Cassandra. The road to 1 PB
Центр Развития Перспективных Технологий — компания разработчик системы мониторинга товаров. Как IT компания с большим количеством данных мы используем множество NoSQL решений в своей повседневной работе. Одним из таких решений является Apache Cassandra.
Суммарно, во всех кластерах Cassandra мы храним 0.4PB данных при общей емкости 0.9PB, стабильно производим 0.7 млн операций записи в секунду и доступа к данным и 1.1 млн когда необходимо разогнаться в трудные времена, при этом продолжаем непрерывно расширяться.
Отсюда лежит и название статьи, к моменту публикации последней главы из цикла петабайтный барьер емкости будет взят.
Материал подразумевает, что вы уже начали знакомиться с этой замечательной базой данных, хотите найти примеры её использования в российском сегменте интернета и будет полезен тем, кто постоянно ищет способ обучиться за счёт чужих ошибок. Ошибок мы совершили не мало, добро пожаловать!
История кассандры в ЦРПТ началась с небольшого проекта по реализации сервера эмиссий кодов маркировки (КМ). Это такой сервис, в котором мы проверяем уникальность кодов и гарантируем отсутствие дубликатов для каждого выпущенного КМ. Код маркировки состоит из идентификаторов применения, GTIN, SERIAL, наших кастомных AI 91/92/93 и некоторых других. Уникальность нам нужна только для комбинации GTIN + SERIAL, остальное не так важно для формирования первичного ключа. Подробный разбор самой системы эмиссии потянет на отдельную статью, в этом же материале ограничимся тем, что на данный момент это самый первый кластер и наибольший по количеству ключей, по состоянию на момент публикации — около 400 миллиардов.
Всего в ЦРПТ три основных кластера кассандры, разного объема, форм фактора и назначения:
Кластер эмиссии. Здесь хранятся все когда-либо выпущенные коды маркировки.
Кластер документов. В нём мы храним все внешние и внутренние документы.
Экспериментальный кластер операционного контура. В нём хранятся все производные из документов операции над КМ.
Под Cassandra мы используем типовые сервера с 64 вычислительными ядрами 384GiB оперативной памяти и 12-ю дисками.
Поскольку Cassandra — это в первую очередь Java приложение, утилизация такого сервера получается неполной. Это и большой размер хипа, и громадный размер внутренних структур данных, о которых поговорим чуть позже, и большие спонтанные задержки на 99-ой перцентили. Конечно, при таком размере памяти очень много данных попадает в Page Cache, но поскольку сама Cassandra в первую очередь база данных класса key-value — данные в большинстве случаев равномерно размазаны по дискам и чаще всего имеют рандомный доступ при чтении, поэтому Page Cache [3] постоянно смывается не успевая нанести большой пользы.
5 секунд из жизни одного кластера
HITS MISSES DIRTIES RATIO BUFFERS_MB CACHE_MB
-30584 32404 35 -1680.4% 705 159453
-35994 37762 101 -2035.9% 705 159450
-40415 51771 58 -355.9% 705 159448
-33187 34991 45 -1839.6% 705 159446
-9604 27292 68 -54.3% 705 159443По этим причинам мы стараемся не использовать большой сервер целиком и разбиваем его на три ноды меньшего размера посредством LXC-контейнеров. Ноде выделяется 21 CPU и 120GiB RAM и четыре диска. В зависимости от нагрузки и объема внутренних структур данных либо 8GiB либо 16GiB в Heap памяти.
Каждый кластер имеет от 15 до 24 нод с фактором репликации 3. В пересчёте на железки это от 5 до 8-ми серверов, в зависимости от кластера. При добавлении нового сервера в строй, одна за другой входят три маленьких ноды, за счёт чего кластер испытывает меньший шок в процессе расширения, чем при росте за счёт более емких серверов.
