Чего «энтерпрайзу» в PostgreSQL не хватает
В конце прошлого года Иван Панченко предложил мне рассказать на внутреннем семинаре Postgres Pro, чего, по нашему опыту использования PostgreSQL в «кровавом энтерпрайзе» «Тензора», не хватает в этой СУБД.
С докладом пока так и не сложилось, зато появилась эта статья, в которой я постарался собрать наиболее показательные вещи и «хотелки», которые вызывают «напряги» при активном использовании PostgreSQL в реальном бизнесе.

Обслуживание сервера
Легковесный менеджер соединений
он же Built-in connection pooler
Сейчас каждое соединение с PostgreSQL инициирует создание на сервере полноценного дочернего процесса, который занимается его обслуживанием и выполнением запросов.
Процесс старта ресурсоемкий и небыстрый сам по себе, а постоянно существующий процесс еще и резервирует на себя некоторую долю RAM, которая со временем имеет свойство расти за счет «накачки» метаинформацией.
Просто представьте, что у вас в базе развернуто миллион таблиц, к которым вы достаточно случайно обращаетесь. Только на системных таблицах
pg_class,pg_depend,pg_statisticsэто даст объем порядка 1GB, который рано или поздно окажется в памяти процесса.
Поэтому в реальных условиях соединения непосредственно с БД стараются беречь, без нужды новые не создавать, а неактивные закрывать поскорее. Для этого «в разрыв» БЛ-БД ставят отдельный сервис connection pooler, который принимает от БЛ все «хотелки» по открытию/закрытию соединений и выполнению запросов, а в БД транслирует их в ограниченное количество длительно живущих коннектов.
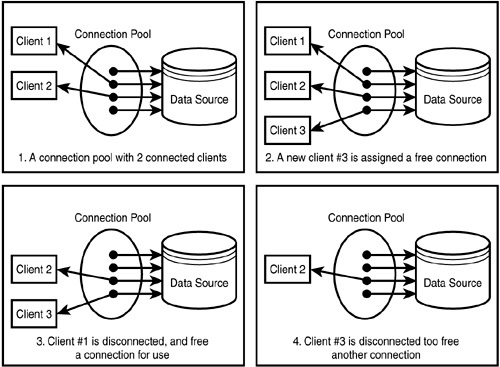 Пример работы connection pool
Пример работы connection poolКлассические представители:
Но, по-любому, это какой-то дополнительный элемент в и без него непростой архитектуре, который требует дополнительного присмотра и обслуживания, чего хотелось бы избежать.
Поэтому еще в начале 2018 года Константин Книжник начал эксперименты с реализацией менеджера соединений «из коробки» на основе интеграции потоков (thread model) в ядро PostgreSQL. В настоящий момент его патч включен на ревью в июльский Commitfest, так что ждем и надеемся на появление хотя бы в v15.
64-bit XID
Если вы пишете в базу много данных, как мы, то достаточно скоро у вас запустится он — autovacuum (to prevent wraparound), чья единственная задача — пробежать по данным и «поправить» их так, чтобы уберечь счетчик транзакций от переполнения.
