Causal Inference: DAG
Многие задачи, встающие перед аналитиками в компаниях, в конечном итоге сводятся к вопросам:, а что если случится это? что будет, если мы введём эту фичу? что будет, если мы примем такую стратегию действий? что будет, если мы ничего не будем делать?
Вы уже наверняка знаете, что лучший способ получить точные ответы на такие вопросы — это эксперименты. Наверное, вы также слышали, что «корреляция — это не каузация» и слепо доверять неэкспериментальным данным не стоит. Но почему это так? И так ли безнадёжны неэкспериментальные исследования? Можно ли приблизить их по точности к экспериментам, и если да, то как?
Всё это попадает в область причинно-следственного вывода (Causal Inference). Она основана на многолетних трудах как в области «классической» статистики, так и в сфере машинного обучения — и даже для краткого введения в проблематику зачастую требуются многостраничные книги. Здесь мы попробуем рассказать о небольшом формальном инструменте, крайне популярном среди неэкспериментальных исследователей. Называется этот инструмент очень коротко — DAG.
Что такое DAG?
Чтобы ответить на этот вопрос, нужно разобрать смысл каждой буквы в этой аббревиатуре. Самая главная буква тут — G, и обозначает она слово Graph. Не путайте с «графиками» (plot) — графами называют структуры вроде вот этой:

Как видите, на рисунке есть пять объектов/переменных, которые связаны линиями. В терминологии графов объекты/переменные называются узлами (nodes), а связи между ними часто называют рёбрами (edges).
Графы — это удобный и наглядный способ представить связи между несколькими объектами. Например, выше видно, что B имеет связи со всеми остальными узлами, а E связан только с B и D.
Обратите внимание, что в текущей версии графа мы можем лишь констатировать наличие связи. Однако связи могут иметь конкретные направления: например, если X является причиной Y. И именно за направленность связей отвечает буква D — Directed. Например, мы можем указать направления в графе следующим образом:

Теперь мы видим, что C влияет на B, B влияет на D, а D влияет на E! Это можно описывать как в терминах причины и следствия, так и в терминах потока информации — информация из C в конечном итоге приходит в E.
Теперь, чтобы стать настоящим DAG-ом, не хватает лишь последней буквы — A (Acyclic). Ацикличность — это отсутствие циклов в графе, т.е. если мы вышли из одного узла и пошли по стрелочкам, то вернуться обратно мы уже не можем.
Выше у нас есть один цикл: A⇒B⇒D⇒A. То есть мы из A вышли и в A же вернулись. С точки зрения Causal Inference это всё равно что сказать «A является причиной и следствием самого себя» либо «следствие предшествует причине», чего по определению не может быть!
Вот так будет выглядеть полноценный DAG:

