Чем Fault Tolerant серверы отличаются от «бытового» ширпотреба на конкретном примере

«Зеркальный» кластер с синхронными вычислительными процессами, вид спереди
Пока тут весь интернет кричит про наш отечественный жёсткий диск на целых 50 Мегабайт массой 25 килограмм, не очень-то понимая, что эта штука может пережить две ядерных войны на дне бассейна, расскажу про серьёзные отказоустойчивые серверы и их отличия от обычного железа. К счастью, к нам как раз поступили на тестирование такие, и была возможность хорошенько над ними поиздеваться.
Эти решения особенно интересны для админов. Дело в том, что они защищены не физически — кожухами, отказоустойчивыми интерфейсами или чем-то ещё, а на уровне именно архитектуры вычислений.
Нам в руки попал флагман ftServer 6800 от Stratus. Это корпус с двумя идентичными вычислительными узлами, объединёнными в один кластер, причем обе его половинки работают синхронно и делают одно и то же «зеркально». Это старая добрая «космическая» архитектура, когда вычислительный процесс проходит сразу два независимых аппаратных пути. Если где-то возникнет баг (не связанный с кривостью кода), то один из результатов точно достигнет цели. Это важно для критичных систем в самых разных областях от банкинга до медицины, и это очень важно там, где есть «тихая потеря данных». То есть там, где во весь рост встают баги процессоров, связанные с тем, что кристаллы всё же уникальные и двух одинаковых машин не бывает в природе. Обычно это не проявляется, но на ответственных задачах требуется защититься от случайного влияния помех и возможных более явных проблем. Поэтому вот так и сделано.
Самое важное:
- Дублируются вычислительные процессы. Компоненты выглядят для ОС, как одно устройство. Failover проходит на уровне драйвера. Нет потерь на синхронизацию CPU, но есть overhead, связанный с репликацией HDD.
- Заявленная доступность 99,999 на Linux, Win и VMware. От девяток рябит в глазах, и поэтому мы взялись проверять это утверждение (насколько возможно).
Как это работает
Один из кластеров всегда будет ведущим (Primary), а другой ведомым (Secondary). Такой подход к построению обусловлен высокими требованиями к отказоустойчивости (99,999), технология гордо зовется DMR (Dual Modular Redundancy). Оба узла кластера синхронно выполняют операции и при потере одного из узлов будет произведено моментальное переключение (failover) на оставшийся в работе.
Каждый из узлов разделен еще на два модуля (Enclosure):
- CPU Enclosure — модуль, включающий в себя CPU и RAM;
- IO Enclosure — модуль, отведенный под PCIe, RAID контроллер (с дисками) и встроенные NIC«и.
К разделению на два модуля инженеры Stratus пришли из-за различных походов к синхронизации содержащихся в них устройств:
- Для CPU Enclosure используется технология Lockstep (шаг в шаг). Она гарантирует, что компоненты этих двух модулей будут работать синхронно и находятся в одинаковых состояниях, а значит, аварийное переключение всегда пройдет успешно.
- Для IO Enclosure нельзя использовать Lockstep из-за наличия большого количества разнородных устройств. RAID-контроллеры из обеих половинок кластера реплицируются с помощью объединения дисков, расположенных в одинаковых слотах (в пары). NIC«и при использовании Windows (драйвер Intel PROset) работают в одном из режимов: AFT, ALB, SFT, и т.д., таким образом Primary узлу доступны порты Secondary ноды — в сумме целых 8 штук. Если же развернут Linux или ESXi, NIC«и cобираются в bonding, то есть происходит объединение портов в пары c общим MAC адресом (по аналогии с дисками). Для сторонних HBA при отказе Primary устройства произойдет переключение на исправное. USB, размещенные на самих половинках, синхронизации не подлежат. Данную проблему решают общие порты VGA, USB и COM, распаянные на пассивном бэкплейне. Они автоматически переключаться на активную половинку при аварии, а значит не придется переключать привычные монитор с мышкой и клавиатурой в порты нового Primary узла.
Для управления кластеризацией используется отдельный ASIC — Stratus Albireo, названный так в честь системы двойной звезды (романтика). Данный контроллер расположен в каждом из вычислительных узлов. Он ответственен за синхронизацию обоих узлов через пассивный бэкплейн, а также за обнаружение неисправностей.
Подключение между модулями вычислительных узлов организовано по схеме full mesh. Таким образом, мы получаем очень гибкую и отказоустойчивую систему: данная компоновка позволяет Primary узлу видеть резервные устройства и в случае чего, к примеру, ввести в работу IO enclosure Secondary узла.

