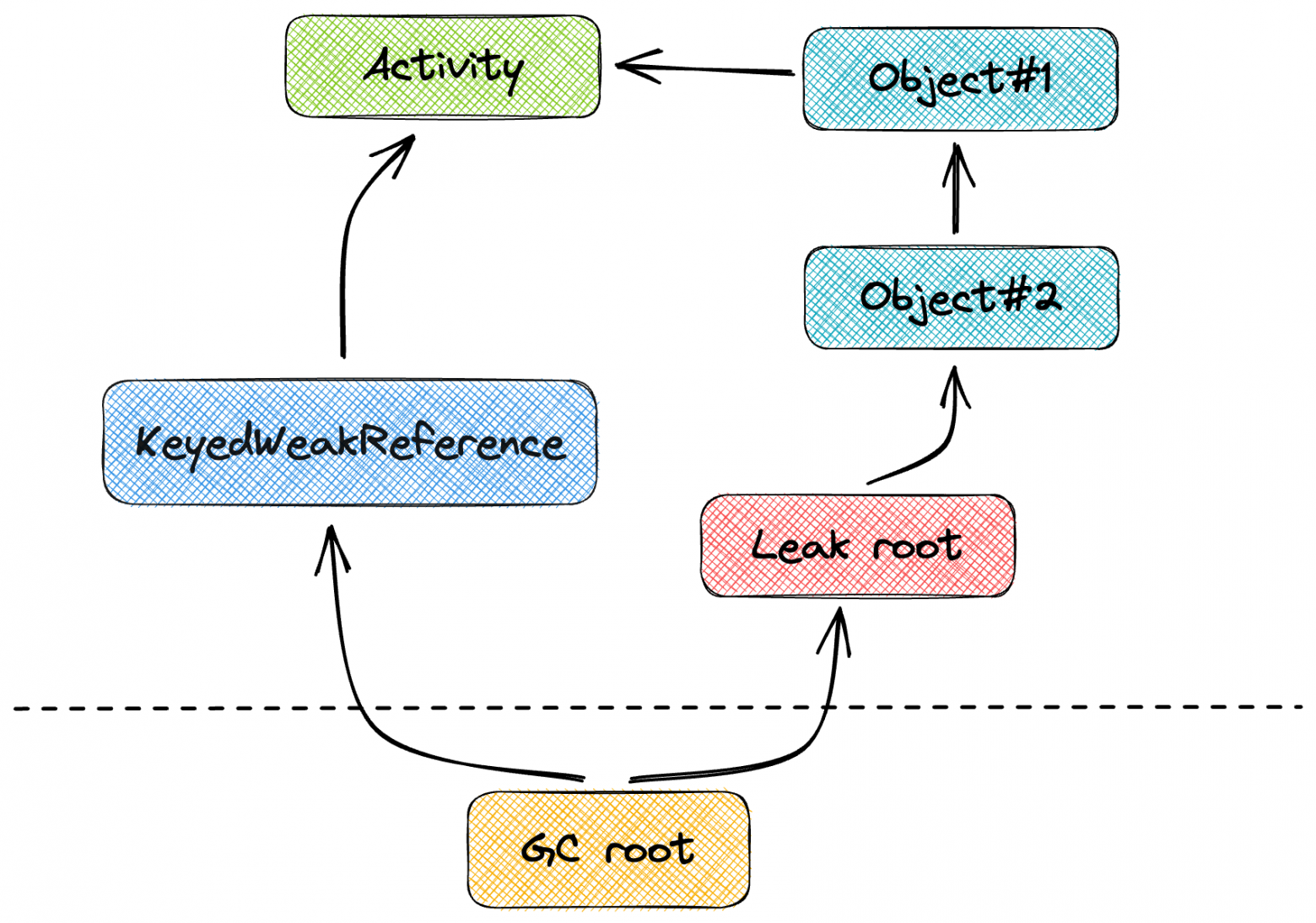
После того как мы нашли утекший объект, нужно построить путь до GC root, чтобы найти ссылку из-за которой он собстна утек. Для этого используется алгоритмы графов для поиска кратчайшего пути. Вы же не думали, что алгоритмы не нужны при разработке мобильных приложений?

Ну, а после нахождения ссылки, все что остается это сохранить этот путь и отобразить его в интерфейсе. Сама концепция не rocket science, однако реализация алгоритма поиска пути до GC root это тема для целого доклада, поэтому тут я его описывать не буду.
Заключение
Что можно вынести из подкапотной работы LeakCanary? Да на самом деле ничего такого, чтобы вы могли взять и применить в своей работе, разве что Content Provider затащить в свои библиотеки для упрощения инициализации на стороне клиента. Однако устройство Leak Canary показывает, что те вещи, про которые, казалось бы спрашивают только на собесах, можно применять и на практике.
Помимо этого работа инструментов, которая может показаться магией всегда базируется на довольно простых концепциях, и уделив на это пару вечеров можно разобраться. Анализ работы инструмента, который мы используем каждый день, дает гораздо больше пользы, чем просто чтение документации, знания из которой быстро вылетят из головы.
Если вам понравилась, подписывайтесь на мой телеграм-канал. Я пишу про Android-разработку и Computer Science, на канале есть больше интересных постов про разработку под Android.
