Что особенного в СУБД для данных в оперативной памяти
Константин Осипов (kostja)

Как родилась идея доклада? Я не очень люблю выступать и рассказывать про фичи, особенно про будущие фичи. Выясняется, что и люди не особо любят это слушать. Они любят слушать про то, как все устроено. Это доклад о том, как все устроено или должно быть, с моей точки зрения, устроено в современной СУБД.
Я попробую сделать так, чтобы мы смогли с макроуровня спуститься на микроуровень, т.е. каким образом, сначала отбрасывая макропроблемы, мы можем создать себе пространство для выбора на среднем уровне и микроуровне.

На макроуровне — это то, как должна быть устроена современная СУБД. Почему у нас сегодня есть возможность создавать новые базы данных, почему нельзя взять текущую и удовлетвориться ее производительностью, подтюнить или написать для нее патч? Просто взять и написать патч, который бы ее ускорил, если она медленная? Из какого пространства решений мы выбираем?
Дальше, после того, как мы какие-то базовые архитектурные принципы зафиксировали, нам нужно спуститься ниже и поговорить об инженерии. Помимо того, что есть базы данных, которые обрабатывают транзакции с помощью многоверсионного контроля версий, базы данных, которые обрабатывают транзакции с помощью блокировок, то, как ты реализовал этот алгоритм (условно говоря, насколько прямые у тебя руки) напрямую влияет на производительность. Если первый фактор дает тебе десятки раз масштабирования роста производительности, второй фактор дает тебе 2–3 раза, но тоже немаловажно, потому что когда потом с твоим решением выйдут на сцену, тебе не будет стыдно, что тот же Redis, хотя он конструктивно проще, не уделывает тебя как Тузик грелку, потому что, несмотря на то, что там миллион фич, ты не проседаешь по производительности и т.д. Это инженерия.
2-ая часть доклада — это про алгоритм и структуру данных, т.е. как мы фиксируем какие-то базовые инженерные подходы, работаем с тредами и т.д. И говорим, как мы реализуем те структуры данных, которые были бы самыми быстрыми и позволяли бы обрабатывать и хранить данные быстрее всего и качественнее всего.
3-я и 4-ая части — самые зубодробительные, потому что там я пытаюсь хотя бы по верхам рассказать про наши алгоритмы и структуры данных, которые мы реализовали.
Архитектура СУБД. С чего стоит начать? Почему есть окно возможностей в 2015 году для современной базы данных.

Напомню базовые требования, это то пространство, в котором мы можем играть. Есть требования ACID, которым мы должны удовлетворять. Любая база данных, которая считает, что она может скипнуть ACID, на мой взгляд, не подлежит серьезному рассмотрению, т.е. это такая поделка на коленке, потому что рано или поздно становится понятно, что нужно все-таки не терять данные, которые тебе дают, нужно быть дружелюбной для пользователей, нужно быть консистентной и т.д. Это академическое определение, но на самом деле даже в ACID на таком маленьком слайде — бездны, т.е. о нем можно говорить 2–3–4 часа.
Что такое DURABILTY? Я всегда, когда об этом рассуждаю, говорю, что такое DURABILTY в плане ядерной войны. DURABIL ли ваша база данных в случае атаки вероятного противника? Или ISOLATION — что это такое? Почему мы говорим, что хотим, чтобы видимость двух транзакций друг на друга не влияла? А что, если я хитрый парень, у меня есть 2 лаптопа, я и с одного лаптопа приконнектился, и с другого. В одном лаптопе я сказал begin, insert, потом я посмотрел, что туда вставил, на основе этого принял решение, во втором лаптопе сделал begin, insert уже тех данных, что я глазками своими посмотрел. Какой я хитрый, я обманул ISOLATION. Есть ли тут какие-то гарантии? Но, тем не менее, это правила игры.
И одно из них, самое фундаментальное, которое очень серьезно влияет на производительность — это Isolation. Почему? Потому что изоляция транзакций друг от друга — это такая штука, которая влияет на очень много вещей сразу. Т.е. можно сделать так, чтобы кто-то читал свою версию данных и не мешал другому человеку (как работает Postgres, MySQL с InnoDB). Но как только речь заходит о записи, то у нас происходит дилемма. У нас нет способа обеспечить изоляцию двух участников, которые пытаются обновлять одни и те же данные и при этом полностью изолировать друг от друга с алгоритмичной точки зрения.