Топология связей между компонентами узлов кластера.
Также Stratus Albireo следит за тем, чтобы потоки данных, получаемые с обоих узлов, были идентичными. При наличии расхождения система выявит причину и постарается устранить сбой. Если ошибка была устранена (тип ошибки correctable), то счетчик MTBF (Mean Time Between Failures) увеличится на 1, а если нет, то данный элемент будет выведен из строя (тип ошибки uncorrectable). Подсчет ошибок ведется для основных компонентов каждого из узлов кластера: CPU, RAM, HDD, IO устройств. За счет накопления статистики контроллер может проактивно сигнализировать о грядущей поломке того или иного компонента.
- Для работы ОС на таком нестандартном решении Stratus использует особые драйверы, разделенные на два класса:
- «Усиленные» драйверы, разработанные совместно с вендором. «Усиленными» они называются потому, что подвергаются ряду тестов на стабильность и совместимость.
- Дополнительный виртуальный драйвер, который заставляет ОС видеть пару устройств, разнесенных по двум вычислительным узлам, как одно устройство, за счет чего обеспечивается прозрачный failover.
Для управления кластером и первичной настройки ОС используется программный пакет Stratus Automated Uptime Layer (для каждой ОС он свой), причем он напрямую связан с Stratus Albireo (без него кластер корректно работать не будет). О типах данного софта и его возможностях мы расскажем далее.
Характеристики
Позиционируется ftServer 6800 как решение для баз данных и высоконагруженных приложений. Для тех, кому нужно что-то попроще, предусмотрено еще две модели: ftServer 2800 и ftServer 4800.
| Характеристика |
ftServer 2800 |
ftServer 4800 |
ftServer 6800 |
| Логический процессор (на узел кластера) |
1 сокет |
1 сокет |
2 сокета |
| Тип процессора |
Intel Xeon processor E5–2630v3, 2.4 GHz |
Intel Xeon processor E5–2670v3, 2.3 GHz |
Intel Xeon processor E5–2670v3, 2.3 GHz |
| Поддерживаемое количество оперативной памяти |
От 8 GB до 64 GB DDR4 |
От 16 GB до 256 GB DDR4 |
От 32 GB до 512 GB DDR4 До 1 ТB для VMware |
| Тип поддерживаемых дисков |
12 Gb/s SAS 2.5? |
12 Gb/s SAS 2.5? |
12 Gb/s SAS 2.5? |
| 10/100/1000 Ethernet порты (на узел кластера) |
2 |
2 |
2 |
| 10 Gb Ethernet порты (на узел кластера) |
Нет |
2 |
2 |
| Встроенные шины PCIe G3 (на узел кластера) |
2?4 PCIe |
2?4 PCIe |
2?4 PCIe 2?8 PCIe |
| Дополнительная PCIe шина (на узел кластера) |
Нет |
2?8 PCIe |
Нет |
В нашем кластере установлено: Intel Xeon processor E5–2670v3, 2.3 GHz (2 шт.), DDR4 32 Гб, 2133 МГц, 512 Гб, 400 Гб SSD (1 шт.), 300 Гб 15k HDD (2 шт.), 1.2 Тб 10k HDD (1 шт.), FC 16 Gb 1 порт.
Конфигурация отвечает соврменным требованиям производительности, причем доступна специальная версия для VMware, которая отличается увеличенным в два раза размером ОЗУ — 1 ТБ. Кто-то скажет, что сейчас стандартом для rack-серверов является 2–3 ТБ RAM, но нужно понимать, что FT кластер — это решение, заточенное в первую очередь под защиту определенной системы, механизм которой накладывает свои ограничения.
Вот вид сзади:

Отдельно про индикацию, она достаточно простая и понятная даже без инструкции:
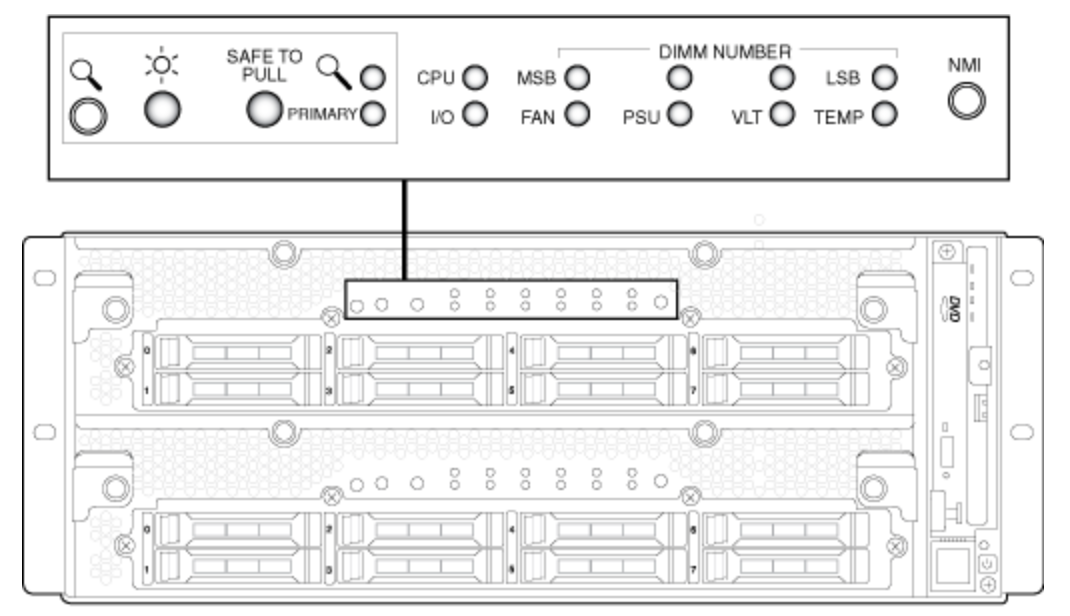
На передней панели расположены основные индикаторы, ответственные за ключевые элементы узлов.
Но заботить нас должны всего три:
- «Солнышко» — питание подключено, данный узел работает;
- Primary — говорит о том, какой из данных узлов кластера является ведущим;
- Safe to Pull — если она мигает, извлекать узел кластера нельзя, а если просто горит — смело вытаскиваем.
Индикация полностью видна только при снятой декоративной панели. Если же ее вернуть на место, то получаем информацию только об общем состоянии системы, а также о том, синхронизированы узлы кластера или нет.
Шасси — короб высотой 4U, который разделён на две основные секции (выделенные под узлы кластера) высотой по 2U каждая и одну дополнительную вертикальную секцию высотой 4U, в которой располагается расширитель менеджмент-модуля, подключающийся в QPI шину (справа на Рисунке 1 он отчётливо виден). С помощью него мы получаем привычный набор: DVD привод, USB порт (еще три расположены сзади), VGA, COM порт и даже модем, также на нем расположена кнопка включения и выключения сервера под колпачком, защищающем от случайного нажатия.
Изначально мы были уверены, что в расширителе находится сам менеджмент-модуль, но данная теория был развенчана эмпирическим методом: несмотря на извлечение расширителя из шасси, мы смогли успешно зайти на BMC (Baseboard management controller). Позже при изучении кластера оказалось, что BMC модули находятся в самих узлах кластера.
Извлечём один из узлов и рассмотрим его поближе. Сделать это просто так не получится, для этого нужно отсоединить кабель питания, который держит перекладину-рычаг (первый рубеж обороны от случайного отключения-извлечения) и открутить два болта спереди Примечательно, что из-за этой самой перекладины блок питания «на горячую» поменять не получится, нужно вытаскивать узел кластера полностью.

Извлечение узла кластера. Шаг 1.

Извлечение узла кластера. Шаг 2.
После данных манипуляций шасси позволит выдвинуть узел кластера только наполовину, для полного извлечения нам потребуется нажать на рычажок.

Извлечение узла кластера. Шаг 3.
После того, как мы заполучили сервер, приступим к осмотру того, что внутри.

Узел кластера.
По сборке самого узла нареканий нет. Сделано все качественно и без явных огрехов.
Размещение элементов и каблирование бэкплейна HDD и двух USB 3.0 (привет PC) лаконичны и не вызывают какого-то негатива. Стоит так же обратить внимание на толщину металла корпуса: тут она толстая, как у тех самых серверов Compaq’a. Основные элементы корпуса притянуты винтами с шайбой-гровером, а значит, вряд ли раскрутятся от вибрации. Инженеры Stratus’а явно хотели показать, что кластер рассчитан на высокие вычислительные и физические нагрузки.
Не можем не отметить интересную находку, а именно значительное количество логотипов компании NEC внутри совсем не NEC«овского сервера. И действительно, там они неспроста. Как нам удалось узнать, у компании Stratus заключен контракт с NEC на производство серверов, а NEC покупает у Stratus«a софт (OEM). Поэтому если зайти на сайт NEC«a, можно поймать нехилое дежавю. По заверениям самого Stratus«а, только при покупке серверного оборудования у них вы получаете самое последнее ПО, что вполне логично.
Управление отказоустойчивым кластером
Перейдём к софту, а именно к менеджмент-интерфейсу BMC (у Stratus’a он носит гордое название Virtual Technician Module). Выглядит он простовато:


Интерфейс VTM
С другой стороны, весь основной функционал присутствует: можем и доступ к KVM получить, и ISO примонтировать, и даже статус основных компонентов узнать.
Интересно сделана нижняя часть менеджмент-консоли, она отображает статус обоих узлов кластера, коды BIOS«a (в момент загрузки), количество пользователей, залогиненных на каждый из VTM«ов, роль узлов в кластере, а также статус Safe to Pull.

