ArrayPool: подводные камни

Автоматическая сборка мусора упрощает разработку программ, избавляя от необходимости отслеживать жизненный цикл объектов и удалять их вручную. Однако, чтобы сборщик мусора был полезным инструментом, а не главным врагом на пути к высокой производительности — иногда имеет смысл помогать ему, оптимизируя частые аллокации и аллокации больших объектов.
Для уменьшения аллокаций в современном .NET предусмотрены Span/Memory, stackalloc с поддержкой Span, структуры и другие средства. Но если без объекта в куче не обойтись, например, если объект слишком большой для стека, или используется в асинхронном коде — этот объект можно переиспользовать. И для самых крупных объектов — массивов, в .NET встроены несколько реализаций ArrayPool.
В этой статье я расскажу о внутреннем устройстве реализаций ArrayPool в .NET, о подводных камнях, которые могут сделать пулинг неэффективным, о concurrent-структурах данных, а также о пулинге объектов, отличных от массивов.
Пул можно рассматривать как аллокатор объектов. У них одинаковый интерфейс с двумя методами, выполняющими функции new и delete. Хорошая реализация нативного аллокатора также переиспользует память: при delete участок памяти не сразу отдаётся операционной системе обратно, а переиспользуется для новых объектов внутри программы, т.е. работает как пул.
Возникает вопрос, зачем делать пул managed-объектов, вместо перехода на нативный аллокатор?
- Это требует меньших изменений в коде, который эти объекты использует. Также, некоторые API принимают
ArraySegment, а неMemory - Это помогает сохранить код кроссплатформенным. Использование стороннего аллокатора обычно предполагает подключение нативной библиотеки.
- Managed-объекты могут иметь ссылки на другие managed-объекты. Ссылаться на managed-объекты из памяти, которой не управляет сборщик мусора нельзя — при дефрагментации кучи и перемещении объектов такие ссылки не будут обновлены и станут невалидными.
Отличие пула от аллокатора в том, что пулу можно не сохранять часть объектов, например, при превышении вместимости — тогда их соберёт сборщик мусора. Аллокатор же должен гарантировать отсутствие утечек памяти.
В .NET встроены две разные реализации абстрактного класса ArrayPool. Т.к. невозможно сохранить массивы для каждого из размера по-отдельности (их будет слишком много), при вызове .Rent(N) пул возвращает массив размера N или больше. Внутри пул хранит массивы с длинами, равными степеням двойки.
Первая — для пулов, создающихся с помощью ArrayPool. Вторая — статический ArrayPool. Также можно сделать свою реализацию ArrayPool.
Разбор отличий пулов, добываемых через ArrayPool и ArrayPool начнём с бенчмарка. Кроме этих реализаций, протестируем также реализацию, которая ничего не переиспользует, а просто аллоцирует новые массивы и бросает их на совесть GC.
// Threads = 16
// Iterations = 64*1024
// ArraySize = 1024
[Benchmark]
public void ArrayPoolConcurrent()
{
var tasks = new Task[Threads];
for (int i = 0; i < Threads; i++)
{
tasks[i] = Task.Run(() =>
{
for (int j = 0; j < Iterations; j++)
{
var arr = pool.Rent(ArraySize);
// имитация использования массива сложностью O(ArraySize)
// не просто так же он нам нужен, чтобы сразу вернуть в пул?
Random.Shared.NextBytes(arr);
pool.Return(arr);
}
});
}
Task.WaitAll(tasks);
}| Pool | Mean | Allocated |
|----------:|------------:|--------------:|
| Create | 170.09 ms | 2.77 KB |
| Shared | 14.96 ms | 2.41 KB |
| new | 69.77 ms | 1072085.02 KB |Код, не связанный с работой с пулом занимает ~13 ms, что было замерено отдельно.