Нам необходимо в том или ином виде сигнализировать другому участнику, что одновременно кто-то еще работает с этими данными. Формализуется это в теории через понятие расписания (я привел пример расписания). У нас есть data items, т.е. X и Y — это наши данные, 1 и 2 — это наши участники, r и w — это обозначение операций. Участники читают или пишут данные, E — это расписание, по которому они работают.

В конечном итоге, единственный внушительный способ обеспечить изоляцию — это блокировки, т.е. фундаментом для баз данных 20-ти, 30-тилетней давности было то, что они базируются вокруг теоремы о двухфазных блокировках.

Т.е. мы говорим о том, что для того, чтобы добиться сериального расписания участники должны захватывать блокировки на те объекты, которые они меняют. При этом есть многоверсионный конкаренси контрол, который позволяет нам в некоторых случаях этих блокировок избежать или отложить их захват, т.е. мы можем в конце, на момент коммита уже проверить, валидировать каким-то образом, что не была нарушена целостность. Т.е. блокировки сильно на участников не влияют, но, тем не менее, даже в многоверсионном конкаренси контроле, в таких алгоритмах требуются в определенных сценариях блокировки на несуществующие объекты. Самый строгий режим сериализации — в классических СУБД это называется serializable, там все равно требуется захватывать блокировки.

Это фундаментальный механизм, и он зафиксирован в академическом сообществе через теорему о двухфазных блокировках, которая более-менее является фундаментальной, т.е. нам нужно эти блокировки накапливать. Классические СУБД построены вокруг этой схемы.