Забавно, что если зайти на Secondary узел кластера, то из функционала пропадает графическая консоль, причем выключить кластер можно, а вот посмотреть, что творится на мониторе, нет.
Стоит добавить, что отключить отдельно один из узлов кластера или вывести из работы какие-то из его элементов с помощью VTM не получится. Для этого нужно, в случае vSphere, развернуть на самом кластере appliance (виртуальная машина ftSys), а при использовании Windows или Linux установить программный пакет. Причем для Windows программный модуль представляет собой приложение с GUI (ftSMC), а для Linux работает только в режиме командной строки и практически полностью дублирует функционал appliance для vSphere. Важно заметить, что установка данных программных пакетов (модуль для ОС, appliance) обязательна, так как они ответственны еще и за первичную конфигурацию ОС или гипервизора для работы на железе кластера, а также отработку failover«a. То есть если вы данные модули не установите и не настроите, в нужный момент кластер просто не отработает экстренное переключение.
Нам была интересна связка Stratus FT и vSphere, поэтому дальше речь пойдет именно об appliance«е. Сам ftSys состоит из двух частей: web-интерфейса, из которого можно отслеживать статус всего кластера и любого из его компонентов, а также командной строки, позволяющей управлять кластером.
Главная страница ftSys: 
Web-консоль ftSys предоставляет доступ к просмотру настроек и статуса удаленного мониторинга (Stratus ActiveService Network, ASN), VTM, виртуальных коммутаторов, состоянию дисковой подсистемы и логам System Management (в них содержатся логи failover«a и дальнейшей синхронизации).
Проверим состояние компонентов кластера:

Раскроем CPU Enclosure 0:

Компоненты кластера могу находится в одном из состояний:
- ONLINE — компонент синхронизирован и находится в работе (относится к CPU и RAM).
- DUPLEX — компонент синхронизирован и находится в отказоустойчивом режиме.
- SIMPLEX — компонент кластера не синхронизирован, либо проходит диагностику.
- BROKEN — компонент неисправен и не прошел диагностику. Важно заметить, что случае сетевых карт BROKEN говорит о том, что сетевой кабель не подключен.
- SHOT — компонент узла диагностирован как неисправный и был электрически изолирован системой.
Раз уж мы заговорили про CPU Enclosure 0, объясним почему именно 0, а не какая-то другая цифра. В системе наименований Stratus«a у каждого компонента есть путь, причем для тех, что находятся в первом узле, в начале пути всегда будет 0, а для тех, что во втором — 1. Сделано это для удобства работы с кластером. К примеру, для просмотра информации о самом компоненте через консоль:

Для разграничения CPU и IO Enclosure у последнего добавлена цифра 1 в начале, поэтому у IO модуля из первого узла путь будет 10, а для этого же модуля из второго узла — 11.
Подключение по SSH к ftSys позволяет производить диагностику сервера, в том числе собирать логи, просматривать детализированные отчеты по компонентам, а также отключать компоненты и модули целиком.
Поддержка и гарантия
Рассмотрим поддержку кластера с описанием заменяемых компонентов. Элементы разделены в группы CRU (Customer Replaceable Unit):
| CRU |
|
| Декоративная панель |
Расширитель менеджмент модуля |
| Вычислительный узел |
PCIe адаптер |
| Память |
PCIe райзер |
| DVD драйв |
PDU |
| HDD |
Бэкплейн |
Это значит, что если у вас вышел из строя CPU или модуль охлаждения, то вам в сборе придёт узел кластера, в который нужно будет переставить все остальные элементы (DIMM, HBA и PCIe райзер) из списка выше.
Сам кластер покрывается одной из четырёх программ поддержки (FtService): Total Assurance, System Assurance, Extended Platform Support и Platform Support. Таблица с основными показателями:
| FtService |
Total Assurance |
System Assurance |
Extended Platform Support |
Platform Support |
| Отправка запчасти заказчику |
NBD (Next Business Day) |
NBD (Next Business Day) |
NBD (Next Business Day) |
NBD (Next Business Day) |
| Время ответа на обращение при уровне Critical |
< 30 минут 24/7/365 |
< 60 минут 24/7/365 |
< 2 часов 24/7/365 |
< 2 часов 9/5/365 |
| Время реагирования на первое обращение |
24/7/365 |
24/7/365 |
24/7/365 |
24/7/365 |
| Проактивный мониторинг (ASN) |
24/7/365 |
24/7/365 |
24/7/365 |
24/7/365 |
| Доступ к инженеру, отвечающему за доступность |
24/7/365 |
24/7/365 |
Нет |
Нет |
| Поиск причины проблемы на уровне софта |
Да |
Да |
Нет |
Нет |
| Определение основной причины проблемы |
Да |
Да |
Нет |
Нет |
| Выезд на сайт |
Да |
Да |
Нет |
Нет |
| Присуждение заявке высокого приоритета |
Да |
Да |
Нет |
Нет |
| Полная поддержка ОС, включая патчи и апдейты |
Да |
Нет |
Нет |
Нет |
| Совместная работа с вендором |
Да |
Нет |
Нет |
Нет |
| Гарантия работы без простоя |
Да |
Нет |
Нет |
Нет |
Стандартная гарантия для кластера — 1 год Platform Support, который предполагает только отправку запчастей с анализом причины проблемы исключительно из логов самого кластера. Это значит, что если причина кроется где-то в ОС, то помогать вам не будут. Придется либо повышать уровень поддержки, либо соглашаться на платную помощь.
Определенные трудности могут возникнуть и при желании обновить или переустановить софт для кластера — в свободном доступе его нет. Нужно запрашивать у вендора или довольствоваться тем, что пришло вместе с самим оборудованием на диске.
Совсем иначе обстоят дела с документацией — она подробная и хорошо написана. Находится в свободном доступе как в виде электронного журнала, так и в виде pdf.
Хотя в России компания Stratus и не на слуху, но при этом достаточно распространена в определённых сферах, к примеру, в нефтегазовой. У компании есть свой склад запчастей, расположенный в Москве, в котором своего часа ждут подготовленные к отправке CRU. Конечно, в случае с нашей необъятной страной потребуется некоторое время на доставку деталей (особенно если проживаете вы во Владивостоке), но это все же лучше, чем если бы запчасти шли из Европы.
Ура, тесты!
Кластер Stratus был подключен по SAN (FC 8 Gb) к СХД (Hitachi AMS 2300). После чего на кластере мы развернули виртуальную машину на VMware ESXi 6 Update 1b под управлением OS Windows 2012 R2 и установили базу данных Oracle DB 12c.