Пул, созданный через ArrayPool оказался медленнее даже аллокации (оператора new), и гораздо медленнее ArrayPool (за вычетом оверхеда). Но не торопитесь делать выводы по одному бенчмарку, тестирующему лишь частный случай, и списывать эту реализацию пула — далее мы разберёмся, как эти пулы устроены внутри, и почему результат получился таким.
Отмечу, что пул — лишь вспомогательный компонент, и бенчмаркать нужно алгоритм или сервис, в котором пул используется — сравнивать, улучшилась ли производительность от переиспользования объектов. Да и самая быстрая реализация пулинга — та, которая не содержит никакой синхронизации с другими потоками. В однопоточном коде проще сохранить массив в поле класса и всегда использовать его, без всяких пулов. А если нужно хранить несколько объектов в однопоточном алгоритме, то подойдут обычные Queue.
ArrayPool.Create ()

Методы .Create() и .Create(maxArrayLength, maxArraysPerBucket)создают ConfigurableArrayPool. Здесь нужно быть осторожным — значение максимальной длины массива в этом пуле по умолчанию — всего лишь 1024 * 1024, при её превышении массивы будут аллоцироваться и не сохраняться в пуле. Поэтому, если ArrayPool создаётся для больших массивов — параметры придётся переопределить.
Реализация ConfigurableArrayPool очень проста:
- массивы в пуле сгруппированы по размерам (размер — всегда степень двойки)
- массивы одного размера хранятся в списке (на основе массива)
- каждый список защищён от многопоточного доступа с помощью SpinLock
Как раз из-за блокировки эта реализация пула не масштабируется на множество потоков. В итоге основным её применением становятся большие массивы, в случае с которыми время работы с пулом пренебрежимо мало по сравнению с обработкой данных, которыми эти массивы заполняются.
ArrayPool.Shared
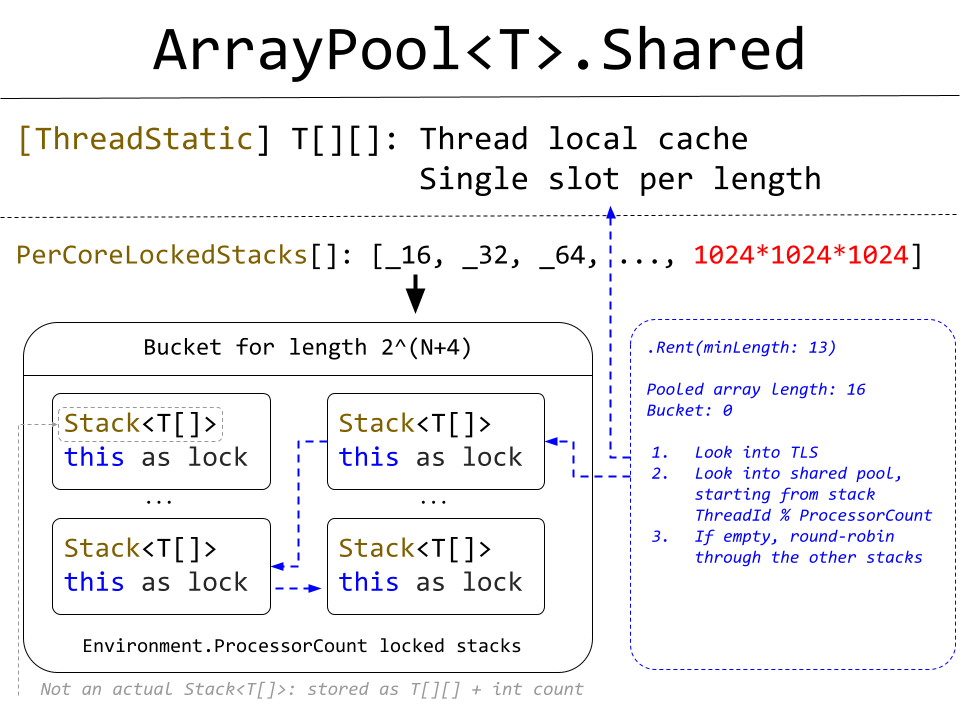
Это статический пул, разделяемый всем кодом в программе. Реализация называется TlsOverPerCoreLockedStacksArrayPool и на данный момент, никаких настроек не имеет. Максимальный размер массива в пуле — 2^30 элементов. Tls в названии значит ThreadLocalStorage, исходя из этого можно догадаться, за счёт чего этот пул работает быстро в многопоточной среде.