Помимо этого, классические СУБД изначально были построены во вселенной, где соотношение «диск — память» совсем другая, не такая, как сейчас. Условно говоря, можно было иметь 640 Кб памяти и 100 Мб диск — и это было хорошо. Т.е. отношение где-то 1 к 100. Сейчас отношение часто 1 к 1000, т.е. изменились эти отношения. А скорости изменились еще более радикально, т.е. если раньше оперативная память была всего лишь в 100 раз быстрее диска, то сейчас она в 1000 или в 10000 раз быстрее диска. Произошло радикальное изменение соотношений, из которых приходилось выбирать.
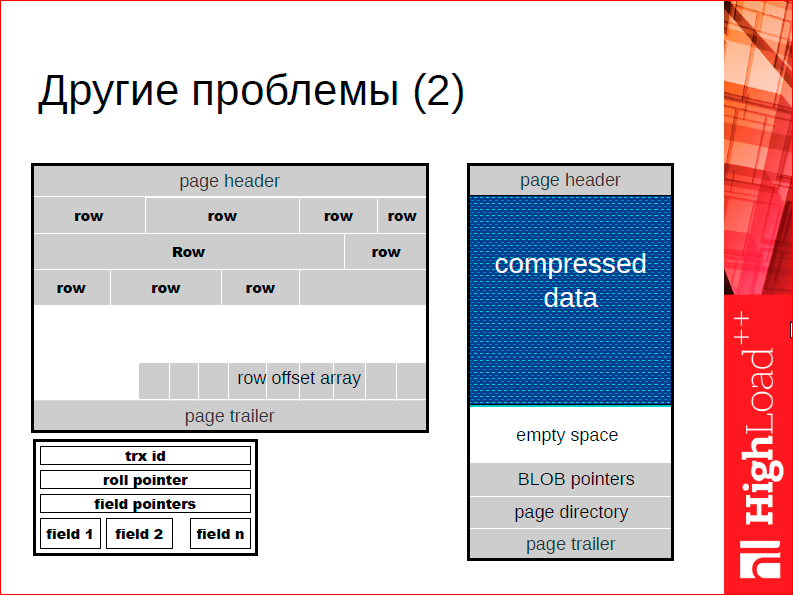
Классический пример того, почему это имеет значение, — это то, что классические СУБД устроены по принципу двухуровневого хранения, т.е. у вас есть какое-то представление данных на диске и у вас есть представление данных в памяти. Память фактически кэширует ваше представление на диске. У вас неизбежно возникает необходимость трейдоффа между тем, чтоб эффективно работать с диском и эффективно работать с памятью.
В частности, чтоб эффективно работать с диском… Обратите внимание на белое пространство на слайде — это типичная страничка типичной СУБД, которая хранит строчки. Обычно страничка недозаполнена, потому что у нас дисковое пространство не дорогое, а стоимость записи на диск растет не пропорционально размеру, который мы записываем, а пропорционально количеству обращений к диску. Соответственно, нам имеет смысл иметь дырки на диске, потому что не страшно, запишем мы эту дырку, записать дырку нам ничего не стоит.
В оперативной памяти история совсем другая. Там важно, чтобы данные занимали как можно меньше пространства, потому что стоимость обращений более-менее одинаковая. Оперативная память имеет более-менее одинаковую цену рандомного доступа, соответственно, нам имеет смысл делать вещи как можно более компактными. Одним из таких факторов является то, что если вы сделаете с нуля СУБД для оперативной памяти, то вам имеет смысл пересмотреть более-менее фундаментальные алгоритмы и структуры данных, на которых вы делаете, т.е. вы можете от этих дырок избавится — это только один из примеров.
Кстати, если говорить об этом примере, получается интересная история. Многие говорят: «Зачем нам СУБД X, мы пользуемся СУБД Y и просто добавим ей памяти». Я видел такие сценарии, когда люди берут базы данных, которые предназначены для секондари сторадж, т.е. для дисковой базы MySQL, Postgres, Mongo, дают ей определенный объем памяти, у них все влезает в память, и они счастливы. Только экономический расчет здесь сразу ущербен, потому что если делать базу данных в памяти, то типичный memory footprint, т.е. объем занимаемой памяти может быть в разы меньше просто за счет того, что нет всех оферхедов, связанных с хранением на диске. Экономически это неправильно — брать СУБД, которая предназначена для хранения на диске, выбрасывать деньги и помещать все данные в памяти.

Мои такие измышления основаны не на пустом месте. В 2008 году вышла статья одного из классиков мира СУБД, с анализом деятельности, которую СУБД проводит в разных подсистемах, т.е. сколько процентов усилий и на что приходится у СУБД. Были выделены основные подсистемы блокировки, latching — это те же самые блокировки, но только на более низком уровне, когда нам нужно блокировать не данные, а процессы, которые между собой взаимодействуют. И в этой статье делается вывод, что лишь 12% современная СУБД тратит на полезную работу, все остальное она тратит на эти магические буквы ACID и на взаимодействие с устаревшими архитектурами, т.е. на работу, построенную по принципу устаревших архитектур. Именно из этого графика исходит это окно возможностей, которое позволяет ускорить СУБД в десятки раз при этом без потери функционала или без существенной потери функционала.
Как же мы можем избавиться от всех этих локинг, летчинг и т.п. штук? Как мы можем избавиться от оверхеда на перегон данных с дисков памяти и на изменение форматов представления? Вот те базисы, которые я выписал и которые легли на основу архитектуры Tarantool:

На самом деле, это не уникальная архитектура. Если вы посмотрите на Memcached, на Redis, на VoltDB, окажется что мы не одни такие, т.е. дальше мы берем и начинаем соревноваться, условно говоря, в своей лиге. Мы уходим в свою лигу, в которой мы говорим, что:
- у нас 100% данных хранится в RAM,
- мы выполняем транзакции последовательно так, чтобы нам не было необходимости брать блокировки; у нас нет самого понятия блокировки, мы просто отдаем тот объем RAM, который у нас отведен на транзакцию, она им эксклюзивно пользуется, потом мы выполняем следующую транзакцию.
Мы, все равно, говорим, что будем шардировать данные, т.е. у нас горизонтальное масштабирование — это норма, поэтому мы даже не пытаемся сделать так, чтобы база данных работала эффективно на одной машине. Одна машина сегодня — это все-таки супер компьютер. 48 ядер, которые имеют разную стоимость доступа к оперативной памяти, т.е. если вы к одному участку из одного ядра обращаетесь — у вас одна цена, к тому же самому участку из другого ядра — у вас другая цена обращения. Это уже суперкомпьютер, и говорить, что эффективная работа на одном компьютере — это та же самая задача, что 10–20 лет назад, уже не приходится, поэтому мы не будем решать эту проблему вообще.
Есть во всей этой истории один интересный момент. Мы говорим, что у нас в памяти есть СУБД, которая выполняет транзакции последовательно. Что же происходит? Если во время выполнения транзакции нам нужно данные не терять, мы должны их записывать в журнал, т.е. эту работу мы отменить не можем. У нас остается журнал, журнал хранится на диске. Если мы будем писать каждую транзакцию в журнал, одну за другой, то мы все равно упремся в проблему производительности, потому что диск медленный, т.е. то, что мы мало используем CPU, нам ничего не дает, диск медленный. Нам нужно придумать, как журнал писать большими объемами, по 100, по 1000 транзакций за раз, тогда мы сможем разнести эту стоимость записи на множество транзакций и повысить фрупут, т.е. пропускную способность. Мы таким образом не повысим производительность, т.е. для каждой транзакции latency у нас останется тем же самым и будет соответствовать стоимости записи на диск, но объем и пропускную способность мы так можем повысить.

Возникает проблема: каким образом откатывать транзакции, если запись журнала не удалась? Я, в принципе, не встречал данные технологии в литературе, но в Tarantool используется аналогия, связанная с кинолентой. Допустим, у нас есть транзакция, которая уже завершилась в памяти, и нам нужно записать ее в журнал. Эта транзакция ждет своей очереди, пока медленный диск ее запишет. В этот момент пришла другая транзакция, которая читает или обновляет те же самые данные. Что с ней делать? Запретить ей выполняться? Если мы запретим ей выполняться, у нас производительность резко упадет. Если мы разрешим ей выполняться, может оказаться, что транзакция, которая ждет своей очереди, не записалась, закончилось место на диске. Что нам тогда делать? Откатывать. \
Откат в Tarantool устроен по принципу обратной раскрутки, т.е. все транзакции выполняются в оптимистическом режиме одна за другой, не ожидая друг друга. Как только происходит какая-то ошибка, ошибка происходит много позже, спустя какое-то время после того, как транзакция выполнилась в памяти. Мы останавливаем наш конвейер и раскручиваем его в обратную сторону. Выкидываем все, что фактически видело «грязные» данные и перезапускаем конвейер. Это безумно дорогая операция. Возможно, потеряется 10000 транзакций под большой нагрузкой, но т.к. она случается крайне редко (в эксплуатации она не случается никогда), вы просто следите за местом на диске.
Ну, «никогда» — это категорично, но фактически, если вы следите за оборудованием, она не случается. Это издержка, на которую стоит идти. И вообще, в целом, когда проектируешь систему, нужно ее проектировать вокруг наиболее вероятного сценария. Если пытаешься стоимость архитектурных решений сделать одинаковой, просто перечисли:, а что если будет откат, что если будет коммит, что если будет еще что-то?… Если код соответствует этому, то скорее всего, эффективной системы не построить, потому что вы будете по худшему случаю себя оценивать.
Зафиксировав т.о. эти базовые принципы, мы переходим к аспектам инженерии. Что хочется сказать про инженерию.