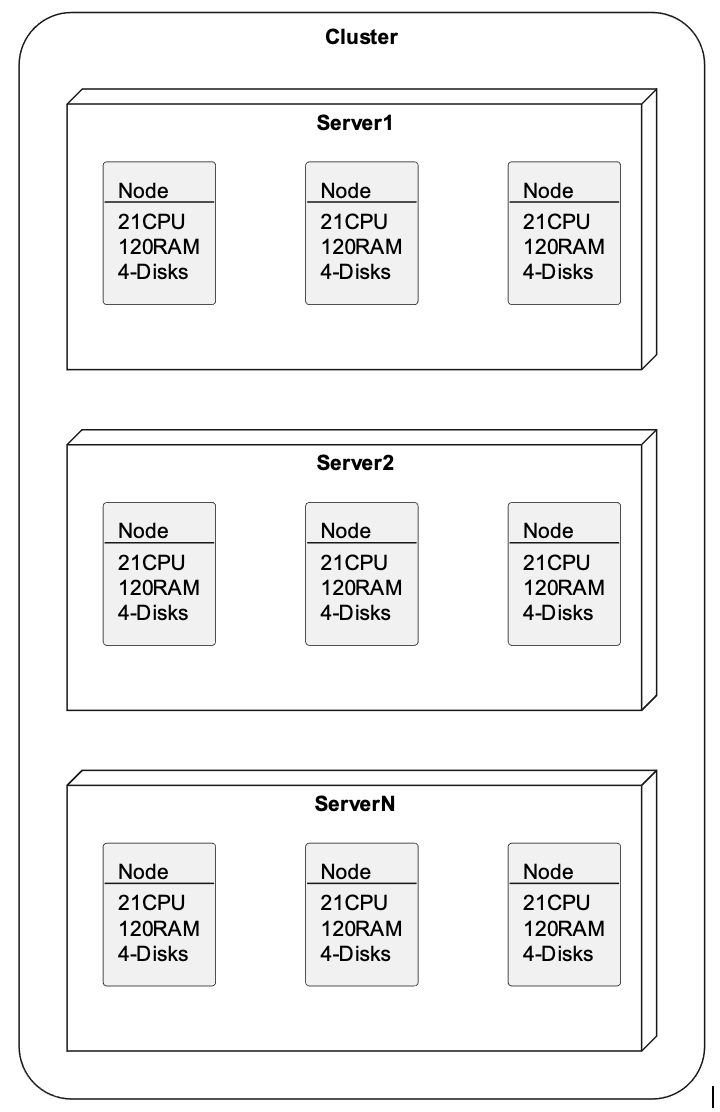 Figure 1. Разделение серверов на ноды
Figure 1. Разделение серверов на ноды
Такая модель была не всегда. Самый первый кластер представлял собой 5 железных серверов с 72 ядрами, 128GiB памяти на борту и имел 10 SSD дисков очень маленького объема (480GiB).
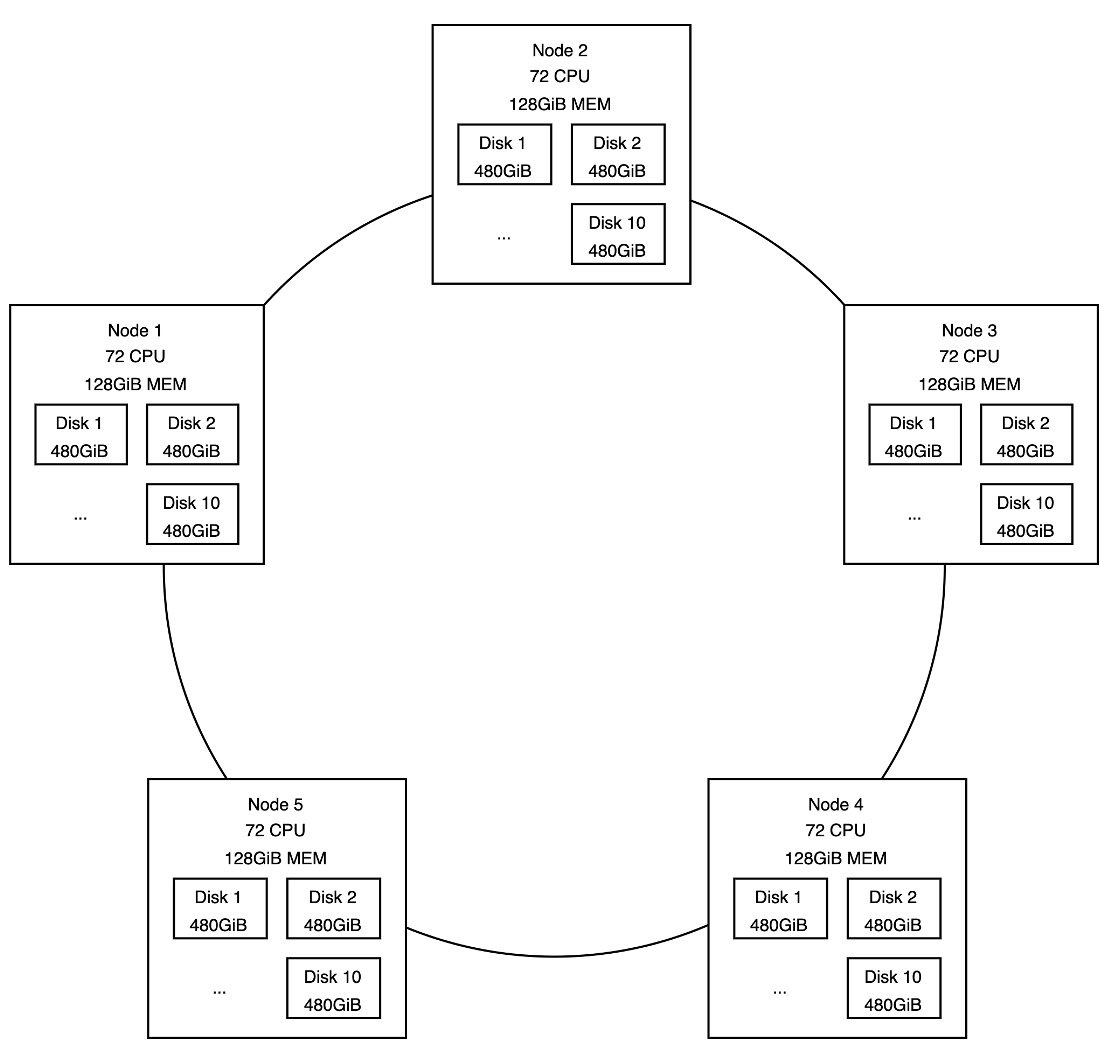 Figure 2. Начальное распределение нод по кластеру
Figure 2. Начальное распределение нод по кластеру
Используем эти знания как отправную точку нашего повествования, итерационно пройдем по причинам и следствиям трансформации кластера, а также изученным урокам следующим маршрутом:
1/7 Just Bunch Of Disks (Просто куча дисков)
2/7 История одного Repair
3/7 Побег из SimpleSnitch
4/7 Apache Cassandra и структуры данных
5/7 Прожимаем tail latency
6/7 «A» упало, «B» пропало
7/7 Маленькие заметки большого кластера
Часть 1/7 Just Bunch Of Disks (Просто куча дисков)
Anything that can go wrong will go wrong. — Murphy’s law
Запись данных в кассандре в большинстве случаев линейная и происходит в два этапа:
Запись CommitLog на диск
Сохранение в MemTable
И первый и второй случай не сильно бьют по IOPS диска, однако, понимая как эти структуры данных могут влиять друг на друга и что потеря диска с коммит-логом в случае «фактора уборщицы выдернувшей вилку сервера из розетки» может привести к потере данных, мы заранее занесли CommitLog на системный раздел, который в наших серверах собирается как RAID1 из двух SSD дисков.