В этом пуле реализовано двухуровневое хранение объектов. Первый уровень — локальный набор массивов для каждого потока. Хранится в [ThreadStatic] поле. Доступ к локальной части пула не требует синхронизации с другими потоками. Однако, локально хранится максимум по одному массиву каждого размера. Использование статического поля здесь возможно, т.к. пул глобальный, т.е. создаётся в единственном экземпляре. В нестатическом пуле для этой оптимизации придётся использовать ThreadLocal.
Второй уровень — разделяемый между потоками. Но в отличие от ConfigurableArrayPool, для каждого размера хранится не один список массивов, а несколько — по количеству логических ядер (max. 64), каждый из списков защищён отдельной блокировкой. Это снижает конкуренцию между потоками — теперь они идут под разные блокировки, а не под одну. Вместо SpinLock в реализации Shared пула используется обычный lock/Monitor.
Speed — Memory tradeoff
Оптимизация с thread local слотом имеет свою цену: в пуле может скопиться большое количество крупных массивов, раздувая память приложения. В примере ниже первый поток создаёт новый массив и возвращает его в пул. Этот массив попадает в Thread Local слот первого потока. В итоге, при попытке получить массив того же размера из другого потока — переиспользования не произойдёт и будет выделен новый массив. В итоге для больших массивов может быть выгоднее использовать реализацию пула с общим набором объектов для всех потоков.
// thread 1
var pool = ArrayPool.Shared;
var arr1 = pool.Rent(1024*1024*1024);
pool.Return(arr1);
Task.Run(() =>
{
// thread 2
var arr2 = pool.Rent(1024 * 1024 * 1024);
Console.WriteLine(arr1 == arr2);
}).Wait(); Очистка памяти при GC
Отчасти для решения предыдущей проблемы, в ArrayPool предусмотрена очистка памяти при сборке мусора. С помощью хака с финализатором пул узнаёт о срабатываниях сборщика мусора и периодически выбрасывает избыток массивов, помогая освободить память.
Не всегда это поведение желательное. Преждевременное удаление больших массивов, находящихся в Large Object Heap, может привести к излишней фрагментации кучи. Это ещё один повод задуматься об использовании другого механизма для переиспользования больших массивов.
Штраф за невозврат массива в пул
Бенчмарк, с которого мы начали, в случае ArrayPool «пробивает» только первый уровень пулинга — thread local. Возникает вопрос, насколько производителен второй уровень — per core locked stacks, особенно учитывая то, что в нём есть блокировка. Для замера, сделаем бенчмарк, использующий сразу два массива из пула.
// Threads = 16
// Iterations = 1024
// ArraySize = 1024
[Benchmark]
public void ArrayPoolConcurrent_TwoArrays()
{
var tasks = new Task[Threads];
for (int i = 0; i < Threads; i++)
{
tasks[i] = Task.Run(() =>
{
for (int j = 0; j < Iterations; j++)
{
var arr1 = pool.Rent(ArraySize);
var arr2 = pool.Rent(ArraySize);
Random.Shared.NextBytes(arr1);
Random.Shared.NextBytes(arr2);
pool.Return(arr2);
pool.Return(arr1);
}
});
}
Task.WaitAll(tasks);
}| Pool | Mean | Allocated |
|----------:|------------:|---------------:|
| Allocator | 138 ms | 2146306.76 KB |
| Create | 230 ms | 2.88 KB |
| Shared | 33 ms | 2.53 KB |Нагрузка, не связанная с пулом, заняла 24 ms — второй уровень Shared пула уже не бесплатен, но пул по прежнему достаточно производителен — это достигается за счёт того, что потоки в бенчмарке берут массивы из разных списков и захватывают разные блокировки — contention не возникает.
