ClearML | Туториал
Исходники
Документация
Лицензия: Apache License 2.0
ClearML — это фреймворк для трекинга ML-экспериментов. Это основное его предназначение. Но сейчас функционал ClearML гораздо шире и позволяет:
Отслеживать метрики, гиперпараметры и артефакты машинного обучения.
Хранить и предоставлять по запросу модели.
Хранить датасеты.
Визуально сравнивать эксперименты.
Воспроизведить эксперименты.
Автоматически логировать все действия.
Настраивать пайплайны обработки данных.
Визуализировать результаты.
И т.д.
Главный конкурент ClearML — Weights & Biases. Но у ClearML есть два серьезных преимущества:
Облачной версией могут пользоваться бесплатно даже небольшие команды.
Есть полноценная локально разворачиваемая версия.
Установка и настройка
Для начала нам понадобится питон-пакет. Выполните в консоли команду:
pip install clearmlДалее вам нужно связать установленный пакет clearml с сервером ClearML, на котором будут храниться все ваши артефакты. Тут есть два варианта:
Для туториала я воспользуюсь облачным сервисом:
Откройте https://app.clear.ml/settings/workspace-configuration (создайте акаунт если у вас его нет).
Нажмите Create new credentials. В открывшемся окне на вкладе LOCAL PYTHON будут отображаться (в черном окошке) данные необходимые установщику.

clearml-initУтилита попросит ввести конфигурационные параметры. Скопируйте всю информацию из черного квадрата (начинается с api…) и вставьте ее в консоль.

Введенную конфигураци ClearML сохранит в C:\Users\
После этого все попытки использовать ClearML из .py файла автоматически задействуют эту конфигурацию.
Но, если вы будете использовать ClearML из ноутбука, то вам дополнительно понадобится объявить служебные переменные в самом ноутбуке. Найти их вы сможете на вкладки JUPYTER NOTEBOOK того же окна CREATE CREDENTIALS. Нужно скопировать их и выполнить в первой ячейке ноутбука.

Терминология
Технически в ClearML приянята следующая структура:
Проект
Задача это некий минимальный полноценный эксперимент. Например, с т.з. бизнеса задачей може быть:
R&D эксперимент: поиск гиперпараметров, исследование новой архитектуры нейронной сети, задействование очередного фреймворка и т.д.
Периодическое переобучение модели.
З.Ы. В своей терминологии ClearML предлагает следующие типы Задач:
training (по-умолчанию) — обучение модели.
testing — тестирование (например, производительности модели).
inference — выполнение предсказания модели.
data_processing — процессы обработки данных.
application — какие-либо еприложения.
monitor — мониторинг процессов.
controller — задача, определяющая логику взаимодействия других задач.
optimizer — специальный тип для задач оптимизации гиперпараметров.
service — служебные задачи.
qc — контроль качества (например, A/B тестирование).
custom — прочее.