Каждый из 10-ти дисков «большой» ноды был заведен как отдельная data_file_directory в cassandra.yaml, что предоставляло кассандре возможность самостоятельно управлять распределением (ключей) данных по диску и при чтении мы попадали напрямую в очередь операций конкретного SSD диска [1],[2], что в сумме давало 5×10 * ~2400 почти 120 тыс операций чтения только с одного кластера. Невероятные цифры, о достижении и целесообразности которых на старте, в 2019-ом мы даже не могли мечтать.
Типовой cassandra.yaml первого кластера
commitlog_directory: /var/lib/cassandra/commitlog
...
data_file_directories:
- /srv/disk01/data
- /srv/disk02/data
...
- /srv/disk10/dataПри записи данных в CommitLog подтверждение записи клиенту может происходить либо после flush«а данных на диск, либо мгновенно, с асинхронным flush«ем (commitlog_sync: batch/periodic). Классический шаблон скорость против сохранности данных.
CommitLog нужен базе, чтобы восстановить MemTable в случае нештатного завершения работы.
При штатном выключении MemTable сбрасывается на диск перед выключением ноды.
При нештатном восстанавливается из CommitLog«а на старте, что существенно замедляет запуск упавшей ноды при больших размерах MemTable. При этом, после сброса MemTable на диск — соответствующие ему записи CommitLog«а зачищаются, для нового MemTable«а его CommitLog пишется независимо.
 Figure 3. Общий процесс (асинхронной) записи commitlog
Figure 3. Общий процесс (асинхронной) записи commitlog
Именно в процессе записи MemTable на диск скрываются первые грабли юного инженера. Проблема не в сохранности данных при commitlog_sync: periodic, как можно было изначально подумать. Перманентно потерять данные при том количестве хинтов, механизмов репейра и строгому следованию правила кворумной записи/чтения нужно сильно постараться или, например, проявить бесконечную отвагу и выключить разом все ноды.