На конференции будет доклад про базу данных в памяти, она называется ChronicleMap, и ChronicleMap интересна тем, что цель, которую перед собой ставили инженеры этой СУБД — это достичь микросекундной latency на обновление СУБД. Задача была в первую очередь, чтобы обновление занимало гораздо меньше времени. В нашем случае ситуация немного другая. И мы этот трейдофф решаем в другую пользу. О чем здесь идет речь? Представим себе, что вам нужно добраться на конференцию, и пробок нет, что вы возьмете? Вы возьмете такси, и это будет быстрее. Вы воспользуетесь общественным транспортом — это будет дешево. Почему общественный транспорт дешев? Потому что он размазывает стоимость на множество участников. Происходит вагонизация, т.е. вы вместе со всеми разделяете стоимость эксплуатации. И в нашем случае цель именно такая.
Если другие СУБД ставят перед собой задачу, допустим, иметь очень низкий latency, но, возможно, не максимальный throughput, т.е. пропускную способность, в нашей ситуации мы говорили, что тот latency, который нам дает оперативная память для нас достаточно — это, допустим, несколько миллисекунд на обработку одного запроса. Это тот параметр, на который мы хотим выйти и в остальном мы хотим оптимизировать throughput, т.е. пропускную способность. Мы делаем так, чтобы максимальное количество запросов разделяло издержки между собой. Что это значит с точки аспектов инженерии?
У нас есть медленная сеть, и сеть, по сути, дорогая. Она дорогая по обмену, потому что мы живем в древнем мире операционных систем сорокалетней давности, и нет способа сходить в сеть, не заглянув в ядро. У нас есть диск, который тоже очень дорогой, сама запись диска медленная, но нам диск писать надо, потому что это единственный способ сохранять данные, чтобы они пережили отказ по питанию. Еще у нас есть транзакшн процессор, который работает в одном треде и выполняет транзакции одну за другой, т.е. транзакшн процессор — это наш конвейер. Каким образом нам сделать так, чтобы этот конвейер у нас простаивал минимально?
Если у нас конвейер на каждый запрос будет обращаться в сеть, потом обращаться на диск, а скорее всего это нужно сделать 2 раза, т.е. ему нужно прочитать запрос, обработать его, записать на диск, ответить, дать результат клиенту. Т.е. в сеть мы обращаемся 2 раза, один раз на диск. Вся эта катавасия займет очень много времени. Нам нужно сделать так, чтобы мы из сети читали максимально быстро, относительно одного запроса — максимально дешево. Что мы для этого делаем? Мы говорим, что наш протокол полностью асинхронен, мы работаем в режиме пайплайнинга, т.е. мы можем из одного коннекта читать запросы множества клиентов и отвечать всем клиентам одновременно. Т.е. каждый клиент получает свой ответ, мы мультипликсируем все это на одном сокете и у нас пайплайнинг идет на каждом уровне, т.е. конвейеризация на каждом уровне работы. И это очень существенный трейдофф, вокруг которого строится СУБД. Поэтому мы работаем в одном треде, поэтому мы даем более низкий latency, чем какие-то другие решения, которые малтитредад, но мы за счет этого снижаем издержки на один запрос.

С точки зрения реализации необходимо найти способ параллелизации парадигмы, в которой мы будем существовать, в которой мы будем все это параллелить. Такой парадигмой является одна из следующих.

Мы фактически должны выбрать что-то из этого. Если мы говорим, что у нас есть конкурентные треды, мы каким-то образом между этими тредами обмениваемся информацией, нам нужно выбрать способ обмена.
Почему это особенно важно в нашем случае? Потому что выбор способа обмена между тредами влияет не только на эти издержки, которые более-менее явные — поход в ядро, поход на диск, поход в сеть, но он имеет такие неявные вещи, например, как часто мы флашим кэш, кэш процессора, т.е. мы с кэшем хорошо работаем или плохо? И с учетом того, что это происходит неявно, фактически это поиск в тумане. Что-то изменил — кэш начал работать чуть лучше, у тебя чуть увеличилась производительность.
Фактически мы сейчас в каком мире живем? Помимо этой большой оперативной памяти, с которой мы имеем дело, у нас от 16 до 32-х Мб кэша 3-го уровня, которая разделяется между всеми ядрами, и чем эффективней мы начнем использовать кэш 3-го уровня, тем лучше мы будем работать. Таким образом, наша задача — сделать так, чтоб кэш 3-го уровня реально работал, работал эффективно.
Вот, у нас есть такой выбор (см. слайд выше), и если мы говорим о парадигмах, мы должны выбрать какую-то парадигму, в которой все это закодировано.
Забегая вперед, я скажу, что мы выбрали последнюю парадигму — это actor model, почему?