Каждый поток не всегда использует только один список. Если при .Rent(N) подходящий массив не был найден в «своём» списке, то по кругу обходятся все остальные, лишь после этого аллоцируется новый массив. И если не возвращать массивы в пул обратно, то каждый вызов .Rent(N) будет по очереди захватывать все блокировки, приводя к большому contention.
| Pool | Mean | Lock Contentions | Allocated |
|----------------:|------------:|-----------------:|--------------:|
| Allocator | 138 ms | - | 2146306.76 KB |
| Shared | 33 ms | - | 2.53 KB |
| Shared_NoReturn | 968 ms | 3666.6667 | 2144145.85 KB |От этой проблемы есть некоторая «защита». Второй уровень пула (PerCoreLockedStacks) инициализируется только при первом возврате массива в него. Если нигде в программе массивы не возвращаются в пул, то .Rent(N) будет аллоцировать новый массив без захвата блокировок.
Также, вместимость Shared пула относительно небольшая — 8 массивов каждого размера в каждом PerCoreLockedStacks (т.е. 512 на размер максимум). И если требуется много массивов, каждый из которых будет использоваться долгосрочно — эффекта от пулинга не будет, т.к. неизбежно будут создаваться новые массивы, а потоки будут обходить блокировки в надежде найти хоть что-то в опустошенном пуле.
Диагностики
Для мониторинга работы стандартных реализаций ArrayPool предусмотрены события System.Buffers.ArrayPoolEventSource. Их можно получить через PerfView, dotnet trace, EventListener и другими способами. Основное событие, на которое имеет смысл смотреть — BufferAllocated — если аллоцируется много новых массивов, значит пулинг неэффективен. Проблему с lock contention в случае с Shared пулом можно вычислить по событиям Microsoft-Windows-DotNETRuntime/Contention/Start. Подробнее о диагностике .NET-приложений уже было описано в недавней статье.
Пример стектрейса из PerfView:
Name
Event Microsoft-Windows-DotNETRuntime/Contention/Start
+ module coreclr <>
+ module System.Private.CoreLib.il <>
|+ module app <b__24_0()>> Увы, о неэффективном использовании SpinLock нет никаких событий. Но о неэффективном использовании ConfigurableArrayPool можно узнать при профилировании или анализе дампа.
Пример стектрейса из dotnet dump:
Call Site
[HelperMethodFrame: 0000004e2f77f488] System.Threading.Thread.SleepInternal(Int32)
System.Threading.Thread.Sleep(Int32) [/_/src/libraries/System.Private.CoreLib/src/System/Threading/Thread.cs @ 375]
System.Threading.SpinWait.SpinOnceCore(Int32) [/_/src/libraries/System.Private.CoreLib/src/System/Threading/SpinWait.cs @ 196]
System.Threading.SpinLock.ContinueTryEnter(Int32, Boolean ByRef) [/_/src/libraries/System.Private.CoreLib/src/System/Threading/SpinLock.cs @ 359]
0000004E2F77F6D0 00007FFCCA93AC9D System.Buffers.ConfigurableArrayPool`1+Bucket[[System.Byte, System.Private.CoreLib]].Rent() [/_/src/libraries/System.Private.CoreLib/src/System/Buffers/ConfigurableArrayPool.cs @ 205]
System.Buffers.ConfigurableArrayPool`1[[System.Byte, System.Private.CoreLib]].Rent(Int32) [/_/src/libraries/System.Private.CoreLib/src/System/Buffers/ConfigurableArrayPool.cs @ 88]
PoolExperiments.b__21_0() [Program.cs @ 162] Пулы других объектов
Пока что речь шла лишь о реализациях ArrayPool — пулах массивов. Иногда требуется переиспользовать не только массивы, но и другие объекты. И их пулинг также имеет свои тонкости.