Здесь введём ещё несколько определений:
Родительские узлы (parent nodes) — узлы, из которых выходят стрелочки
Дочерние узлы (child nodes) — узлы, в которые входят стрелочки
Узлы-потомки (descendant nodes) — дочерние узлы дочерних узлов
Узлы-предки (ancestor nodes) — родительские узлы родительских узлов
Например:
A является родительским узлом для B
B является дочерним узлом для A, C и D
E — это потомок А и С (и частично D —, но о таких вещах позднее).
Немного уточнений
Прежде чем мы пойдём дальше, давайте проясним пару моментов.
Имеют ли эти DAG-и какое-то отношение к Airflow?
Airflow — инструмент для автоматизации рутинных задач, позволяющий запускать некоторые скрипты в определённом порядке по расписанию. Мы учим пользоваться им на многих наших курсах, поэтому вы могли увидеть знакомую аббревиатуру. Это не случайность — с точки зрения математики это ровно те же самые DAG-и!
Разница здесь в целях использования. В рамках Causal Inference DAG-и используются для представления структуры причинно-следственных связей. Airflow же использует эту концепцию для оркестрации процессов — через DAG-и он указывает, в каком порядке выполняются задачи и как они зависят друг от друга.
Иными словами, это хорошая демонстрация силы математики — одна и та же формальная идея может применяться для решения совершенно разных задач!
А как же «порочные круги»? Можно ли их представить в DAG-е?
В реальной жизни довольно часто встречаются ситуации, где A влияет на B, а B затем влияет на A. На первый взгляд это выглядит нарушением условия ацикличности и серьёзным ограничением применимости DAG-ов на практике:
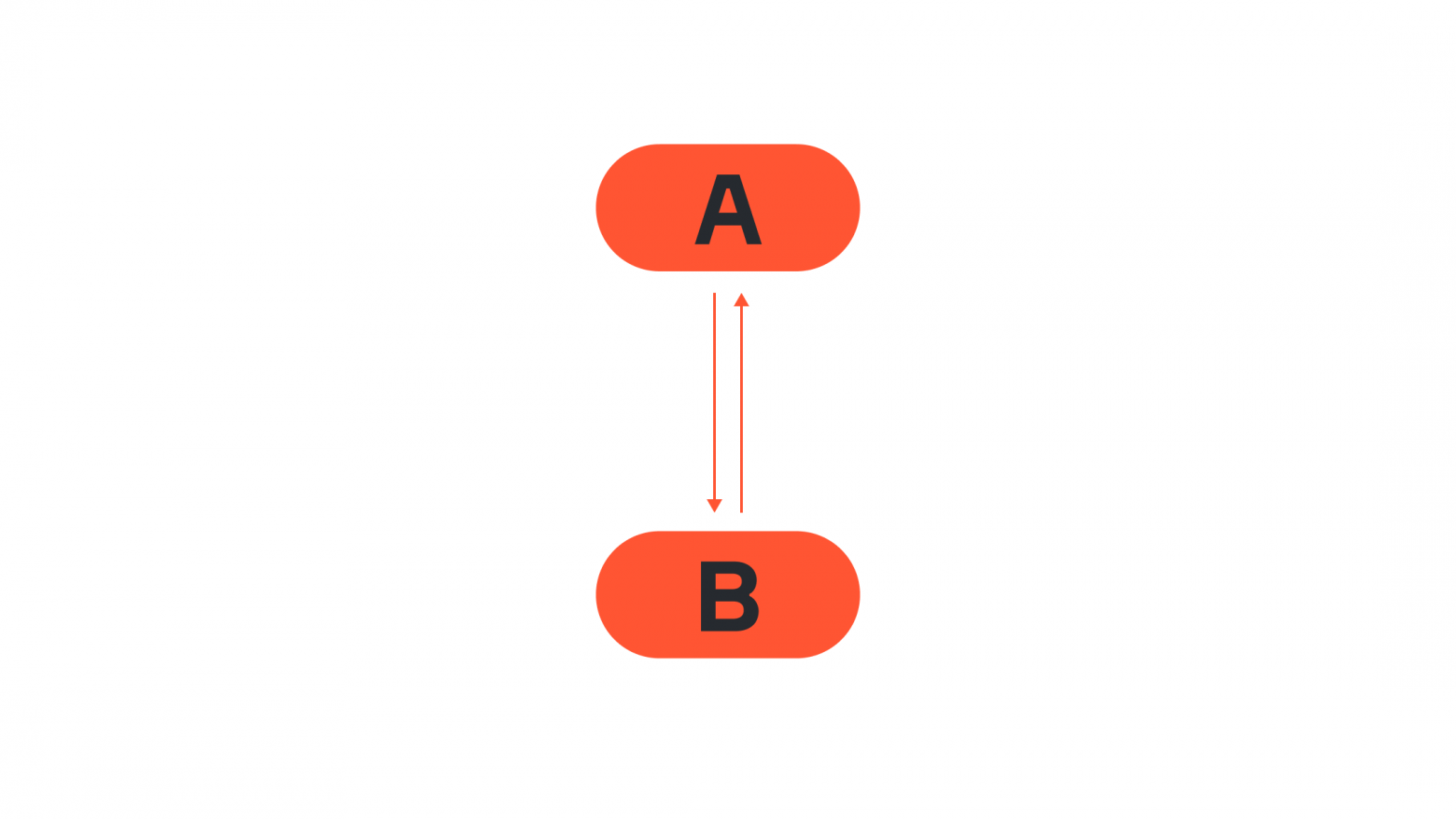
Однако взгляните ещё раз на предложение выше: «A влияет на B, а B затем влияет на A». В дело вступает переменная времени, и представить её можно следующим образом:

Как видите, цикл исчез: мы просто указали, что B влияет на A через какое-то время. DAG-и налагают запреты лишь на ситуации, когда B влияет из настоящего на событие в прошлом, что, согласитесь, не особо реалистично. Только если представить возможность путешествия во времени :)
Зачем нужны DAG-и?
Важно сделать оговорку: сами по себе DAG-и не оценивают наличие, силу и направление связей! Техники и алгоритмы каузального вывода — это отдельная тема, которую мы вынесем в дополнительную литературу. Польза DAG-ов в другом: они помогают принимать решения о том, какие переменные нам нужно контролировать.
Что такое «контроль переменной»? Это её фиксация в каких-то постоянных значениях, чтобы исключить дополнительные источники изменчивости в наших данных и таким образом идентифицировать каузальный эффект, т.е. оценить влияние X и Y максимально точно, сделав поправку на побочные воздействия. Достигается контроль либо разными сортами рандомизации (как в экспериментах), либо набором хитрых статистических техник (об этом в дополнительной литературе).
С точки зрения DAG-ов контроль переменных можно представить как перекрытие потока информации — мы просто блокируем предполагаемые пути перемещения информации и таким образом исключаем воздействие того, что нам не нужно. Также в особых случаях это называют закрытием чёрных ходов (closing backdoors).
Например, в нашем DAG-е мы можем контролировать переменную B. Посмотрите, какие пути передачи информации при этом перекрылись:

Как видите, в данном случае мы перекрыли поток информации от A и C, поступающий в Е! Также это можно сформулировать следующими способами:
Е независима от A и С, если учитывать B
Формальная запись: (E⫫A, E⫫C)∣B
E и A, а также E и C d-сепарированы, если учитывать B
На понятии условных независимостей (т.е. независимости двух переменных с учётом некоторой третьей) и базируется весь причинно-следственный вывод на неэкспериментальных данных.
Обратите внимание, что путь от D оказался перекрыт не полностью — одна стрелочка из D идёт напрямую в E, минуя B! Таким образом, здесь мы можем оценить:
Все непрямые воздействия у нас заблокированы.
Здесь может возникнуть вопрос:, а нужен ли нам вообще DAG? Не будет ли проще запихнуть в модель все возможные переменные, а потом уже разбираться, какой эффект оказала каждая с учётом остальных? И вот тут перед нами предстаёт главная практическая польза DAG-ов: не всякий контроль одинаково полезен, и DAG может помочь нам отделить хороший контроль от плохого. Чтобы понять, как именно, нам нужно ознакомиться с тремя основными паттернами в DAG-ах.
Основные варианты связей в DAG-ах
Цепь (chain)
Цепи возникают тогда, когда на пути между причиной и следствием лежит ещё какая-то переменная. Такую переменную называют медиатором:

На графе слева видно, что A сначала воздействует на C, а потом C воздействует на B. Таким образом, A не воздействует на B напрямую — всё обусловлено переменной C.
Сравните с конфигурацией справа: часть воздействия D на E является прямым воздействием, а часть обусловлена медиатором F.
Пример
Чтобы не ходить далеко, давайте в качестве примера возьмём наши курсы! Не секрет, что цель большинства наших студентов — получить работу в сфере Data Science, и, судя по нашей статистике трудоустройства, это вполне себе вероятный исход :)
Однако степень прямоты этого воздействия — вопрос более спорный. В конце концов, мы делаем образовательные курсы и даём определённый набор знаний, который как раз и должен приводить к устройству на работу:
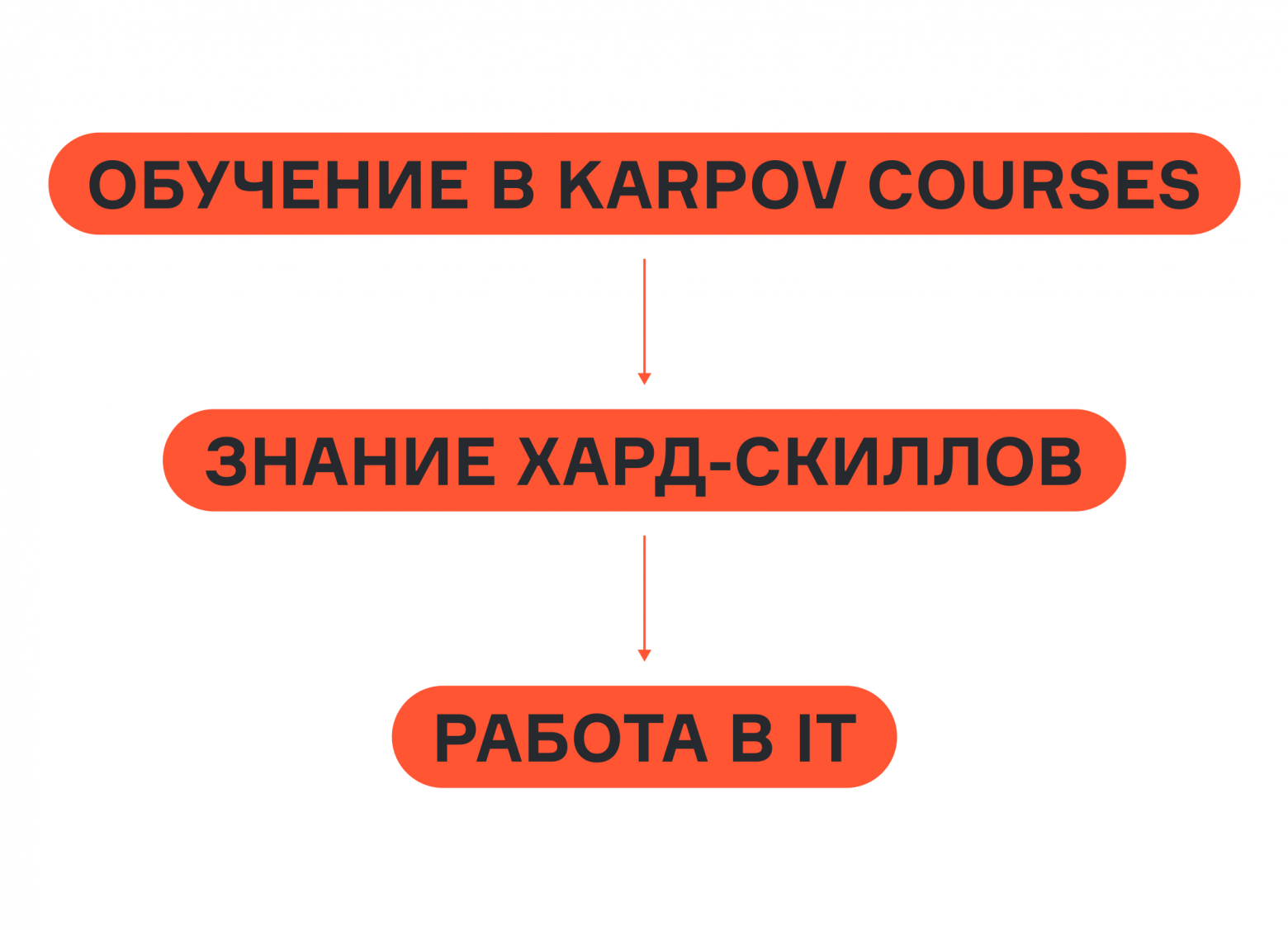
Есть ли какой-то вариант каузальной связи без медиатора в виде знаний? Например, сам наш бренд — периодически студенты приносят вакансии, в которых прохождение наших курсов является большим плюсом. Этот вариант уже может быть путём прямого воздействия:

Нужно ли такое контролировать?
Зависит от нашего исследовательского вопроса. Если нас интересуют только прямые воздействия либо есть необходимость разделить прямое и непрямое (например, мы хотим изолировать эффект, связанный только с нашим брендом), тогда медиаторы определённо нужно учитывать.
Однако часто нас интересует полный эффект воздействия — в нашем случае и качество получаемых знаний, и бренд, и эффективность программы трудоустройства, и другие потенциальные факторы. В таком случае включать медиаторы в модель противопоказано.
Вилка (fork)
В этой ситуации у интересующих нас переменных есть общая причина — некая переменная, которая вызывает и ту, и другую переменную. Их называют побочными переменными (confounders):

Слева видна ситуация, когда A и B независимы, но являются следствием общей причины C, что может приводить к ложной ассоциации между A и B. Даже если каузальная связь (обусловленная другими факторами) реально есть, побочная переменная сместит её оценку — либо завысит, либо занизит. Такая ситуация может произойти в графе справа, если мы хотим оценить воздействие D на E.
Пример
Представьте, что вы наш студент и в один прекрасный день решили пройти наш курс. Вы открываете нашу LMS, где лежат все задания…, а она не открывается.
Тогда вы пишете в наш Slack — команда поддержки помогает именно там, и они явно должны знать о произошедшем. Вернее, вы хотели бы туда написать, но Slack тоже не открывается.
Что же произошло? LMS сломала Slack? Slack сломал LMS? Ни то, ни другое — прямого сообщения между этими двумя сервисами нет. Соответственно, должна быть какая-то общая причина поломки: ей могут оказаться, например, сбои интернета.

Соответственно, если мы проконтролируем эти сбои, то LMS и Slack не должны быть связаны! Если же связь всё ещё есть — значит, может быть ещё какая-то общая причина.
Вы могли бы также предположить, что общей причиной поломки обоих сервисов является сбой на уровне общего для них сервера:

Это валидный DAG, но неверный: опять же, сервера LMS принадлежат нам, а сервера Slack — компании Slack. Поэтому более реалистичный DAG выглядит вот так:

Если они сломались оба и причина не в самом интернете, то произошло редкое событие: две независимые причины появились одновременно. Главное — не принять их за единую причину, а также подумать, есть ли ещё какие-то «чёрные ходы», дающие альтернативное объяснение событиям.
Нужно ли такое контролировать?
Однозначно! Побочные переменные являются главной причиной мантры «корреляция не равно каузация», и чем эффективнее мы сможем перекрыть эти потоки информации, тем лучше. Фактически вся область Causal Inference посвящена тому, как с ними бороться :)
Но очень важно не перепутать вилку с её тёмным двойником.
Перевёрнутая вилка (inverted fork)
Если простая вилка имеет общую причину, то в перевёрнутой вилке мы имеем дело с общим следствием. Иными словами, есть некоторый дочерний узел с несколькими родителями — и такой узел называют коллайдером (collider):
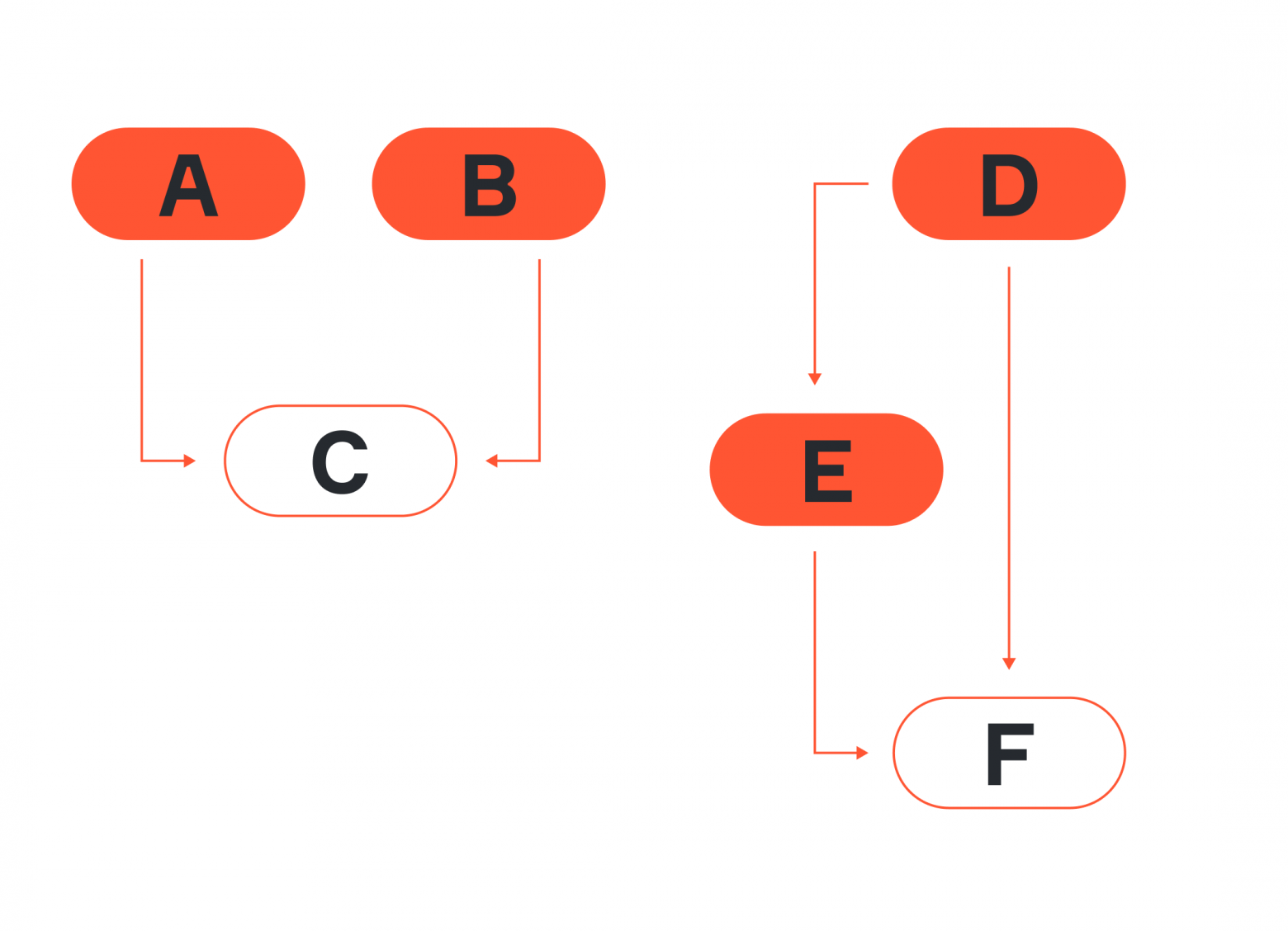
Слева мы видим переменные A и B, которые независимы друг от друга, но обе являются причинами C. Справа наблюдается то же самое, только D и E каузально связаны.
Интересный факт: вариант с независимыми переменными A и B в литературе иногда можно встретить под названием имморальность (immorality). Скорее всего, это следствие терминологии: в имморальности у родительских узлов есть «дети», но между самими родителями нет никакой связи.
Как работать с коллайдерами? Их нужно игнорировать. В этом заключается коварство обратной вилки: мы, как люди и будущие/настоящие дата-сайентисты, привыкли, что действие лучше бездействия, а учесть фактор лучше, чем не учесть. Но если включить коллайдер в нашу модель, то вместо закрывания потока информации мы открываем новый и создаём ложную ассоциацию между переменными. В литературе это называют парадоксом Берксона, который может быть частным случаем ошибки отбора (selection bias).
Пример
Давайте вернёмся к концу нашего прошлого примера — там как раз были две хорошие перевёрнутые вилки. Возьмём одну из них:

Как понимаете, наши сервера вряд ли могут как-то повлиять на качество интернета. Но если мы будем смотреть только на ситуации, где LMS не работает, то мы увидим довольно сильную отрицательную взаимосвязь. Как так получается? Давайте попробуем разобраться.
Представим, что вероятность нормальной работоспособности нашего сервера в текущий момент времени составляет 99%. Такую же вероятность дадим работоспособности интернета. Всего у нас есть четыре возможные комбинации ситуаций — так как события у нас независимые, их общая вероятность считается как произведение обеих вероятностей:
Вероятность, что оба работают: 0.99×0.99 ≈ 0.98
Вероятность, что работает только сервер: 0.99×0.01 ≈ 0.01
Вероятность, что работает только интернет: 0.01×0.99 ≈ 0.01
Вероятность, что оба сломались: 0.01×0.01 ≈ 0.0
Как видите, чаще всего всё будет работать окей. В редких случаях будет ломаться либо сервер, либо интернет. Оба сразу ломаться будут исчезающе редко.
Но что если мы будем учитывать только ситуации, когда LMS уже не работает? Тогда вероятность одновременной работоспособности и сервера, и интернета становится нулевой — достаточно истинности одного фактора, чтобы LMS перестала работать!
Как посчитать остальные вероятности при условии неработоспособности LMS? Для этого нам нужно сложить вероятности оставшихся трёх исходов и поделить оставшиеся вероятности на эту сумму.
Вероятность, что оба работают: 0
Вероятность, что работает только сервер: 0.01 / (0.01 + 0.01 + 0.0) ≈ ≈ 0.497
Вероятность, что работает только интернет: 0.01 / (0.01 + 0.01 + 0.0) ≈≈ 0.497
Вероятность, что оба сломались: 0.00 / (0.01 + 0.01 + 0.0) ≈ 0.005
Что мы имеем?
Примерно в 50% случаев сервер не будет работать, а интернет будет
Примерно в 50% других случаев интернет не будет работать, а сервер будет
Очень редко не будут работать оба, но это должно очень повезти
К какому выводу мы можем прийти? Либо активность сервера ломает интернет, либо интернет ломает нам сервер! Оба варианта, конечно же, неверные.
Нужно ли такое контролировать?
Категорически противопоказано! Контроль коллайдеров никогда не приводит ни к чему хорошему — добавление таких переменных в модель всегда создаёт ложные ассоциации либо искажает существующие связи.
Более того, нельзя контролировать и потомков коллайдера! Это приводит к аналогичному эффекту, хотя он может быть и немного менее выраженным.
Например, у нас таким потомком может быть нерабочая страница с заданием. Это прямое следствие сбоев LMS, и контролировать такое — всё равно что контролировать сами поломки LMS:

Что почитать
На тему Causal Inference написано уже очень много книг и статей. Чтобы вы не запутались во всём многообразии литературы, мы составили небольшую подборку:
Causal Inference in Statistics: A Primer — классическое введение в DAG-и от Judea Pearl, одного из главных исследователей проблематики каузальности.
A Crash Course in Good and Bad Controls — ещё более широкий разбор разных ситуаций, когда что-то может быть «хорошим» или «плохим» контролем. Более того, описываются ситуации «нейтральных» переменных, которые не влияют на идентификацию каузального эффекта, но могут влиять на точность оценки.
Causal Inference for the Brave and True — хорошее введение не только в общую проблематику каузального вывода, но и разные техники контроля переменных. Первая половина книги посвящена более «классическим» методам, вторая смотрит на проблему с точки зрения нововведений в машинном обучении. Также книга содержит много тематических мемов и примеров расчёта на Python.
The Effect: An Introduction to Research Design and Causality — по сравнению c предыдущей старается максимально оберегать читателя от формул, больше полагаясь на словесное объяснение и развитие интуиции. При этом местами она оказывается даже подробнее и глубже, хотя покрывает не все темы из предыдущей книги и больше напирает именно на «классические» подходы. Помимо примеров на Python, также есть примеры на R и в Stata.
Хороший флоучарт для выбора книги — в зависимости от желаемой сложности и научного интереса. Впрочем, многие книги из диаграммы более продвинутые и требуют определённой терпимости к математической нотации. Также на сайте есть препринт книги, рассматривающей Causal Inference с позиции машинного обучения, но он так и остался недописанным.
Также добавим пару полезных инструментов:
Библиотека DoWhy на Python — пытается быть максимально всеобъемлющей и охватить все возможные шаги каузального вывода, начиная от DAG и заканчивая анализом надёжности вывода.
DAGgity — достаточно известное standalone и веб-приложение, в котором можно нарисовать свой DAG и автоматически его проанализировать. Обязательно загляните в раздел Learn — там тоже много всего полезного!