Проблема заключалась в распределении данных MemTable между имеющимися data_file_directories.
При сбросе MemTable на диск он разделяется по количеству data-директорий и попадающих в них диапазонов ключей (в token-range)[4]
Из этого вытекает два обстоятельства:
Любой flush интенсивной, равномерно нагруженной записью — это всегда столько SS (Sorted String) таблиц, сколько было указано data-директорий. Эти SSTables впоследствии необходимо мержить (прогонять через процесс Compaction).
Учитывается только распределение ключей внутри token-range, но не размер партиций. Если хотя бы одна таблица имеет неравномерное распределение ключей, например при wide-partition, вся data-директория будет с перекосом по размеру, относительно остальных.
 Figure 4. Процесс сброса MemTable на диск
Figure 4. Процесс сброса MemTable на диск
Подобное поведение присутствует не с первой версии кассандры, а только начиная с >=3.2 и редко упоминается в материалах по первоначальной настройке кластера. Изменения алгоритма со ссылками на код и причинами его появления подробно описаны в CASSANDRA-6696. Предыдущее поведение (до реализации тикета) могло приводить к проблеме воскрешения удаленных строк при выходе из строя одного из дисков, поскольку данные одного и того же диапазона ключей могли находиться на нескольких дисках одновременно и при потере более свежего диапазона с отметками об удалении (Tombstone) — автоматически становиться доступными на проблемной ноде (даже после замены диска).
Наш первый кластер столкнулся с проблемой из-за наличия имбалансных партиций и относительно небольшого размера каждого конкретного диска на версиях >=3.10.4. В одной из таблиц мы хранили метаданные по запросам и день выполнения запроса был одной из составляющих для partition-key.
Таблица с дисбалансом по ключам
-- Никогда, НИКОГДА не копируйте этот код из статьи не впитав последствия УРОК(а) 1
create table requests
(
app_name ascii,
type ascii,
day ascii,
ts timeuuid,
source ascii,
protocol ascii,
request_path text,
instance_id ascii,
request_id ascii,
PRIMARY KEY ((app_name, type, day), ts)
)
with caching = {'keys': 'NONE', 'rows_per_partition': 'NONE'}
and compaction = {'class': 'TimeWindowCompactionStrategy','compaction_window_unit': 'DAYS','compaction_window_size': 1}
and compression = {'class': 'org.apache.cassandra.io.compress.LZ4Compressor', 'chunk_length_in_kb': '64'}
and speculative_retry = 'NONE'
and default_time_to_live = 15552000;Из этого следует первый выученный нами урок:
Урок 1: При использовании data_file_directories с дисками небольшого объема всегда убеждайтесь в отсутствии перекосов по объему данных в используемой структуре, поскольку Cassandra не заботится о размере размещаемых данных на каждом диске, а только равномерно распределяет между ними токены.
В нашем случае разброс между дисками составлял ~150GB, но даже этого хватило, чтобы при заполнении одного диска на 400GB, при общей заполненности кластера 35–40% остановились все последующие Compaction-процессы для этого диапазона ключей, что в свою очередь приводило к деградации по скорости чтения, а также, из-за отсутствия фонового слияния строк в разных SSTable — к ускоренному заполнению диска.
Compaction и скорости чтения из множества SSTable будет посвящен отдельный набор граблей.
Для того чтоб оживить кластер, данные на проблемных нодах были перемещены на свободные диски. Под соответствующие директории с таблицами были созданы симлинки и кластер продолжил функционировать. В дальнейшем мы отказались от таблицы с запросами с последующей её полной очисткой, изменили конфигурацию и топологию кластера, в результате которой приблизились к финальному варианту ноды: 21CPU/60RAM/4-Disks. Как и почему 60GiB RAM превратились в 120GiB в деталях расскажем в четвертой части нашего повествования.
Одним из вариантов решения проблемы в моменте могло бы стать добавление дополнительных дисков (и новых data-директорий) с последующим вызовом nodetool relocatesstables, но тогда о наличии подобной опции мы не знали, подразумевая что кол-во data-директорий остается неизменным в течении всего жизненного цикла ноды. Еще одна возможная точка расширения кластера в моменте, которую можно было проверить — это наличие неудаленных снепшотов SS таблиц через nodetool listsnapshots && nodetool clearsnapshot, но автоматического создания снепшотов на тот момент предусмотрено не было, да и на лежащей ноде особо nodetool«ом не разгуляешься.