Тестовый стенд
Тестирование проводилось в два этапа:
- Оценка failover«a и failback«а при высокой утилизации вычислительных ресурсов. Характеристики используемой виртуальной машины: 40 vCPU, 500 GB vRAM.
- Cравнение Stratus FT с VMware FT. Характеристики используемой виртуальной машины: 4 vCPU, 16 GB vRAM.
Отличия в характеристиках ВМ для 1-го и 2-го этапов связано с ограничением VMware FT в 4 vCPU.
Для тестирования нами был использован набор бенчмарков Swingbench. Из списка доступных тестов был выбран Sales History. Данный тест создаёт собственную БД (выбранный размер — 8 ГБ) и позволяет генерировать запросы (заведомо заданные) к ней с определенной частотой.
Запросы представляют собой разного вида выгрузки, такие как отчеты по продажам за месяц, неделю и т.д. Настройки бенчмарка (описаны внесённые в готовую модель изменения):
- Number of Users: 450 (вместо стандартных 16). Количество пользователей увеличено для полноценной (близкой к 95% в пике) нагрузки на ВМ.
- Продолжительность теста: 1,5 часа. Достаточное время для проверки надежности платформы в целом, а также выхода на нормальное среднее значение показателей производительности.
Для исследования нами была выбрана следующая методика:
1. Запуск тестов. Оценка производительности кластера, определение средних значений (спустя 15 минут работы):
- Transactions-per-Minute (TPM, количество транзакций в минуту);
- Transactions-per-Second (TPS, количество транзакций в секунду);
- Response Time (RT, время обработки db query).
2. Отключение Primary узла кластера;
3. Введение узла кластера в работу (спустя 30 минут после отключения);
4. Ожидание полной синхронизации обоих узлов и получения статуса DUPLEX для всех компонентов.
Этап I. Оценка failover«a и синхронизации при высокой утилизации вычислительных ресурсов.
1. Средние показатели производительности:
- Transactions-per-Minute, TPM: 542;
- Transactions-per-Second, TPS: 9;
- Response Time (время обработки db query): 29335 мс.
2. Отключение Primary узла кластера:
06/06–07:57:10.101 INF t25 CpuBoard[0] DUPLEX/SECONDARY → SIMPLEX/PRIMARY
Данная строка в логах ftSys — маркер извлечения узла. После чего был потерян один ICMP Echo Request (Рисунок 17) до виртуальной машины, а затем кластер продолжил работу в нормальном режиме.

Результаты извлечения Primary узла кластера Влияния на дисковую подсистему замечено не было, средние задержки на чтение остались в пределах эталонных