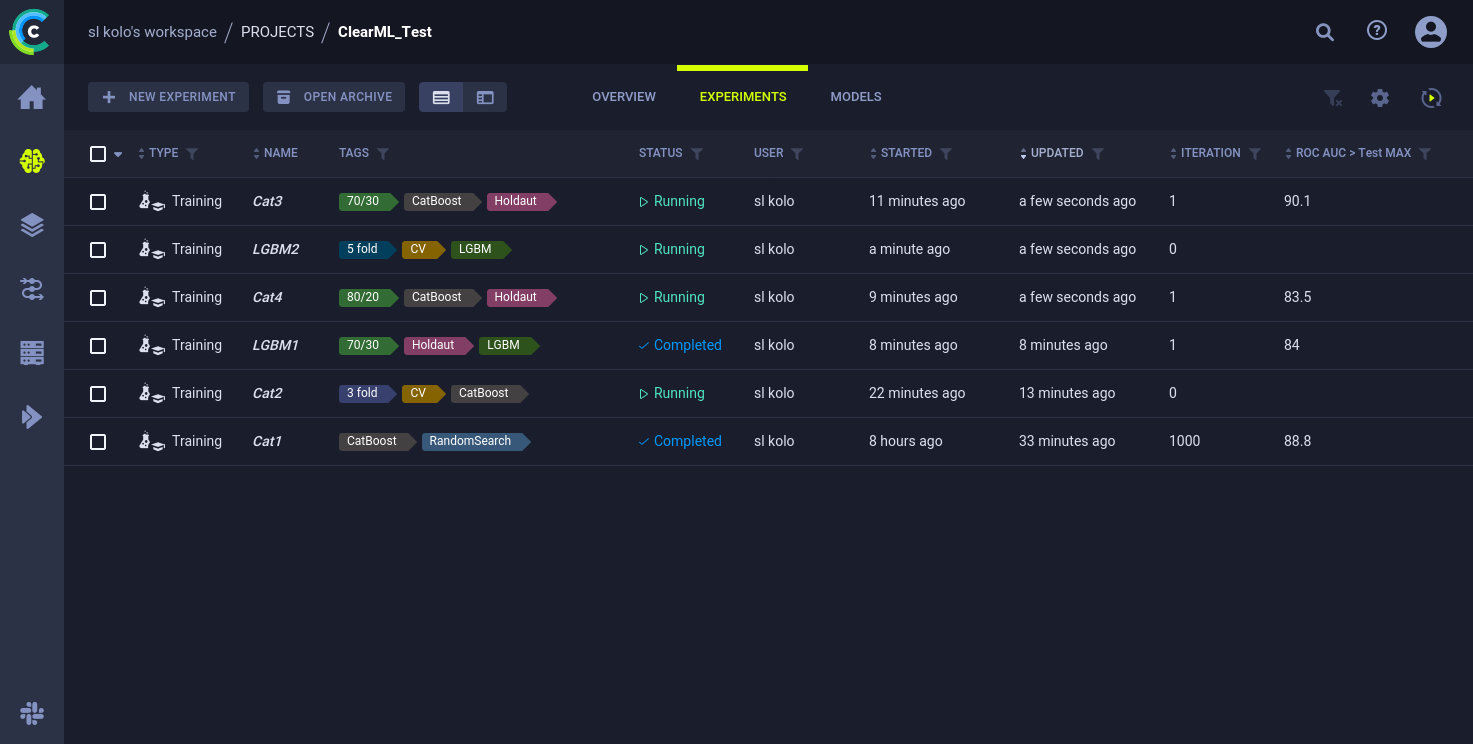
Выбранный тип будет отображаться в списке проведенных экспериментов.
А теперь попробуем пройти все шаги обучения модели на еще не заезженном датасете титаника :)
Простой процесс
Дальнейшие действия я буду выполнять в ноутбуке (каждый кусок кода в отдельной ячейке). Поэтому сначала иницируем служебные переменные (у вас значения будут отличаться):
%env CLEARML_WEB_HOST=https://app.clear.ml
%env CLEARML_API_HOST=https://api.clear.ml
%env CLEARML_FILES_HOST=https://files.clear.ml
%env CLEARML_API_ACCESS_KEY=QZY14BD1QAL151CWFZ5L
%env CLEARML_API_SECRET_KEY=x8Lhn5RdQpwk21oKoldbg5H0EuMfn50Soxw1uOVsy5VLEtBfuRimport pandas as pd
import numpy as np
from clearml import Task, Logger
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, ParameterSampler
from catboost import CatBoostClassifier, Pool
from sklearn.metrics import roc_auc_score task = Task.init(
project_name='ClearML_Test',
task_name='Cat1',
tags=['CatBoost','RandomSearch'])Тут произошли две важные вещи:
ClearML создал новую Задачу в указанном Проекте.
В выводе появится ссылка на веб-страницу эксперимента — откройте ее (или ручками перйдите к Задаче через интрефейс).

Каждый раз выполняя этот кусок кода на сервере будет создаваться новая Задача.