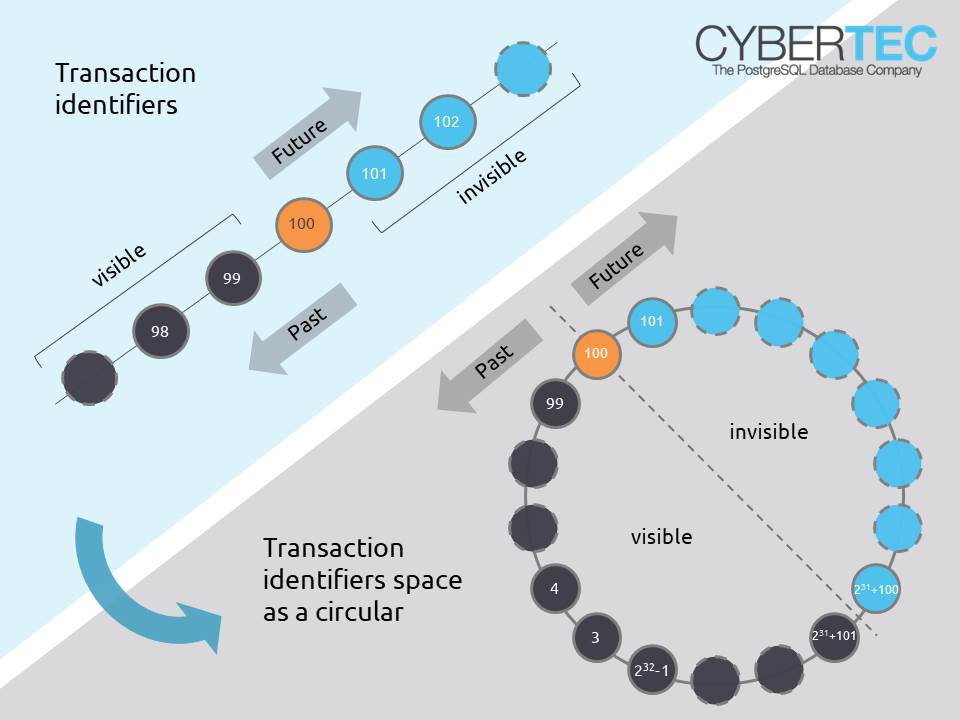 Одно из наглядных объяснений 32-bit transaction ID wraparound
Одно из наглядных объяснений 32-bit transaction ID wraparoundНо вот какой-то не особо необходимый с прикладной точки зрения процесс на сильно нагруженной (а иначе бы он у вас еще нескоро случился) системе, который будет активно читать-писать диск — это совсем не то, что хотелось бы видеть на базе «в рабочий полдень».
А чтобы никаких подобных процессов не запускалось, достаточно расширить идентификатор транзакции xid с 32 до 64 бит — соответствующий патч Александр Коротков запустил еще в 2017 году. В ядро он тогда так и не был включен, зато попал в Postgres ProEnterprise, откуда рано или поздно доберется и до «ванильного» ядра.
Система хранения данных
Микротаблицы
Каждая таблица и индекс в PostgreSQL с точки зрения хранения представляет из себя не меньше 3 файлов:
То есть если вам необходимо иметь небольшую статичную «словарную» табличку на пару десятков записей, то вы автоматически получаете 3 файла по 8KB, хотя можно было бы обойтись и единственной страницей heap.
Поэтому такая табличка, созданная в каждой из клиентских схем, где изолированы пользовательские данные, сразу дает резкое увеличение количества файлов на носителе (миллионы их!), что негативно влияет как на время бэкапа, так и на производительность всей дисковой подсистемы.
zheap
Если предыдущий патч устраняет необходимость в достаточно редкой операции, то использование хранилища zheap призвано помочь сэкономить ресурсы сервера на таблицах, в которых почти не бывает ROLLBACK — обычно это различные «логоподобные» вещи или агрегатные «срезы», где важно только текущее состояние, но UPDATE случаются постоянно.