Результаты извлечения Primary узла кластера
3. Введение узла кластера в работу:
Выдержка из логов ftSys:
06/06–08:25:32.061 INF t102 CIM Indication received for: ftmod 16 41
06/06–08:25:32.065 INF t102 Ftmod — indicationArrived. Index=125, OSM index=124
06/06–08:25:32.142 INF t102 Fosil event on bmc[10/120]
06/06–08:25:32.145 INF t25 Bmc[10/120] SIMPLEX/PRIMARY → DUPLEX/PRIMARY
Отметим, что новый узел кластера (под замену) приходит без прошивок и при инициализации в шасси на него заливаются микрокоды и конфигурация с оставшегося в работе.
4. Ожидание полной синхронизации обоих узлов и получения статуса DUPLEX для всех компонентов:
В течение 20 минут после введения узла кластера в работу производится диагностика и синхронизация оборудования в следующем порядке (с наслоением, т.е. может происходить ряд параллельных операций):
i. BMC (VTM);
ii. IO Slots (PCIe);
iii. HDD и SSD;
iv. RAM и CPU.
i. BMC (VTM). Синхронизация BMC в нашем случае проходила чуть быстрее, так как прошивки и конфигурация уже находились на извлеченном узле.
Выдержка из логов ftSys:
06/06–08:25:32.145 INF t25 Bmc[10/120] SIMPLEX/PRIMARY → DUPLEX/PRIMARY
06/06–08:26:44.107 INF t25 Bmc[11/120] EMPTY/NONE → DUPLEX/SECONDAR
06/06–08:26:44.259 INF t25 BMC flags, Needed=00, Changed=00
06/06–08:26:44.259 INF t25 Check if can proceed with checking for CFG conflict, saveRestoreCompleted: true
Из логов видно, что сначала в DUPLEX перешел тот VTM, который после failover«a стал PRIMARY и только через минуту этот же статус получил SECONDARY VTM.
ii. IO Slots (PCIe). Во время синхронизации PCIe сначала происходит определение типа райзера (Make) и только потом идет поочередное считывание каждого из IO слотов.
Выдержка из логов ftSys:
06/06–08:27:47.119 INF t25 Make Riser for IoBoard[11]: 2x PCI-E2(x8)
06/06–08:27:47.122 INF t25 Make IoSlots for IoBoard[11]
06/06–08:27:47.238 INF t25 IoSlot[11/1] UNKNOWN/NONE → EMPTY/NONE
06/06–08:27:47.239 INF t25 IoSlot[11/1] removing PCI, was 0000:43:00
06/06–08:27:47.245 INF t25 IoSlot[11/2] UNKNOWN/NONE → EMPTY/NONE
06/06–08:27:47.245 INF t25 IoSlot[11/2] removing PCI, was 0000:55:00
06/06–08:27:47.252 INF t25 IoSlot[11/3] UNKNOWN/NONE → INITIALIZING/NONE
06/06–08:27:47.256 INF t25 IoSlot[11/4] UNKNOWN/NONE → EMPTY/NONE
06/06–08:27:47.256 INF t25 IoSlot[11/4] removing PCI, was 0000: c7:00
06/06–08:27:47.262 INF t25 IoSlot[11/5] UNKNOWN/NONE → INITIALIZING/NONE
Причем первыми поднимаются NIC«и и происходит добавление их в ESXi:
06/06–08:27:48.705 INF t191 NetworkIfc (vmnic_110601) UNKNOWN/NONE → ONLINE/NONE
06/06–08:27:48.709 INF t191 NetworkIfc (vmnic_110600) UNKNOWN/NONE → ONLINE/NONE
06/06–08:27:48.712 INF t191 BondedIfc (vSwitch0) connecting slave vmnic_110600
06/06–08:27:48.716 INF t191 BondedIfc (vSwitch0.Management_Network) connecting slave vmnic_110600
В этот момент незначительно возрастает время ответа при ICMP Echo запросе: 
Синхронизация узлов. Добавление NIC.
iii. HDD и SSD. После того как NIC«и подняты, начинается считывание данных о дисках и последующая их синхронизация:
06/06–08:28:31.432 NOT t12 Storage Plugin: INFORMATION — 11/40/1 is now STATE_ONLINE / REASON_NONE
06/06–08:28:31.433 INF t12 Auto bringup Disk[11/40/1] based on MTBF
06/06–08:28:31.963 NOT t12 Storage Plugin: non-blank disk 11/40/1 discovered (safe mode)
06/06–08:28:31.964 INF t13 Storage: query superblock: vmhba1: C0: T1: L0
06/06–08:28:31.964 NOT t12 Storage Plugin: INFORMATION — 11/40/2 is now STATE_ONLINE / REASON_NONE
06/06–08:28:31.965 INF t12 Auto bringup Disk[11/40/2] based on MTBF
06/06–08:28:32.488 NOT t12 Storage Plugin: non-blank disk 11/40/2 discovered (safe mode)
06/06–08:28:32.488 NOT t12 Storage Plugin: INFORMATION — 11/40/3 is now STATE_ONLINE / REASON_NONE
06/06–08:28:32.489 INF t12 Auto bringup Disk[11/40/3] based on MTBF
06/06–08:28:32.964 NOT t12 Storage Plugin: non-blank disk 11/40/3 discovered (safe mode)
06/06–08:28:32.964 NOT t12 Storage Plugin: INFORMATION — 11/40/4 is now STATE_ONLINE / REASON_NONE
06/06–08:28:32.965 INF t12 Auto bringup Disk[11/40/4] based on MTBF
Далее ftSys определяет загрузочный диск и приступает к его синхронизации:
06/06–08:28:40.360 INF t102 == 11/40/1 is a boot disk
06/06–08:28:40.360 INF t102 CIM Indication received for: FTSYS_Storage
06/06–08:28:40.367 NOT t12 Storage Plugin: INFORMATION — 11/40/1 is now STATE_SYNCING / REASON_NONE
Последними поднимаются RAID контроллер (10/5, 11/5) и FC HBA (10/3, 11/3) для обоих узлов:
06/06–08:30:47.421 INF t25 IoSlot[11/3] ONLINE/NONE → DUPLEX/NONE
06/06–08:30:47.426 INF t25 IoSlot[11/5] ONLINE/NONE → DUPLEX/NONE
06/06–08:30:56.144 INF t25 IoSlot[10/5] SIMPLEX/NONE → DUPLEX/NONE
06/06–08:30:56.151 INF t25 IoSlot[10/3] SIMPLEX/NONE → DUPLEX/NONE
iv. RAM и CPU. Включение CPU Enclosure замыкает синхронизацию узлов кластера:
06/06–08:28:46.409 INF t25 CpuBoard[1] REMOVED_FROM_SERVICE/OK_FOR_BRINGUP → DIAGNOSTICS/NONE
Через 2 минуты произошел переход CPU из статуса DIAGNOSTICS в статус INITIALIZING и началось считывание прошивок из вышедшего из строя узла кластера:
06/06–08:31:21.105 INF t102 Fosil event on cpu[1]
06/06–08:31:21.105 INF t25 CpuBoard[1] DIAGNOSTICS/NONE → INITIALIZING/NONE
06/06–08:31:26.105 INF t25 Read IDPROM/board data for CpuBoard[1]
06/06–08:32:02.048 INF t102 CIM Indication received for: ftmod
06/06–08:32:02.053 INF t102 Ftmod — indicationArrived. Index=153, OSM index=152
06/06–08:32:02.112 INF t102 Fosil event on cpu[1]
Во время синхронизации RAM и CPU производительность упала до 20% или 125 TPM, причем на участке с 8:31:50 до 8:32:15 (25 секунд) TPS равнялось нулю.
Стоит также обратить внимание на Response Time, в данный отрезок времени его показатель достиг абсолютного максимума в 313686 мс и длился 3 с.
Синхронизация закончилась 08:37:29.351, хотя согласно графику ниже, просадка завершилась в 08:33:35.
06/06–08:32:04.280 INF t25 CpuBoard[1] INITIALIZING/NONE → DUPLEX/SECONDARY
06/06–08:34:29.351 INF t25 Bringup Complete event, restoring bringup policy.
06/06–08:37:29.351 INF t25 BringupPolicy: enableCPU bringup
Можно сделать вывод, что синхронизация узлов кластера после failover«a не сильно влияет на производительность кластера до момента синхронизации CPU и RAM, последняя же просаживает основные показатели кластера. Важно учитывать, что в данном случае процессоры были утилизированы на 75% и RAM на 52%.