З.Ы. Вы можете получить програмный доступ к ранее созданой Задаче (и всем ее артефактом), просто подключившись к ней по Id или по имени Задачи и Проекта:
prev_task = Task.get_task(task_id='123456deadbeef')
# или
prev_task = Task.get_task(project_name='proj1', task_name='my_task')ClearML начнет автоматически логировать все стандартные вводы и выводы, а также выводы многих популярных библиотек.
Например, на вкладке Execution можно увидить вводимый код и все иницированные библиотеки и их версии (см. скрин выше). А т.к. мы выполняем код в ноутбуке, то на вкладке Artifacts можно найти ссылку на полностью скомпилированый ноутбук в виде HTML-страницы (и сохраненный на стороне сервера).

Если при выполнении метода init указанного Проекта не существует, то ClearML автоматически создаст его –, но это не по фэн-шую :)
fpath = 'titanic.csv'
df_raw = pd.read_csv(fpath)
task.upload_artifact(name='data.raw', artifact_object=fpath)Тут, поимимо загрзуки данных в пандас, мы попутно отправляем наши данные в ClearML как Артифакт, просто указав путь к CSV-файлу и задав имя артифакта. Все загруженные артифакты можно найти на вкладке Artifacts, соответствующего эксперимента. И отсюда же вы можете их скачать.

При создании артифакта вы можете указать путь к целой папке, тогда ClearML поместит ее содежимое в zip-архив и сохранит как артефакт.
task.upload_artifact(
name='eda.describe.object',
artifact_object=df_raw.describe(include=object))
task.upload_artifact(
name='eda.describe.number',
artifact_object=df_raw.describe(include=np.number))ClearML может хранить в виде Артифактов практически любые Python-объекты. Здесь мы поместили в Артефакт вывод пандосовского метода describe. Причем мы можем посмотреть на этот вывод в интерфейсе ClearML.

sns.pairplot(df_raw, hue='Survived')
plt.title('Pairplot')
plt.show()ClearML автоматически логирует вывод любого использования Matplotlib (именно для этого здесь метод show, хотя Seaborn и без него бы вывел график) — все выведенные графики вы найдете на вкладке Plots.

df_preproc = df_raw.drop(columns=['PassengerId','Name','Ticket'])
for col in ['Sex','Cabin','Embarked']:
df_preproc[col] = df_preproc[col].astype(str)
task.upload_artifact(name='data.preproc', artifact_object=df_preproc)
train, test = train_test_split(df_preproc, test_size=0.33, random_state=42)
task.upload_artifact(name='data.train', artifact_object=train)
task.upload_artifact(name='data.test', artifact_object=train)Мы сформировали еще три датасета и все три отправили в ClaerML как Артефакты. Но в отличии от первого раза, сейчас мы напрямую указали пандосовский датасет. ClaerML понимает этот формат и мы можем (частично) посмотреть на датасет прямо из интерфейса ClaerML.

Пандосовский Артефакт можно также зарегистрировать методом register_artifact. В отличии от upload_artifact он автоматически детектирует изменения датафрейма и синхронизирует их с сервером.