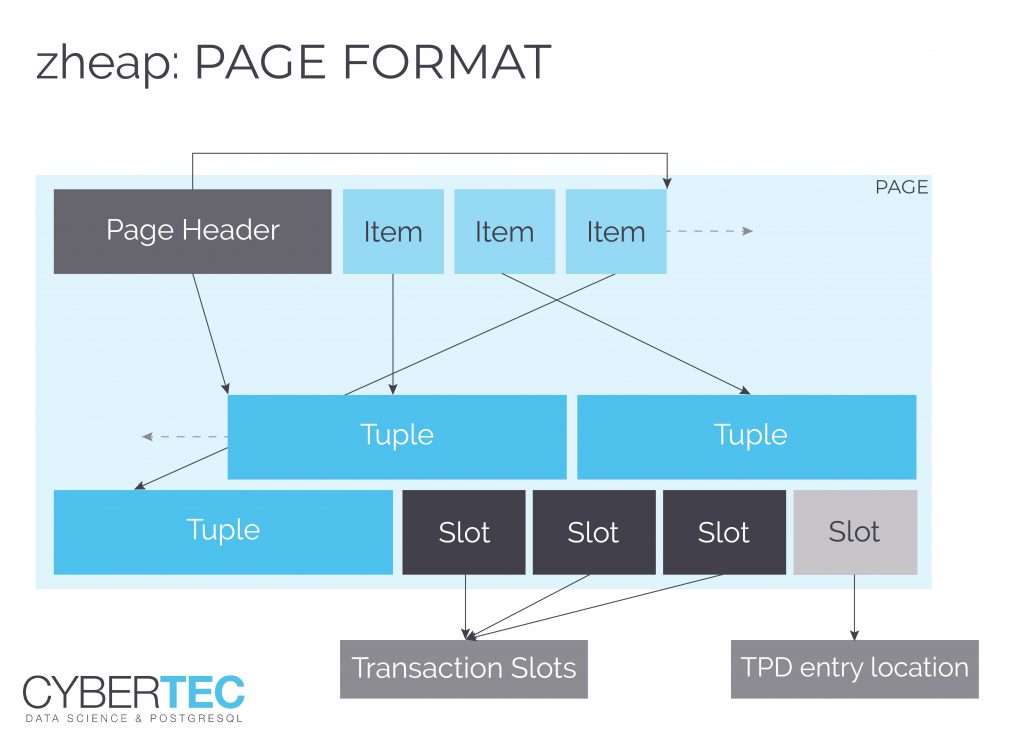 Информация о транзакциях хранится отдельно от контейнера записи
Информация о транзакциях хранится отдельно от контейнера записиПочитать по теме:
Append-only Storage
В бизнесе СУБД часто используются для хранения многократно повторяющихся или монотонно увеличивающихся значений — например, логи, дата и время создания какого-то документа, его числовой PK, …
Знание этого факта позволяет существенно сэкономить записываемый объем. Например, переведя базу нашего сервиса мониторинга с v12 на v13, мы сразу получили примерно 10% выигрыша в объеме индексов за счет дедупликации в btree-индексах на реальных данных.
В эту же категорию можно отнести уже принятый патч «BRIN multi-minmax and bloom indexes».
В идеале, хотелось бы иметь возможность назначать часть полей индексов или целых таблиц как «no-MVCC» (то есть не поддерживается никакое версионирование, а потому — и изменение данных, плюс мгновенная видимость со стороны других транзакций), чтобы иметь возможность сэкономить на полях поддержки MVCC.
 Timescale базируется на ядре PostgreSQL, но «заточена» на timeseries-data
Timescale базируется на ядре PostgreSQL, но «заточена» на timeseries-dataОтложенная индексация
Одной из причин Uber-скандала, всколыхнувшего PostgreSQL-сообщество несколько лет назад была Index Write Amplification, когда записываемый в таблицу кортеж сразу же одновременно записывается и во все индексы, подходящие по условию для него. Получается, чем больше индексов есть на таблице, тем дольше будет производиться вставка в нее.
Но ведь большинство этих индексов заведомо не будут использованы для поиска этой записи сразу же после завершения запроса! Точнее, разработчик точно может отметить эти индексы и их желаемую «актуальность», примерно как это настраивается для реплики.
CREATE INDEX ... WITH (max_lag = '1min');В этом случае сервер сам сможет «размазать» необходимые операции во времени для балансировки нагрузки. Наиболее актуальна эта тема при конкуренции с поисковыми системами вроде Sphinx/ElasticSearch, где основная задача «найти вообще», а не «найти прямо сразу сейчас».
Почитать по теме:
Columnar Storage
В идеале — в ядре или в contrib иметь возможность подключения колоночного хранилища для различных аналитических нужд.