Что можно сказать о локах? Я программировал с использованием мутексов всю свою сознательную жизнь — прекрасный инструмент. Одна из существенных проблем мутексов для эффективного программирования — это проблема композабилити. О чем здесь речь? Представьте, что у вас есть критическая секция, которую вы, допустим, вставляете в конкурентную структуру данных. Структура данных работает с кучей тредов. Вы берете эту критическую секцию, инкапсулируете ее в какой-то метод. У вас есть метод insert в какую-то конкурентную структуру данных. Далее у вас есть еще некая макроструктура, которая пользуется этой структурой данных, и она также должна работать в критической секции, т.е. она должна быть также конкурентна. Блокировки не позволяют вам просто взять и вызвать один метод из другого, вы должны 10 раз продумать, почему? Не приведет это к дедлокам или к каким-нибудь другим проблемам, которые я здесь описал. Откуда это может все возникнуть? Вы просто не можете произвольным образом использовать код, который использует блокировки друг из друга, у вас теряется основное свойство программирования, когда мы можем совершать инкапсуляции, докомпозировать проблемы в более мелкие. На самом деле wait-free алгоритмы решают одну проблему — проблему дедлоков. Wait-free алгоритмы не дедлочатся, потому что они не ждут. Но они не решают других проблем? связанных с алгоритмами? построенными вокруг модели блокировок.

Дедлок — это цикл ожидания. Мы из какого-то места кода используем локи в порядке А, В, из другого места кода мы используем локи в порядке В, А. Опа! И у нас под нагрузкой все это схлопнулось — дедлок.
Что такое конвоирование и хотспоты? Это относится, в том числе, и к wait-free алгоритмам. В чем проблема? Вы написали свою программу в предположении, что это критическая секция работает с двумя тредами. У нее, допустим, есть продьюсер-тред, консьюмер-тред, эти треды обращаются к этой критической секции в среднем… Допустим, у них нагрузка в 1000 запросов в секунду. Соответственно, они обращаются к критической секции 1000 раз в секунду — у вас все работает. Дальше у вас обстоятельства меняются. Меняется железо или меняется работа, которую выполняют треды, или меняется окружение, с которым они работают, т.е. у вас появляется еще неизвестное в этой системе. Мы говорим о композабилити, т.е. вы начинаете систему расширять и настраивать, и ваша критическая секция внезапно становится горячей. Допустим, какая-то мелкая вещь, которая под критической секцией фактически две переменные обновляет, но она начинает дергаться, не 1000 раз в секунду, как вы планировали, а 10000 раз в секунду, 100000 раз в секунду, и вокруг нее происходит постоянная борьба, снимаются треды с управления и т.д. Что может произойти дальше?
Вы можете попробовать поиграть с приоритетами или порядком, т.е. вы говорите, что какие-то запросы более приоритетны, какие-то менее приоритетны. Это может привести к тому, что более приоритетные запросы к критической секции начинают вытеснять менее приоритетные. Менее приоритетные никогда не выполняются — это голодание.
Конвоирование — это, как раз, та ситуация, когда у вас маленькая критическая секция вложена в большую и из-за этого к маленькой критической секции не пробиться.
Есть множество разных ситуаций, которые так или иначе выражаются в одном выводе — локи не компоузебл. Система написана вокруг блокировок и, если это является основным примитивом программирования, из этого нельзя строит масштабируемые системы.
Это было понятно не только мне, но и создателям Erlang«а, которые сделали его 30–40 лет назад. По большому счету, если говорить о том инструменте, на котором должен быть написан Tarantool — это инструмент, наверное, называется Erlang.