X_train = train.drop(columns=['Survived'])
y_train = train['Survived']
model = CatBoostClassifier(silent=True)
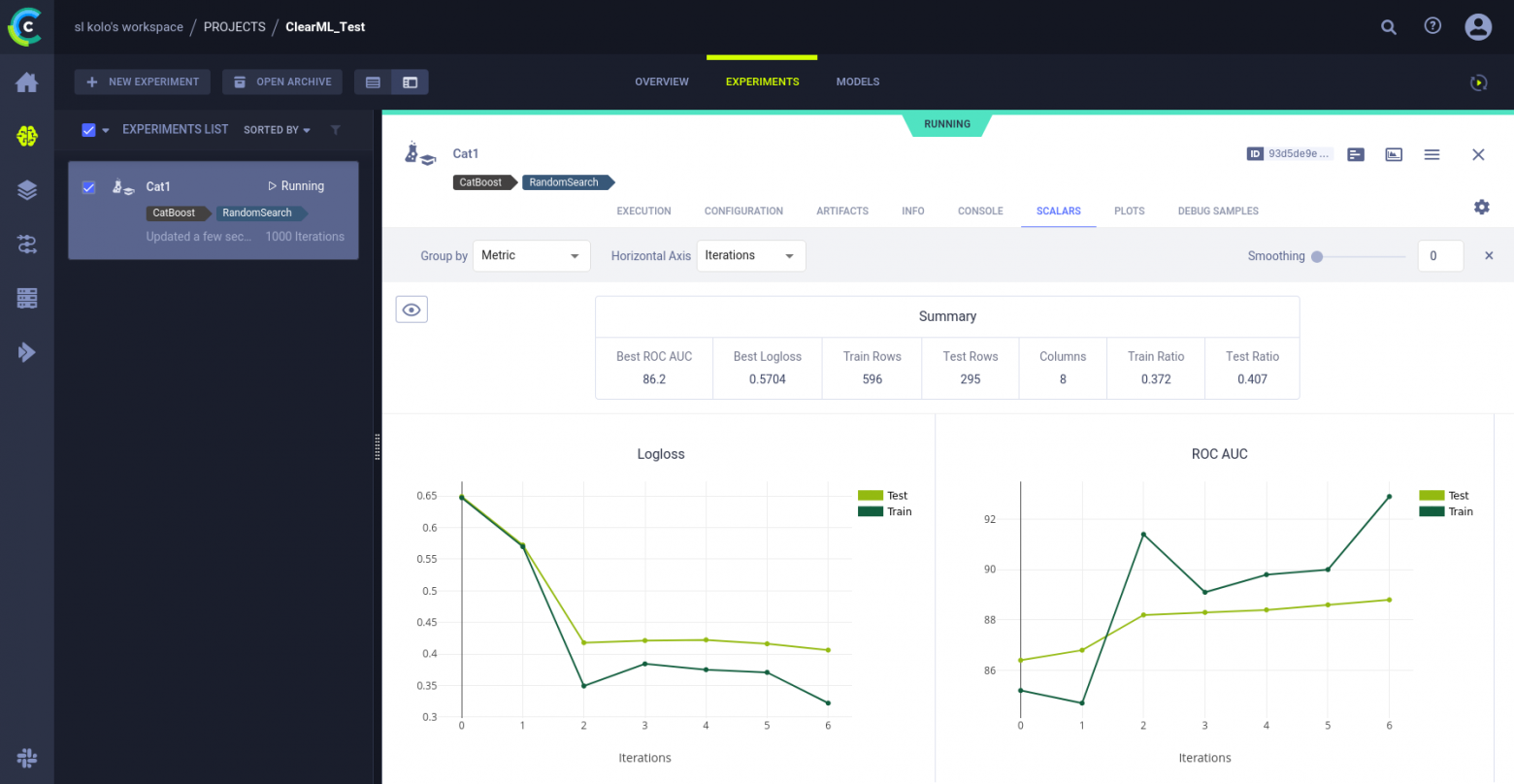
model.fit(X_train, y_train, cat_features=['Sex','Cabin','Embarked']);ClaerML автоматически логирует выводы некоторых популярных библиотек и CatBoost среди них. После выполнения этого кода на вкладк Scalars вы сможете увидеть кривую обучения CatBoost«а.