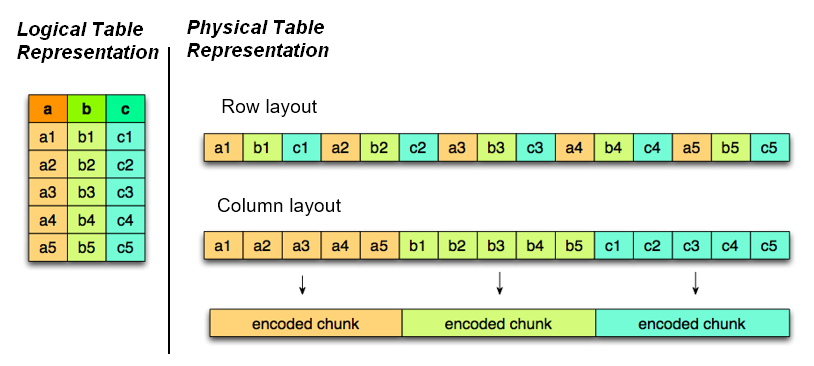 Хранение данных «по столбцам»
Хранение данных «по столбцам»Да, есть решения от Citus, но «в энтерпрайзе» не всегда есть возможность установки дополнительных внешних модулей.
In-memory Storage
Появление очень быстрого нетранзакционного хранилища без сброса на диск сильно помогло бы использовать разноуровневые кэши прямо в PostgreSQL, а не выносить их куда-то в Redis, например — получился бы некий аналог Oracle TimesTen In-Memory Database и Tarantool.
Масштабирование
TEMPORARY TABLE и реплики
Если для генерации отчетов в своей системе вы предпочитаете не писать мегасложные запросы, а более простые итерации по временным таблицам, то неприятностей будет ровно две:
И если с первой проблемой еще как-то можно смириться и исправлять регулярным VACUUM pg_class, то второй недостаток достаточно сильно мешает.
Multimaster
Давно хочется иметь «из коробки».
SQL
SQL-defined Index