Инициализация CPU Enclosure. Влияние на производительность
Этап II. Сравнение Stratus FT с VMware FT
Для проведения этапа II виртуальная машина из этапа I была клонирована на HA кластер из четырех блэйд-серверов Cisco UCS B200 M3 (CPU: Intel Xeon E5–2650, 2.0GHz; RAM: 128 GB DDR3) под управлением ESXi 6 Update 2. Серверы также были подключены по SAN (8 Gb) к СХД (Hitachi AMS 2300).
Средние показатели производительности без VMware FT (Сравнивать производительность VMware и Stratus (Этап I) не имеет смысла в силу ограничения на количество vCPU и типа самих CPU (отличаются семейством и тактовой частотой):
— Transactions-per-Minute, TPM: 190;
— Transactions-per-Second, TPS: 3;
— Response Time (время обработки db query): 2902 мс.
Перед тем как включить FT обозначим его основные особенности:
— Доступно максимум 4-е vCPU и 64 GB Ram на одну ВМ;
— На одном хосте может использоваться максимум 8 vCPU в режиме FT;
— Требуется выделенный 10 ГБ vNIC для синхронизации узлов кластера;
— Требуется общая СХД;
Синхронизация происходит на уровне виртуальных машин (Primary и Secondary), арбитром выступает vCenter.
Средние показатели производительности с VMware FT:
— Transactions-per-Minute, TPM: 160;
— Transactions-per-Second, TPS: 2;
— Response Time (время обработки db query): 3652 мс.
Можно сделать вывод, что мы теряем 16% общей производительности кластера, особенно существенно FT сказывается на Response Time.