Логируемые библиотеки можно посмотреть здесь:
https://github.com/allegroai/clearml/tree/master/examples/frameworks
# Сетка для перебора гиперпараметров
param_grid = {
'depth': [4,5,6,7,8],
'learning_rate': [0.1,0.05,0.01,0.005,0.001],
'iterations': [30,50,100,150]
}
# Формируем датасет для тестирования
X_test = test.drop(columns=['Survived'])
y_test = test['Survived']
# Инциируем объект логирования
log = Logger.current_logger()
# Переменные для хранения результатов
best_score = 0
best_model = None
i = 0
# Перебираем случайные 50 гиперпараметров
for param in ParameterSampler(param_grid, n_iter=50, random_state=42):
# Обучаем модель
model = CatBoostClassifier(**param, silent=True)
model.fit(X_train, y_train, cat_features=['Sex','Cabin','Embarked'])
# Оцениваем модель
test_scores = model.eval_metrics(
data=Pool(X_test, y_test, cat_features=['Sex','Cabin','Embarked']),
metrics=['Logloss','AUC'])
test_logloss = round(test_scores['Logloss'][-1], 4)
test_roc_auc = round(test_scores['AUC'][-1]*100, 1)
train_scores = model.eval_metrics(
data=Pool(X_train, y_train, cat_features=['Sex','Cabin','Embarked']),
metrics=['Logloss','AUC'])
train_logloss = round(train_scores['Logloss'][-1], 4)
train_roc_auc = round(train_scores['AUC'][-1]*100, 1)
# Сравниваем текущий скор с лучшим
if test_roc_auc > best_score:
# Сохраняем модель
best_score = test_roc_auc
best_model = model
# Записываем метрики в ClearML
log.report_scalar("Logloss", "Test", iteration=i, value=test_logloss)
log.report_scalar("Logloss", "Train", iteration=i, value=train_logloss)