В целом, один из подходов, который может разрешить проблему композабилити, — это подход функционального программирования, когда критические секции явно не задаются, а во время выполнения параллелизмы определяются на основании функциональных зависимостей. Другими словами, вы нигде не берете никаких локов, но если у вас одна и та же функция является функциональной зависимостью от другой, то вы можете распараллелить ее выполнение прозрачно для автора.
Этим пользуются всякие функциональные языки, которые умеют это достаточно хорошо делать. У вас нет общих данных, и поэтому у вас нет конфликтов по общим данным, т.е. функциональное программирование, вроде как, подходит.
Но, к сожалению, если говорить о системном программировании, т.е. поженить функциональный подход и системное программирование, то сред, на которых можно основываться, у нас сегодня нет.
Таким образом, мы приходим к модели, которую я заспойлил в самом начале, а это именно то, на чем нам нужно останавливаться, что позволяет нам делать компоузебл систему и делать ее дешево.

Чем привлекательна Actor model, т.е. модель обмена сообщениями между независимыми участниками? У нас однотредовая система, в этой системе уже есть кооперативная многозадачность, т.е. на уровне одного треда мы создали микропотоки, которые линейно выполняются, а взаимодействовать между собой они могут как через общую память, потому что там нет никаких проблем, но они могут взаимодействовать между собой так же и через посылку сообщений.
Нам осталось решить проблему для взаимодействия между тредами. Вернемся к картинке «Система массового сообщения»:
У нас есть Network тред, Transaction Processor тред, Write Ahead Logging тред и для каждого запроса в каждом треде концептуально есть какая-то сущность — actor, актер. Задача актера в network треде — взять запрос, распарсить его, проанализировать его корректность и отправить сообщение «выполни этот запрос» Transaction processor«у. Transaction processor берет запрос, проверяет нет ли там duplicate key, нет ли там каких-то еще constraint violation, выполняет какие-то триггеры, вставляет его везде, и говорит: «Ок» соответствующему ему бади в write ahead log — запиши этот запрос на диск. Он берет запрос и записывает на диск.
В буквальном смысле, если бы мы так делали, мы бы обменивались сообщениями на каждый запрос. Мы хотим сократить это, т.е. мы в этой парадигме хотим, чтобы действительно сущности в нашей программе обменивались сообщениями, но издержки на этот обмен были минимальными, т.е. нам нужен какой-то способ мультиплексировать обмен. И Actor model за счет того, что она инкапсулирует обмен сообщениями, позволяет сообщения передавать пачками. Т.е. мы берем Actor model, говорим, что для того, чтобы что-то сделать, нужно послать сообщения между соответствующими Actor«ами в разных тредах, и под капотом каждый раз, когда происходит посылка сообщения, мы соответствующего Actor«а соспейдим, т.е. снимаем его с управления и передаем управление следующему Actor«у. Таким образом, на основе корутин в каждом треде у нас постоянно происходит работа, но также постоянно происходит переключение между Actor«ами.
Почему это для меня является центральным моментом? Я даже нарисовал красивый гиперкуб на слайде «Actor model» (см. выше), на котором я пытаюсь подчеркнуть важность именно такой парадигмы. В чем свойство гиперкуба? В том, что количество связей там растет пропорционально количеству узлов, т.е. не квадратично, а пропорционально.
Если взять Tarantool, то вершинами в этом гиперкубе можно считать отдельные треды. Мы хотим сделать так, чтоб связность между тредами была низкой, таким образом, мы через линки между вершинами образуем связи между тредами. И наша задача — поддерживать низкое количество связей, чтобы обмен был дешевым.
Если вспомнить какие-то древние суперкомпьютеры типа Крея, и вы посмотрите на дизайн, окажется, что они на самом деле были построены по принципу гиперкубов. Вообще, если смотреть на обычные механические телефонные свичи, они пытаются решить ту же самую проблему — как в наше трехмерное пространство уместить мультиплексирование множества взаимодействующих сущностей и сделать это эффективно. Это получается уже какое-то пространственное мышление, а не инженерное.
Почему нарисован 4-х мерный гиперкуб? Я говорил только об одном треде и взаимодействии в одном треде, но при шардировании появляется та же самая проблема — запрос приходит на любой узел в кластере, и этот узел должен взаимодействовать со всеми узлами для того, чтобы этот запрос обработать. Имеем ту же самую проблему квадратичного роста количества связей, т.е. у нас n квадрат связей от количества участников. И единственный способ это количество связей контролировать — это каким-то образом загнать его в такое пространство.
Почему эта модель является хорошей с точки зрения современной системы? Посмотрите, если взять типичный чип, эта штучка в центре — это кэш 3-го уровня:

Очень занятным в этом смысле является спор между поклонниками архитектур CISC и RISC в 2015 году. Я обеими руками выступаю за ARM процессоры — у них лучшее энергосбережение и т.д., но меня смешит спор про архитектуры, потому что, по большому счету, современный CPU — это огромный кэш 3-го уровня, все остальное — это 15% от чипа. Спор про то, какой процессор эффективней в этой истории — тот, кто работает с кэшем 3-го уровня лучше, тот и эффективен.
Почему Actor model хороша, в том числе, для современного железа? Если посмотреть на доступ к кэшу 3-го уровня, то чем меньше мы туда лезем, тем лучше. Каждый раз, когда мы вынуждены послать какое-то сообщение, т.е. синхронизировать два конкурентных процесса, мы должны так или иначе залочить эту шину обмена, чтобы обеспечить консистентность данных. Например, в Intel меняешь данные в одном процессе, и они в конечном итоге поменяются во всех. Поэтому нам лучше всего редко менять разделяемые данные. Идея с мультиплексированием обмена сообщениями состоит ровно в этом — чтобы разделить эту стоимость, лочить шину обмена от 1000 до 10000 раз в секунду. Это нормальная производительность, дает приемлемый для нас latency в 1–2 мс на обработку запроса, таким образом, снижаются издержки на обмен.
Часть 3 посвящена памяти, все-таки, мы — СУБД в памяти, и мы должны очень много внимания посвящать памяти.

Зачем были части 1 и 2? Я пытался показать, каким образом мы от всего пространства решений спускаемся на уровень ниже.
Сейчас мы упростили себе проблему — у нас нет конкурентности, у нас есть память, которую должен обрабатывать один тред. Нет памяти, разделяемой между тредами, весь обмен между тредами происходит за счет обмена сообщениями.
Что же делать дальше? Как сделать так, чтобы в одном треде работа с памятью была эффективной?
На слайде я показал, чем не подходит классический менеджер. Допустим, у нас есть свой, какие требования к нему мы предъявляем?

Наши уникальные требования, в первую очередь, это поддержка квот. Мы гарантируем пользователю, что мы не выходим за отведенную нам память. Если происходит ошибка, часто возникает вопрос: «а вы крэшитесь, если у вас кончается память?». Можем, если есть ошибка в коде, но в целом, если кончается память, система перестает сохранять данные, но продолжает работать — отдавать текущие данные. Это одна из целей.
Вторая цель. Есть такая штука как компактификация журнала. Нам нужно периодически сбрасывать на диск весь наш снимок, всю нашу память для того, чтобы ускорить восстановление, т.е. для этого нам нужны консистентные снимки памяти. Более того, нам нужны консистентные снимки, если мы хотим поддерживать так называемые интерактивные транзакции, т.е. транзакция, которая началась на клиенте, работает, если мы хотим делать классический multiversion concurrency control, то для этого тоже нужны консистентные снимки.

Аллокаторы памяти в этом одном треде выстроены по определенной иерархии, и вершины иерархии являются поставщиком памяти уровня ниже. Наш подход заключается в том, что мы пытаемся инкапсулировать как можно меньше при работе с памятью, т.е. мы предоставляем программисту СУБД набор инструментов, подходящий для соответствующих ситуаций. На вершине иерархии находится объект, который глобален, в принципе, их может быть много, у нас их сейчас два — память (квота) под данные и квота под runtime.
Квота под runtime у нас сейчас не ограничена, но ее можно задать. Глобальным объектом на вершине иерархии является квота. Квота — это очень простой объект, в котором хранятся две величины — разрешенный пользователям объем и текущий потребленный объем. Это объект конкурентный, и он разделяется между этими тремя тредами.
Пользователем квоты является так называемая арена. Арена выглядит таким образом:

Фактически это дисп