Средние показатели производительности VMware

Средние показатели производительности VMware FT
Оценим влияние failover и восстановления FT кластера на производительность ВМ в случае VMware FT и Stratus ftServer.
VMware FT
При отработке failover«a происходит рост производительности ВМ с 160 до 190 TPM, так как в это время механизм репликации не работает.
После завершения переключения поднимается новая Secondary ВМ силами Storage vMotion и включается механизм, позволяющий машинам работать синхронно — vLockstep. Отметим, что после возвращения FT кластера в свое нормальное состояние показатель TPM просел до 140 и обратно к среднему значению в 160 так и не вернулся.
Среднее время на синхронизацию и переход от стояния «starting» к «protected» составляет в среднем 10 минут.
Stratus ftServer
Потери на синхронизацию составили 42% от исходной производительности или 143 TPM при среднем показателе в 241 (Рисунок 26). Как и в предыдущем случае в начальный момент репликации CPU Enclosure было замечено падение показателя TPS до 0.
Среднее время на синхронизацию и переход от состояния SIMPLEX к DUPLEX для компонентов обоих узлов кластера составляет в среднем 2 минуты.
Различия между решениями Stratus и VMware обусловлены тем, что Stratus ftServer изначально разрабатывался как FT кластер, поэтому мы не имеем существенных ограничений по CPU, памяти или нужды в общем хранилище (при использовании только внутренней дисковой подсистемы узлов). VMware FT представляет лишь дополнительную опцию, которая до 6-ой версии vSphere прибывала в изоляции за счет ограничения одним vCPU и была на рынке невостребована.
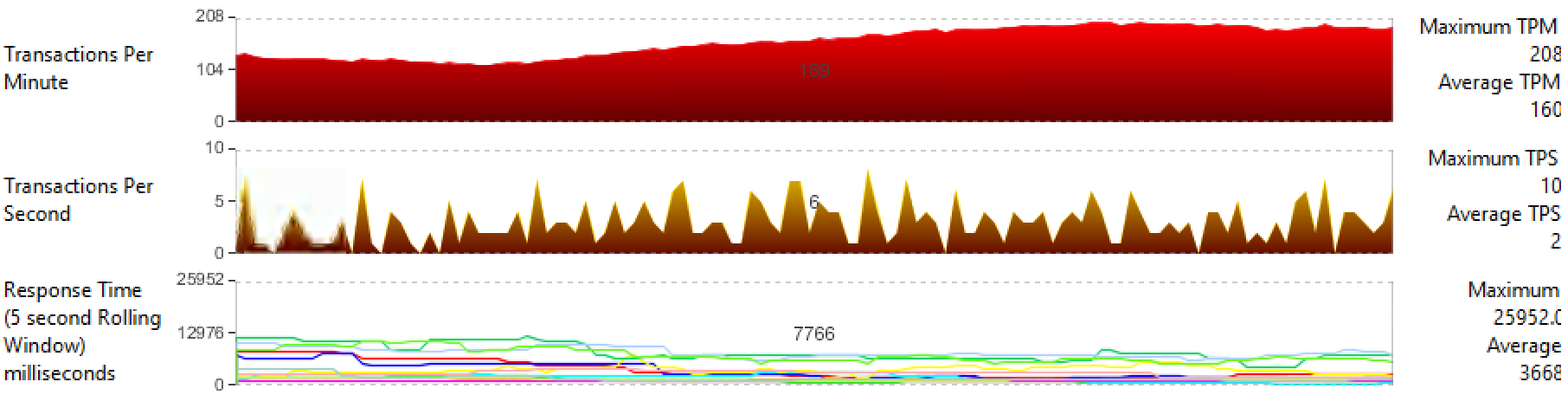
Vmware FT. Рост производительности в процессе failover

Vmware FT. Падение производительности после восстановления FT

Stratus ftServer. Производительность решения при failover и после завершения синхронизации узлов
Выводы
ftServer выделяется проработанной архитектурой, которая обеспечивает full-mesh соединение между модулями узлов кластера, что приводит к увеличению и без того высокого уровня защищенности от отказа какого-либо из компонентов. Решение не ограничено софтом, поддерживает последние версии Windows и Linux, а также виртуализацию vSphere и Hyper-V.
Отлично обстоят дела с документацией — подробная и хорошо написана. Кроме того, стоит отметить наличие русскоговорящей поддержки и склада в Москве, что гарантирует своевременную помощь.
Стоит отметить показательно малое время на синхронизацию (после замены узла) процессорных модулей (во время которого происходит существенное снижение производительности) и практически незаметную репликацию IO модулей.
Учитывая все вышесказанное, отметим, что у Stratus получилось отличное кластерное решение, а заявленная доступность 99,999 действительно имеет под собой прочное основание.
Где применяется
В мировой и российской практике такие системы используются:
- Для автоматизации непрерывных и дискретных производственных процессов и в системах учёта энергоресурсов (АСУТП/SCADA и АСКУЭ).
- Для MES — систем контроля и учета административно-хозяйственной деятельности предприятий.
- Естественно, в финансах. Это Processing/ERP, биржевые шлюзы. Как правило, это банковский процессинг либо Oracle.
- Как VoIP шлюзы, софтфоны, call-центры, биллинги, где минута простоя может означать с тысячу потерянных клиентов.
- Удаленные вычислительные узлы, труднодоступные для обслуживания, как правило без персонала — тот самый «космос».
Лицензия
Ещё один важный момент. Управление делается как одиночным сервером, лицензирование тоже как одиночного сервера (это очень важно для банковских лицензий на СУБД).
Ссылки:
- Документация вендора
- Архитектура
- Кейсы и применение
- Моя почта: GMogilev@croc.ru
Комментарии (1)
4 августа 2016 в 10:09 (комментарий был изменён)
0↑
↓
, а что делают с генератором случайных чисел в таких системах? При первой загрузке инициализируется какое-то определенное состояние?