log.report_scalar("ROC AUC", "Test", iteration=i, value=test_roc_auc)
log.report_scalar("ROC AUC", "Train", iteration=i, value=train_roc_auc)
i+=1Здесь мы делаем следующее:
Определяем сетку для перебора гиперпараметров.
Случайным образом отбираем 50 возможных значений гиперпараметров.
Обучаем модель.
Считаем метрики.
Если метрика показала лучший скор из всех предыдущих, то:
До кучи сохраним еще несколько параметров в виде констант:
log.report_single_value(name='Best ROC AUC', value=test_roc_auc)
log.report_single_value(name='Best Logloss', value=test_logloss)
log.report_single_value(name='Train Rows', value=X_train.shape[0])
log.report_single_value(name='Test Rows', value=X_test.shape[0])
log.report_single_value(name='Columns', value=X_train.shape[1])
log.report_single_value(name='Train Ratio', value=round(y_train.mean(),3))
log.report_single_value(name='Test Ratio', value=round(y_test.mean(),3))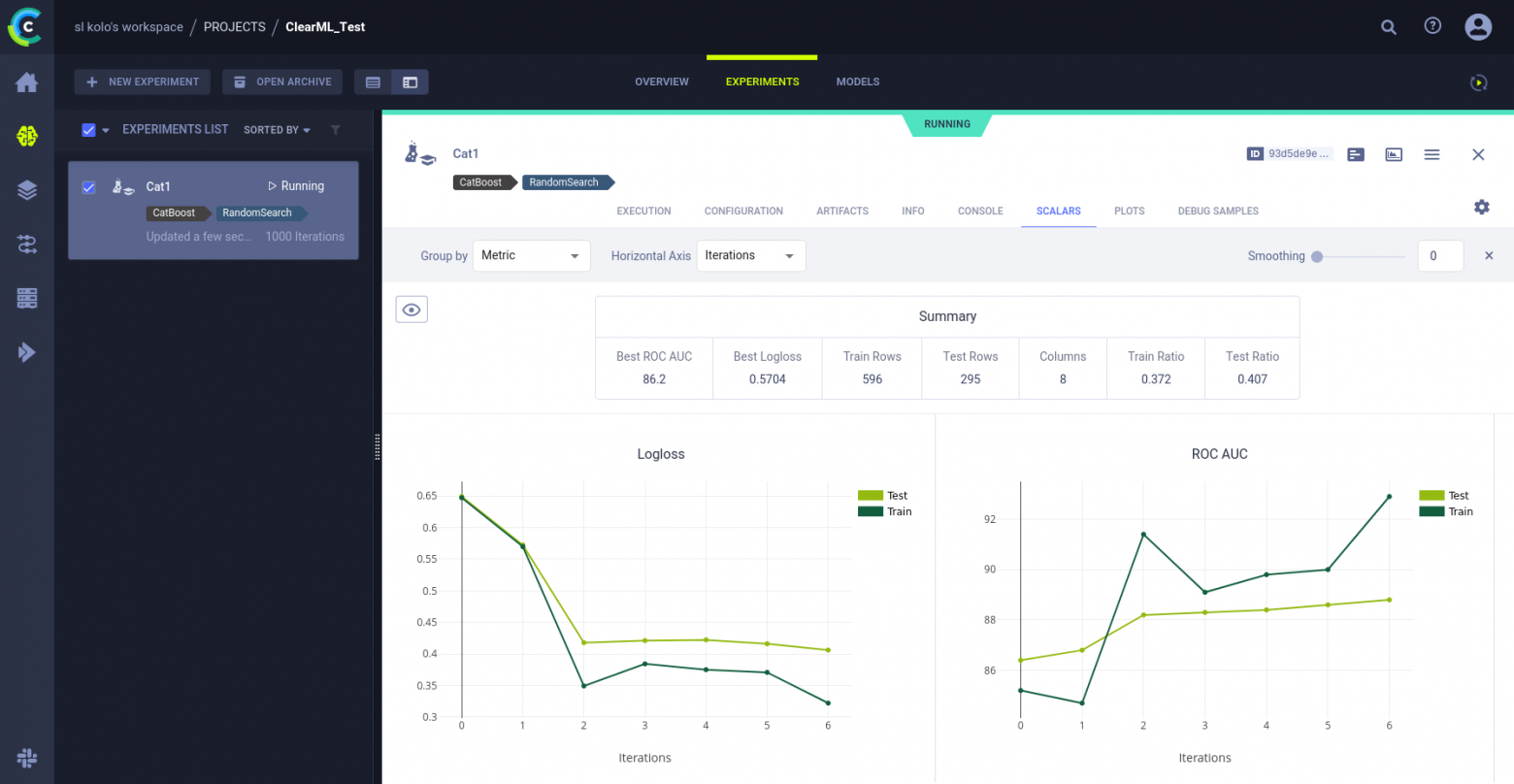
В ClearML реализовано множество различных видов отчетов:
https://clear.ml/docs/latest/docs/references/sdk/logger/
https://github.com/allegroai/clearml/tree/master/examples/reporting
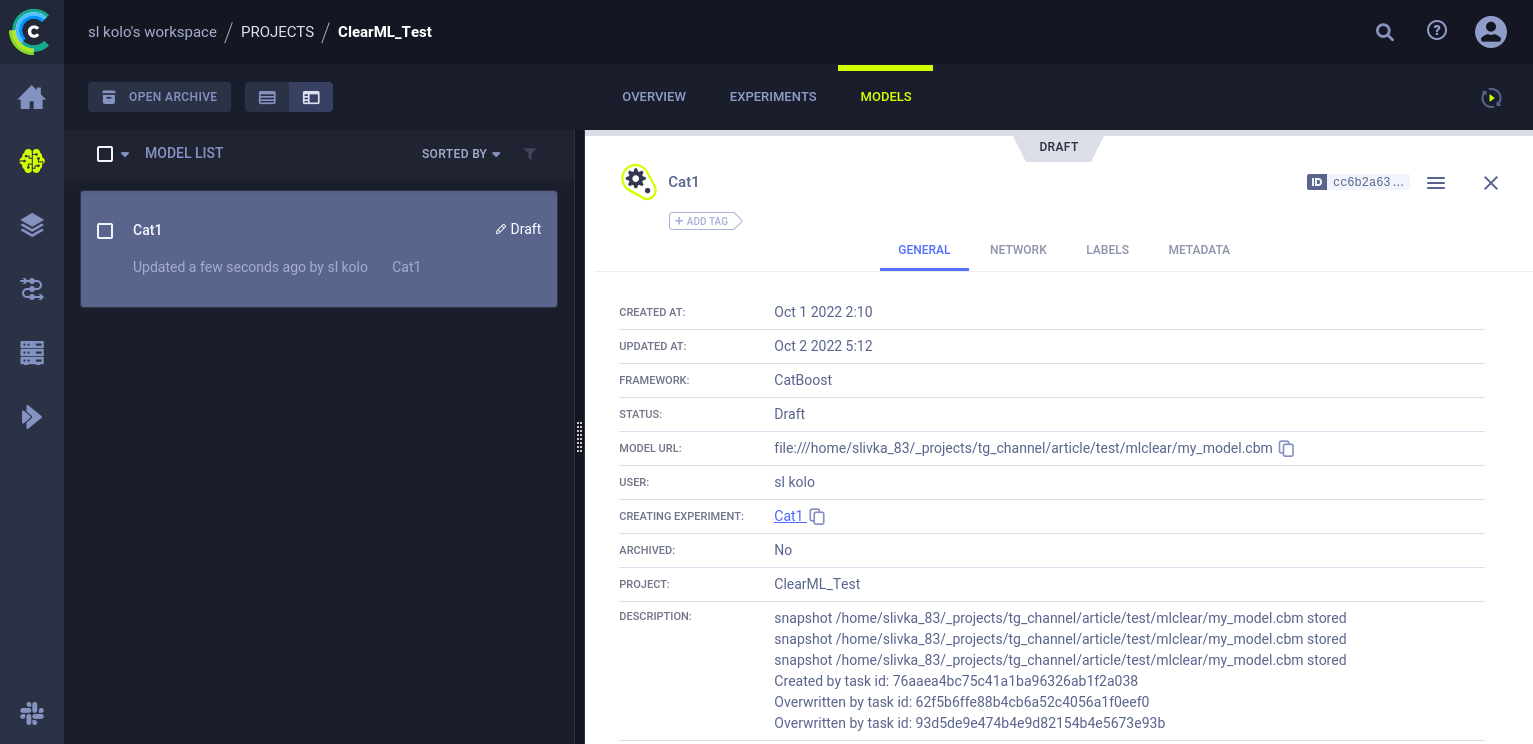
best_model.save_model('my_model.cbm')Технически мы просто сохранили модель локально, но ClearML опять автоматически это отследил и сохранил ее на сервере. Увидеть ее вы можете на отдельной вкладке Models в вашем Проекте. В рамках одного проекта вы проводите кучу экспериментов и у каждого из них (в теории) на выходе — модель. И все эти модели собраны в одном месте в рамках Проекта.