Второй уровень ArrayPool для массивов одного размера — по сути уже потокобезопасный пул одинаковых объектов. Казалось бы, почему не взять его в качестве пула объектов? В некоторых сценариях такой подход будет удачным, но большинство объектов, не являющихся массивами — маленькие. С одной стороны, это увеличивает требования к производительности пула — overhead от пулинга уже не спрятать среди полезной нагрузки. С другой — позволяет не заморачиваться с многопоточностью и сделать [ThreadStatic]Stack/Queue пул, локальный для каждого потока. Такой вариант не подходит для объектов, которые могут перемещаться из одного потока в другой, т.к. возникает риск опустошения пула в одном из потоков и переполнения в другом — разницы с аллокацией тогда не будет.
Также часто пул объектов реализуют на основе ConcurrentQueue. Например, так реализован DefaultObjectPool из пакета Microsoft.Extensions.ObjectPool, с тем отличием, что в нём есть ещё и первый уровень — поле _fastItem под хранение одного объекта. Это поле класса, не статическое, и не [ThreadStatic]/ThreadLocal. Работа с ним ведётся через atomic инструкции (Interlocked).
Вместо ConcurrentQueue можно использовать другую структуру данных — ConcurrentStack или ConcurrentBag. Использовать стек не имеет смысла — он аллоцирует по ноде связного списка на каждый элемент, и хуже масштабируется — когда ConcurrentQueue разрывается потоками с двух разных сторон, вся нагрузка на стек приходится только на один его край, а LIFO-порядок не даёт никаких преимуществ для пула. ConcurrentBag работает быстрее в случае, когда добавления и удаления элементов происходят из одного потока за счёт ThreadLocal<> внутри, но не догоняет по производительности алгоритм из ArrayPool.
Для теста были сделаны несколько реализаций пулов — наивные поверх одной concurrent-коллекции, глобальной Stack под локом (с _fastItem слотом и без), отдельным ThreadLocal Stack для каждого потока, также взяты DefaultObjectPool (и его модификация с ThreadLocal) и ArrayPool для сравнения. В качестве объекта использовался массив размером 1 КБ для унификации кода с бенчмарком для ArrayPool.
| Pool | Mean | Lock Contentions | Allocated |
|--------------------:|-------:|-----------------:|------------:|
| StackWithLock | 818 ms | 6476.0000 | 3.87 KB |
| StackWithLock+Slot | 685 ms | 3200.0000 | 3.30 KB |
| ConcurrentStackObj | 540 ms | - | 65539.59 KB |
| ConcurrentQueueObj | 455 ms | - | 3.82 KB |
| DefaultObjectPool | 320 ms | - | 2.99 KB |
| ThreadLocObjectPool | 208 ms | - | 2.87 KB |
| ConcurrentBagObj | 77 ms | - | 2.51 KB |
| Shared | 35 ms | 0.0667 | 2.49 KB |
| ThreadStaticStack | 27 ms | - | 2.44 KB |Структуре данных недостаточно быть lock-free, чтобы быть быстрой — разница с обычной блокировкой оказалась всего ~2 раза. Атомарные инструкции — не магия, хоть они и работают быстрее блокировок, но atomic write масштабируется плохо. В итоге для большей производительности следует пользоваться теми же техниками, что в ArrayPool — thread local слоты и шардирование разделяемого между потоками хранилища, чтобы минимизировать любую синхронизацию потоков.
В критичных для производительности местах внутри dotnet/runtime реализованы свои пулы. Например, в PoolingAsyncValueTaskMethodBuilder, использующимся для снижения числа аллокаций в асинхронном коде, реализован двухуровневый пул — [ThreadStatic] слот + слоты по количеству ядер, работа с которыми ведётся через Interlocked.