Было бы фантастично уметь описывать новые виды индексов прямо на SQL/PLPGSQL, без необходимости C-кодинга — фактически, тут нет ограничений, кроме производительности из-за необходимости сделать все «здесь и сейчас». Но если вспомнить про описанную выше возможность отложенной индексации, то задача уже не кажется такой уж нереальной.
Ведь если можно описывать на различных языках логику формирования и преобразования записи таблицы, то почему бы не позволить то же самое для записи индекса?…
Почитать по теме:
Мониторинг
В инфраструктуре PostgreSQL сильно не хватает удобных средств быстрого визуального контроля и анализа происходящего с производительностью базы. Тут мы в меру собственных сил стараемся создавать подобные инструменты и формировать некоторую базу возможных оптимизаций.
Производительность запросов
Сам анализ, куда ушло время в запросе по тексту плана является нетривиальным, но если его прогнать через визуализацию на explain.tensor.ru, становится попроще:
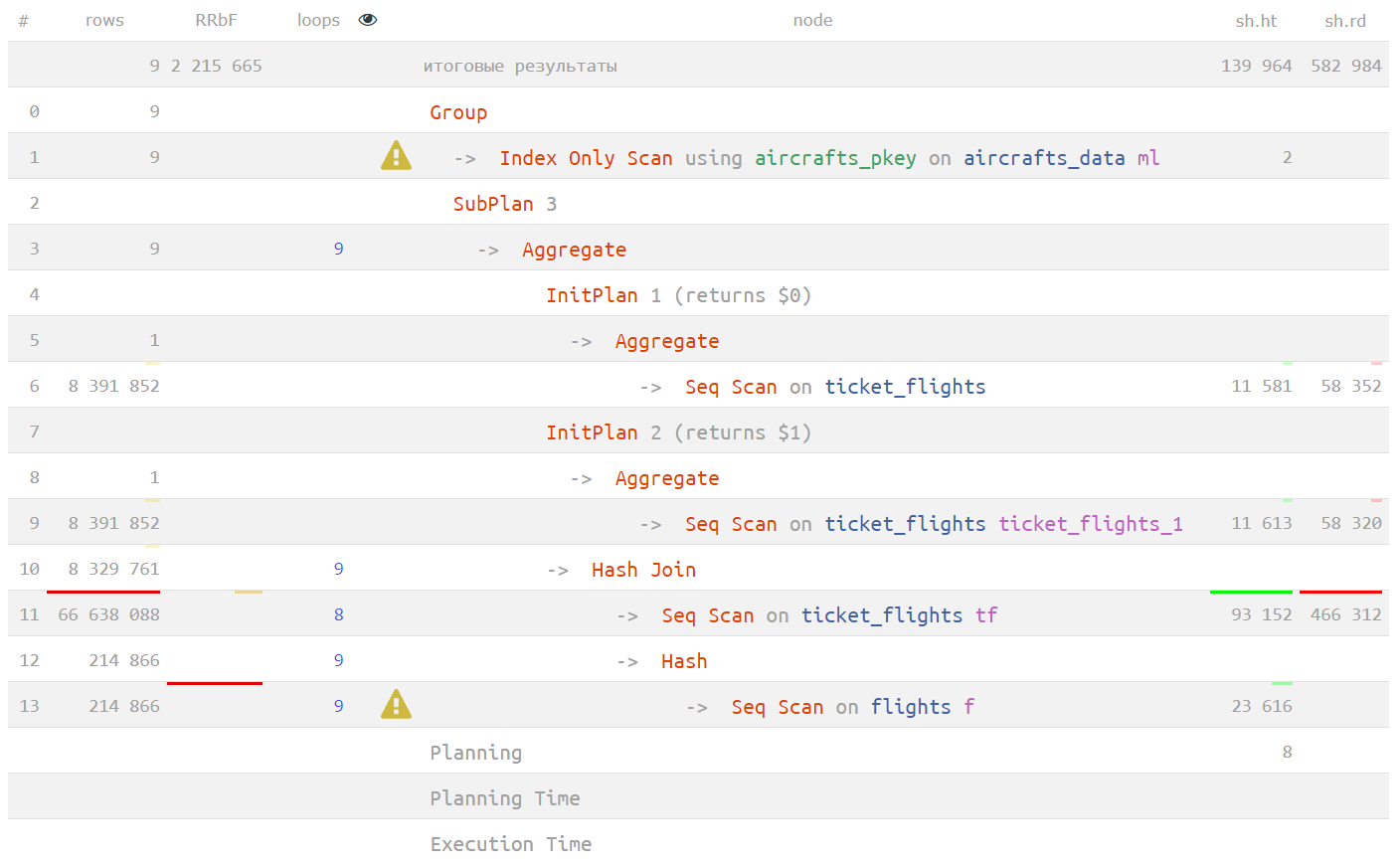 Визуальный анализ плана запроса