Вы также можете сохранять модели вручную:
https://clear.ml/docs/latest/docs/clearml_sdk/task_sdk/#logging-models-manually
task.close()Со списом всех экспериментов вы можете ознакомится в папке Проекта. Выводимые колонки настраиваются. Например, вы можете вывести туда свою метрику.
Локальное развертывание
Для лакального развертывания сервера ClearML вам нужно скачать готовый докер-образ и запустить его у себе. Инструкция как это сделать для вашей системы:
https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server
А теперь мельком посмотрим на некоторые другие интересные возможности ClearML, подробное рассмотрение которых выходит за рамки данного туториала…
REST API
Предположим, что у вас есть кластер, в который сложно установить дополнительные Python-пакеты (например, clearml). Тогда вы сможете общаться с сервером ClearML посредством REST API. Подробная документация: https://clear.ml/docs/latest/docs/references/api/index/
Сравнение экспериментов
Вы можете наглядно сравнить два (или более) эксперимента. Для этого выделите их в списке экспериментов и нажмите Compare внизу экрана. Для сравнения доступна как текстовая информация так и графики.

Более подробно
Воспроизведение эксперимента
Если по каким-либо причинам вам необходимо повторить ранее проведенный эксперимент, то это можно сделать в пару кликов прямо из интерфейса ClearML.
Оркестрация
В ClearML вы можете строить паплайны обработки данных (как в Airflow, Dagster или Prefect).