Bounded queue
Может возникнуть желание сделать свой собственный пул. Например, есть подозрение, что мешают блокировки внутри стандартного Shared пула — внешне это может проявляться как высокая tail latency в метриках сервиса (какие-то два потока делят один LockedStack — разделение происходит по ThreadId). Или нужен эффективный пул для объектов с общим хранилищем между потоками.
Казалось, можно взять ArrayPool и заменить LockedStacks на несколько ConcurrentQueue. Но важной деталью реализаций ArrayPool — поддержка ограничения числа элементов, хранящихся внутри пула. В пулах на основе ConcurrentQueue это реализуется с помощью дополнительного счётчика элементов, изменяющегося через Interlocked. Это, во-первых, замедляет работу с очередью, добавляя ещё одну точку синхронизации. Во-вторых, это неэстетично — ConcurrentQueue реализована поверх internal-класса ConcurrentQueue, который представляет из себя очередь с ограниченной ёмкостью. В результате, при использовании счётчика bounded-очередь обёрнута в unbounded, а поверх неё реализована bounded-очередь.
Возникает желание извлечь ConcurrentQueue в отдельный класс и использовать его для реализации пула. Причём, не только у меня. Об этом есть очень старый proposal в dotnet/runtime, но, что называется, не договорились. Сам класс ConcurrentQueue легко отделяется от ConcurrentQueue и сразу готов к использованию.
Протестируем такую реализацию. В случае, когда используется по одному LockedStack или очереди на каждое логическое ядро — разницы нет. Но если уменьшить шардирование в 4 раза, становится видна разница между разными вариантами. Это показывает, насколько важно предположение о том, что разные потоки будут пользоваться разными блокировками в структуре ArrayPool, а также то, что казалось бы легковесный Interlocked счётчик вокруг очереди всё же добавляет накладные расходы. Если же вас устраивает пул с неограниченной вместимостью, то ConcurrentQueue — хорошая структура для этой задачи.
Per core data structures:
| Pool | Mean |
| BoundedQueuePool | 33 ms |
| ConcurrentQueue | 33 ms |
| Shared | 33 ms |
| ConcurrentQueue+Counter | 33 ms |
(ProcessorCount / 8) data structures:
| Pool | Mean | Lock Contentions |
|------------------------ |------------:|-----------------:|
| BoundedQueuePool | 65 ms | - |
| ConcurrentQueue | 65 ms | - |
| Shared_Limited | 118 ms | 354.4 |
| ConcurrentQueue+Counter | 75 ms | - |Пулинг объектов помогает снизить аллокации и нагрузку на сборщик мусора, но сами пулы — сложные структуры данных, и неудачная или неподходящая для конкретного профиля нагрузки реализация пула может испортить производительность. Так, даже оставаясь в рамках стандартных реализаций пулов, для небольших массивов, нужных на короткое время предпочтительно использовать масштабирующийся ArrayPool, а для больших массивов — пул, созданный через ArrayPool как более вместительный и экономный в плане отсутствия разделения по потокам.
Также, если вам захотелось запулить все объекты в программе — подумайте дважды. Избыточный пулинг значительно усложняет код, особенно когда появляется ручной подсчёт ссылок и другие нетривиальные способы трекинга жизненного цикла объектов. Всё это не избавляет от риска использовать уже возвращённый в пул объект и не заметить этого. В некоторых случаях, проще положиться на сборщик мусора, или снизить число аллокаций другими инструментами, будто структуры, stackalloc, Span/Memory, или scatter-gather IO.
Кроме пулинга массивов и объектов есть и более сложные случаи, например динамические структуры данных — листы, хэш-таблицы; переиспользование объектов внутри concurrent структур данных. Но это уже совсем другая история.