Визуальный анализ плана запроса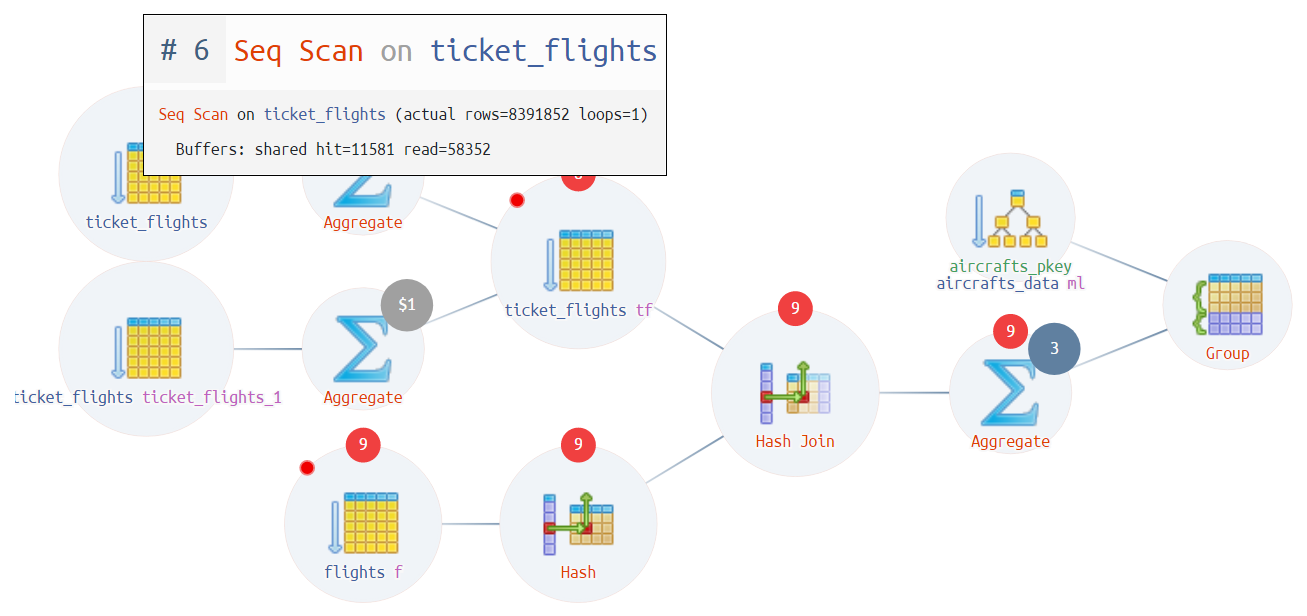 Диаграмма выполнения плана
Диаграмма выполнения планаПочитать по теме:
Снапшоты статистики таблиц
Чтобы определить, в каком именно таблице/индексе «сильно болит», у Oracle есть AWR, а наиболее близким аналогом для PostgreSQL является pg_profile.
Но идея хранить дополнительные данных ровно в той же базе, на которой и так идут проблемы (иначе зачем вам нужен столь подробный мониторинг?), нам показалась не слишком эффективной. Поэтому мы вынесли съем, хранение и визуализацию этой информации на отдельный сервис, который собирает у нас внутри компании всю статистику о работе PostgreSQL-серверов.
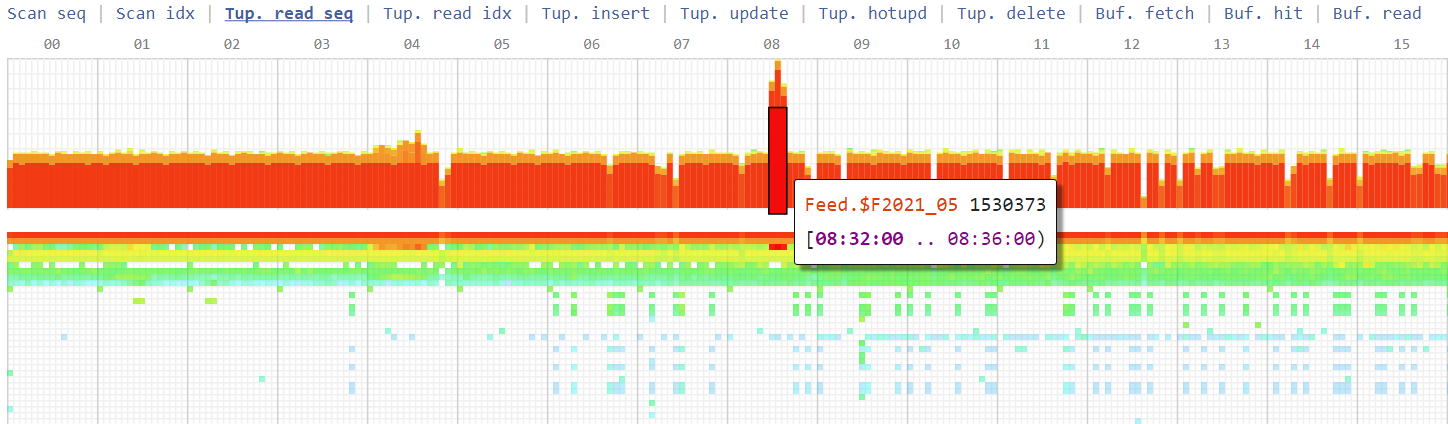 Тепловая карта операций по таблицам
Тепловая карта операций по таблицамПочитать по теме:
Это — что напрягает нас в этой, безусловно, отличной СУБД. В комментариях оставляйте рассказы о своих «болях» и «хотелках» при использовании PostgreSQL.