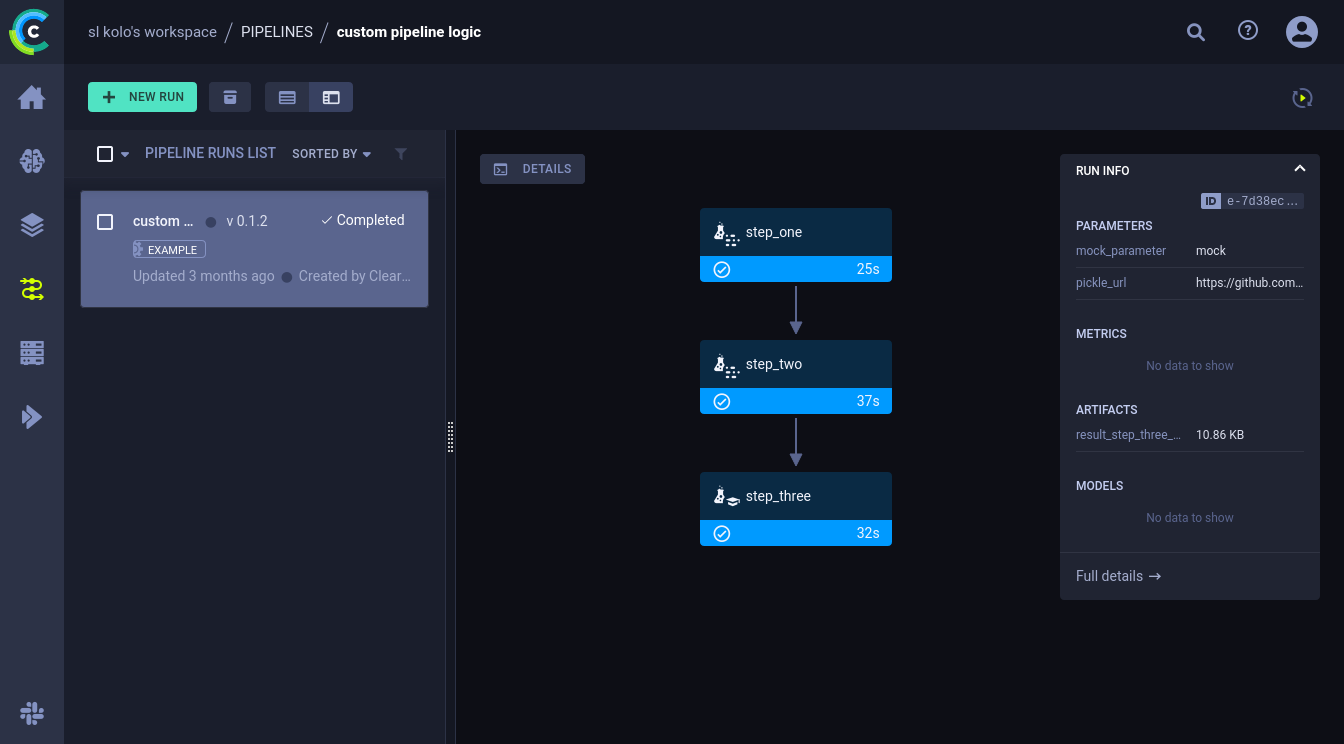
Подробнее: https://clear.ml/docs/latest/docs/pipelines/pipelines
Датасеты
ClearML имеет отдельное хранилище для датасетов. Например у вас имеется какой-то общий бенчмарк и нужно не просто подтянуть его в отдельный проект, а предоставить его всей команде.
Возможности хранилища:
Отслеживание версий.
Вы можете хранить файлы в облачном хранилище или локальной сети.
Датасеты могут иметь наследование от других датасетов и собираться по цепочке в пайпаланы.
Вы всегда можете получить локальную копию датасета.
Небольшой пример создания датасета:
from clearml import Dataset
dataset = Dataset.create(
dataset_name="cifar_dataset",
dataset_project="dataset examples"
)
dataset.add_files(path='cifar-10-python.tar.gz')
Более подробно:
https://clear.ml/docs/latest/docs/clearml_data/clearml_data
https://clear.ml/docs/latest/docs/guides/datasets/data_man_python
Что дальше?
Это далеко не все возможности ClearML. С другими вы сможете ознакомится в документации.
Также в стандартной установке имеется много примеров использования ClearML. Можете изучить их на досуге. Найти их вы сможете в Projects/ClearML examples.

Еще вы можете посмотреть:
Мой телеграм-канал
